MATLAB遗传算法vs元启发式算法:优势对比与应用策略
发布时间: 2024-11-15 21:02:57 阅读量: 28 订阅数: 19 
# 1. 遗传算法与元启发式算法概述
遗传算法与元启发式算法是解决复杂优化问题的有力工具,它们在IT领域及相关的工程问题中扮演着重要角色。本章将对这两种算法的概念、特点以及它们在行业中的应用进行概述。
## 1.1 算法的定义和用途
遗传算法(Genetic Algorithm, GA)是一种模拟自然选择和遗传学机制的搜索算法,它属于元启发式算法的一种。由于其独特的全局搜索能力和相对简单的实现方式,遗传算法广泛应用于函数优化、机器学习、控制工程和调度等领域。
## 1.2 算法的发展背景
遗传算法的发展受到生物学中自然选择理论的启发。1975年,美国计算机科学家John Holland教授提出了遗传算法的基础理论,此后,这一算法不断被改进并应用到更多的领域。元启发式算法,如遗传算法,是为了解决NP-hard问题而诞生的一类算法。NP-hard问题的特点是,随着问题规模的增大,寻找最优解所需的时间会指数级增长。
## 1.3 算法的行业影响
在IT行业内,遗传算法与元启发式算法提供了新的解决方案来优化性能,提高效率。例如,通过遗传算法优化代码,能够显著减少程序的运行时间。在工程领域,它们被用于设计更有效的交通调度系统、电网管理,甚至在游戏设计中用于创造出更具挑战性的AI对手。
总的来说,遗传算法和元启发式算法是值得深入研究和实践的领域,其在提升算法效率和解决复杂问题中发挥着不可忽视的作用。在接下来的章节中,我们将详细探讨遗传算法的基础理论、实现步骤以及它们在工程和科学研究中的具体应用。
# 2. ```
# 第二章:遗传算法基础理论与实践
## 2.1 遗传算法核心概念
### 2.1.1 遗传算法的工作原理
遗传算法(Genetic Algorithm, GA)是一种模拟自然选择和遗传机制的搜索优化算法,由John Holland及其同事们在1975年提出。其工作原理主要模仿了生物进化过程中的“适者生存,优胜劣汰”的规律。遗传算法将问题的潜在解编码为一系列的串结构,这些串结构常被视作“染色体”,而串中的每个元素则对应“基因”。
算法初始化时,随机生成一组“种群”(也就是一组潜在的解决方案)。通过选择(Selection)、交叉(Crossover)和变异(Mutation)这三种主要操作,种群中表现较好的个体被保留下来,并产生新的后代。这个过程会重复迭代,直至达到预设的终止条件,最终解(最优解或近似最优解)被找到。
遗传算法的优势在于能够在较大的搜索空间中有效进行全局搜索,并且在复杂问题中,具有较好的鲁棒性和通用性。
### 2.1.2 遗传算法的关键组成部分
遗传算法的关键组成部分包括:
- **种群(Population)**:一组候选解的集合。
- **个体(Individual)**:种群中的每一个候选解,通常用字符串表示。
- **适应度函数(Fitness Function)**:衡量个体适应环境能力的函数,解的优劣由它决定。
- **选择(Selection)**:决定哪些个体能够遗传到下一代的过程。
- **交叉(Crossover)**:将两个个体的部分基因结合产生新个体的过程。
- **变异(Mutation)**:随机改变个体中某些基因的值以引入新的遗传信息。
- **终止条件(Termination Condition)**:决定算法何时停止的条件,如达到最大迭代次数或满足适应度阈值。
## 2.2 遗传算法的实现步骤
### 2.2.1 初始化种群
初始化种群是遗传算法的第一步,通常情况下,种群是随机生成的。种群中个体的数量被称为种群大小(Population Size),是遗传算法的一个关键参数,需要根据问题的复杂性和计算资源合理选择。
初始化种群的伪代码如下:
```pseudo
Population = []
For i = 1 to PopulationSize do
Individual = GenerateRandomIndividual()
Population.add(Individual)
EndFor
```
这里的`GenerateRandomIndividual()`函数负责根据问题的编码方式生成随机个体。
### 2.2.2 选择、交叉和变异操作
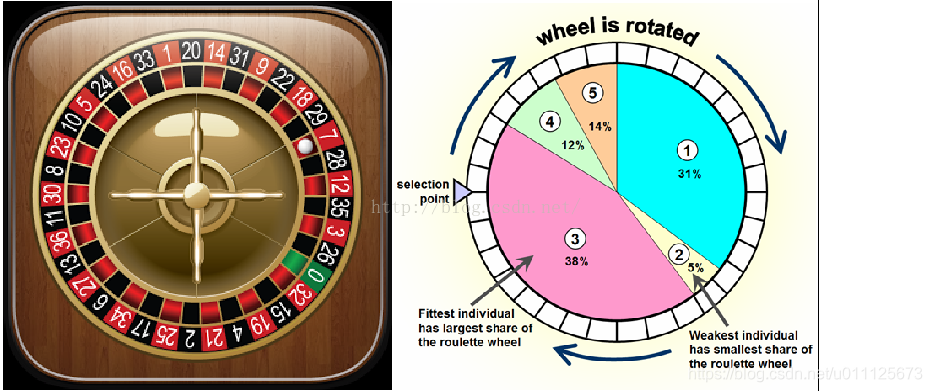
在遗传算法中,选择操作的目的是从当前种群中选择优秀的个体遗传到下一代。常见的选择方法包括轮盘赌选择(Roulette Wheel Selection)和锦标赛选择(Tournament Selection)。
交叉操作是遗传算法中模拟生物染色体交叉的主要环节,它随机配对种群中的个体,然后交换它们的部分基因片段。
变异操作随机改变个体中的某些基因,以维持种群的多样性并避免算法过早收敛到局部最优解。
### 2.2.3 算法终止条件与结果评估
遗传算法的终止条件可以是达到一定的迭代次数、找到足够好的解或是适应度提升幅度低于某个阈值。在每一代结束时,算法都会评估种群中每个个体的适应度,并根据适应度值进行选择、交叉和变异操作。
伪代码表示如下:
```pseudo
While not TerminationCondition() do
SelectedIndividuals = Selection(Population)
Offspring = Crossover(SelectedIndividuals)
Offspring = Mutation(Offspring)
Population = Combine(Population, Offspring)
EvaluateFitness(Population)
EndWhile
```
在上面的伪代码中,`TerminationCondition()`函数根据设定的终止条件判断算法是否继续迭代。`Selection()`、`Crossover()`、`Mutation()`函数分别执行选择、交叉和变异操作。`EvaluateFitness()`函数负责计算种群中每个个体的适应度。
## 2.3 遗传算法的编码和解码策略
### 2.3.1 二进制编码
二进制编码是最常用的遗传算法编码方式之一。在这种方式下,问题的解被编码为一串0和1组成的二进制字符串。二进制编码简单直观,适用于许多优化问题,但也有一些局限性,比如在表示实数时可能会有精度问题。
### 2.3.2 浮点数编码
浮点数编码使用实数来表示染色体上的基因。这种编码方式可以提供更高的精度,并且在一些问题中能直接对应到问题的参数,使用起来更为直观和方便。
### 2.3.3 编码与解码的实践案例分析
在实践中,编码和解码策略需要根据具体问题进行选择。比如,对于一个旅行商问题(TSP),二进制编码可能需要额外的解码步骤将基因映射到城市访问序列,而实数编码则可以直观地表示城市间的距离。
```markdown
| 编码类型 | 优点 | 缺点 | 适用问题 |
|----------|------|------|----------|
| 二进制编码 | 直观、简单、易于实现 | 精度有限,解码过程可能复杂 | 需要离散编码的问题 |
| 浮点数编码 | 高精度、表示直观 | 实现相对复杂 | 需要连续参数的问题 |
```
以浮点数编码为例,一个简单的遗传算法代码实现如下:
```python
import numpy as np
# 假设问题的解由三个实数参数组成
def generate_individual():
return np.random.rand(3)
# 适应度函数,根据问题定义
def fitness(individual):
# 示例适应度计算
return -sum(individual ** 2)
# 交叉操作
def crossover(parent1, parent2):
alpha = np.random.rand()
return alpha * parent1 + (1 - alpha) * parent2
# 变异操作
def mutate(individual, mutation_rate):
if np.random.rand() < mutation_rate:
idx = np.random.randint(0, len(individual))
individual[idx] += np.random.randn()
return individual
# 遗传算法主程序
def genetic_

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏深入探讨了 MATLAB 中遗传算法和非线性规划函数优化技术的应用。它提供了全面的指南,涵盖了遗传算法的技巧、非线性规划的策略、案例分析、多目标优化优势、调试秘诀、敏感性分析、算法对比、生物信息学应用、并行计算指南、参数调优以及在化学工程中的实战技巧。此外,它还介绍了遗传算法和模拟退火策略的互补性,帮助读者找到全局最优解。该专栏为优化问题提供了全面的解决方案,适用于各种领域的研究人员和从业者。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【HDMI升级必备秘籍】:新旧设备兼容性深度解读与指南
.png)
参考资源链接:[HDMI各版本详解:1.3a至2.0技术飞跃与差异对比](https://wenku.csdn.net/doc/6460bc8e5928463033af8f6e?spm=1055.2635.3001.10343)
# 1. HDMI技术的历史回顾与升级需求
## HDMI技术的起源
HDMI(High-Definition Multimedia Interface
SONY IMX 178性能剖析:掌握高分辨率图像采集的关键5大因素

参考资源链接:[索尼IMX178:高性能CMOS图像传感器技术解析](https://wenku.csdn.net/doc/2e2hfcxefh?spm=1055.2635.3001.10343)
# 1. SONY IMX 178图像传感器简介
SONY IMX 178 是一个高分辨率图
【C#终极指南】:让ListBox控件字体颜色随心变(15种技巧大公开)
参考资源链接:[C# ListBox 中指定行字体颜色修改教程](https://wenku.csdn.net/doc/5a83kp9z0v?spm=1055.2635.3001.10343)
# 1. C#中的ListBox控件基础
## 1.1 ListBox控件概述
ListBox是C# Windows窗体应用程序中常用的控件之一,它提供了一个列表供用户选择。在这个基础章节中,我们将介绍ListBox的基本功能和属性,以及如何在应用程序中实现基础的列表展示。
## 1.2 添加ListBox到窗体
要在C#窗体中添加ListBox控件,可以通过拖放控件或在代码中声明和配置控件。以
【MD310变频器参数设置:性能提升手册】

参考资源链接:[汇川MD310系列变频器用户手册:功能特性与使用指南](https://wenku.csdn.net/doc/8bnnqnnceg?spm=1055.2635.3001.10343)
# 1. MD310变频器概述与基础操作
## 1.1 MD310变频器简介
MD310变频器是工业自
Fanuc CNC机械臂操作全攻略:自动化控制一步到位
参考资源链接:[FANUC机器人自动运行设置详解:RSR与PNS启动](https://wenku.csdn.net/doc/12rv1nsph5?spm=1055.2635.3001.10343)
# 1. Fanuc CNC机械臂基础概述
在现代工业生产中,CNC(Computer Numerical Control,计算机数控)机械臂扮演着至关重要的角色。作为自动化技术的核心设备,CNC机械臂
【地震数据分析密籍】:掌握FK方法的10大应用场景及实战技巧

参考资源链接:[Lupei Zhu教授的FK工具包:水平分层模型格林函数计算与地震图合成教程](https://wenku.csdn.net/doc/6412b70abe7fbd1778d48e0d?spm=1055.2635.3001.10343)
# 1. FK方法基础与地震数据处理
F
【HFSS 3D Layout新手必读】:掌握软件界面与基本操作的7个步骤
参考资源链接:[HFSS 3D Layout用户手册:全面指南](https://wenku.csdn.net/doc/6412b6edbe7fbd1778d48793?spm=1055.2635.3001.10343)
# 1. HFSS 3D Layout简介与安装
## 简介
HFSS 3D Layout 是一款在高频电子电路设计领域广泛使用的仿真软件。它允许工程师在3D环境中进行快速、精确的电磁场模拟和电路设计。HFSS 3D Layout特别适合于设计高速数字电路、射频电路和复杂的天线系统。
## 安装要求
在进行HFSS 3D Layout安装之前,您需要确保计算机满足以下基本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )