混合精度训练掌握:PyTorch提升数据并行性能的关键技术
发布时间: 2024-12-12 03:50:12 阅读量: 14 订阅数: 12 

实现SAR回波的BAQ压缩功能
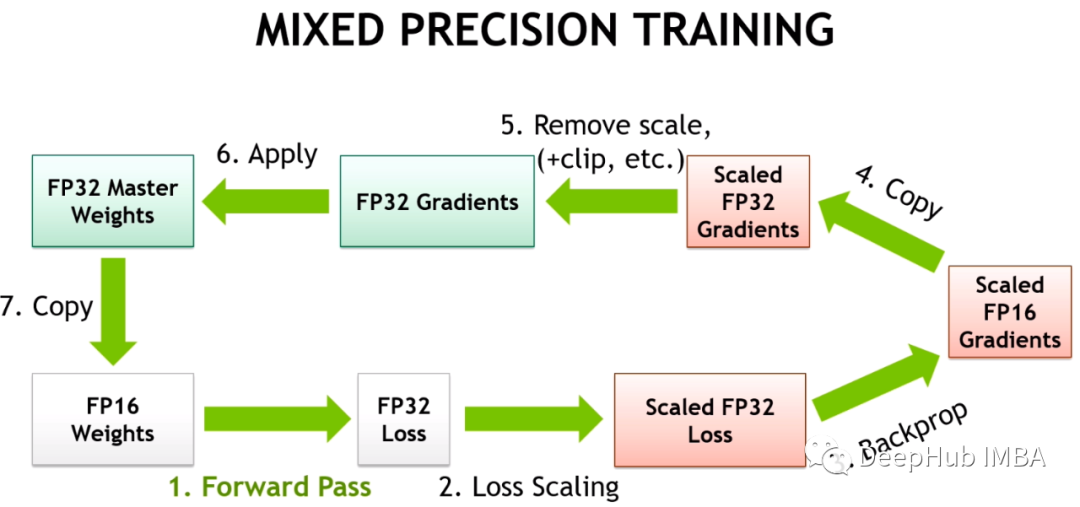
# 1. 混合精度训练基础与重要性
在深度学习领域,模型的训练过程要求高精度的计算,但同时也需要高效的执行速度和较低的资源消耗。混合精度训练作为一种先进的技术,通过结合不同精度的数值格式,解决了这一矛盾,从而在保证模型精度的同时,大幅度提高了训练的效率。
## 1.1 混合精度训练的基本概念
混合精度训练的核心思想是利用半精度(FP16)或更低精度的数据类型来执行计算,同时辅以单精度(FP32)来维持数值稳定性。这种做法不仅可以减少内存占用和提高运算速度,还可以通过特定硬件(例如NVIDIA的Tensor Core)实现显著的加速效果。
## 1.2 混合精度训练的优势分析
采用混合精度训练相比传统的单精度训练方式,有着以下几个明显优势:
- **提升计算效率**:半精度浮点数的运算速度和内存占用都远低于单精度浮点数。
- **减少内存占用**:可以有效降低内存使用,这对于训练超大型模型尤为重要。
- **加速训练过程**:特别是结合现代GPU的专门硬件加速技术,如Tensor Core,训练速度可以大幅提升。
实现混合精度训练时,我们需要注意的是,在训练过程中保持模型的数值稳定性和减少精度损失,这将在后续章节中详细讨论。
# 2. PyTorch中的混合精度实现
## 2.1 混合精度训练的基本概念
### 2.1.1 浮点数精度与计算效率
在深度学习训练中,浮点数精度是影响计算效率和模型表现的关键因素之一。单精度浮点数(float32)是最常用的数值表示方式,它在内存占用和计算速度方面达到了良好的平衡,同时也能够满足大多数深度学习模型的精度要求。然而,随着模型规模的扩大,对于计算资源的需求也在不断增加。为此,研究者开发了混合精度训练方法,通过结合单精度浮点数和半精度浮点数(float16),以减少内存占用并加快计算速度,从而在一定程度上缓解硬件资源的压力。
### 2.1.2 混合精度训练的优势分析
混合精度训练的优势主要体现在两个方面:内存效率和计算效率。通过使用float16,可以减少模型参数和激活值的存储需求,降低内存占用,进而使得在相同硬件资源下能够训练更大的模型。同时,支持float16的硬件通常能够提供更高的计算吞吐量,从而加快训练速度。混合精度训练还有助于改善训练过程中的数值稳定性,通过梯度缩放等技术,确保训练的收敛性。
## 2.2 PyTorch自动混合精度API使用
### 2.2.1 AMP API概述
PyTorch提供了自动混合精度(AMP)API,目的是为了简化混合精度训练的实现。AMP能够自动识别模型中可以使用float16进行运算的部分,同时保持关键计算使用float32,以确保训练的数值稳定性。AMP API支持两种模式:一种是纯脚本模式,另一种是GradScaler模式,后者能够在训练过程中自动进行梯度缩放,帮助解决混合精度训练中可能出现的梯度消失或梯度爆炸问题。
### 2.2.2 如何在PyTorch中启用AMP
启用PyTorch中的AMP非常简单,只需要导入`torch.cuda.amp`模块中的`autocast`和`GradScaler`。在训练循环中,使用`autocast`上下文管理器包围模型的前向传播和损失计算,这样就能自动将这些部分的计算使用float16执行。对于反向传播,使用`GradScaler`来缩放梯度,然后用优化器正常进行参数更新。以下是启用AMP的代码示例:
```python
import torch
from torch.cuda.amp import autocast, GradScaler
model = ... # 模型定义
optimizer = ... # 优化器定义
scaler = GradScaler()
for input, target in data:
optimizer.zero_grad(set_to_none=True)
# autocast上下文管理器确保浮点数运算使用float16
with autocast():
output = model(input)
loss = loss_fn(output, target)
# 使用梯度缩放避免数值问题
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
```
### 2.2.3 AMP的实践应用场景
混合精度训练尤其适用于大规模的深度学习模型,例如在自然语言处理(NLP)和计算机视觉(CV)领域的大型模型。这些模型通常有数十亿甚至数千亿的参数,对内存和计算资源的需求巨大。在实际应用中,开发者可以将AMP API与PyTorch的数据并行性结合,进一步提升模型的训练效率。此外,AMP也常用于在GPU集群上进行分布式训练,以缩短训练时间,提高研究和产品开发的迭代速度。
## 2.3 混合精度训练中的错误和调试
### 2.3.1 常见问题及解决方案
在混合精度训练过程中,开发者可能会遇到一系列问题,例如梯度消失或爆炸、精度损失等。这些问题通常与数值精度和数值稳定性有关。解决这些问题的常用策略包括:
- **梯度缩放**:使用GradScaler在反向传播之前放大梯度,这样可以防止在低精度下梯度消失的问题。
- **损失缩放**:在损失计算之前对损失值进行缩放,以便

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 PyTorch 中的数据并行技术,提供了全面的指南,帮助读者充分利用 GPU 加速。专栏涵盖了数据并行机制、最佳实践、性能调优策略、数据加载优化、混合精度训练、模型一致性、模型并行与数据并行的对比、内存管理技巧、多 GPU 系统中的扩展性、云计算部署、负载均衡策略、生产环境最佳实践、跨节点通信延迟解决方案、序列模型并行化挑战、自定义操作并行化、梯度累积并行化、数据加载优化和梯度裁剪处理等主题。通过深入的分析和实用技巧,本专栏旨在帮助读者掌握 PyTorch 数据并行技术,从而显著提高深度学习模型的训练效率和性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MAC版SAP GUI安装与配置秘籍】:一步到位掌握Mac上的SAP GUI安装与优化
参考资源链接:[MAC版SAP GUI快速安装与配置指南](https://wenku.csdn.net/doc/6412b761be7fbd1778d4a168?spm=1055.2635.3001.10343)
# 1. SAP GUI简介及安装前准备
## 1.1 SAP G
BIOS故障恢复:面对崩溃时的恢复选项与技巧
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2018/P/j/8qyRn6Q1WEr2jdkn3h6Q/m4.jpg)
参考资源链接:[Beyond BIOS中文版:UEFI BIOS开发者必备指南](https://wenku.csdn.
硬件维修秘籍:破解联想L-IG41M主板的10大故障及实战解决方案
参考资源链接:[联想L-IG41M主板详细规格与接口详解](https://wenku.csdn.net/doc/1mnq1cxzd7?spm=1055.2635.3001.10343)
# 1. 硬件维修基础知识与主板概述
在硬件维修领域,掌握基础理论是至关重要的第一步。本章将介绍硬件维修的核心概念,并对主板进行基础性的概述,为后续更深入的维修实践奠定坚实的基
MSFinder数据处理:批量文件处理,效率提升50%的秘诀!

参考资源链接:[使用MS-FINDER进行质谱分析与化合物识别教程](https://wenku.csdn.net/doc/6xkmf6rj5o?spm=1055.2635.3001.10343)
# 1. MSFinder数据处理概述
## 1.1 数据处理的重要性
在现代IT行业,数据处理作为数据科学的核心组成部分,关系到数据分析的准确性和效率。MSFinder作为一种专门的处理工具,旨在帮
FEKO案例实操进阶:3个步骤带你从新手到实践高手

参考资源链接:[FEKO入门详解:电磁场分析与应用教程](https://wenku.csdn.net/doc/6h6kyqd9dy?spm=1055.2635.3001.10343)
# 1. FEKO软件概述与基础入门
## 1.1 软件简介
FEKO是一款用于复杂电磁场问题求解的高频电磁模拟软件,它提供了一系列先进的解决方案,包括基于矩量法(MoM)、多层快速多极子方法(MLFMM)、物
【ZKTime考勤数据库性能调优】:慢查询分析与优化策略

参考资源链接:[中控zktime考勤管理系统数据库表结构优质资料.doc](https://wenku.csdn.net/doc/2phyejuviu?spm=1055.2635.3001.10343)
# 1. ZKTime考勤系统概述
在当今数字化时代,考勤系统已经成为企业日常管理不可或缺
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )