Scrapy中的错误处理与重试机制:如何应对爬取过程中的异常情况
发布时间: 2023-12-16 02:06:43 阅读量: 351 订阅数: 32 
# 1. 简介
## 1.1 Scrapy框架概述
Scrapy是一个基于Python的开源网络爬虫框架,它提供了简单而强大的工具,用于快速和高效地提取所需数据。通过定义爬虫、处理页面和提取数据的方式,用户可以灵活地定制爬取过程。
## 1.2 错误处理与重试机制的重要性
在网络爬虫的实际应用中,经常会遇到各种问题,如网络超时、HTTP错误、页面结构变化等异常情况。合理的错误处理与重试机制可以提高爬取的稳定性和可靠性,确保爬虫的顺利运行。
## 1.3 目录概要
本文将深入探讨Scrapy中的错误处理与重试机制,内容包括错误处理基础、重试机制的实现、自定义错误处理与重试策略、实践与案例分析、总结与展望等方面。通过学习本文,读者将了解如何应对爬取过程中的异常情况,提升爬虫程序的稳定性和可靠性。
# 2. 错误处理基础
在爬取过程中,经常会遇到各种异常情况。为了保证爬虫能够稳定运行,并能适应不同的异常情况,错误处理是非常重要的。在Scrapy框架中,错误处理是通过异常处理来实现的。
### 2.1 常见的爬取过程中可能出现的异常情况
在爬取过程中,常见的异常情况包括:
1. 网络连接错误:例如DNS解析失败、连接超时等。
2. HTTP错误:例如404页面不存在、500服务器内部错误等。
3. 解析错误:例如页面内容结构变化导致无法解析数据。
4. 登录验证错误:例如需要登录才能访问的页面,登录验证失败。
5. 防爬机制:例如页面存在验证码、IP被封等。
6. 其他未知异常:例如硬件故障、网络中断等。
### 2.2 理解异常处理在Scrapy中的作用
Scrapy框架中的异常处理主要有以下几个作用:
1. 错误日志记录:Scrapy能够将异常信息记录在日志中,方便排查问题。
2. 中断爬取:遇到异常情况时,可以中断当前请求或整个爬虫,避免进一步出现错误。
3. 异常处理:可以通过异常处理逻辑来对不同的异常情况进行处理,例如重新发起请求、调整解析规则等。
4. 错误重试:可以通过错误重试机制来处理一些临时性错误,提高爬虫的稳定性。
### 2.3 设置HTTP错误处理
在Scrapy中,默认情况下,当遇到HTTP错误(例如404或500)时,Scrapy会自动将请求标记为失败(non-200 response)并返回Response对象。可以通过settings.py文件中的`HTTPERROR_ALLOWED_CODES`参数来设置允许的HTTP错误码。
```python
# settings.py
HTTPERROR_ALLOWED_CODES = [404, 500]
```
在上述示例中,我们设置了404和500两个HTTP错误码为允许的错误码。这意味着当爬虫遇到这两个错误码时,不会将请求标记为失败。
同样,在异常处理中,我们可以通过在爬虫中重写`handle_httpstatus_list`方法来自定义HTTP错误处理。以下是一个示例:
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
def start_requests(self):
yield scrapy.Request(url='http://www.example.com', callback=self.parse)
def parse(self, response):
if response.status == 404:
self.logger.error('Page not found: %s', response.url)
```
在上述示例中,我们重写了`parse`方法,并通过判断响应的状态码为404来自定义处理逻辑。
以上是错误处理基础的介绍,下一章节将介绍如何实现重试机制来应对异常情况。
# 3. 重试机制的实现
在爬取过程中,经常会遇到一些临时的网络问题或服务器端错误,为了增加爬取的成功率,Scrapy提供了重试机制来应对这些异常情况。本章将介绍重试机制的实现方法以及在Scrapy中如何配置和调整重试机制。
#### 3.1 重试机制的工作原理
当Scrapy请求一个页面时,如果遇到了网络问题或者服务器返回了错误状态码(比如500 Internal Server Error),Scrapy会根据配置的重试机制进行处理。重试机制会尝试重新发送请求,以期待获取正常的响应。通过设置合适的重试次数和重试间隔,可以有效地提高爬取的成功率。
#### 3.2 在Scrapy中配置重试机制
在Scrapy中,可以通过设置RetryMiddleware来启用重试机制。RetryMiddleware是Scrapy内置的中间件,用于处理请求的重试逻辑。在middlewares.py文件中,配置RetryMiddleware的相关参数,例如:
```python
# 在middlewares.py中配置RetryMiddleware
from scrapy.downloadermiddlewares.retry import RetryMiddleware
from scrapy.utils.response import response_status_message
from scrapy.utils.python import global_object_name
from twisted.internet.error import TimeoutError, TCPTimedOutError
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏《Scrapy》涵盖了使用Python爬虫框架Scrapy进行网页数据爬取的全面知识。从入门指南、页面选择器到数据提取,再到数据存储和导出等,专栏详细介绍了如何使用Scrapy灵活定制爬虫。专栏还包括了应对网站反爬机制的策略、爬虫调度器控制爬取频率和并发、分布式爬取和数据聚合等内容。此外,专栏还分享了在Scrapy中处理登录认证、错误处理与重试、深度优先与广度优先爬取、IP代理轮换与失效检测等技巧。最后,专栏还讲述了如何利用Scrapy与Splash结合实现动态网页爬取、数据清洗与去重、与Elasticsearch整合实现搜索引擎数据索引等高级应用,并介绍了Scrapy爬虫的部署与定时任务管理技巧。无论你是初学者还是有一定经验的开发者,本专栏都能帮助你掌握Scrapy爬虫的核心技术和实际应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
脉冲宽度调制(PWM)在负载调制放大器中的应用:实例与技巧

# 1. 脉冲宽度调制(PWM)基础与原理
脉冲宽度调制(PWM)是一种广泛应用于电子学和电力电子学的技术,它通过改变脉冲的宽度来调节负载上的平均电压或功率。PWM技术的核心在于脉冲信号的调制,这涉及到开关器件(如晶体管)的开启与关闭的时间比例,即占空比的调整。在占空比增加的情况下,负载上的平均电压或功率也会相
【Python分布式系统精讲】:理解CAP定理和一致性协议,让你在面试中无往不利

# 1. 分布式系统的基础概念
分布式系统是由多个独立的计算机组成,这些计算机通过网络连接在一起,并共同协作完成任务。在这样的系统中,不存在中心化的控制,而是由多个节点共同工作,每个节点可能运行不同的软件和硬件资源。分布式系统的设计目标通常包括可扩展性、容错性、弹性以及高性能。
分布式系统的难点之一是各个节点之间如何协调一致地工作。
MATLAB机械手仿真并行计算:加速复杂仿真的实用技巧
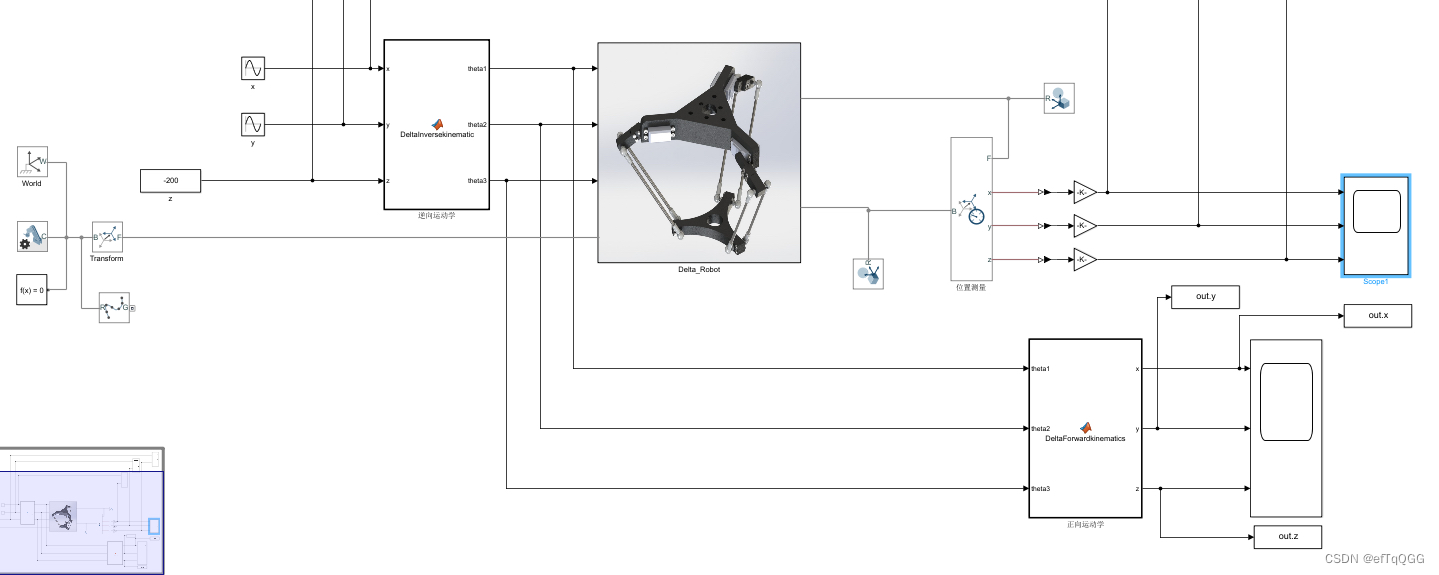
# 1. MATLAB机械手仿真基础
在这一章节中,我们将带领读者进入MATLAB机械手仿真的世界。为了使机械手仿真具有足够的实用性和可行性,我们将从基础开始,逐步深入到复杂的仿真技术中。
首先,我们将介绍机械手仿真的基本概念,包括仿真系统的构建、机械手的动力学模型以及如何使用MATLAB进行模型的参数化和控制。这将为后续章节中将要介绍的并行计算和仿真优化提供坚实的基础。
接下来,我
【趋势分析】:MATLAB与艾伦方差在MEMS陀螺仪噪声分析中的最新应用
# 1. MEMS陀螺仪噪声分析基础
## 1.1 噪声的定义和类型
在本章节,我们将对MEMS陀螺仪噪声进行初步探索。噪声可以被理解为任何影响测量精确度的信号变化,它是MEMS设备性能评估的核心问题之一。MEMS陀螺仪中常见的噪声类型包括白噪声、闪烁噪声和量化噪声等。理解这些噪声的来源和特点,对于提高设备性能至关重要。
数据库备份与恢复:实验中的备份与还原操作详解

# 1. 数据库备份与恢复概述
在信息技术高速发展的今天,数据已成为企业最宝贵的资产之一。为了防止数据丢失或损坏,数据库备份与恢复显得尤为重要。备份是一个预防性过程,它创建了数据的一个或多个副本,以备在原始数据丢失或损坏时可以进行恢复。数据库恢复则是指在发生故障后,将备份的数据重新载入到数据库系统中的过程。本章将为读者提供一个关于
【宠物管理系统权限管理】:基于角色的访问控制(RBAC)深度解析
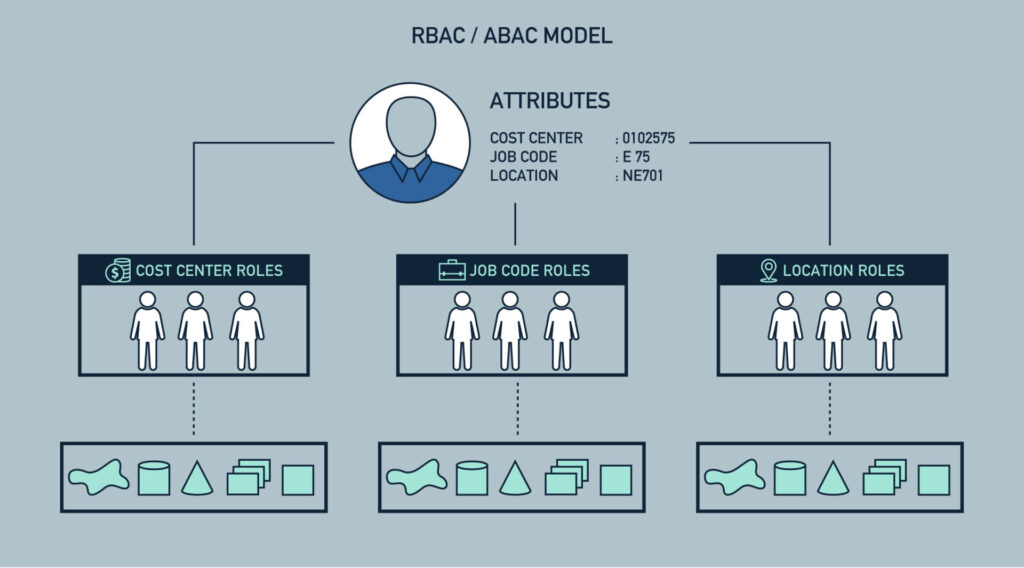
# 1. 基于角色的访问控制(RBAC)概述
在信息技术快速发展的今天,信息安全成为了企业和组织的核心关注点之一。在众多安全措施中,访问控制作为基础环节,保证了数据和系统资源的安全。基于角色的访问控制(Role-Based Access Control, RBAC)是一种广泛
【系统解耦与流量削峰技巧】:腾讯云Python SDK消息队列深度应用

# 1. 系统解耦与流量削峰的基本概念
## 1.1 系统解耦与流量削峰的必要性
在现代IT架构中,随着服务化和模块化的普及,系统间相互依赖关系越发复杂。系统解耦成为确保模块间低耦合、高内聚的关键技术。它不仅可以提升系统的可维护性,还可以增强系统的可用性和可扩展性。与
深入理解模块化编程:MATLAB模块库翻译与应用的核心概念

# 1. 模块化编程的基本原理
在软件工程领域,模块化编程被广泛采纳并视为创建可扩展、可维护软件的关键策略。它允许开发者将复杂系统分解为独立的功能模块,每个模块负责系统的一部分。这样,不仅使得代码的管理更为简单,还能够提高代码的复用性,降低系统整体的复杂度。
## 1.1 模块化编程的概念
模块化编程是将程序分解为独立、可替换的模块的一种编程范式。每个模块都有一组定义好的接口,通过这些接口与其它模块进行交互。这种方法的好处是,开发者可以独立地开发
【集成学习方法】:用MATLAB提高地基沉降预测的准确性

# 1. 集成学习方法概述
集成学习是一种机器学习范式,它通过构建并结合多个学习器来完成学习任务,旨在获得比单一学习器更好的预测性能。集成学习的核心在于组合策略,包括模型的多样性以及预测结果的平均或投票机制。在集成学习中,每个单独的模型被称为基学习器,而组合后的模型称为集成模型。该
【数据不平衡环境下的应用】:CNN-BiLSTM的策略与技巧

# 1. 数据不平衡问题概述
数据不平衡是数据科学和机器学习中一个常见的问题,尤其是在分类任务中。不平衡数据集意味着不同类别在数据集中所占比例相差悬殊,这导致模型在预测时倾向于多数类,从而忽略了少数类的特征,进而降低了模型的泛化能力。
## 1.1 数据不平衡的影响
当一个类别的样本数量远多于其他类别时,分类器可能会偏向于识别多数类,而对少数类的识别
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )