Redis安装攻略:环境准备与安装步骤详解
发布时间: 2024-05-01 03:57:55 阅读量: 133 订阅数: 40 

# 1. Redis安装环境准备**
Redis的安装需要满足一定的系统环境要求,并安装必要的依赖软件。
### 2.1 系统环境要求
* 操作系统:Linux(推荐使用CentOS 7或Ubuntu 18.04)
* CPU:64位处理器
* 内存:4GB以上
* 磁盘空间:1GB以上
### 2.2 依赖软件安装
在安装Redis之前,需要安装以下依赖软件:
* gcc
* make
* glibc
* zlib
# 2. Redis安装环境准备
### 2.1 系统环境要求
Redis对系统环境有一定的要求,以确保其稳定高效运行。一般情况下,Redis需要以下系统环境:
- 操作系统:Linux/Unix系统,如CentOS、Ubuntu、Debian等
- CPU:推荐使用多核CPU,以提高Redis的并发处理能力
- 内存:根据Redis的使用场景和数据量,一般建议分配4GB以上内存
- 硬盘:推荐使用固态硬盘(SSD),以提高Redis的读写性能
### 2.2 依赖软件安装
在安装Redis之前,需要安装以下依赖软件:
- gcc:C语言编译器,用于编译Redis源码
- make:构建工具,用于编译和安装Redis
- glibc:C语言标准库,提供Redis运行所需的函数和数据结构
- jemalloc:内存分配器,可优化Redis的内存管理效率
**安装依赖软件的步骤如下:**
```shell
# 使用yum安装依赖软件
yum install gcc make glibc jemalloc
# 使用apt-get安装依赖软件
apt-get install gcc make glibc jemalloc
```
**安装完成后,可以通过以下命令验证依赖软件是否已安装:**
```shell
# 查看gcc版本
gcc --version
# 查看make版本
make --version
# 查看glibc版本
glibc --version
# 查看jemalloc版本
jemalloc --version
```
# 3. Redis安装步骤详解
### 3.1 下载Redis源码
**操作步骤:**
1. 访问Redis官方网站(https://redis.io/download)下载最新版本的Redis源码。
2. 解压下载的源码包。
### 3.2 编译并安装Redis
**操作步骤:**
1. 进入解压后的Redis源码目录。
2. 执行以下命令编译Redis:
```bash
make
```
3. 编译完成后,执行以下命令安装Redis:
```bash
make install
```
**逻辑分析:**
* `make`命令用于编译Redis源码,生成可执行文件。
* `make install`命令将编译好的可执行文件安装到系统指定目录。
### 3.3 配置Redis配置文件
**操作步骤:**
1. 复制Redis配置文件模板到目标目录:
```bash
cp redis.conf /etc/redis/redis.conf
```
2. 根据需要修改配置文件中的参数。
**参数说明:**
| 参数 | 说明 |
|---|---|
| `port` | Redis服务监听的端口 |
| `bind` | Redis服务绑定的IP地址 |
| `maxmemory` | Redis最大内存限制 |
| `maxclients` | Redis最大客户端连接数 |
| `requirepass` | Redis访问密码 |
**代码示例:**
```
# Redis配置文件
port 6379
bind 127.0.0.1
maxmemory 128mb
maxclients 10000
requirepass mypassword
```
**逻辑分析:**
* Redis配置文件中包含了Redis服务的配置参数。
* 修改配置文件中的参数可以调整Redis服务的运行行为。
# 4. Redis服务管理
### 4.1 启动和停止Redis服务
**启动Redis服务**
* **命令:** redis-server [配置文件路径]
* **参数:**
* **配置文件路径:** 指定Redis配置文件的路径,默认为/etc/redis.conf。
* **示例:**
```
redis-server /etc/redis.conf
```
**停止Redis服务**
* **命令:** redis-cli shutdown
* **参数:** 无
* **示例:**
```
redis-cli shutdown
```
### 4.2 查看Redis服务状态
**命令:** redis-cli info
**参数:** 无
**输出示例:**
```
# Server
redis_version:6.2.6
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:6a85a31c7c5487b0
redis_mode:standalone
os:Linux 5.10.102-linuxkit x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:10.2.1
process_id:1
run_id:986a0669f60d1925436a278a60c1212919686325
tcp_port:6379
uptime_in_seconds:126637
uptime_in_days:1
hz:10
configured_hz:10
executable:/usr/local/bin/redis-server
config_file:/etc/redis.conf
# Clients
connected_clients:1
client_recent_max_input_buffer:0
client_recent_max_output_buffer:0
blocked_clients:0
# Memory
used_memory:3.82M
used_memory_human:3.82M
used_memory_rss:10.28M
used_memory_rss_human:10.28M
used_memory_peak:3.82M
used_memory_peak_human:3.82M
total_system_memory:18632.92M
total_system_memory_human:18632.92M
used_memory_lua:352.88K
used_memory_lua_human:352.88K
maxmemory:0
maxmemory_human:0
maxmemory_policy:noeviction
mem_fragmentation_ratio:1.00
mem_allocator:jemalloc-5.2.1
```
### 4.3 Redis服务优化
**参数优化**
Redis提供了丰富的配置参数,可以根据实际业务场景进行优化。以下是一些常用的优化参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
| maxmemory | 设置Redis最大内存限制 | 0 (无限制) |
| maxmemory-policy | 设置Redis内存淘汰策略 | noeviction |
| maxmemory-samples | 设置Redis采样数量,用于淘汰策略 | 5 |
| timeout | 设置Redis客户端连接超时时间 | 300 秒 |
| slowlog-log-slower-than | 设置慢查询日志记录阈值 | 1000 微秒 |
| slowlog-max-len | 设置慢查询日志最大长度 | 128 |
**持久化优化**
Redis提供了两种持久化方式:RDB和AOF。RDB是将Redis数据定期保存到磁盘快照中,而AOF是将Redis所有写操作记录到日志文件中。为了提高持久化性能,可以考虑以下优化:
* **开启AOF持久化:** AOF持久化比RDB持久化性能更好,可以避免数据丢失。
* **调整AOF文件大小:** 适当调整AOF文件大小,既能保证数据安全,又能避免频繁的AOF重写。
* **使用fsync优化:** fsync操作可以将AOF数据同步到磁盘,提高持久化速度。
**复制优化**
Redis支持主从复制,可以提高数据冗余和可用性。为了优化复制性能,可以考虑以下优化:
* **使用slave-serve-stale-data:** 允许从节点在同步未完成时提供服务,提高读性能。
* **调整复制缓冲区大小:** 适当调整复制缓冲区大小,既能保证复制稳定性,又能提高复制速度。
* **使用复制过滤器:** 过滤掉某些类型的写操作,减少复制流量。
**其他优化**
除了上述优化外,还可以考虑以下优化:
* **使用Redis模块:** Redis模块可以扩展Redis的功能,提高性能。
* **启用Redis集群:** Redis集群可以将Redis数据分布在多个节点上,提高可扩展性和性能。
* **监控Redis性能:** 使用Redis监控工具,实时监控Redis性能,及时发现问题。
# 5. Redis配置详解
### 5.1 常用Redis配置参数
Redis配置文件中包含大量配置参数,以下列出一些常用的配置参数:
| 参数 | 默认值 | 描述 |
|---|---|---|
| `maxmemory` | 0 | Redis允许使用的最大内存量,单位为字节。如果达到此限制,Redis将开始驱逐旧数据。 |
| `maxmemory-policy` | `noeviction` | 当达到`maxmemory`限制时,Redis驱逐数据的策略。`noeviction`表示不驱逐任何数据,`volatile-lru`表示驱逐最近最少使用的键值对,`allkeys-lru`表示驱逐所有键值对。 |
| `timeout` | 0 | Redis客户端连接的超时时间,单位为秒。如果客户端在指定时间内没有发送任何命令,Redis将关闭连接。 |
| `databases` | 16 | Redis数据库的数量。每个数据库都是一个独立的键值对空间。 |
| `appendonly` | `no` | 是否启用AOF持久化。如果启用,Redis将所有写入操作记录到一个AOF文件。 |
| `save` | | RDB持久化配置。指定Redis保存快照的频率。例如,`save 60 1000`表示每60秒保存一次快照,如果在1秒内有超过1000个键值对发生变化。 |
| `requirepass` | | 设置Redis访问密码。 |
| `bind` | 127.0.0.1 | Redis监听的IP地址。 |
| `port` | 6379 | Redis监听的端口。 |
### 5.2 配置文件优化建议
根据实际应用场景,可以对Redis配置文件进行优化。以下是一些优化建议:
* **设置合理的`maxmemory`限制:**根据实际内存容量和数据大小设置`maxmemory`限制,避免Redis因内存不足而驱逐数据。
* **选择合适的`maxmemory-policy`:**根据数据访问模式选择合适的驱逐策略。如果数据访问模式比较随机,可以使用`volatile-lru`策略;如果数据访问模式比较集中,可以使用`allkeys-lru`策略。
* **设置适当的`timeout`值:**根据客户端连接的活跃程度设置`timeout`值。如果客户端连接比较活跃,可以设置较小的`timeout`值;如果客户端连接比较稳定,可以设置较大的`timeout`值。
* **启用AOF持久化:**AOF持久化可以保证Redis数据的安全性。建议在生产环境中启用AOF持久化。
* **优化RDB持久化配置:**根据数据变化频率和数据量大小优化RDB持久化配置。如果数据变化频率比较高,可以设置较小的RDB保存间隔;如果数据量比较大,可以设置较大的RDB保存间隔。
* **设置访问密码:**为了保证Redis服务的安全性,建议设置访问密码。
* **绑定到特定IP地址:**如果Redis服务只允许特定IP地址访问,可以设置`bind`参数。
# 6. Redis故障排除
### 6.1 常见Redis故障问题
在使用Redis的过程中,可能会遇到各种故障问题,常见的问题包括:
- **Redis无法启动:**
- 端口冲突:检查是否其他进程正在使用Redis默认端口(6379)。
- 依赖软件未安装:确保已安装必要的依赖软件,如jemalloc、zlib等。
- 配置文件错误:检查Redis配置文件是否有语法错误或配置不当。
- **Redis服务不稳定:**
- 内存不足:Redis使用内存存储数据,当内存不足时,可能会导致服务不稳定。
- CPU使用率过高:Redis处理大量请求时,CPU使用率可能会过高,导致服务响应缓慢。
- 网络问题:检查网络连接是否稳定,是否有防火墙或其他网络问题阻碍Redis与客户端通信。
- **Redis数据丢失:**
- AOF持久化配置错误:检查AOF持久化配置文件是否配置正确,确保数据能够正常持久化到磁盘。
- RDB持久化失败:检查RDB持久化配置文件是否配置正确,并确保Redis有足够的磁盘空间进行持久化。
- **Redis命令执行失败:**
- 参数错误:检查命令参数是否正确,是否符合Redis命令语法。
- 数据类型不匹配:确保操作的数据类型与命令要求相符,例如不能对字符串类型执行数字操作。
- 权限不足:检查用户是否有执行该命令的权限,某些命令需要管理员权限。
### 6.2 故障排除方法
遇到Redis故障问题时,可以采取以下故障排除方法:
- **查看日志:**Redis通常会将错误和警告信息记录到日志文件中,检查日志文件可以帮助定位问题。
- **使用Redis客户端:**通过Redis客户端(如redis-cli)连接到Redis服务器,并执行相关命令来检查服务状态和数据完整性。
- **检查配置:**仔细检查Redis配置文件,确保配置正确无误,并根据实际情况进行调整。
- **重启服务:**有时重启Redis服务可以解决一些临时性故障问题。
- **联系Redis社区:**如果无法自行解决问题,可以向Redis社区寻求帮助,在论坛或邮件列表中提问。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Redis从入门到精通》专栏全面介绍了Redis的安装、配置、客户端使用和配置文件解读等内容。专栏包含一系列文章,涵盖了Redis在Windows和Linux系统下的安装指南、环境变量设置、服务启动、客户端分类解析和连接验证技巧。通过深入浅出的讲解和详细的步骤指导,专栏旨在帮助初学者快速掌握Redis的基本知识和使用技巧,并为进阶用户提供深入的理解和实践指导。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
推荐系统中的L2正则化:案例与实践深度解析
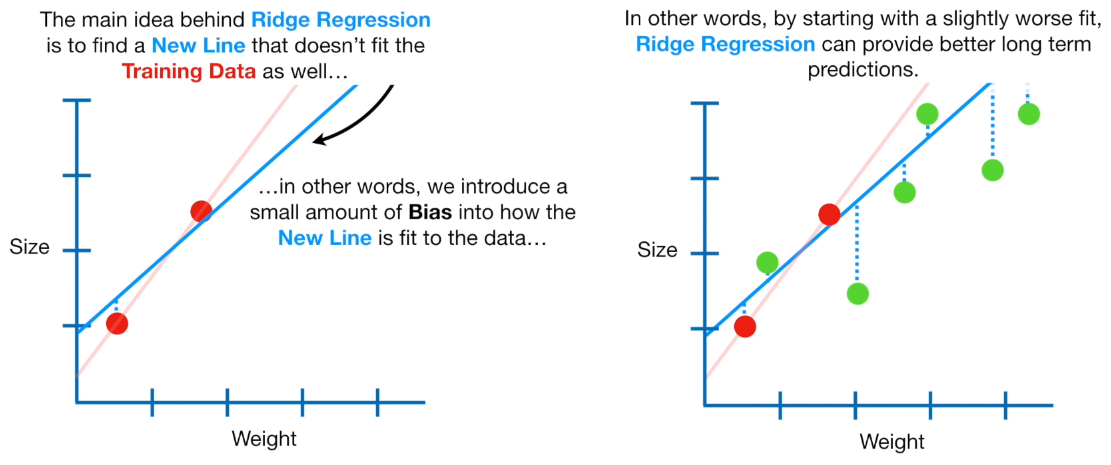
# 1. L2正则化的理论基础
在机器学习与深度学习模型中,正则化技术是避免过拟合、提升泛化能力的重要手段。L2正则化,也称为岭回归(Ridge Regression)或权重衰减(Weight Decay),是正则化技术中最常用的方法之一。其基本原理是在损失函数中引入一个附加项,通常为模型权重的平方和乘以一个正则化系数λ(lambda)。这个附加项对大权重进行惩罚,促使模型在训练过程中减小权重值,从而达到平滑模型的目的。L2正则化能够有效地限制模型复
【从零开始构建卡方检验】:算法原理与手动实现的详细步骤
# 1. 卡方检验的统计学基础
在统计学中,卡方检验是用于评估两个分类变量之间是否存在独立性的一种常用方法。它是统计推断的核心技术之一,通过观察值与理论值之间的偏差程度来检验假设的真实性。本章节将介绍卡方检验的基本概念,为理解后续的算法原理和实践应用打下坚实的基础。我们将从卡方检验的定义出发,逐步深入理解其统计学原理和在数据分析中的作用。通过本章学习,读者将能够把握卡方检验在统计学中的重要性
【LDA与SVM对决】:分类任务中LDA与支持向量机的较量
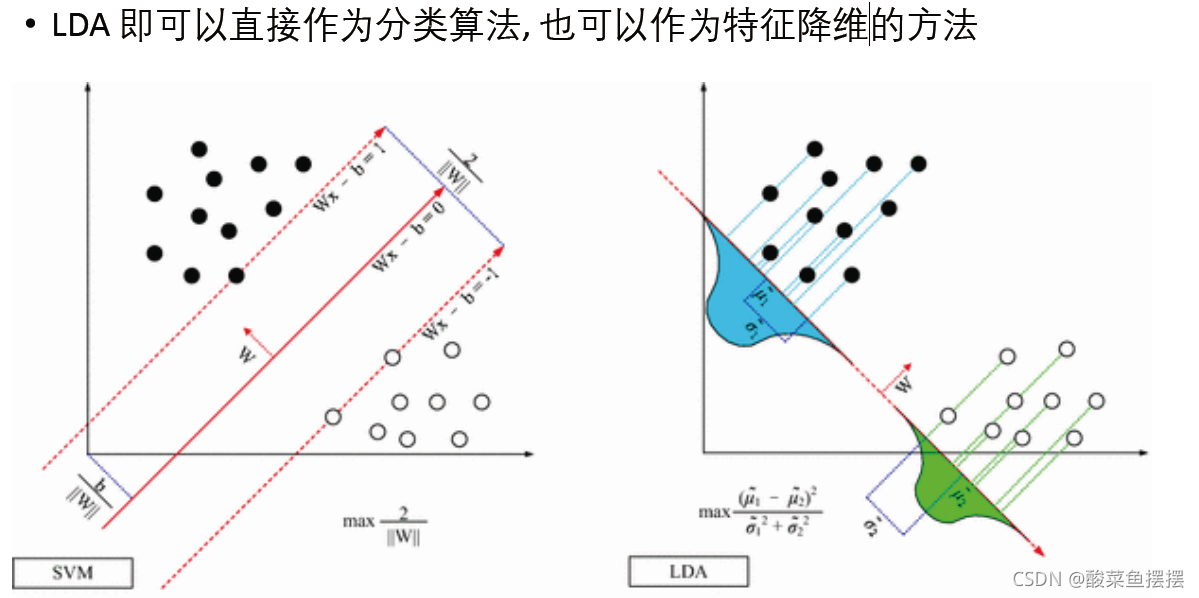
# 1. 文本分类与机器学习基础
在当今的大数据时代,文本分类作为自然语言处理(NLP)的一个基础任务,在信息检索、垃圾邮
数据增强新境界:自变量与机器学习模型的8种交互技术

# 1. 数据增强与机器学习模型概述
在当今的数据驱动时代,机器学习已经成为解决各种复杂问题的关键技术之一。模型的性能直接取决于训练数据的质量和多样性。数据
机器学习中的变量转换:改善数据分布与模型性能,实用指南
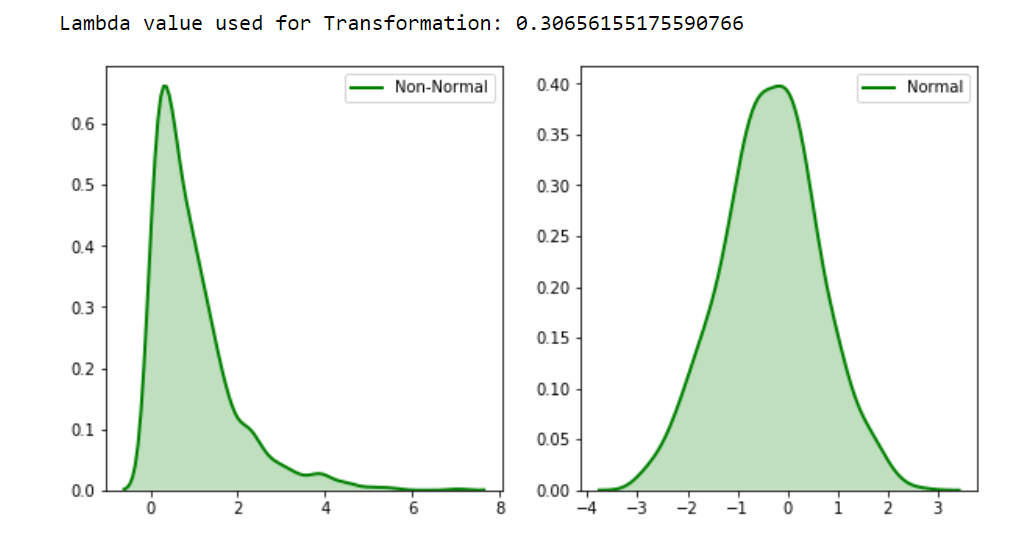
# 1. 机器学习与变量转换概述
## 1.1 机器学习的变量转换必要性
在机器学习领域,变量转换是优化数据以提升模型性能的关键步骤。它涉及将原始数据转换成更适合算法处理的形式,以增强模型的预测能力和稳定性。通过这种方式,可以克服数据的某些缺陷,比如非线性关系、不均匀分布、不同量纲和尺度的特征,以及处理缺失值和异常值等问题。
## 1.2 变量转换在数据预处理中的作用
大规模深度学习系统:Dropout的实施与优化策略
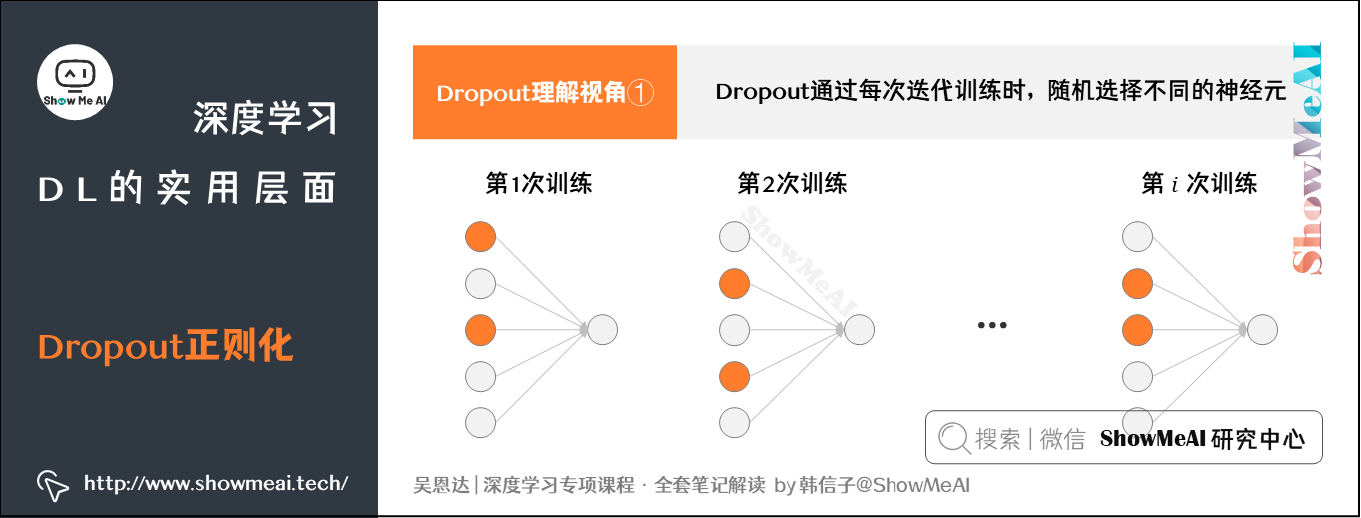
# 1. 深度学习与Dropout概述
在当前的深度学习领域中,Dropout技术以其简单而强大的能力防止神经网络的过拟合而著称。本章旨在为读者提供Dropout技术的初步了解,并概述其在深度学习中的重要性。我们将从两个方面进行探讨:
首先,将介绍深度学习的基本概念,明确其在人工智能中的地位。深度学习是模仿人脑处理信息的机制,通过构建多层的人工神经网络来学习数据的高层次特征,它已
贝叶斯方法与ANOVA:统计推断中的强强联手(高级数据分析师指南)
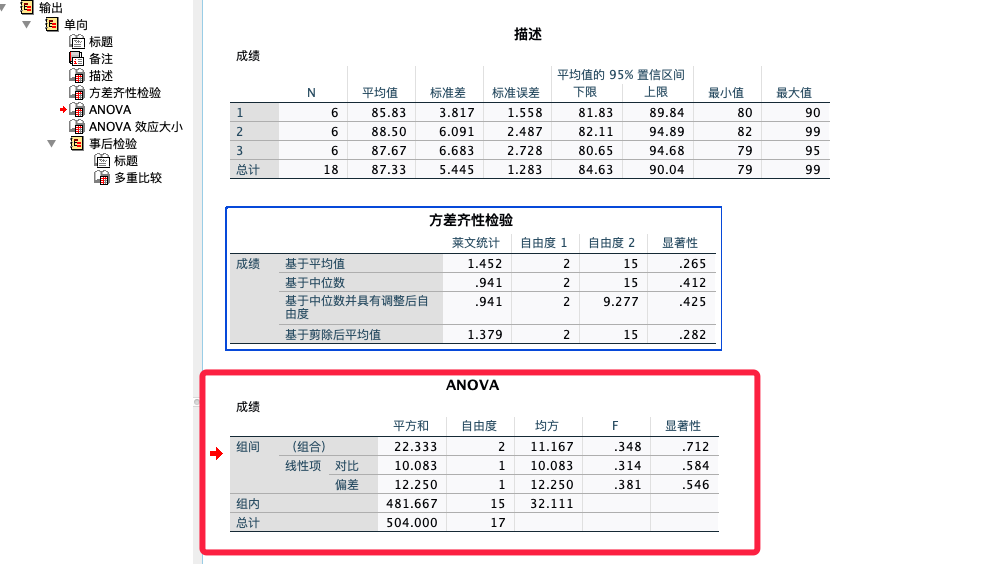
# 1. 贝叶斯统计基础与原理
在统计学和数据分析领域,贝叶斯方法提供了一种与经典统计学不同的推断框架。它基于贝叶斯定理,允许我们通过结合先验知识和实际观测数据来更新我们对参数的信念。在本章中,我们将介绍贝叶斯统计的基础知识,包括其核心原理和如何在实际问题中应用这些原理。
## 1.1 贝叶斯定理简介
贝叶斯定理,以英国数学家托马斯·贝叶斯命名
图像处理中的正则化应用:过拟合预防与泛化能力提升策略

# 1. 图像处理与正则化概念解析
在现代图像处理技术中,正则化作为一种核心的数学工具,对图像的解析、去噪、增强以及分割等操作起着至关重要
【Lasso回归与岭回归的集成策略】:提升模型性能的组合方案(集成技术+效果评估)
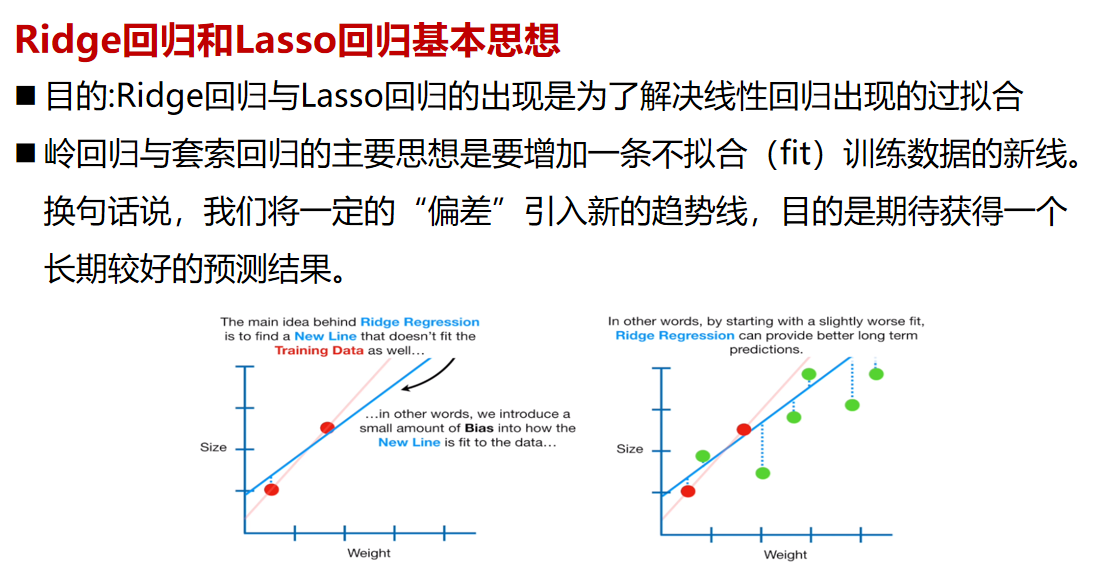
# 1. Lasso回归与岭回归基础
## 1.1 回归分析简介
回归分析是统计学中用来预测或分析变量之间关系的方法,广泛应用于数据挖掘和机器学习领域。在多元线性回归中,数据点拟合到一条线上以预测目标值。这种方法在有多个解释变量时可能会遇到多重共线性的问题,导致模型解释能力下降和过度拟合。
## 1.2 Lasso回归与岭回归的定义
Lasso(Least
自然语言处理中的过拟合与欠拟合:特殊问题的深度解读
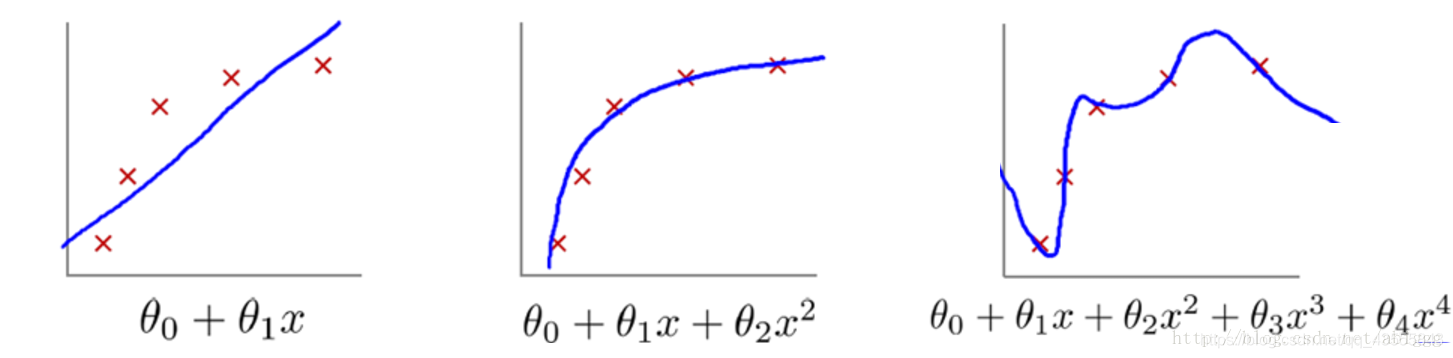
# 1. 自然语言处理中的过拟合与欠拟合现象
在自然语言处理(NLP)中,过拟合和欠拟合是模型训练过程中经常遇到的两个问题。过拟合是指模型在训练数据上表现良好
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )