【R语言全方位入门指南】:从零开始的分析师成长之路
发布时间: 2024-11-06 05:17:03 阅读量: 25 订阅数: 44 

基于遗传算法的动态优化物流配送中心选址问题研究(Matlab源码+详细注释),遗传算法与免疫算法在物流配送中心选址问题的应用详解(源码+详细注释,Matlab编写,含动态优化与迭代,结果图展示),遗传
# 1. R语言基础知识概览
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。它是S语言的现代实现,并在数据科学社区中广泛流行。本章节将为读者提供R语言的基础知识概览,包括R语言的历史、安装步骤以及一些核心概念。
## 1.1 R语言简介
R语言起源于1990年代早期,由新西兰奥克兰大学的Ross Ihaka和Robert Gentleman合作开发。R语言以其强大的社区支持、丰富多样的包以及在数据科学领域的广泛应用而闻名。R语言尤其擅长统计分析,提供了各种统计测试、线性建模和时间序列分析的工具。
## 1.2 R语言的安装
要在计算机上安装R语言,可以通过R语言官方网站下载适合您操作系统的安装包。在安装过程中,建议同时下载RStudio IDE,这是一款流行的R语言集成开发环境,可以帮助用户更高效地编写和管理R代码。
```r
# 安装R语言的R代码示例
install.packages("utils")
```
## 1.3 R语言的核心概念
在使用R语言之前,需要理解几个核心概念:**对象**、**函数**和**包**。R语言是面向对象的,意味着它操作的是对象,包括向量、矩阵、数据框等数据结构。函数是执行特定任务的代码块,而包是包含一组函数和数据集的集合,用于扩展R语言的功能。
通过这一章的内容,读者将对R语言有一个初步的了解,并为后续章节的深入学习打下坚实的基础。
# 2. R语言编程基础
## 2.1 R语言的数据结构
### 2.1.1 向量、矩阵、数组的基本操作
R语言中,数据结构是进行数据处理的基础。其中,向量、矩阵和数组是最常用的基本数据结构。
向量是R语言中最基本的数据结构,可以存储数值型、字符型或逻辑型数据。创建向量可以使用`c()`函数,例如:
```R
vec <- c(1, 2, 3, 4, 5)
```
矩阵是具有相同数据类型元素的二维数组,通过`matrix()`函数创建:
```R
mat <- matrix(c(1, 2, 3, 4, 5, 6), nrow=2, ncol=3)
```
数组是多维的数据结构,由`array()`函数创建:
```R
arr <- array(c(1:12), dim=c(2, 3, 2))
```
理解向量、矩阵和数组的结构对后续的数据处理至关重要。向量操作主要涉及元素选择、运算和函数应用。矩阵和数组的操作则包括维度操作、索引选择、转置等。
### 2.1.2 数据框和列表的使用
数据框(DataFrame)是R语言中一种特殊的数据结构,用于存储表格数据,其中每一列可以是不同的数据类型。
创建数据框可以使用`data.frame()`函数:
```R
df <- data.frame(
name = c("Alice", "Bob", "Charlie"),
score = c(90, 85, 95)
)
```
列表(List)是R语言中可以包含不同类型和结构的数据的容器,允许包含不同长度和类型的元素。
创建列表可以使用`list()`函数:
```R
lst <- list(
name = c("Alice", "Bob", "Charlie"),
score = c(90, 85, 95),
details = list(
age = c(20, 21, 19),
gender = c("Female", "Male", "Male")
)
)
```
数据框和列表的使用需要理解它们结构的灵活性,以及如何通过索引访问和修改数据。
## 2.2 R语言的函数和模块
### 2.2.1 函数定义与调用
R语言中的函数是组织代码和进行计算的重要工具。函数定义使用`function()`关键字,调用则是通过函数名加括号进行。
定义一个函数示例如下:
```R
addTwoNumbers <- function(x, y) {
return(x + y)
}
```
调用这个函数:
```R
sum <- addTwoNumbers(5, 7)
print(sum) # 输出:12
```
函数在R中是“一等公民”,这意味着它们可以作为参数传递给其他函数,也可以作为返回值从函数中返回。
### 2.2.2 包和模块的安装与管理
R语言的强大功能部分得益于其庞大的包库,这些包可以安装到R环境中用于特定的数据处理任务。
安装包可以使用`install.packages()`函数:
```R
install.packages("dplyr")
```
加载包则使用`library()`或`require()`函数:
```R
library(dplyr)
```
R中的包管理是进行数据分析、统计建模和可视化的基础。通过熟悉包的安装、更新、卸载和加载,可以有效地管理和维护R环境。
## 2.3 R语言的数据输入输出
### 2.3.1 读取和保存数据集
数据的输入输出(I/O)是数据分析的重要环节。R语言提供了多种读取和保存数据的方法。
读取数据,例如从CSV文件中读取数据:
```R
data <- read.csv("data.csv", header = TRUE)
```
保存数据,例如将数据框保存为CSV文件:
```R
write.csv(data, "output_data.csv", row.names = FALSE)
```
读取和保存数据需要考虑数据的格式、路径和参数设置。R语言支持多种文件格式,包括但不限于CSV、Excel、JSON和SQL数据库。
### 2.3.2 数据导入导出的格式转换
R语言中数据导入导出的格式转换涉及不同数据类型的转换。例如,读取Excel文件使用`readxl`包,保存为RData格式使用`save()`函数:
```R
data <- read_excel("data.xlsx", sheet = "Sheet1")
save(data, file = "data.RData")
```
格式转换还包括数据类型的改变,比如字符型向量转换为数值型:
```R
numVec <- as.numeric(c("1", "2", "3"))
```
数据导入导出和格式转换是数据处理流程中不可或缺的部分,理解它们可以提高数据处理的效率和灵活性。
以上介绍了R语言编程基础中的数据结构、函数和模块以及数据输入输出的基本操作,为后续的数据处理和分析打下坚实的基础。
# 3. R语言数据处理实战
## 3.1 数据清洗与预处理
### 3.1.1 缺失数据处理
数据清洗是数据分析中不可或缺的一环,而处理缺失数据是数据清洗中的一个核心问题。在R语言中,我们可以通过多种方法来识别和处理缺失值。最简单的识别方法是使用`is.na()`函数,它可以判断数据框中的元素是否为NA。
```r
# 创建一个包含缺失值的数据框
data <- data.frame(
x = c(1, 2, NA, 4, 5),
y = c(NA, 2, 3, 4, 5)
)
# 识别数据框中的缺失值
missing_values <- is.na(data)
```
R语言提供了多种处理缺失数据的函数,比如使用`na.omit()`可以删除含有缺失值的行:
```r
# 删除含有缺失值的行
clean_data <- na.omit(data)
```
此外,我们也可以用`complete.cases()`来识别完全数据行,并通过逻辑索引来筛选:
```r
# 保留完全数据行
complete_data <- data[complete.cases(data), ]
```
在某些情况下,我们可能需要估算缺失数据。常用的估算方法包括均值、中位数和众数等。R中我们可以使用`mean()`、`median()`或`mode()`函数(注意R语言中`mode()`函数并不直接计算众数,需自定义函数)来实现这一点。
```r
# 使用均值填充缺失数据
data$y[is.na(data$y)] <- mean(data$y, na.rm = TRUE)
```
处理缺失数据的策略要根据具体的数据集和分析目标来决定,没有统一的标准。某些情况下,缺失值本身就携带了信息,可能需要保留并进行进一步分析。
### 3.1.2 数据转换和归一化
数据转换和归一化是数据预处理的另一个重要方面。在R语言中,我们可以通过数据转换来改变数据的分布形态,而归一化则将数据缩放到一定的范围,如0到1之间。
对于数据转换,常用的转换包括对数转换、平方根转换等。例如,对数转换可以减轻数据中的偏态:
```r
# 对数据进行对数转换
transformed_data <- log(data$x + 1)
```
归一化则是将数据缩放到一个特定的范围,R语言中的`scale()`函数能够实现这一目标:
```r
# 归一化数据框中的数值型变量
normalized_data <- scale(data)
```
归一化后的数据通常对大多数机器学习算法效果较好,因为它可以防止某些数值较大的特征对结果产生不成比例的影响。
## 3.2 数据探索性分析
### 3.2.1 描述性统计分析
描述性统计分析是理解数据特征的重要手段。在R中,我们可以使用多种函数来进行描述性统计分析,例如`summary()`、`mean()`、`median()`、`sd()`(标准差)和`var()`(方差)等。
```r
# 统计分析数据框中的数值型变量
summary(data)
mean(data$x)
median(data$x)
sd(data$x)
var(data$x)
```
`summary()`函数提供了一个关于数据的快速概览,包括最小值、第一四分位数、中位数、均值、第三四分位数和最大值。这对于初步评估数据特征非常有用。
### 3.2.2 数据可视化技巧
数据可视化是探索性分析中的一个关键组成部分。R语言提供了强大的图形绘制包`ggplot2`。使用`ggplot2`,我们可以创建各种各样的图表,如直方图、箱线图、散点图等。
```r
# 创建直方图
library(ggplot2)
ggplot(data, aes(x)) +
geom_histogram(bins = 30, fill = "steelblue") +
theme_minimal()
# 创建箱线图
ggplot(data, aes(y = y)) +
geom_boxplot(fill = "lightgreen") +
theme_minimal()
```
`ggplot2`遵循“图形语法”的原则,通过组合图层(如`geom_histogram()`和`geom_boxplot()`)来创建图形。它不仅提供了美观的图形,而且能够直观地展示数据分布特征。
## 3.3 数据子集与合并
### 3.3.1 数据筛选与排序
在进行数据分析时,常常需要根据特定条件筛选数据子集。在R语言中,可以使用`subset()`函数或逻辑索引来筛选数据:
```r
# 使用subset函数筛选数据
subset_data <- subset(data, x > 2)
# 使用逻辑索引筛选数据
filtered_data <- data[data$x > 2, ]
```
排序操作则可以使用`order()`函数或`sort()`函数,`order()`返回排序后的索引,而`sort()`直接返回排序后的向量。
```r
# 使用order函数进行排序
sorted_data <- data[order(data$x), ]
# 使用sort函数进行排序
sorted_values <- sort(data$x)
```
在数据筛选和排序的基础上,我们还可以对数据进行进一步的操作,例如计算分组统计量。
### 3.3.2 数据集的合并与连接操作
数据合并和连接是数据分析中常见的操作。例如,当我们有两个相关的数据集时,我们可能需要根据某一个共同的键值将它们合并。
```r
# 创建另一个数据框以便合并
other_data <- data.frame(
y = c(1, 3, 5, 7, 9),
z = c("a", "b", "c", "d", "e")
)
# 合并两个数据框,按y列进行连接
merged_data <- merge(data, other_data, by = "y")
```
R中`merge()`函数提供了灵活的方式来根据一个或多个键值合并数据框。此外,`cbind()`函数可以按列合并数据框,而`rbind()`函数可以按行合并。
```r
# 按列合并数据框
combined_by_column <- cbind(data, other_data)
# 按行合并数据框
combined_by_row <- rbind(data, other_data)
```
在数据集合并时,需要特别注意数据的一致性和完整性。数据类型和行数都应该对齐,否则可能会出现数据错位的情况。在进行复杂的数据处理时,适当的预处理和数据类型转换是必要的步骤。
# 4. R语言统计分析和机器学习
## 4.1 基本统计分析方法
### 4.1.1 常见统计测试
统计测试是数据分析过程中的核心组成部分,用于从数据中提取有用信息,进行假设检验。在R语言中,可以使用多个内置函数来执行各种统计测试。比如,当我们需要判断两组数据是否存在显著差异时,可以使用t检验(t-test)。下面的代码展示了如何使用t.test函数来检验两组数据的均值是否存在统计学上的显著差异:
```r
# 生成两组随机数据
group1 <- rnorm(50, mean = 100, sd = 10)
group2 <- rnorm(50, mean = 110, sd = 10)
# 使用t检验
result_t_test <- t.test(group1, group2)
# 打印结果
print(result_t_test)
```
以上代码首先创建了两组正态分布的随机数据`group1`和`group2`,然后使用`t.test`函数进行均值差异的t检验。最后,打印出t检验的结果。在结果中,我们将查看p值来判断两组数据的均值是否有统计学上的显著差异。通常情况下,如果p值小于0.05,我们认为两组数据均值存在显著差异。
### 4.1.2 相关性和回归分析
在统计学中,相关性分析用于探究两个或多个变量之间的关系强度。R语言提供了`cor`函数来计算变量之间的相关系数,而`lm`函数可以用来执行线性回归分析。
```r
# 假设我们有两组变量x和y
x <- c(1, 2, 3, 4, 5)
y <- c(2, 3.9, 6.1, 8, 10)
# 计算相关系数
correlation <- cor(x, y)
cat("The correlation coefficient is:", correlation)
# 线性回归分析
linear_model <- lm(y ~ x)
summary(linear_model)
```
此例中,`cor`函数计算了向量x和y的相关系数,而`lm`函数构建了y对x的线性回归模型,并使用`summary`函数来获取回归分析的详细结果。相关系数和线性模型的参数估计及统计检验结果,可以揭示变量之间的相关性和依赖性。
## 4.2 机器学习算法应用
### 4.2.1 常用机器学习模型简介
R语言不仅在统计学中有所应用,它也支持众多的机器学习算法,可以用于分类、回归、聚类等任务。常用的一些包如`caret`、`e1071`等,提供了对多种机器学习模型的支持。
下面介绍几种基本的机器学习模型,以及如何使用R语言实现它们:
- 线性回归:已在4.1.2节提及。
- 逻辑回归:用于二分类问题。
- 支持向量机(SVM):用于分类和回归任务。
- 决策树:用于分类和回归分析。
- 随机森林:通过集成多个决策树提高预测精度。
### 4.2.2 模型训练与验证
在机器学习任务中,模型的训练和验证是至关重要的。R语言中包含了一些用于划分数据集的函数,以及评估模型性能的指标,比如准确率、召回率等。下面是如何使用`caret`包来训练一个模型,并进行交叉验证的示例:
```r
library(caret)
# 划分训练集和测试集
set.seed(123)
trainingIndex <- createDataPartition(y, p = 0.75, list = FALSE)
trainingData <- x[trainingIndex,]
testingData <- x[-trainingIndex,]
# 训练模型,这里以逻辑回归为例
model <- glm(y ~ x, data = trainingData, family = binomial)
# 预测和评估模型
predictions <- predict(model, testingData, type = "response")
predictions_class <- ifelse(predictions > 0.5, 1, 0)
# 创建一个混淆矩阵来评估模型性能
confusionMatrix(as.factor(predictions_class), as.factor(testingData$y))
```
在这个例子中,我们首先使用`createDataPartition`函数划分数据集,并确保结果可复现(通过设置`set.seed`)。然后,使用`glm`函数建立一个逻辑回归模型,并通过`predict`函数进行预测。最后,我们构建了一个混淆矩阵来计算模型的准确率、召回率等指标。
## 4.3 高级分析技术
### 4.3.1 时间序列分析
时间序列分析是处理和分析按时间顺序排列的数据点的方法。它在预测未来趋势和行为、评估政策制定的影响等方面至关重要。R语言提供了丰富的函数和包用于时间序列分析,如`forecast`包。
```r
library(forecast)
# 假设我们有一段时间序列数据
ts_data <- ts(c(112, 118, 132, 129, 121, 135, 148, 148, 136, 119, 104, 118), frequency = 12)
# 对时间序列数据进行分解分析
decomposed_ts <- decompose(ts_data)
# 绘制分解图
plot(decomposed_ts)
```
此代码展示了如何使用`decompose`函数对时间序列数据进行趋势、季节性和随机波动的分解,并通过`plot`函数绘制分解图。
### 4.3.2 文本分析基础
文本分析是从文本数据中提取信息和洞察的过程,R语言中也有多个包可以进行文本分析,例如`tm`包。
```r
library(tm)
# 假设我们有一段文本数据
text_data <- c("R语言是一种优秀的统计分析工具", "它广泛应用于数据科学领域")
# 创建一个文本挖掘语料库
corpus <- Corpus(VectorSource(text_data))
# 文本预处理:转换为小写、去除标点符号、停用词
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeWords, stopwords("en"))
# 创建词频矩阵
tdm <- TermDocumentMatrix(corpus)
m <- as.matrix(tdm)
word_freqs <- sort(rowSums(m), decreasing = TRUE)
dm <- data.frame(word = names(word_freqs), freq = word_freqs)
# 打印词频统计结果
print(dm)
```
此示例中,`Corpus`函数创建了一个语料库对象,然后进行了一系列文本预处理步骤,包括转换为小写、去除标点符号和停用词。之后,创建了一个词频矩阵并将其转换为数据框,最后打印出最常见的词汇及其频率。
以上内容详细介绍了R语言在统计分析和机器学习领域的基本使用方法,包括统计测试、相关性和回归分析、常用机器学习模型、模型训练与验证以及高级分析技术。通过实际的代码演示和逻辑分析,展示了如何在R语言中执行复杂的统计和机器学习任务。
# 5. R语言在数据分析领域的应用案例
## 5.1 金融分析的实战演练
在金融分析领域,数据的力量是巨大的。通过运用R语言,分析师可以构建复杂的风险评估模型、优化投资组合,甚至可以进行算法交易策略的开发。接下来,我们将深入探讨这一领域内一些具体的应用案例。
### 5.1.1 风险评估模型构建
风险评估模型是金融分析的核心之一。利用R语言,我们可以方便地实现这些模型,并对金融资产的风险进行量化。例如,我们可以使用R语言的`PerformanceAnalytics`包来进行资产的风险-回报分析。
```r
# 安装并加载PerformanceAnalytics包
install.packages("PerformanceAnalytics")
library(PerformanceAnalytics)
# 假设我们有一个资产收益数据框df_returns
# 计算资产的风险-回报指标
chart.RiskReturnScatter(df_returns)
```
该代码将帮助我们绘制资产的风险-回报散点图,从而直观地评估不同资产的风险和回报表现。此外,我们还可以使用`rugarch`包来构建更复杂的金融时间序列风险评估模型,比如GARCH模型。
### 5.1.2 投资组合优化
投资组合优化是另一个金融领域的重要应用。我们可以利用R语言来计算有效前沿,以及应用不同的优化算法来找到最优的投资组合权重。
以下是使用`portfolio.optim`函数实现Markowitz投资组合优化的示例:
```r
# 安装并加载tseries包
install.packages("tseries")
library(tseries)
# 假设我们有资产收益数据框df_portfolios和相应风险权重df_risks
# 进行投资组合优化
portfolio.optim(df_returns, pm = 0.01, shorts = TRUE)
```
该函数会返回在给定预期收益率下最小化风险的投资组合权重。通过这种方式,我们可以构建符合特定风险偏好和收益目标的投资组合。
## 5.2 生物统计的应用
R语言在生物统计领域同样大有用武之地。它不仅提供了丰富的统计分析工具,还支持各种生物信息学和基因组学数据的分析。
### 5.2.1 基因表达数据分析
基因表达数据分析需要处理大量的基因数据,以识别与特定疾病或生物过程相关的基因。R语言提供了如`limma`这样的包来进行微阵列数据的分析。
```r
# 安装并加载limma包
install.packages("limma")
library(limma)
# 假设我们有微阵列数据框df_microarray
# 使用limma进行数据分析
design <- model.matrix(~df_microarray$group)
fit <- lmFit(df_microarray, design)
eb <- eBayes(fit)
```
上述代码通过构建线性模型并应用经验贝叶斯方法,帮助我们识别出在不同实验条件之间表达差异显著的基因。
### 5.2.2 临床试验数据处理
在临床试验中,R语言可用于数据清洗、统计分析,以及生成临床试验报告。例如,我们可以使用`survival`包来分析生存时间数据。
```r
# 安装并加载survival包
install.packages("survival")
library(survival)
# 假设我们有生存时间数据框df_survival
# 进行生存分析
surv_obj <- Surv(time=df_survival$time, event=df_survival$status)
cox_fit <- coxph(surv_obj ~ df_survival$age + df_survival$sex)
```
代码中的`coxph`函数用于拟合Cox比例风险模型,这在评估不同变量对生存时间影响的研究中非常有用。
## 5.3 市场营销分析
在市场营销领域,R语言能够帮助我们对客户数据进行深入分析,从而识别客户群体、预测销售趋势等。
### 5.3.1 客户细分与聚类分析
通过对客户行为数据进行聚类分析,我们可以将客户分成不同的群体,进而实现更加个性化的营销策略。
```r
# 安装并加载cluster包
install.packages("cluster")
library(cluster)
# 假设我们有客户行为数据框df_customers
# 使用k-means聚类算法进行客户细分
set.seed(123) # 设置随机种子以获得可重复的结果
kmeans_fit <- kmeans(df_customers, centers=3)
```
上述代码将客户数据分为三个聚类中心,我们可以基于这些分群结果对客户进行细分并制定营销策略。
### 5.3.2 预测模型在销售预测中的应用
销售预测对于企业决策至关重要。R语言中的多种预测模型可以帮助我们准确预测未来的销售情况。
```r
# 安装并加载forecast包
install.packages("forecast")
library(forecast)
# 假设我们有历史销售时间序列数据框df_sales
# 使用ARIMA模型进行销售预测
arima_fit <- auto.arima(df_sales)
forecasted_sales <- forecast(arima_fit, h=12) # 预测未来12个月的销售情况
```
通过上述代码,我们可以构建一个自回归积分滑动平均(ARIMA)模型来预测未来一段时间内的销售情况,这对于库存管理和销售策略调整非常有用。
通过本章节的讨论,我们可以看到R语言在数据分析应用中的多面性。无论是在金融、生物统计还是市场营销领域,R都提供了强大的工具集来执行深度分析和决策支持。以上案例只是冰山一角,真正强大的是掌握这些工具和方法来解决实际问题的能力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供全面的 R 语言学习指南,涵盖从入门到高级的各个方面。专栏内容包括:
* 环境搭建:打造专属的数据分析工作站。
* 核心操作:高效处理向量和矩阵。
* 数据包使用:安装和使用常用数据包。
* 函数编写:从自定义函数到高级应用。
* 数据清洗:巧妙清除数据杂质。
* 统计分析:掌握数据集的基本统计技巧。
* 图形绘制:从基础到高级的可视化技术。
* 数据处理捷径:使用 tidyverse 包简化流程。
* 回归分析:构建简单到多元回归模型。
* 优化问题:深入 optim 包的秘藏技巧。
* 时间序列分析:预测和处理时间数据。
* 机器学习:使用 caret 包打造预测模型。
* 文本分析:从基础到情感分析的完整流程。
* 高维数据分析:主成分分析(PCA)的精妙应用。
* 网络分析:构建和分析复杂网络关系。
* 并发编程:使用 parallel 包提升数据处理效能。
* 数据库连接:连接 MySQL、PostgreSQL 等数据库。
* Web 开发:使用 shiny 包构建交互式应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ILWIS3.8空间分析功能全解析】:深度解读与应用案例

# 摘要
本文全面介绍ILWIS 3.8在空间分析领域的应用和功能。首先概述了ILWIS 3.8的空间分析框架及其基础功能和数据管理能力,包括对空间数据格式的支持、图层的创建与编辑,以及空间数据库的管理。接着深入探讨了ILWIS 3.8的核心空间分析功能,如缓冲区分析、网络分析与路径规划、地统计分析与地形模型,以及土地覆盖分类与变化检测技术。随后,文章通过应用实践章节展示了ILWIS 3.8
【Nextcloud深度剖析】:Windows服务器上的安装、优化与故障处理案例
# 摘要
Nextcloud作为一个开源的云存储解决方案,为用户提供了在私有服务器上存储和分享文件的平台。本文首先介绍了Nextcloud的基本概念及安装流程,然后详细探讨了其配置与管理,包括配置文件结构、用户权限设置以及应用扩展和集成。接着,本文着重分析了Nextcloud的性能优化方法,包括性能监控、调优、高可用性部署以及缓存与存储优化。在安全加固与故障排查章节,文章讨论了
【Python编程提升指南】:掌握AssimpCy,高效处理3D模型的10大技巧

# 摘要
本文主要探讨了Python编程在3D模型处理中的应用,特别是通过AssimpCy库实现的高效加载、变换和渲染。文章首先介绍了3D图形编程的基本概念及其在Python中的应用,随后详细阐述了AssimpCy库的安装、配置和核心数据结构解析。在此基础
【测量平差程序的优化】:性能提升与资源管理的高效策略
# 摘要
本文概述了测量平差程序优化的重要性,并深入探讨了相关理论基础与算法优化。首先,分析了平差问题的数学模型和最小二乘法的应用,然后对算法效率进行了理论分析,着重于计算复杂度和精度与效率之间的权衡。高效算法设计包括矩阵运算优化和迭代与直接算法的选择。在性能优化实践方面,探讨了代码级优化策略、多线程与并行计算的应用以及性能测试与评估。资源管理与优化章节则涵盖了内存管理、数
【Hybrid TKLBIST问题速解】:5大常见难题,一步到位的解决方案

# 摘要
Hybrid TKLBIST是一种结合了传统测试技术与现代测试方法的综合测试框架,它的基本概念、理论基础、常见难题以及实践应用是本文的研究重点。本文首先介绍了Hybrid TKLBIST的定义、原理及核心测试方法论,
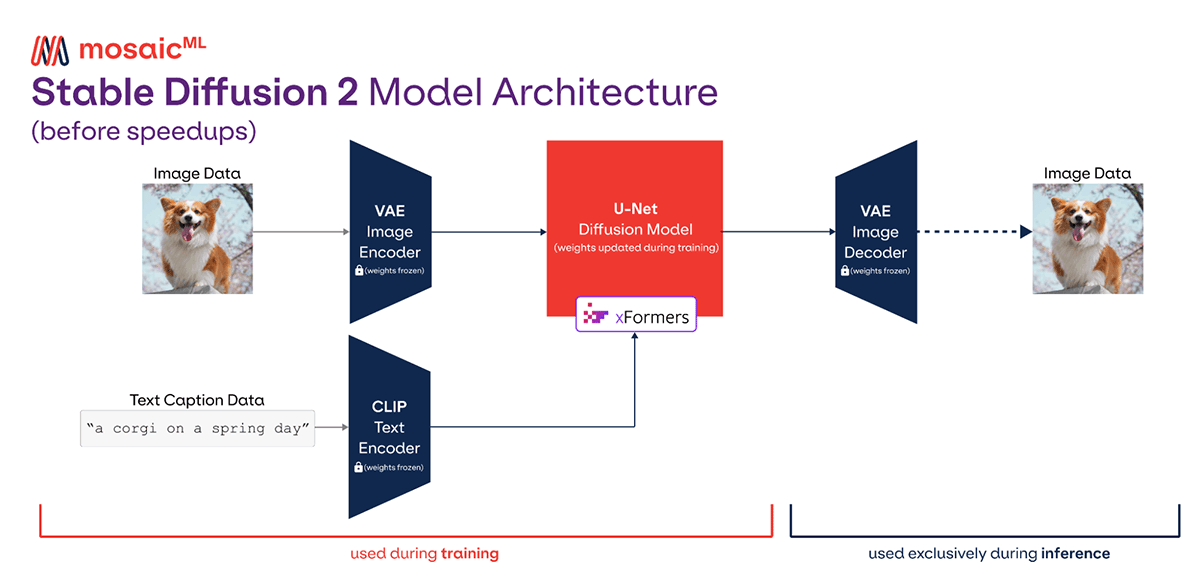
【Stable Diffusion参数调优宝典】:专家级别的调整与优化
# 摘要
Stable Diffusion模型作为一种深度学习生成模型,广泛应用于图像和文本生成等领域。本文旨在全面概述Stable Diffusion模型的基本概念、参数体系及调优技术。文章首先介绍了Stable Diffusion的结构与调优基础,然后深入探讨了其参数体系,包括参数的定义、类型和调优过程中的理论基础,如梯
项目时间管理新策略:华为无线搬迁案例中的WBS应用详解
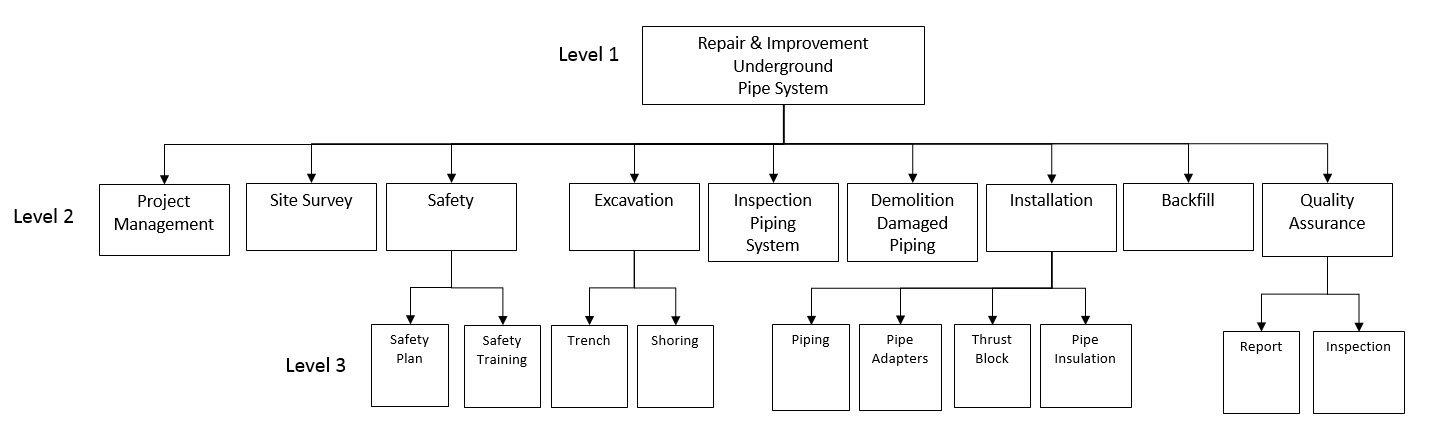
# 摘要
本文通过项目时间管理的理论基础探讨,详细阐述了WBS(工作分解结构)的概念、重要性、创建原则以及技巧,并将这些理论应用于华为无线搬迁案例中。通过对项目背景与目标的介绍,分析了搬迁项目的复杂性,并具体说明了如何设计WBS结构,结合时间计划,并进行跟踪和控制。文中还分析了项目时间管理的改进成果和WBS应用的深入分析。最后,针对WBS策略的优化与未来发展趋势进行了
【C#实践指南】:如何高效处理DXF文件数据
# 摘要
C#作为一门流行的应用程序开发语言,在处理DXF(Drawing Exchange Format)文件数据方面展现出了强大的功能。本文旨在介绍和分析C#在DXF文件数据处理中的各种技术和方法。通过深入探讨DXF文件格式、分析现有处理库和工具,并提供具体的编程实践,文章展示了从读取、编辑到高级应用的完整处理流程。本文还包含了案例研究,分析了真实世界中的需求、实现策略以及问题解决,旨在为开发者提供宝贵的经验和见解。文章的最后展望了未来技术趋势,
【信号完整性保障】:多输入时序电路信号完整性维护技巧

# 摘要
信号完整性是高性能电子系统设计中的关键因素,直接影响到电路的稳定性和性能。本文首先介绍了信号完整性的重要性和基本概念,然后深入探讨了信号完整性的理论基础,包括信号传输线效应、串扰以及电源噪声等问题。接着,本文分析了多输入时序电路面临的信号完整性挑战,并提出了相应的布线策略。第四章讨论了信号完整性维护的技术实践,涉及测试与仿真方法以及问题调试。文章进一步阐述了信号完整
【程控交换软件故障快速诊断】:用户摘挂机识别异常的检测与即时修复指南

# 摘要
程控交换软件故障的快速诊断对于确保通信系统稳定运行至关重要。本文概述了程控交换软件故障快速诊断的方法与实践应用,详细探讨了用户摘挂机识别异常的理论基础、检测技术、即时修复方法,并分析了这些异常对通话质量与系统性能的影响。文章进一步阐述了检测工具与流程的实现、常见异常的检测实例以及软件和硬件层面的修复策略。在实践应用方面,提供了现场与远程故
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )