【并发集合的性能调优】:针对不同场景优化ConcurrentHashMap参数
发布时间: 2024-10-22 05:29:17 阅读量: 4 订阅数: 5 
# 1. 并发集合的基本概念
## 1.1 并发编程的挑战
在现代IT系统中,高并发处理是衡量系统性能的重要指标之一。传统的集合操作在面对多线程环境时往往会遇到线程安全问题,这会导致数据竞争、死锁、饥饿等问题,从而严重影响程序的稳定性和效率。因此,对并发集合的需求应运而生。
## 1.2 并发集合的定义
并发集合是为了应对多线程环境下数据操作而设计的集合类型,它们能够提供线程安全的操作。与普通的集合类不同,它们内部采用了各种锁机制、无锁编程、原子操作等技术来保障线程安全,同时尽量减少锁的竞争来提升性能。
## 1.3 常见的并发集合类
Java中的并发集合主要包括`ConcurrentHashMap`、`CopyOnWriteArrayList`、`BlockingQueue`等。`ConcurrentHashMap`作为并发集合中的一个典型代表,因其高效的并发读写性能和灵活的API,在实际开发中应用广泛。接下来的章节将深入探讨`ConcurrentHashMap`的原理和用法。
# 2. 深入理解ConcurrentHashMap
### 2.1 ConcurrentHashMap的数据结构
#### 2.1.1 Segment分段锁机制
在多线程环境下,为了保证并发性能,ConcurrentHashMap引入了分段锁(Segmentation)的概念。分段锁是一种将数据分组的技术,每组数据都有一个独立的锁。这种设计降低了锁的竞争程度,从而提高了系统的并发处理能力。在Java 8之前的版本中,ConcurrentHashMap被分为16个Segment,每个Segment拥有自己的锁。
这种设计使得ConcurrentHashMap能够在不完全锁定整个Map的情况下进行操作,这样就可以支持多线程并发地读取,同时还能保证写入时的线程安全。
接下来,我们将通过代码块和逻辑分析来说明Segment分段锁的实现方式。
```java
// 以下代码模拟了Segment分段锁机制的基本实现思路
// 此段代码仅为示意,非实际ConcurrentHashMap代码
// 假设有一个Segment数组,每个Segment代表一个分段
Segment[] segments = new Segment[16];
// Segment类实现包含自己的锁和哈希表
class Segment extends ReentrantLock {
// 存储数据的哈希表
HashTable table;
// 锁定操作,只锁定需要操作的Segment
void lock() { /* 锁定逻辑 */ }
void unlock() { /* 解锁逻辑 */ }
}
// put操作
void put(K key, V value) {
// 计算key的哈希值,确定要锁定的Segment
int hash = hash(key);
int index = hash % segments.length;
segments[index].lock();
try {
// 在锁定的Segment上执行put操作
segments[index].table.put(key, value);
} finally {
segments[index].unlock();
}
}
```
在上述代码中,我们定义了一个Segment数组,每个Segment对象都有自己的锁。put操作时,通过计算key的哈希值来决定需要锁定哪个Segment,仅对那个Segment加锁,这样其它的Segment可以不受影响地被其他线程操作。这种分而治之的策略有效地降低了锁的竞争。
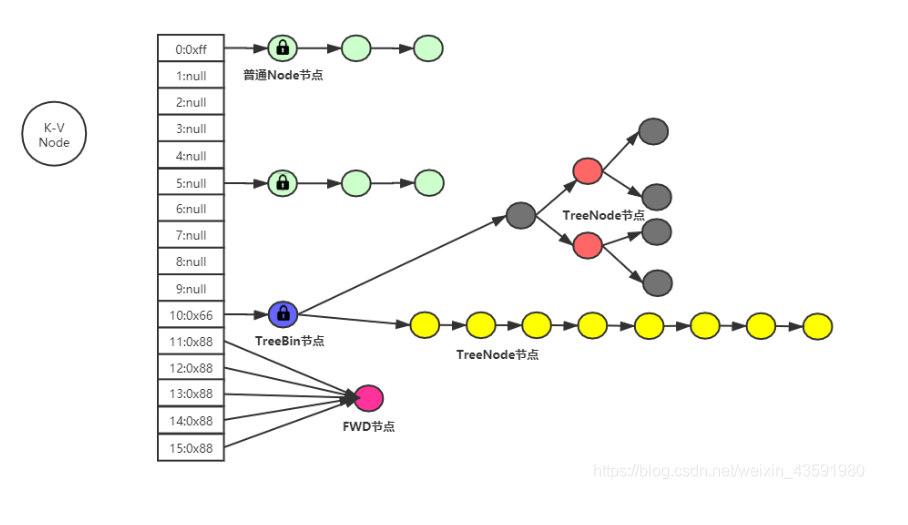
#### 2.1.2 节点(Node)的设计
在Java 8及之后的版本中,ConcurrentHashMap的实现有了一些变化,不再使用Segment分段锁,而是采用了Node数组加红黑树的组合结构来存储数据。每个Node节点代表了ConcurrentHashMap中的一个键值对。
每个Node节点包含四个属性:hash、key、value和next。其中next是一个指向下一个具有相同哈希值的Node节点的引用。这种结构支持了更高的并发度,因为除了首节点外,其他相同哈希值的节点的插入、删除操作可以并行处理,不会相互阻塞。
下面是Node节点的一个简单代码示例,用于展示其基本结构:
```java
// Node节点定义
class Node<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
}
```
Node节点的使用减少了锁的粒度,相比于Java 8之前的Segment锁机制,这种设计在大部分情况下能提供更好的性能,尤其是在数据分布均匀时。
### 2.2 ConcurrentHashMap的核心操作
#### 2.2.1 put操作的并发实现
put操作是ConcurrentHashMap中最常见的操作之一。ConcurrentHashMap通过一种称为"无锁化"的技术实现了put操作的高并发。下面的代码将解释put操作的具体实现和并发策略:
```java
// put操作方法的示例
V put(K key, V value) {
return putVal(key, value, false);
}
// putVal方法定义了详细的put操作逻辑
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 空槽位直接放入新节点
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
```
在putVal方法中,如果遇到

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Go中间件CORS简化攻略:一文搞定跨域请求复杂性
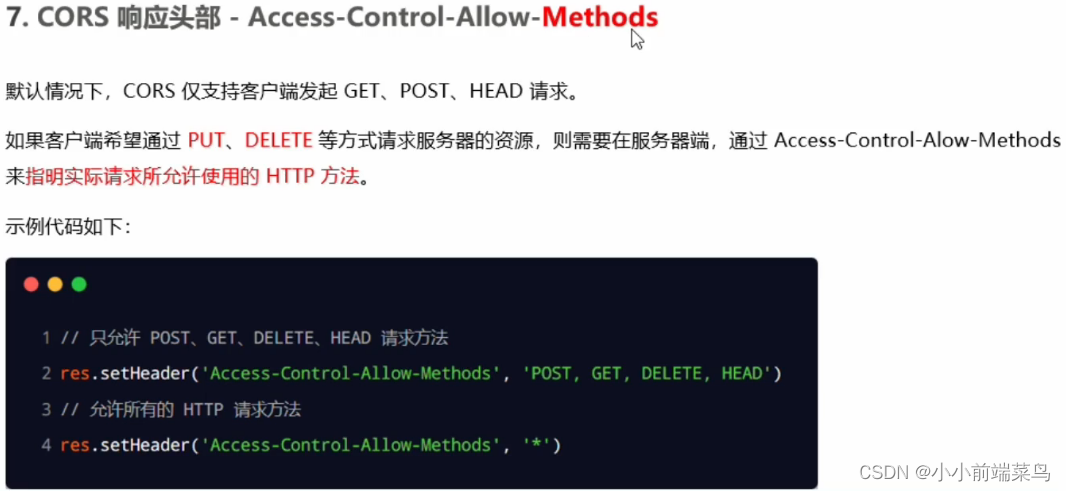
# 1. 跨域资源共享(CORS)概述
跨域资源共享(CORS)是Web开发中一个重要的概念,允许来自不同源的Web页面的资源共享。CORS提供了一种机制,通过在HTTP头中设置特定字段来实现跨域请求的控制。这一机制为开发者提供了灵活性,但同时也引入了安全挑战。本章将为读者提供CORS技术的概览,并阐明其在现代Web应用中的重要性。接下来,我们会深入探讨CORS的工作原理以及如何在实际的开发中运用这一技术
C++14 std::make_unique:智能指针的更好实践与内存管理优化

# 1. C++智能指针与内存管理基础
在现代C++编程中,智能指针已经成为了管理内存的首选方式,特别是当涉及到复杂的对象生命周期管理时。智能指针可以自动释放资源,减少内存泄漏的风险。C++标准库提供了几种类型的智能指针,最著名的包括`std::unique_ptr`, `std::shared_ptr`和`std::weak_ptr`。本章将重点介绍智能指针的基本概念,以及它
Go语言自定义错误类型与测试:编写覆盖错误处理的单元测试
# 1. Go语言错误处理基础
在Go语言中,错误处理是构建健壮应用程序的重要部分。本章将带你了解Go语言错误处理的核心概念,以及如何在日常开发中有效地使用错误。
## 错误处理理念
Go语言鼓励显式的错误处理方式,遵循“不要恐慌”的原则。当函数无法完成其预期工作时,它会返回一个错误值。通过检查这个
C++17模板变量革新:模板编程的未来已来
# 1. C++17模板变量的革新概述
C++17引入了模板变量,这是对C++模板系统的一次重大革新。模板变量的引入,不仅简化了模板编程,还提高了编译时的类型安全性,这为C++的模板世界带来了新的活力。
模板变量是一种在编译时就确定值的变量,它们可以是任意类型,并且可以像普通变量一样使用。与宏定义和枚举类型相比,模板变量提供了更强的类型检查和更好的代码可读性。
在这一章中,我们将首先回顾C++模板的历史和演进,然后详细介绍
【配置管理实用教程】:创建可重用配置模块的黄金法则
# 1. 配置管理的概念和重要性
在现代信息技术领域中,配置管理是保证系统稳定、高效运行的基石之一。它涉及到记录和控制IT资产,如硬件、软件组件、文档以及相关配置,确保在复杂的系统环境中,所有的变更都经过严格的审查和控制。配置管理不仅能够提高系统的可靠性,还能加快故障排查的过程,提高组织对变化的适应能力。随着企业IT基础设施的不断扩张,有效的配置管理已成为推动IT卓越运维的必要条件。接
C#日志记录经验分享:***中的挑战、经验和案例
# 1. C#日志记录的基本概念与必要性
在软件开发的世界里,日志记录是诊断和监控应用运行状况的关键组成部分。本章将带领您了解C#中的日志记录,探讨其重要性并揭示为什么开发者需要重视这一技术。
## 1.1 日志记录的基本概念
日志记录是一个记录软件运行信息的过程,目的是为了后续分析和调试。它记录了应用程序从启动到执行过程中发生的各种事件。C#中,通常会使用各种日志框架来实现这一功能,比如NLog、Log4Net和Serilog等。
## 1.2 日志记录的必要性
日志文件对于问题诊断至关重要。它们能够提供宝贵的洞察力,帮助开发者理解程序在生产环境中的表现。日志记录的必要性体现在以下
【掌握Criteria API动态投影】:灵活选择查询字段的技巧

# 1. Criteria API的基本概念与作用
## 1.1 概念介绍
Criteria API 是 Java Persistence API (JPA) 的一部分,它提供了一种类型安全的查询构造器,允许开发人员以面向对象的方式来编写数据库查询,而不是直接编写 SQL 语句。它的使用有助于保持代码的清晰性、可维护性,并且易于对数据库查询进行单
【Java Spring AOP必备攻略】:掌握面向切面编程,提升代码质量与维护性
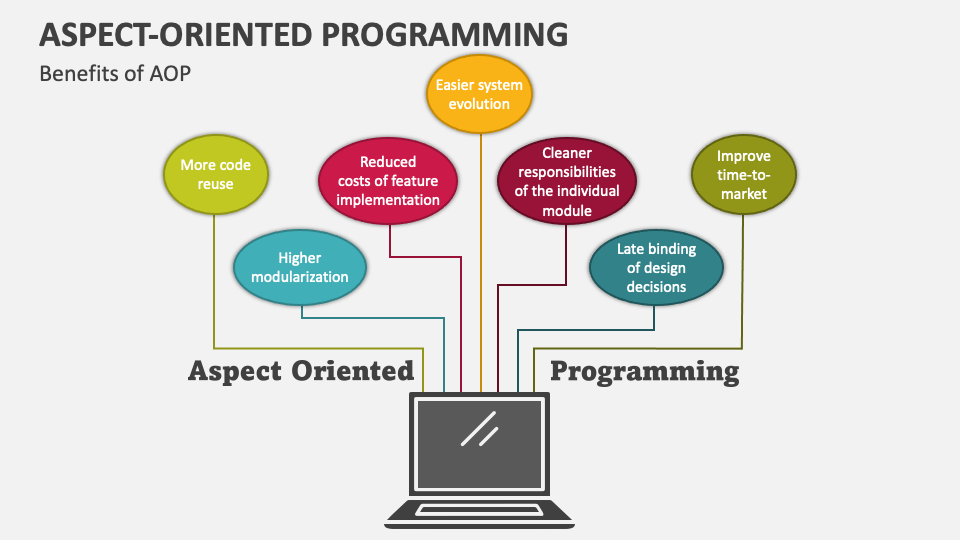
# 1. Spring AOP核心概念解读
## 1.1 AOP简介
面向切面编程(Aspect-Oriented Programming,简称AOP),是作为面向对象编程(OOP)的补充而存在的一种编程范式。它主要用来解决系统中分布于不同模块的横切关注点(cross-cutting concerns),比如日志、安全、事务管理等。AOP通过提供一种新的模块化机制,允许开发者定义跨
***模型验证性能优化:掌握提高验证效率的先进方法
# 1. 模型验证性能优化概述
在当今快节奏的IT领域,模型验证性能优化是确保应用和服务质量的关键环节。有效的性能优化不仅能够提升用户体验,还可以大幅度降低运营成本。本章节将概述性能优化的必要性,并为读者提供一个清晰的优化框架。
## 1.1 优化的必要性
优化的必要性不仅仅体现在提升性能,更关乎于资源的有效利用和业务目标的实现。通过对现有流程和系统进行细致的性能分析,我
代码重构与设计模式:同步转异步的CompletableFuture实现技巧
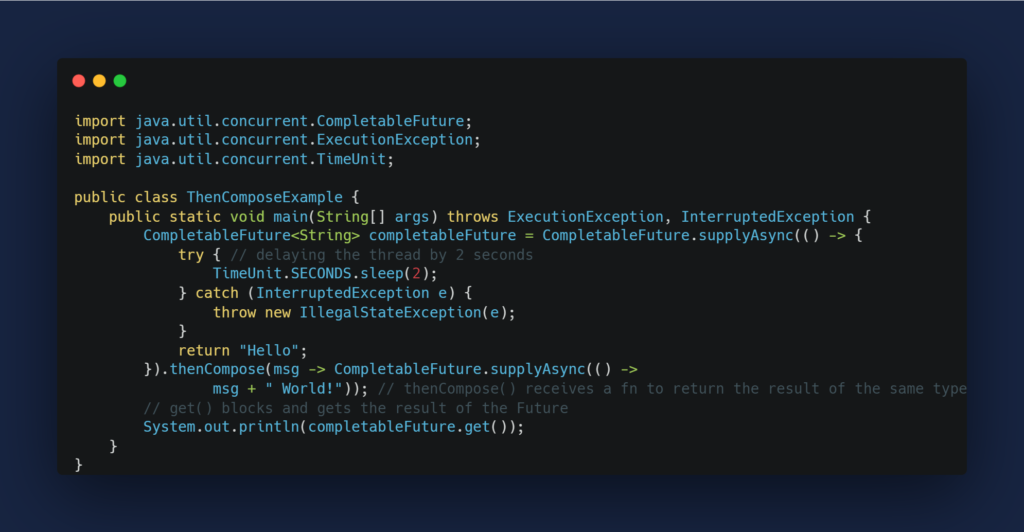
# 1. 代码重构与设计模式基础
在当今快速发展的IT行业中,软件系统的维护和扩展成为一项挑战。通过代码重构,我们可以优化现有代码的结构而不改变其外部行为,为软件的可持续发展打下坚实基础。设计模式,作为软件工程中解决特定问题的模板,为代码重构提供了理论支撑和实践指南。
## 1.1 代码重构的重要性
重构代码是软件开发生命周期中不
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )