Elasticsearch数据库ID获取策略:从文档ID到滚动查询
发布时间: 2024-07-28 14:46:24 阅读量: 37 订阅数: 45 
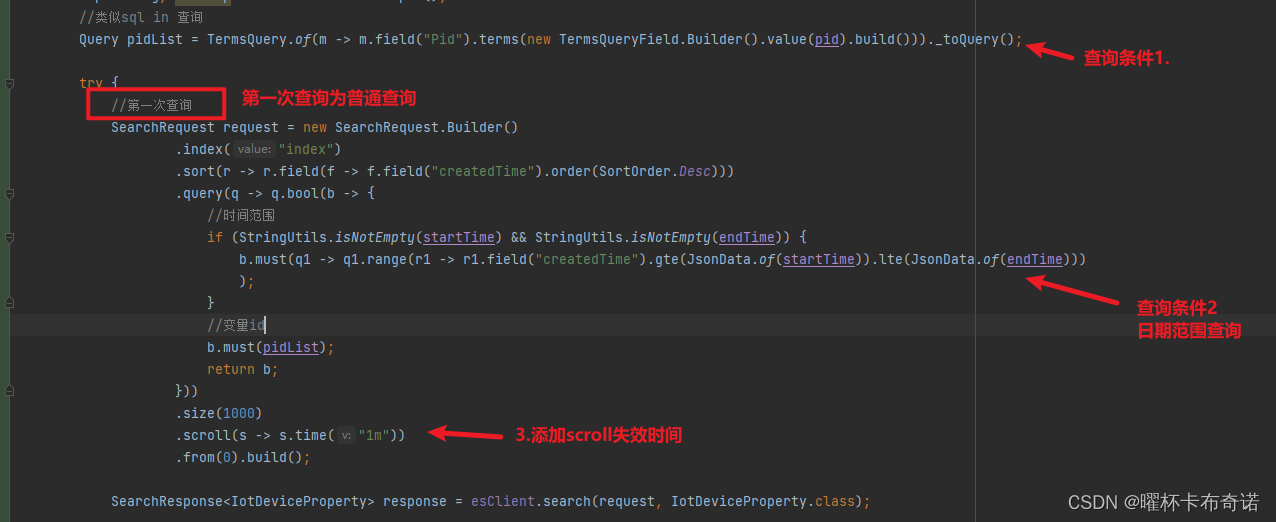
# 1. Elasticsearch数据库ID获取概述**
Elasticsearch中的文档ID是唯一标识符,用于识别和检索特定文档。ID获取策略决定了如何从Elasticsearch数据库中获取文档ID。本章将概述Elasticsearch ID获取策略,包括其定义、用途和不同策略的类型。
# 2. 文档ID获取策略**
**2.1 文档ID的定义和用途**
Elasticsearch中的文档ID是唯一标识符,用于识别集群中特定文档。它是一个字符串,可以由用户指定或由Elasticsearch自动生成。文档ID对于以下目的至关重要:
- **文档检索:**通过文档ID,可以快速检索特定文档。
- **数据更新:**文档ID用于更新或删除现有文档。
- **数据分析:**文档ID可用于连接不同索引中的文档,进行数据分析和聚合。
**2.2 通过_id参数获取文档ID**
获取文档ID最简单的方法是使用`_id`参数。此参数允许用户指定要检索的文档的ID。例如,以下查询将检索具有ID为`1`的文档:
```
GET /my-index/my-type/_doc/1
```
如果文档ID不存在,则查询将返回404错误。
**代码逻辑分析:**
- `GET`:HTTP请求方法,用于检索资源。
- `/my-index/my-type/_doc/1`:请求路径,其中`my-index`是索引名称,`my-type`是类型名称,`1`是文档ID。
**参数说明:**
- `_id`:指定要检索的文档ID。
**2.3 通过_doc参数获取文档ID**
另一种获取文档ID的方法是使用`_doc`参数。此参数将返回文档的内部ID,该ID由Elasticsearch自动生成。例如,以下查询将检索具有内部ID为`1`的文档:
```
GET /my-index/my-type/_doc/1/_source
```
**代码逻辑分析:**
- `GET`:HTTP请求方法,用于检索资源。
- `/my-index/my-type/_doc/1/_source`:请求路径,其中`my-index`是索引名称,`my-type`是类型名称,`1`是内部文档ID,`_source`用于检索文档的源数据。
**参数说明:**
- `_doc`:指定要检索的文档的内部ID。
# 3. 滚动查询获取ID
### 3.1 滚动查询的概念和原理
滚动查询是一种在Elasticsearch中获取大量文档ID的有效方法。它允许用户分批获取文档,每次获取一批ID,而不是一次性获取所有ID。这种分批处理方式可以显著降低服务器端的内存消耗和网络开销。
滚动查询通过使用`scroll` API实现。`scroll` API返回一个游标,该游标指向服务器端存储的当前结果集。用户可以使用游标分批获取文档ID,直到游标过期或没有更多结果为止。
### 3.2 使用滚动查询获取ID的步骤
使用滚动查询获取ID的步骤如下:
1. **创建滚动查询:**使用`scroll` API创建滚动查询,指定查询条件、滚动时间和文档数量。
2. **获取初始结果:**使用`search` API执行滚动查询,获取第一批文档ID。
3. **滚动游标:**使用`scroll` API滚动游标,获取下一批文档ID。
4. **重复步骤3:**重复滚动游标,直到游标过期或没有更多结果。
### 3.3 滚动查询的优化技巧
为了优化滚动查询的性能,可以采

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了各种数据库中获取 ID 的机制和最佳实践。从 MySQL 到 MongoDB,从 Redis 到 Elasticsearch,我们揭示了这些数据库如何生成和管理 ID。通过深入理解内部原理和性能优化秘籍,开发人员可以提高代码效率并满足不同需求。本专栏还提供了针对特定数据库的指南,包括查询语句、API 调用和数据结构,帮助开发人员掌握各种获取 ID 的方法。此外,我们探讨了 ID 生成策略,从自增主键到 UUID,以及如何根据特定数据库的特性选择合适的策略。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
算法到硬件的无缝转换:实现4除4加减交替法逻辑的实战指南
# 摘要
本文旨在介绍一种新颖的4除4加减交替法,探讨了其基本概念、原理及算法设计,并分析了其理论基础、硬件实现和仿真设计。文章详细阐述了算法的逻辑结构、效率评估与优化策略,并通过硬件描述语言(HDL)实现了算法的硬件设计与仿真测试。此外,本文还探讨了硬件实现与集成的过程,包括FPGA的开发流程、逻辑综合与布局布线,以及实际硬件测试。最后,文章对算法优化与性能调优进行了深入分析,并通过实际案例研究,展望了算法与硬件技术未来的发
【升级攻略】:Oracle 11gR2客户端从32位迁移到64位,完全指南

# 摘要
随着信息技术的快速发展,企业对于数据库系统的高效迁移与优化要求越来越高。本文详细介绍了Oracle 11gR2客户端从旧系统向新环境迁移的全过程,包括迁移前的准备工作、安装与配置步骤、兼容性问题处理以及迁移后的优化与维护。通过对系统兼容性评估、数据备份恢复策略、环境变量设置、安装过程中的问题解决、网络
【数据可视化】:煤炭价格历史数据图表的秘密揭示

# 摘要
数据可视化是将复杂数据以图形化形式展现,便于分析和理解的一种技术。本文首先探讨数据可视化的理论基础,再聚焦于煤炭价格数据的可视化实践,
FSIM优化策略:精确与效率的双重奏

# 摘要
本文详细探讨了FSIM(Feature Similarity Index Method)优化策略,旨在提高图像质量评估的准确度和效率。首先,对FSIM算法的基本原理和理论基础进行了分析,然后针对算法的关键参数和局限性进行了详细讨论。在此基础上,提出了一系列提高FSIM算法精确度的改进方法,并通过案例分析评估
IP5306 I2C异步消息处理:应对挑战与策略全解析

# 摘要
本文系统介绍了I2C协议的基础知识和异步消息处理机制,重点分析了IP5306芯片特性及其在I2C接口下的应用。通过对IP5306芯片的技术规格、I2C通信原理及异步消息处理的特点与优势的深入探讨,本文揭示了在硬件设计和软件层面优化异步消息处理的实践策略,并提出了实时性问题、错误处理以及资源竞争等挑战的解决方案。最后,文章
DBF到Oracle迁移高级技巧:提升转换效率的关键策略

# 摘要
本文探讨了从DBF到Oracle数据库的迁移过程中的基础理论和面临的挑战。文章首先详细介绍了迁移前期的准备工作,包括对DBF数据库结构的分析、Oracle目标架构的设计,以及选择适当的迁移工具和策略规划。接着,文章深入讨论了迁移过程中的关键技术和策略,如数据转换和清洗、高效数据迁移的实现方法、以及索引和约束的迁移。在迁移完成后,文章强调了数据验证与性能调优的重要性,并通过案例分析,分享了不同行业数据迁移的经
【VC709原理图解读】:时钟管理与分布策略的终极指南(硬件设计必备)
# 摘要
本文详细介绍了VC709硬件的特性及其在时钟管理方面的应用。首先对VC709硬件进行了概述,接着探讨了时钟信号的来源、路径以及时钟树的设计原则。进一步,文章深入分析了时钟分布网络的设计、时钟抖动和偏斜的控制方法,以及时钟管理芯片的应用。实战应用案例部分提供了针对硬件设计和故障诊断的实际策略,强调了性能优化
IEC 60068-2-31标准应用:新产品的开发与耐久性设计
# 摘要
IEC 60068-2-31标准是指导电子产品环境应力筛选的国际规范,本文对其概述和重要性进行了详细讨论,并深入解析了标准的理论框架。文章探讨了环境应力筛选的不同分类和应用,以及耐久性设计的实践方法,强调了理论与实践相结合的重要性。同时,本文还介绍了新产品的开发流程,重点在于质量控制和环境适应性设计。通过对标准应用案例的研究,分析了不同行业如何应用环境应力筛选和耐久性设计,以及当前面临的新技术挑战和未来趋势。本文为相关领域的工程实践和标准应用提供了有价值的参考。
# 关键字
IEC 60068-2-31标准;环境应力筛选;耐久性设计;环境适应性;质量控制;案例研究
参考资源链接:
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )