Optimization Tips for Query Results in DBeaver
发布时间: 2024-09-13 19:11:50 阅读量: 41 订阅数: 30 
# 1. **Optimization Tips for Query Result Sets in DBeaver**
1. **Introduction**
Why optimizing query result sets is important:
- Improves database query efficiency
- Reduces system resource consumption
- Enhances user experience
Introduction to DBeaver:
- DBeaver is a free, universal database management tool that supports multiple database systems, including MySQL, PostgreSQL, etc.
- It provides a powerful query editor and an environment for writing SQL.
In the following, we will discuss key techniques for optimizing query result sets in DBeaver.
# 2. **The Importance of Database Indexes**
Database indexes play a crucial role in optimizing query result sets. By creating and managing indexes properly, we can significantly improve the efficiency and performance of database queries.
#### 2.1 What are indexes and how do they work?
An index is a storage path, similar to the table of contents in a book, which helps a database quickly locate data records. It is essentially a data structure that arranges data according to certain rules to speed up data retrieval.
In databases, indexes are implemented using B-trees (Balanced Trees) or hash tables. When executing queries, the database engine can use indexes to quickly locate records that meet the conditions, rather than scanning the entire table one by one.
#### 2.2 Creating and Managing Indexes
The following table shows a SQL example for creating indexes on tables in DBeaver:
| SQL Statement | Description |
|-----------------------------------------------|------------------------------------------------|
| `CREATE INDEX idx_name ON table_name (column_name);` | Creates an index named `idx_name` on the `column_name` column of the `table_name` table |
| `DROP INDEX idx_name;` | Deletes the index named `idx_name` |
By creating indexes on appropriate fields and regularly maintaining and optimizing them, query performance can be greatly enhanced, and data retrieval time shortened.
#### 2.3 Advantages and Disadvantages of Indexes
Advantages of indexes:
- Improves data retrieval speed
- Accelerates data queries
- Reduces database I/O operations
Disadvantages of indexes:
- Increases database storage space
- Index maintenance adds to the time overhead of data writes
- Improper index design may lead to decreased performance
Through reasonable index design and management, the advantages of indexes can be fully utilized, enhancing the overall performance of the database.
# 3. **Fundamentals of Query Optimization**
In database query optimization, there are some basic techniques that can help us improve query efficiency. The following will introduce several key optimization points:
1. **Use of the WHERE clause**
-尽可能 Use the WHERE clause in query statements to filter data, reducing the size of the result set and avoiding full table scans.
2. **Optimizing JOIN operations**
- Choose appropriate JOIN types, such as INNER JOIN, LEFT JOIN, etc., to avoid performance degradation due to excessive JOINs.
3. **Avoid SELECT *** (asterisk)
- Avoid using SELECT * in queries; instead, specify the fields to be queried explicitly to reduce unnecessary data transfer and consumption.
The following example code shows a simple SQL query optimization:
```sql
-- Query for users with order amounts greater than 1000 and their corresponding order numbers
SELECT u.username, o.order_id
FROM users u
JOIN orders o ON u.user_id = o.user_id
WHERE o.amount > 1000;
```
4. **Use of Indexes**
- Indexes are key to optimizing query performance. Creating indexes on table fields can speed up data retrieval.
The following table shows the fields and indexes of two tables:
| Table Name | Field | Index |
|------------|--------------|-------------|
| users | user_id | Primary Key |
| orders | order_id | Primary Key |
| orders | user_id | Foreign Key |
Using appropriate indexes can improve query efficiency and reduce database query time. We will continue to explore more techniques for database query optimization in subsequent chapters.
In the process of optimizing database queries, these basic optimization strategies will have a significant impact on query efficiency. By applying WHERE clauses, JOIN optimization, and avoiding SELECT *, combined with the use of indexes, queries can be performed more efficiently and quickly.
# 4. **Using Appropriate Data Types**
Choosing the right data type in a database plays a crucial role in query performance. It can save storage space and improve query speed. The following will detail the impact of data type selection on query performance and a comparison of common data types.
1. **The impact of data type selection on query performance**
- The size of the data type directly affects the storage space of database tables. Smaller data types take up less space, reducing disk I/O, and thus improving query efficiency.
- More precise data types can provide better data constraints, helping to avoid data anomalies and errors, ensuring data quality.
2. **Comparison of common data types**
\# | Data Type | Description | Advantages | Disadvantages
---|-----------|-------------|------------|-------------
1 | INT | Integer type | Small storage space, fast calculation speed | Cannot store decimals
2 | VARCHAR | Variable length string | Saves space | Requires extra space to store length information
3 | DECIMAL | Fixed-point decimal | Accurate storage of decimals | Takes up more space
4 | DATE | Date type | Convenient date processing | Cannot store time
3. **Example Code: Using Appropriate Data Types**
```sql
-- Create a user table using appropriate data types
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
salary DECIMAL(10, 2),
created_at DATE
);
```
4. **Summary:**
- Data type selection should be determined based on actual needs and business scenarios to save storage space and improve query efficiency.
- Choosing the right data type based on the characteristics of different data types helps ensure data accuracy and consistency.
5. **Mermaid Flowchart Example:**
```mermaid
graph LR
A[Data Type Selection] --> B(Select Appropriate Data Types Based on Requirements)
B --> C{Do You Need to Accurately Store Decimals?}
C -- Yes --> D(Choose DECIMAL)
C -- No --> E(Choose Other Data Types)
```
By selecting data types reasonably, query performance can be optimized, enhancing the efficiency and stability of the database.
# 5. **Analysis of Execution Plans**
An execution plan is a set of steps created by a database to execute an SQL query. It shows how the database engine executes the query and provides important information about performance bottlenecks and optimization opportunities. By analyzing the execution plan, you can understand where the performance bottlenecks of the query are, thereby optimizing the query to improve efficiency.
#### **Importance**
- Understanding the execution plan can help you identify bottlenecks in queries for targeted optimization.
- The execution plan can be used to understand how the database engine processes queries, which helps improve query performance.
- You can perform index optimization and SQL restructuring based on information in the execution plan to achieve query optimization.
#### **Interpreting Key Information in the Execution Plan**
An execution plan generally includes the following key information:
- Table access order
- Connection type (such as inner join, outer join)
- Index usage
- Operation type (such as full table scan, index scan)
- Row count estimation
#### **Example Code**
```sql
-- View execution plan
EXPLAIN SELECT * FROM employees WHERE department_id = 10;
```
#### **Analysis of the Execution Plan**
In the above example, we used the `EXPLAIN` command to view the execution plan for the query of records in the `employees` table where `department_id` is 10. By viewing the execution plan, you can see how the database engine accesses the table and uses indexes, allowing for further optimization.
#### **Optimization Suggestions**
Based on the analysis of the execution plan, we can optimize queries:
- Ensure correct index usage
- Avoid full table scans and make full use of indexes
- Restructure queries to avoid unnecessary JOIN operations
#### **Flowchart**
```mermaid
graph LR
A[Start] --> B[Execute SQL Query]
B --> C[Get Execution Plan]
C --> D[Analyze Execution Plan]
D --> E[Apply Optimization Strategies]
E --> F[Apply Optimized Query]
F --> G[End]
```
Through the analysis of the execution plan above, we can better understand how queries are executed, find optimization potential, and improve query performance.
# 6. **Monitoring and Adjusting Buffer Pools**
In the process of database query optimization, monitoring and adjusting buffer pools is an essential step. The following will详细介绍 the role of buffer pools, parameter settings, monitoring tools, and adjustment techniques.
1. **Function and Parameter Settings of Buffer Pools**
The buffer pool is an area used to cache data and query results. By using the buffer pool, disk read and write operations can be reduced, thereby improving query performance. In DBeaver, we can adjust the size and behavior of the buffer pool by setting the following parameters:
| Parameter Name | Description |
|------------------------|------------------------------------------------|
| `shared_buffers` | Sets the size of the buffer pool in pages, with a default of 8MB |
| `effective_cache_size` | Estimates the amount of memory the system can use in cache |
| `work_mem` | Controls memory usage for sorting and hash operations |
2. **Tools and Techniques for Monitoring Buffer Pools**
In DBeaver, we can monitor and adjust the buffer pool using the following methods:
- View PostgreSQL system views, such as `pg_buffercache`
- Use the `pg_stat_insights` plugin to monitor buffer pool hit rates and space utilization
- Query system tables like `pg_settings` to view the current buffer pool parameter settings
3. **Example Code: Querying Buffer Pool Usage**
The following simple SQL query can help us understand the usage of the buffer pool:
```sql
SELECT
c.relname as table_name,
pg_size_pretty(pg_table_size(c.oid)) as table_size,
pg_size_pretty(pg_indexes_size(c.oid)) as index_size,
pg_size_pretty(pg_total_relation_size(c.oid)) as total_size
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE n.nspname NOT IN ('pg_catalog', 'information_schema')
ORDER BY pg_total_relation_size(c.oid) DESC;
```
4. **Flowchart: Buffer Pool Monitoring and Adjustment Process**
The flowchart drawn using Mermaid format shows the process of monitoring and adjusting buffer pools:
```mermaid
graph TD;
A[Start] --> B[Check Buffer Pool Hit Rate and Space Utilization];
B --> C{Do You Need to Adjust Parameters?};
C -- Yes --> D[Adjust Buffer Pool Parameters];
C -- No --> E[End];
```
By monitoring and adjusting buffer pools, we can better optimize query performance, improving the efficiency and responsiveness of the database system. In practical applications, setting buffer pool parameters reasonably according to specific scenarios and needs is very important.
# 7. **Advanced Optimization Techniques**
In this section, we will introduce some advanced query optimization techniques to help you further improve database query performance.
1. **Using Inline Views and Subqueries**
- Inline views are subqueries included in a query, which can simplify complex query logic.
- Subqueries are nested and executed within the main query, allowing for more complex query requirements to be fulfilled.
2. **Optimizing Range Queries**
- For range queries, try to avoid using broad conditions in the WHERE clause and consider introducing indexes or optimizing query conditions.
- When using BETWEEN and IN conditions, pay attention to the range size to avoid full table scans.
3. **Using Temporary Tables to Optimize Complex Queries**
- When dealing with complex queries, consider using temporary tables to reduce data processing and improve query efficiency.
4. **Code Example - Inline Views and Subqueries**
```sql
-- Example of an inline view
SELECT *
FROM (
SELECT column1, column2
FROM table1
WHERE column3 = 'value'
) AS inline_view
JOIN table2 ON inline_view.column1 = table2.column1;
```
5. **Flowchart - Query Optimization Decision Process**
```mermaid
graph TD;
A[Start] --> B(Check if Inline Views or Subqueries Can Be Used);
B --> C{Are Conditions Met?};
C -->|Yes| D(Write Inline Views or Subqueries);
C -->|No| E(Continue to the Next Optimization Step);
D --> F[Optimization Complete];
E --> G(Consider Optimizing Range Queries);
G --> H{Do You Need to Optimize?};
H -->|Yes| I(Optimize Range Query Conditions or Introduce Indexes);
H -->|No| J(Continue to the Next Optimization Step);
I --> K[Optimization Complete];
J --> L(Consider Using Temporary Tables to Optimize Complex Queries);
L --> M{Do You Need Temporary Tables?};
M -->|Yes| N(Create Temporary Tables for Optimization);
M -->|No| O(Optimization Complete);
N --> O;
```
Through the above advanced optimization techniques, you can better optimize query result sets in DBeaver, improving database query performance and efficiency.
---
This is the specific content of Chapter 7. Are you satisfied with this, or do you need me to provide you with more information?

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Xilinx FPGA与DisplayPort接口:10分钟快速掌握实战技巧
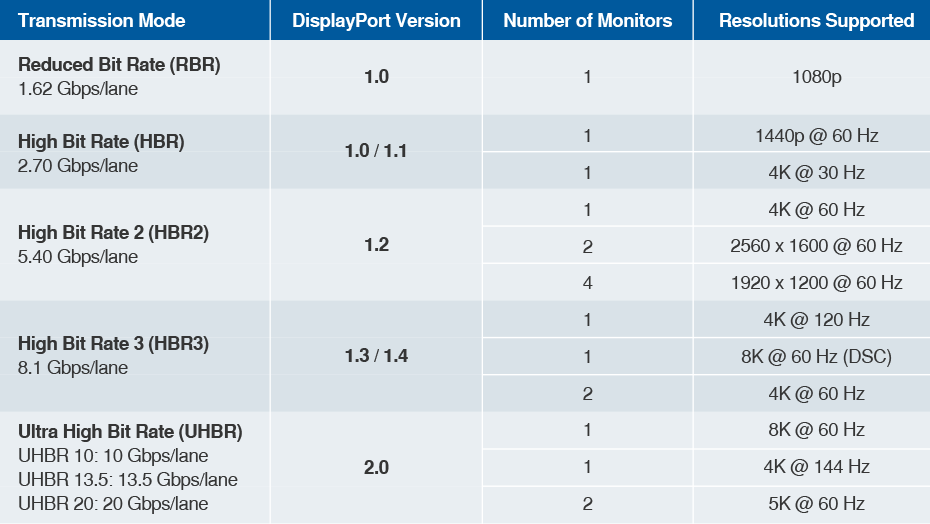
# 摘要
随着数字媒体和高分辨率显示技术的快速发展,Xilinx FPGA与DisplayPort接口的应用变得越来越广泛。本文旨在介绍Xilinx FPGA及其与DisplayPort接口的基础知识、协议详解、开发环境配置、实战技巧以及性能优化与故障排除。通过深入分析DisplayPort协议的演变和信号结构,并结合Xilinx FPGA
【力控组态脚本调试艺术】:提升脚本运行效率与稳定性的专家级技巧

# 摘要
力控组态脚本作为一种重要的工业自动化脚本语言,其稳定性和运行效率直接关系到工业系统的可靠性和性能。本文首先对力控组态脚本的基础知识进行了介绍,然后详细探讨了脚本调试的方法、性能分析工具的应用以及提升脚本效率的策略。此外,本文还阐述了确保脚本稳定性的实践方法,并介绍了力控组态脚本的高级应用,包括第三方工具的集成、跨平台脚本开发及安全性加固。通过综合运用各种优化技术与最佳实践,本文旨在为工业自动化领域中力控组
数据挖掘实操演习:从清洗到模型评估的全流程攻略

# 摘要
数据挖掘作为从大量数据中提取信息和知识的过程,已成为数据分析和机器学习领域的重要组成部分。本文首先介绍了数据挖掘的理论基础和应用场景,强调了数据预处理的重要性,并详细讨论了数据清洗、数据变换和特征工程的关键技巧与方法。随后,本文探讨了分类与回归模型、聚类分析和关联规则学习等数据挖掘模
PyCAD脚本编程:从新手到专家的10个技巧快速掌握

# 摘要
本文系统地探讨了PyCAD脚本编程的基础知识与高级应用,从基础绘图命令到3D建模与渲染技术,再到性能优化与实战演练。文章首先介绍了PyCAD脚本编程的基础和绘图命令的深入解析,包括层和属性的管理以及图形变换与编辑技术。其次,探讨了脚本编程实践中的参数化绘图、自动化任务脚
AI加速器内存挑战:如何通过JESD209-5B实现性能跃升

# 摘要
本文探讨了AI加速器内存技术的现状与挑战,并着重分析了JESD209-5B标准对于AI加速器内存性能的影响及其应用实践。文章首先概述了JESD209-5B标准的背景、技术细节以及对AI加速器的重要意义。随后,文章详细介绍了JESD209-5B标准在硬件实现、软件优化,以及在实际AI系统中的应用案例,并探讨了通过JESD209-
【操作系统设计:磁盘调度的深度探讨】:掌握关键算法,提升设计质量

# 摘要
磁盘调度算法是操作系统中用于提高磁盘I/O性能的关键技术。本文首先概述了磁盘调度的基本概念和重要性,随后介绍了几种基础磁盘调度算法(如FCFS、SSTF和SCAN),分析了它们的工作原理、优缺点以及性能评估。接着探讨了高级磁盘调度算法(包括C-SCAN、N-Step-SCAN和电梯算法)的特点和效率。第四章着眼于性能优化,涵盖了评价指标和动态调度策略,以及模拟实验的设计与结果分析。第五章研究了磁盘调度在现代操作系统
【流体动力学基础构建】:为热仿真奠定坚实的理论基础

# 摘要
流体动力学和热仿真作为工程科学中的重要分支,对于理解和预测流体行为及其在热传递过程中的作用至关重要。本文首先介绍了流体动力学的基本概念、原理及其数学描述和分析方法,随后探讨了热传递机制和热仿真的
GSM 11.11版本与物联网:把握新机遇与应对挑战的策略
# 摘要
本文首先概述了GSM 11.11版本的特点及其在物联网技术中的应用潜力,随后深入探讨了物联网的基础知识,包括其定义、组成、技术框架以及应用场景。重点分析了GSM 11.11版本与物联网融合的技术特点和应用实例,同时不忽视了由此产生的技术与市场挑战。此外,本文对物联网的安全问题进行了系统的分析,并提出了相应的安全防护措施和策略。最后,本文展望了物联网的发展趋势、商业前景以及政策环境,旨在为物联网的可持续发展提供洞见和策略支持。
# 关键字
GSM 11.11版本;物联网;技术框架;安全问题;安全防护;发展趋势
参考资源链接:[3GPP TS 11.11:GSM SIM-ME 接口规
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )