【企业IT架构的核心】:IARE架构的10大关键组件和实践指南
发布时间: 2024-09-24 09:14:58 阅读量: 122 订阅数: 54 
# 1. IARE架构概述
在信息技术快速发展的今天,IARE架构(Integrated Architecture for Rapid Enterprise,集成快速企业架构)已经成为企业信息化建设的重要组成部分。IARE架构是为企业提供快速响应市场变化、灵活应对业务需求而设计的一种集成化架构模式。它将企业的各种信息系统整合在一起,通过模块化、服务化的组件,实现企业内部各业务单元之间的高效协同和快速迭代。
IARE架构不是单一的技术或工具,它是一个整体的概念,涉及数据层、应用层以及企业服务总线(ESB)等多个层面。它的设计思想强调灵活性、可扩展性和可维护性,目的是让企业在激烈的市场竞争中保持敏捷,快速适应外部变化。
在接下来的章节中,我们将详细解读IARE架构的关键组件、安全策略、高可用性设计、性能优化以及未来的发展趋势等各个方面,为IT从业者提供深入的理解和具体的实践指导。
# 2. IARE架构的关键组件解析
## 2.1 数据层组件
### 2.1.1 数据库管理系统
数据库管理系统(Database Management System, DBMS)是构建数据层组件的核心。在现代企业架构中,选择合适的DBMS至关重要,因为它直接影响到数据存储、查询性能、安全性和可扩展性。
**关键特性分析:**
- **事务处理能力**:DBMS需要支持ACID(原子性、一致性、隔离性、持久性)特性,确保数据的准确性和可靠性。
- **并发控制**:能够支持多用户同时访问,保证数据的一致性和系统的稳定性。
- **数据备份与恢复**:一个健壮的备份和恢复机制是任何企业级DBMS的必备,以应对数据丢失或系统故障的情况。
**常用DBMS对比:**
| 特性 | MySQL | PostgreSQL | Oracle |
| --- | --- | --- | --- |
| 事务支持 | 强 | 强 | 强 |
| 并发控制 | 优良 | 优良 | 最佳 |
| 开源 | 是 | 是 | 否 |
| 成本 | 低 | 低 | 高 |
| 平台支持 | 多 | 多 | 有限 |
**代码块示例:**
```sql
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
LastName VARCHAR(255),
FirstName VARCHAR(255),
BirthDate DATE,
HireDate DATE
);
```
*逻辑分析及参数说明:*
在此示例SQL代码中,我们定义了一个简单的员工表。表包含员工ID、姓、名、出生日期和雇佣日期等字段,并将`EmployeeID`字段设置为主键。选择适合的DBMS及编写有效的SQL语句是数据层组件设计的关键部分。
### 2.1.2 数据存储与备份策略
数据存储和备份策略是确保数据层高可用性和灾难恢复能力的关键组成部分。有效的数据备份策略可以防止数据丢失,而高效的数据存储机制可以提升数据访问速度。
**存储技术选择:**
- **传统存储:** 如硬盘驱动器(HDD),成本低,但速度相对较慢。
- **固态存储:** 如固态驱动器(SSD),读写速度快,但成本高。
- **云存储服务:** 提供弹性扩展能力,但对网络连接有依赖。
**备份策略:**
- **完全备份:** 定期备份全部数据,简单但占用大量存储空间。
- **差异备份:** 只备份自上次完全备份以来发生改变的数据,节省空间但恢复过程更复杂。
- **增量备份:** 仅备份自上次备份(完全、差异或增量)以来的更改数据,是最节省空间的方式。
**代码块示例:**
```bash
mysqldump -u username -p database_name > backup_file.sql
```
*逻辑分析及参数说明:*
上述代码块使用`mysqldump`工具备份MySQL数据库。参数`-u`后面跟数据库用户名,`-p`提示输入密码,`database_name`是需要备份的数据库名称,而`> backup_file.sql`则是输出备份文件的路径。这是最基础的数据备份方法,适用于多种备份策略的实施。
**mermaid流程图示例:**
```mermaid
graph LR
A[开始备份] --> B[选择备份类型]
B --> C[完全备份]
B --> D[差异备份]
B --> E[增量备份]
C --> F[备份全部数据]
D --> G[备份新旧数据差异]
E --> H[备份数据差异]
F --> I[存储备份文件]
G --> I
H --> I
I --> J[备份完成]
```
*流程图逻辑分析及说明:*
此流程图展示了选择不同备份类型后的操作流程。无论选择哪种备份策略,最终都会将备份文件存放到指定位置,以确保数据的安全性和在灾难发生时的快速恢复。在实施备份策略时,选择合适的工具和理解其背后的工作机制是至关重要的。
# 3. IARE架构的安全策略
## 3.1 网络安全
网络安全是保障IARE架构稳定运行的基石,涉及对内部网络、数据传输、远程访问等多个方面的防护。
### 3.1.1 防火墙与入侵检测系统
防火墙是网络安全的第一道防线,它通过定义访问控制策略,来阻止未经授权的访问,同时允许合法流量通过。随着网络威胁的不断增加,入侵检测系统(IDS)成为网络安全的重要组成部分,它能够在检测到潜在入侵行为时发出警报,并可与防火墙联动,及时封堵攻击源。
部署防火墙通常涉及以下关键步骤:
1. **需求分析**:确定架构需要保护的资源和安全需求。
2. **选择防火墙类型**:硬件防火墙或软件防火墙,选择合适的产品来满足性能和功能需求。
3. **配置安全策略**:定义规则集,用于允许或拒绝特定类型的流量。
4. **部署与测试**:在IARE架构的关键节点部署防火墙,并进行测试以确保策略有效。
5. **监控与维护**:持续监控防火墙日志,定期更新策略,以适应新的安全威胁。
入侵检测系统(IDS)的部署通常需要以下步骤:
1. **系统评估**:评估现有的网络架构,确定潜在的监控点。
2. **选择IDS产品**:根据性能、检测技术(如签名检测、异常检测等)、可管理性等因素选择合适的IDS。
3. **配置与测试**:配置检测规则和响应策略,并在隔离环境中进行测试。
4. **集成与部署**:将IDS集成到现有的安全架构中,并在生产环境中部署。
5. **定期审计与升级**:定期进行安全审计,及时升级检测签名库和系统。
以下是一个简单的配置命令示例,用于配置基于Linux的iptables防火墙规则:
```bash
# 启动iptables服务
service iptables start
# 允许所有出站流量
iptables -P OUTPUT ACCEPT
# 拒绝所有入站流量,然后逐一添加允许的规则
iptables -P INPUT DROP
# 允许本地回环接口(通常用于允许本机通信)
iptables -A INPUT -i lo -j ACCEPT
# 允许特定服务的端口,例如允许HTTPS(443端口)
iptables -A INPUT -p tcp --dport 443 -j ACCEPT
# 保存规则并重启iptables服务
service iptables save
service iptables restart
```
### 3.1.2 VPN与远程访问控制
虚拟私人网络(VPN)为远程用户提供了安全访问企业内部网络的手段。它通过加密数据传输,确保数据包在公共网络上的安全传输。VPN的实现多种多样,包括基于SSL/TLS的VPN、IPSec VPN等。每种实现方式都有其特点和适用场景。
VPN的部署步骤通常包括:
1. **确定VPN类型**:根据安全性、易用性、兼容性等因素确定使用哪种类型的VPN。
2. **配置VPN服务器**:设置VPN服务器,配置相应的认证和加密参数。
3. **配置客户端**:在用户设备上配置VPN客户端,以连接到VPN服务器。
4. **测试连接**:测试VPN连接的安全性和稳定性,确保远程访问安全可靠。
5. **维护和更新**:定期更新VPN服务器和客户端软件,修复已知的安全漏洞。
在Linux系统中,可以使用openvpn来搭建VPN服务。以下是配置openvpn的一个简化示例:
```bash
# 安装OpenVPN
apt-get install openvpn
# 创建证书和密钥(需要预先安装easy-rsa)
mkdir /etc/openvpn/easy-rsa/keys
cd /etc/openvpn/easy-rsa/
./easyrsa init-pki
./easyrsa build-ca
./easyrsa gen-req server nopass
./easyrsa sign-req server server
./easyrsa gen-req client nopass
./easyrsa sign-req client client
cp pki/ca.crt pki/issued/server.crt pki/private/server.key /etc/openvpn/server/
cp pki/ca.crt pki/issued/client.crt pki/private/client.key /etc/openvpn/client/
# 配置OpenVPN服务端
echo "port 1194
proto udp
dev tun
ca ca.crt
cert server.crt
key server.key
dh dh2048.pem
server **.*.*.***.***.***.*
ifconfig-pool-persist ipp.txt
keepalive 10 120
cipher AES-256-CBC
persist-key
persist-tun
status openvpn-status.log
verb 3
explicit-exit-notify 1" > /etc/openvpn/server.conf
# 配置OpenVPN客户端
echo "client
proto udp
remote my-server-1 1194
resolv-retry infinite
nobind
persist-key
persist-tun
remote-cert-tls server
cipher AES-256-CBC
verb 3
<ca>
-----BEGIN CERTIFICATE-----
-----END CERTIFICATE-----
</ca>
<cert>
-----BEGIN CERTIFICATE-----
-----END CERTIFICATE-----
</cert>
<key>
-----BEGIN PRIVATE KEY-----
-----END PRIVATE KEY-----
</key>" > /etc/openvpn/client.conf
# 启动OpenVPN服务
service openvpn start server
service openvpn start client
```
## 3.2 应用与数据安全
在保障了网络层面的安全之后,还需要针对应用程序和数据采取安全措施。
### 3.2.1 加密技术的应用
加密技术是保障数据安全的重要手段,能够防止数据在传输或存储过程中被未授权访问。在IARE架构中,数据加密通常发生在数据存储和传输两个层面。
- **存储加密**:对数据库中的敏感数据(如密码、支付信息等)进行加密存储。常见的做法包括对称加密和非对称加密,其中对称加密算法如AES,非对称加密算法如RSA。
- **传输加密**:使用SSL/TLS等协议对数据在互联网上的传输进行加密,确保数据在客户端和服务器之间的传输安全。例如,HTTPS协议在HTTP基础上加入了SSL/TLS来加密数据传输过程。
### 3.2.2 审计与监控机制
审计和监控机制用于记录和审查系统活动,以检测和响应异常行为。它们是追踪数据访问、操作和系统性能的重要工具。
- **日志管理**:收集、存储和分析安全相关的日志文件,比如访问日志、错误日志、系统日志等。日志管理系统还负责对日志文件进行归档和压缩。
- **入侵检测系统(IDS)和入侵防御系统(IPS)**:这两者通常基于已知的攻击模式和异常行为模式对系统进行监控,一旦检测到可疑活动,它们可以立即响应,采取措施阻止进一步的入侵尝试。
- **变更管理**:跟踪和记录系统变更历史,保证任何对系统或数据的修改都可以追溯,以防止非法或未授权的系统变更。
- **性能监控**:监控系统性能指标,如CPU、内存、磁盘I/O、网络流量等,以便于及时发现系统负载异常、资源瓶颈或其他可能影响系统性能的问题。
通过上述措施,可以在一定程度上保证IARE架构的安全性。然而,安全是一个持续的过程,需要根据最新的威胁情报和安全政策不断调整和优化安全策略。下一章将探讨IARE架构的高可用性设计,这是确保架构稳定性和可靠性的另一关键方面。
# 4. IARE架构的高可用性设计
## 4.1 负载均衡技术
### 4.1.1 负载均衡策略与工具
在追求无间断服务的IT环境中,负载均衡技术是实现高可用性不可或缺的一环。通过将传入的网络流量分散到多个服务器,负载均衡器可以防止任何单个服务器因处理过多请求而成为瓶颈。这样不仅可以提升整体的处理能力,还可以实现服务器的冗余,从而确保服务的连续性。
#### 负载均衡策略
负载均衡策略的实现可以基于多种不同的算法,比如轮询(Round Robin)、最少连接(Least Connections)和基于资源的策略(Resource-based)。轮询策略会依次将新的连接请求分发到下一个服务器,而最少连接策略则会将新的连接请求发送到当前活动连接最少的服务器。基于资源的策略会根据服务器的CPU、内存或其他资源使用情况动态分配请求。
#### 负载均衡工具
现代的负载均衡器可以是软件形式也可以是硬件形式,一些广泛使用的软件负载均衡器如HAProxy和Nginx提供了灵活的配置选项。硬件负载均衡器通常由像F5 Networks和Citrix这样的公司提供,它们提供了高性能和高可用性的解决方案。
```bash
# 示例:使用Nginx作为负载均衡器的配置片段
http {
upstream backend {
***;
***;
least_conn;
}
server {
listen 80;
location / {
proxy_pass ***
}
}
}
```
在上述Nginx配置中,定义了一个名为`backend`的上游服务器组,并配置了最少连接算法。任何经过代理的请求都会被转发到`backend`组中的服务器。
### 4.1.2 实现高可用性实例分析
为了深入理解负载均衡技术如何增强高可用性,我们可以分析一个实际的案例。以一个在线零售网站为例,该网站需要在大促销期间处理比平时高出数倍的用户流量。
#### 高可用性配置
在这个实例中,该网站部署了多台应用服务器,并通过负载均衡器来分配用户的请求。负载均衡器配置了健康检查机制,当检测到某台应用服务器出现故障时,它将自动将流量重定向到其他健康的服务器。此外,应用服务器都运行在云服务提供商的多个数据中心中,确保即使某一地理位置的数据中心发生故障,业务也能无缝切换到其他数据中心。
#### 监控与分析
实时监控服务如New Relic或Datadog被用来监控服务器的性能指标,如响应时间和系统负载。一旦指标超过预定阈值,系统管理员会收到警报,并可以采取相应措施。这种实时监控不仅有助于检测并解决问题,还可以用于分析系统的瓶颈,以进一步优化负载均衡策略。
```bash
# 示例:监控系统响应时间的代码片段
# 假设我们有一个监控服务的脚本库
monitoring_service.check_response_time(server_name)
```
上述代码片段调用了一个假设的`check_response_time`函数,用于检查名为`server_name`的服务器的响应时间是否在合理范围内。此函数可以根据配置定期执行,或者在负载均衡器检测到异常时触发。
## 4.2 灾难恢复与业务连续性计划
### 4.2.1 数据备份与恢复策略
灾难恢复计划的核心是确保数据的安全性和业务的连续性。有效的备份策略是灾难恢复的基础,它确保在数据丢失或损坏时能够迅速恢复。
#### 多层次备份策略
多层次备份策略包括全量备份、增量备份和差分备份。全量备份定期创建数据的完整副本,增量备份仅备份自上次备份以来更改的部分,而差分备份则备份自上次全量备份以来的所有更改。这种策略可以减少备份所需的时间和存储空间,同时确保数据可以被快速恢复。
#### 自动化备份流程
自动化备份流程是确保备份任务按时执行的最佳实践。这通常涉及使用定时任务(如cron作业)来触发备份脚本,并使用版本控制系统来管理备份文件。自动化工具如Bacula或Amanda可以帮助管理员轻松配置和管理备份过程。
```mermaid
graph LR
A[开始备份任务] --> B{检查数据完整性}
B -->|数据完整| C[执行增量备份]
B -->|数据损坏| D[执行全量备份]
C --> E[验证备份成功]
D --> E
E --> F[清理旧备份]
F --> G[备份日志记录]
```
在上述流程图中,备份任务首先检查数据的完整性。如果数据完整,就执行增量备份;如果数据损坏,则执行全量备份。备份完成后,系统会验证备份是否成功,然后清理旧备份,并记录备份日志。
### 4.2.2 灾难恢复演练与优化
灾难恢复计划成功的关键在于演练。通过定期进行灾难恢复演练,组织可以验证备份策略的有效性,发现潜在的缺陷,并优化恢复流程。
#### 定期演练
在灾难恢复演练中,模拟从硬件故障、数据损坏到数据中心完全宕机等不同灾难场景。演练的内容包括从备份中恢复数据,重启关键系统,以及验证应用程序和服务的功能完整性。
#### 演练后的优化
演练之后,重要的是回顾演练过程,分析所遇到的问题和瓶颈,并据此优化灾难恢复计划。任何发现的弱点都应该被记录下来,并在下一次演练之前进行修正。
```mermaid
graph LR
A[开始演练] --> B[备份数据]
B --> C[模拟灾难]
C --> D[恢复数据和系统]
D --> E[验证服务]
E --> F[记录演练结果]
F --> G[根据结果优化计划]
```
在该流程图中,灾难恢复演练开始于数据备份,然后模拟灾难场景,接着是数据和系统的恢复,以及服务的验证。演练结束后,记录所有结果并用于优化灾难恢复计划。
通过上述高可用性的策略和实践,IARE架构能够确保即使在面对硬件故障、网络攻击或不可抗力因素时,企业关键应用的持续运行和服务的快速恢复。这种对业务连续性的重视是现代IT架构成功的关键。
# 5. IARE架构的性能优化
在现代企业中,随着业务的快速扩张和IT系统复杂度的提升,IT架构的性能优化已经变得尤为重要。性能优化不仅仅是提升用户体验,更是为了确保业务的连续性和稳定性。在本章节中,我们将深入探讨如何通过性能监控与分析,以及性能调优实践,来优化IARE(Integrated Architecture for Rapid Enterprise)架构的整体性能。
## 5.1 性能监控与分析
### 5.1.1 性能指标和监控工具
为了确保IT架构的高性能,首先需要建立一套完善的性能监控机制。这包括定义关键性能指标(KPIs),比如响应时间、事务吞吐量、CPU和内存使用率等。这些指标能够帮助IT团队实时了解系统的运行状态。
常用的性能监控工具有:
- **New Relic:** 提供全面的服务器、应用、数据库性能监控服务。
- **Prometheus:** 开源监控解决方案,支持强大的数据查询语言。
- **SolarWinds:** 提供综合监控解决方案,特别适合大型网络监控。
### 5.1.2 性能瓶颈分析方法
性能瓶颈分析通常涉及以下步骤:
1. **数据收集**:使用监控工具收集系统运行数据。
2. **数据报告**:对收集的数据进行整理,并生成报告。
3. **瓶颈定位**:通过报告识别潜在的性能瓶颈。
4. **问题诊断**:进一步诊断瓶颈原因,可能是配置错误、硬件限制或其他问题。
5. **优化建议**:基于诊断结果提出针对性的优化建议。
性能瓶颈分析的常见工具和方法包括:
- **火焰图(Flame Graphs)**:可视化CPU使用情况。
- **A/B测试**:比较不同系统配置或代码修改对性能的影响。
- **压力测试工具**:如Apache JMeter,用于模拟高负载并分析性能表现。
## 5.2 性能调优实践
### 5.2.1 系统级性能优化
系统级性能优化包括了硬件资源的分配、操作系统参数的调整、网络配置优化等多个方面。以Linux系统为例,以下是一些常见的系统级性能优化措施:
```bash
# 修改文件描述符限制
ulimit -n 10240
# 开启TCP/IP网络优化参数
echo "net.ipv4.tcp_tw_recycle = 1" >> /etc/sysctl.conf
sysctl -p
```
#### 参数说明:
- `ulimit -n` 设置每个进程可以打开的最大文件数。
- `net.ipv4.tcp_tw_recycle = 1` 开启TCP时间戳复用,加快TCP连接的回收速度。
### 5.2.2 应用代码性能优化
应用层的性能优化是提高整个IT架构性能的关键。从编写高效代码到使用高效的算法和数据结构,再到应用缓存策略,每一个环节都至关重要。
以下是一个使用缓存来优化数据检索性能的代码示例:
```python
from functools import lru_cache
@lru_cache(maxsize=128)
def calculate fibonacci(n):
if n < 2:
return n
return calculate(n-1) + calculate(n-2)
# 调用函数计算Fibonacci数
result = calculate(50)
```
#### 逻辑分析:
- `lru_cache` 装饰器用于实现最少最近使用(Least Recently Used)缓存机制。
- `maxsize` 参数定义了缓存的最大大小。
通过缓存计算结果,可以显著提高性能,特别是在需要重复计算的场景下。
总结这一章节,性能优化是一个系统工程,需要从硬件、操作系统、网络配置和应用代码等多个层面进行综合考虑。通过对性能指标的实时监控和分析,结合具体的系统和应用调优,IARE架构可以实现更为高效和稳定的性能表现。在下一章节中,我们将探讨IARE架构的安全策略,这是确保企业IT系统稳定运行的另一大支柱。
# 6. IARE架构的未来趋势与挑战
随着技术的不断发展,IARE架构也在不断地演化以适应新的业务需求和技术环境。本章节将深入探讨新兴技术对IARE架构的影响,以及持续交付和DevOps在架构中的实践。
## 6.1 新兴技术的影响
### 6.1.1 云计算与IARE架构的融合
云计算已经成为IT行业的一个重要趋势。对于IARE架构来说,云计算提供了极大的灵活性和扩展性,能够有效地应对不断变化的业务需求。在IARE架构中融合云计算主要体现在以下几个方面:
- **资源按需分配**:云计算平台可以根据实际需求动态分配计算资源,降低企业在硬件资源上的投资。
- **服务化模型**:SaaS(软件即服务)、PaaS(平台即服务)和IaaS(基础设施即服务)为IARE架构提供了全新的部署和服务交付方式。
- **弹性伸缩能力**:云平台能够根据负载自动调整资源,保证应用的高性能和高可用性。
### 6.1.2 大数据与实时分析的要求
随着数据量的爆炸性增长,大数据技术对于IARE架构的重要性日益凸显。架构师需要考虑到如何在保证数据实时性和分析效率的同时,整合和处理大量数据。关键点包括:
- **数据集成**:高效的数据集成技术能够处理多种数据源,满足实时分析的需求。
- **分布式计算**:采用分布式计算框架(如Hadoop和Spark)处理大规模数据集,保证数据处理的性能和可靠性。
- **实时数据流处理**:使用流处理框架(如Apache Kafka和Apache Flink)对实时数据进行快速响应和分析。
## 6.2 持续交付与DevOps
### 6.2.1 持续集成/持续部署(CI/CD)的实践
持续集成/持续部署(CI/CD)是现代软件开发中不可或缺的一部分,它能够确保应用代码的快速迭代和部署。在IARE架构中实现CI/CD的实践包括:
- **自动化构建与测试**:自动化工具(如Jenkins、Travis CI)能够在代码提交后自动执行构建和测试流程,确保代码质量。
- **版本控制策略**:采用Git等现代版本控制系统管理代码变更,支持分支策略和代码审查机制。
- **部署自动化**:将部署流程自动化(如使用Ansible、Chef或Puppet),减少人为错误,提高部署效率。
### 6.2.2 DevOps文化与组织变革
DevOps不仅仅是一套工具和流程的集合,它更是一种文化,要求开发和运维团队紧密合作,共同负责产品的整个生命周期。在组织中推动DevOps文化变革的关键因素有:
- **跨部门沟通与合作**:打破传统孤岛,鼓励跨职能团队的沟通和协作,确保项目顺利进行。
- **持续学习与改进**:建立持续反馈和改进机制,不断优化工作流程和工具,提升整体效率。
- **工具链的整合**:整合开发、运维工具形成自动化工具链,减少手工操作,提高工作效率。
## 6.3 未来展望
面对快速变化的业务和技术环境,IARE架构的未来将更加注重灵活性和适应性。新兴技术如AI、物联网(IoT)和边缘计算将与IARE架构相结合,带来新的发展机遇。同时,组织文化、人员技能和流程的持续优化将是架构师和IT管理者不断追求的目标。
在下一章节,我们将详细探讨如何具体实现云计算与IARE架构的融合,以及如何在企业内推广和实践持续交付和DevOps文化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
IARE 专栏深入探讨了信息架构参考模型 (IARE) 在企业数字化转型中的关键作用。它提供了一系列全面的文章,涵盖了 IARE 在数据保护、物联网、IT 性能优化、业务敏捷性、架构升级、安全、监控和日志分析、事件驱动架构以及自动化流程中的最佳实践和策略。通过深入的案例研究和技术见解,该专栏旨在帮助企业充分利用 IARE,以提高效率、增强安全性并推动数字化创新。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
极端事件预测:如何构建有效的预测区间
# 1. 极端事件预测概述
极端事件预测是风险管理、城市规划、保险业、金融市场等领域不可或缺的技术。这些事件通常具有突发性和破坏性,例如自然灾害、金融市场崩盘或恐怖袭击等。准确预测这类事件不仅可挽救生命、保护财产,而且对于制定应对策略和减少损失至关重要。因此,研究人员和专业人士持
【实时系统空间效率】:确保即时响应的内存管理技巧

# 1. 实时系统的内存管理概念
在现代的计算技术中,实时系统凭借其对时间敏感性的要求和对确定性的追求,成为了不可或缺的一部分。实时系统在各个领域中发挥着巨大作用,比如航空航天、医疗设备、工业自动化等。实时系统要求事件的处理能够在确定的时间内完成,这就对系统的设计、实现和资源管理提出了独特的挑战,其中最为核心的是内存管理。
内存管理是操作系统的一个基本组成部
学习率对RNN训练的特殊考虑:循环网络的优化策略

# 1. 循环神经网络(RNN)基础
## 循环神经网络简介
循环神经网络(RNN)是深度学习领域中处理序列数据的模型之一。由于其内部循环结
激活函数理论与实践:从入门到高阶应用的全面教程

# 1. 激活函数的基本概念
在神经网络中,激活函数扮演了至关重要的角色,它们是赋予网络学习能力的关键元素。本章将介绍激活函数的基础知识,为后续章节中对具体激活函数的探讨和应用打下坚实的基础。
## 1.1 激活函数的定义
激活函数是神经网络中用于决定神经元是否被激活的数学函数。通过激活函数,神经网络可以捕捉到输入数据的非线性特征。在多层网络结构
时间序列分析的置信度应用:预测未来的秘密武器
# 1. 时间序列分析的理论基础
在数据科学和统计学中,时间序列分析是研究按照时间顺序排列的数据点集合的过程。通过对时间序列数据的分析,我们可以提取出有价值的信息,揭示数据随时间变化的规律,从而为预测未来趋势和做出决策提供依据。
## 时间序列的定义
时间序列(Time Series)是一个按照时间顺序排列的观测值序列。这些观测值通常是一个变量在连续时间点的测量结果,可以是每秒的温度记录,每日的股票价
【算法竞赛中的复杂度控制】:在有限时间内求解的秘籍
# 1. 算法竞赛中的时间与空间复杂度基础
## 1.1 理解算法的性能指标
在算法竞赛中,时间复杂度和空间复杂度是衡量算法性能的两个基本指标。时间复杂度描述了算法运行时间随输入规模增长的趋势,而空间复杂度则反映了算法执行过程中所需的存储空间大小。理解这两个概念对优化算法性能至关重要。
## 1.2 大O表示法的含义与应用
大O表示法是用于描述算法时间复杂度的一种方式。它关注的是算法运行时
Epochs调优的自动化方法
# 1. Epochs在机器学习中的重要性
机器学习是一门通过算法来让计算机系统从数据中学习并进行预测和决策的科学。在这一过程中,模型训练是核心步骤之一,而Epochs(迭代周期)是决定模型训练效率和效果的关键参数。理解Epochs的重要性,对于开发高效、准确的机器学习模型至关重要。
在后续章节中,我们将深入探讨Epochs的概念、如何选择合适值以及影响调优的因素,以及如何通过自动化方法和工具来优化Epochs的设置,从而
【损失函数与随机梯度下降】:探索学习率对损失函数的影响,实现高效模型训练

# 1. 损失函数与随机梯度下降基础
在机器学习中,损失函数和随机梯度下降(SGD)是核心概念,它们共同决定着模型的训练过程和效果。本
机器学习性能评估:时间复杂度在模型训练与预测中的重要性
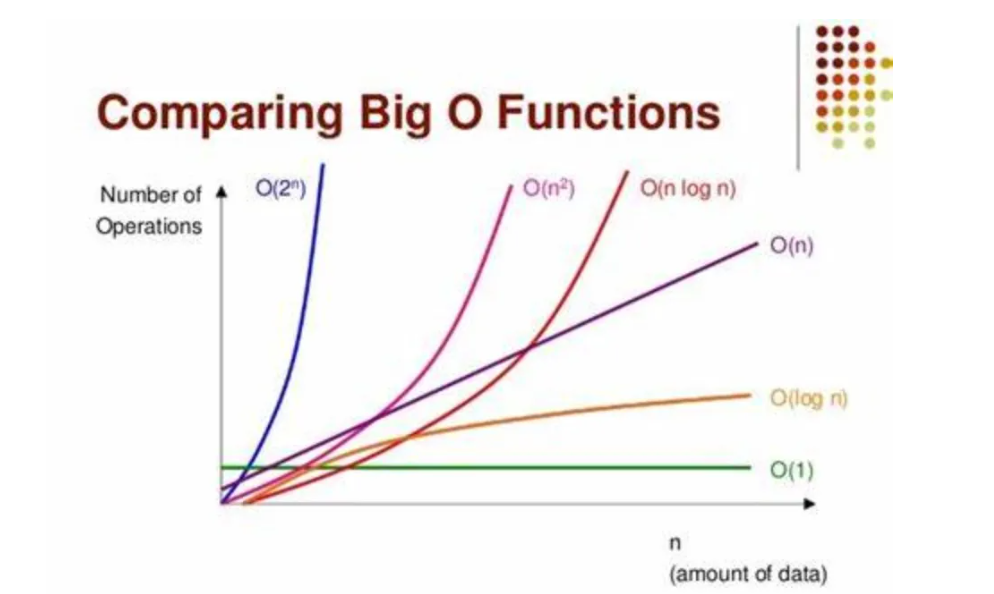
# 1. 机器学习性能评估概述
## 1.1 机器学习的性能评估重要性
机器学习的性能评估是验证模型效果的关键步骤。它不仅帮助我们了解模型在未知数据上的表现,而且对于模型的优化和改进也至关重要。准确的评估可以确保模型的泛化能力,避免过拟合或欠拟合的问题。
## 1.2 性能评估指标的选择
选择正确的性能评估指标对于不同类型的机器学习任务至关重要。例如,在分类任务中常用的指标有
【批量大小与存储引擎】:不同数据库引擎下的优化考量

# 1. 数据库批量操作的理论基础
数据库是现代信息系统的核心组件,而批量操作作为提升数据库性能的重要手段,对于IT专业人员来说是不可或缺的技能。理解批量操作的理论基础,有助于我们更好地掌握其实践应用,并优化性能。
## 1.1 批量操作的定义和重要性
批量操作是指在数据库管理中,一次性执行多个数据操作命
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )