3D零件库扩展术:大数据时代下的增长应对策略
发布时间: 2024-12-03 23:56:19 阅读量: 4 订阅数: 9 

参考资源链接:[3DSource零件库在线版:CAD软件集成的三维标准件库](https://wenku.csdn.net/doc/6wg8wzctvk?spm=1055.2635.3001.10343)
# 1. 3D零件库概述与大数据时代的挑战
## 1.1 3D零件库的定义与作用
随着制造行业的数字化转型,3D零件库成为工业产品开发中不可或缺的一部分。它不仅存储了大量的零件数据信息,还支持设计、分析和制造等关键环节,提高了生产效率并降低了成本。
## 1.2 大数据时代的挑战
在大数据时代,3D零件库面临的挑战包含但不限于:数据量的爆炸式增长、数据格式的多样性、数据处理与分析的复杂性。这些挑战要求开发者和维护者不仅要关注数据存储,还要关注数据的挖掘、分析和可视化等多方面的需求。
## 1.3 大数据技术与3D零件库的融合前景
大数据技术的融合为3D零件库带来了新的发展机遇。通过高效的数据处理和分析手段,可以更好地进行零件的检索、推荐和管理,同时提高设计和生产的智能化水平。3D零件库未来将更加紧密地与大数据技术结合,共同推动制造业的创新发展。
```mermaid
graph LR
A[3D零件库定义] --> B[大数据挑战]
B --> C[大数据技术应用前景]
```
# 2. 3D零件库的数据架构与管理策略
## 2.1 3D数据的结构化处理
### 2.1.1 数据模型的设计原则
在3D零件库中,数据模型的设计直接关系到信息的检索效率和用户体验。一个良好的数据模型应遵循以下原则:
- **统一性原则**:确保数据模型在不同数据源和系统间保持一致,避免信息孤岛。
- **扩展性原则**:数据模型应支持未来数据类型和关系的扩展,适应技术变化。
- **简洁性原则**:避免过度设计,确保模型简单直观,便于理解和维护。
- **标准化原则**:使用业界标准的数据格式和协议,如ISO标准的STEP和IGES格式。
### 2.1.2 元数据管理和存储策略
元数据是描述数据的数据,它为3D零件库提供了关键信息,包括零件名称、尺寸、材料属性等。元数据管理策略应包含以下几个方面:
- **元数据标准的建立**:统一元数据格式和结构,便于数据交换和整合。
- **元数据的分类**:按零件的属性对元数据进行分类,方便检索。
- **存储机制的选择**:依据数据量和访问频率选择合适的存储方式,如使用NoSQL数据库存储非结构化数据。
### 2.1.3 结构化处理示例代码
下面是一个简单的代码示例,展示如何使用Python将零件的非结构化数据转换为结构化格式,并存入数据库。
```python
import json
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData
# 假设我们有一批非结构化的零件数据
unstructured_data = [
{"part_id": "1", "name": "gear", "material": "aluminum", "size": "M"},
{"part_id": "2", "name": "bolt", "material": "steel", "size": "S"}
]
# 将非结构化数据转换为结构化数据
structured_data = [json.loads(json.dumps(d)) for d in unstructured_data]
# 定义数据库连接和表结构
engine = create_engine('sqlite:///parts.db')
metadata = MetaData()
parts_table = Table('parts', metadata,
Column('part_id', Integer, primary_key=True),
Column('name', String),
Column('material', String),
Column('size', String))
# 创建表
metadata.create_all(engine)
# 存储结构化数据到数据库
with engine.connect() as connection:
for part in structured_data:
connection.execute(parts_table.insert(), part)
```
该代码通过创建一个SQLAlchemy表对象,并使用SQLite数据库存储零件信息。这些结构化的数据可以方便地进行查询和分析。
## 2.2 3D零件库的数据治理
### 2.2.1 数据质量管理
数据治理的核心是确保数据的准确性和可靠性。以下是数据质量管理的几个关键步骤:
- **数据清洗**:通过算法检测和修正错误的数据,例如使用正则表达式标准化零件名称。
- **数据一致性校验**:确保数据在各个阶段的一致性,包括数据的来源、存储和传输。
- **数据审计**:定期对数据进行质量审核,确保数据的准确性和完整性。
### 2.2.2 数据安全管理与合规性
3D零件库中存储了大量敏感数据,因此数据安全管理至关重要。这涉及到:
- **数据访问控制**:实现基于角色的访问控制(RBAC),限制对敏感数据的访问。
- **数据加密**:使用加密技术保护存储和传输中的数据。
- **合规性遵循**:确保遵守相关法律法规,如GDPR或HIPAA。
### 2.2.3 数据管理代码示例
以下是一个简单的数据管理脚本,用于更新零件库中的数据,并进行权限检查。
```python
from flask import Flask, request, jsonify, abort
from flask_httpauth import HTTPBasicAuth
app = Flask(__name__)
auth = HTTPBasicAuth()
# 模拟数据库
db = {
'parts': {
'1': {'name': 'gear', 'material': 'aluminum', 'size': 'M'},
'2': {'name': 'bolt', 'material': 'steel', 'size': 'S'}
}
}
# 用户权限
users = {
'admin': 'secret'
}
@auth.verify_password
def verify_password(username, password):
if username in users and users[username] == password:
return username
@app.route('/update-part', methods=['POST'])
@auth.login_required
def update_part():
if request.json is None or 'part_id' not in request.json:
abort(400)
part_id = request.json['part_id']
name = request.json.get('name', db['parts'][part_id]['name'])
material = request.json.get('material', db['parts'][part_id]['material'])
size = request.json.get('size', db['parts'][part_id]['size'])
db['parts'][part_id] = {'name': name, 'material': material, 'size': size}
return jsonify({'status': 'success', 'part_id': part_id})
if __name__ == '__main__':
app.run()
```
该脚本使用Flask框架和HTTP基本认证来限制对3D零件库数据的访问。用户需要通过认证才能更新零件数据。这只是一个简单的例子,实际部署时需要更复杂的权限管理和安全措施。
## 2.3 3D零件库的扩展技术
### 2.3.1 云计算技术的应用
云计算为3D零件库提供了可扩展的存储和计算资源。它允许3D零件库根据需求动态地进行资源分配和释放。云服务模型包括:
- **SaaS (Software as a Service)**:3D零件库作为服务提供给用户,无需本地部署。
- **PaaS (Platform as a Service)**:提供云平台和工具给开发者,以便构建和管理3D零件库。
- **IaaS (Infrastructure as a Service)**:提供虚拟化的计算资源,开发者可以自行搭建和管理零件库。
### 2.3.2 分布式存储解决方案
分布式存储解决方案可以提高数据的可靠性、可用性和扩展性。它允许3D零件库在多个物理位置存储数据副本,从而提供更好的容错能力。分布式存储的关键技术包括:
- **一致性哈希**:用于高效地管理和定位数据节点。
- **分布式文件系统**:如HDFS或Ceph,用于存储大量数据。
- **数据复制和分片**:通过数据复制保证数据安全,通过数据分片提高数据的访问效率。
### 2.3.3 云计算与分布式存储代码示例
下面是一个简化的Python脚本,演示如何使用Amazon S3服务和HDFS搭建一个简单的分布式文件系统来存储3D模型文件。
```python
from boto.s3.connection import S3Connection
import os
# 初始化S3连接
conn = S3Connection('access_key', 'secret_key')
bucket_name = 'my-3d-parts-library'
# 创建一个新的S3桶(如果它不存在)
if not conn.get_bucket(bucket_name):
conn.create_bucket(bucket_name)
# 假设我们有一个3D模型文件要上传
file_path = 'path/to/3d_model_file.stl'
with open(file_path, 'rb') as file_data:
conn.get_bucket(bucket_name).new_key('3d_model_file.stl').set_contents_from_file(file_data)
print(f"File {file_path} has been uploaded to bucket {bucket_name}")
```
此脚本使用了`boto`库,这是Python的Amazon Web Services (AWS) SDK。它首先检查一个指定的桶是否存在,如果不存在,则创建一个新的桶,并将文件上传到该桶中。在实际部署中,还需要考虑安全性、错误处理和数据完整性校验等更多因素。
### 2.3.4 云计算与分布式存储流程图
为了更直观地理解云计算和分布式存储在3D零件库中的应用,我们来看一个简化的流程图:
```mermaid
graph LR
A[用户上传3D模型文件] -->|通过API| B[负载均衡器]
B -->|数据请求| C[分布式文件系统]
C -->|文件存储| D1[存储节点1]
C -->|文件存储| D2[存储节点2]
C -->|文件存储| D3[存储节点3]
D1 -.->|数据同步| D2
D1 -.->|数据同步| D3
D2 -.->|数据同步| D3
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#ccf,stroke:#f66,str
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
3DSource零件库专栏深入探讨了3D零件库的各个方面,为工程师和设计师提供了全面指南。专栏涵盖了从性能优化到高效存储、扩展术到安全措施等广泛主题。
在"3D零件库性能优化"中,读者将了解设计原理,以提高数据检索效率。而"【深度解析】3D零件库高效存储"则揭示了优化查询性能的黄金法则。此外,"3D零件库扩展术"探讨了大数据时代下的增长应对策略,而"【安全先行】3DSource零件库"则提供了精通访问控制和数据加密的指南。
通过阅读3DSource零件库专栏,工程师和设计师可以掌握管理和利用3D零件库的最佳实践,从而提高设计效率、优化数据存储并确保数据安全。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VRAY渲染器细分曲面与多边形优化:110个术语与技巧,提升细节品质
参考资源链接:[VRAY渲染器关键参数中英文对照与详解](https://wenku.csdn.net/doc/2mem793wpe?spm=1055.2635.3001.10343)
# 1. VRAY渲染器基础知识
## VRAY渲染器简介
VRAY是目前最流行的渲染器之一,它用于生成高质量的三维图形。广泛应用于建筑可视化、游戏设计和电影制作等领域。VRAY使用光线追踪算法来生成照片级真实感的图像。
## 核心功能与技术
该渲染器的核心功能包括光线追踪、全局照明、散焦和运动模糊等。VRAY的技术优势在于其高度可定制性和强大的渲染算法,可以输出高质量的渲染结果。
## 入门操作指南
初
GWR 4.0负载均衡技术:实现系统负载均衡的8个关键技巧

参考资源链接:[GWR4.0地理加权回归模型初学者教程](https://wenku.csdn.net/doc/5v36p4syxf?spm=1055.2635.3001.10343)
# 1. GWR 4.0负载均衡技术概述
在信息技术日益成熟的今天,高并发、大数据量的网络应用已成常态。为满足苛刻的性能需求,负载均衡技术应运而生,它通过合理的资源分配,保证
【并行测试的秘密武器】:马头拧紧枪缩短回归周期的并行测试策略
参考资源链接:[Desoutter CVI CONFIG用户手册:系统设置与拧紧工具配置指南](https://wenku.csdn.net/doc/2g1ivmr9zx?spm=1055.2635.3001.10343)
# 1. 并行测试的基本概念
## 1.1 并行测试的定义
并行测试(Parallel Testing),顾
控制系统中的矩阵应用:技术与案例解读
参考资源链接:[《矩阵论》第三版课后答案详解](https://wenku.csdn.net/doc/ijji4ha34m?spm=1055.2635.3001.10343)
# 1. 矩阵理论基础
矩阵理论是数学的一个分支,它在现代科学技术中扮演着至关重要的角色,尤其在控制系统领域。理解矩阵理论的基础知识是深入研究矩阵在控制系统中应用的前提。本章将介绍矩阵的定义、分类、基本运算规则以及矩阵的特殊形式,如对角矩阵、单
图像处理新技术前沿:IMX385LQR与人工智能的完美融合
参考资源链接:[Sony IMX385LQR:高端1080P星光级CMOS传感器详解](https://wenku.csdn.net/doc/6412b6d9be7fbd1778d48342?spm=1055.2635.3001.10343)
# 1. IMX385LQR传感器的革新特性
IMX385LQR传感器自问世以来,就以其创新性特性在图像捕捉领域引发关注。该传感器搭载了先进的堆栈式CMOS设计,这种结构可以极大地提升光信号的转换效率,进而增强在各种光照条件下的成像质量。此外,IMX385LQR具备高速数据读取能力,它的高速接口技术使其能够快速处理大量图像数据,这对于需要实时捕捉和分析
PCAN-Explorer 5硬件配置详解:如何设置最佳硬件配置(实用、权威性)
参考资源链接:[PCAN-Explorer5全面指南:硬件连接、DBC操作与高级功能](https://wenku.csdn.net/doc/4af937hfmn?spm=1055.2635.3001.10343)
# 1. PCAN-Explorer 5概述与基本配置
在信息技术迅速发展的今天,汽车电子设备和工业
统计推断的可视化方法
参考资源链接:[统计推断(Statistical Inference) 第二版 练习题 答案](https://wenku.csdn.net/doc/6412b77cbe7fbd1778d4a767?spm=1055.2635.3001.10343)
# 1. 统计推断与可视化的关系
## 1.1 统计推断与可视化的桥梁作用
统计推断与可视化是数据分析中密不可分的两个环节。统计推断通过数学方法从样本数
I2C多主设备系统设计全攻略:架构与实现的高级技巧

参考资源链接:[I2C总线PCB设计详解与菊花链策略](https://wenku.csdn.net/doc/646c568a543f844488d076fd?spm=1055.2635.3001.10343)
# 1. I2C多主设备技术概述
## 1.1 I2C多主设备的必要性
I2C (Inter-Integrated Circuit) 是一种两线串行通信协
Modbus多主站配置管理:高级技术与策略指南
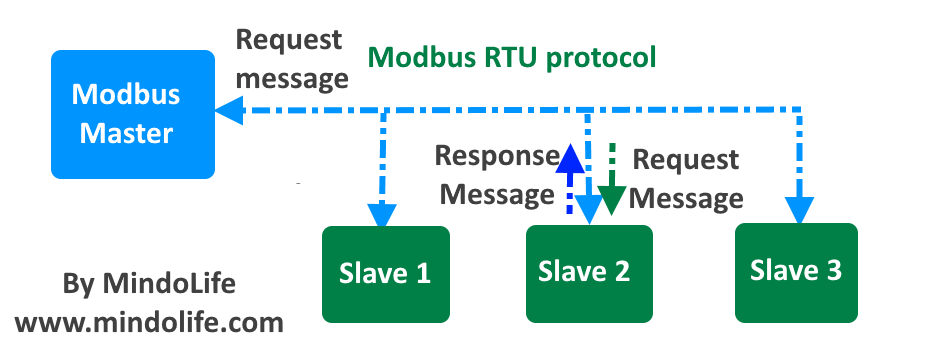
参考资源链接:[Modbus协议中文版【完整版】.pdf](https://wenku.csdn.net/doc/645f30805928463033a7a0fd?spm=1055.2635.3001.10343)
# 1. Modbus多主站概述与协议基础
## 1.1 Modbus协议的起源与发展
Modbus是一种开放的、应用广泛的工业通信协议,由Modicon公司在1979年提出。随着工业自动化的需求增长,
【ILI9341中文显示最佳实践】:界面设计与用户体验优化(专业建议)

参考资源链接:[ILI9341彩色LCD驱动模块中文使用手册](https://wenku.csdn.net/doc/6401abd2cce7214c316e9a1c?spm=1055.2635.3001.10343)
# 1. ILI9341显示屏基础知识回顾
ILI9341是一款广泛使用的TFT LCD控制器,其在许多小型显示模块中得到了应用,特别是在嵌入式系统和物联网设备中。了解ILI934
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )