Basic Operation Guide: SQL Queries in DBeaver
发布时间: 2024-09-13 19:13:07 阅读量: 28 订阅数: 35 

pimtempelaars-sql-in-dbeaver.pdf
# 1. Introduction to DBeaver
DBeaver is a universal database management tool and SQL client that supports various database management systems, including MySQL, PostgreSQL, Oracle, etc. It offers robust SQL editors, data querying, data export and import functionalities, making it convenient for developers and database administrators to manage and query databases.
### Advantages of DBeaver
1. Free and Open Source: DBeaver is open-source software that can be used for free without additional costs.
2. Cross-Platform Support: DBeaver runs on multiple operating systems, including Windows, Linux, macOS, etc.
3. Multi-Database Support: DBeaver supports various database management systems, seamlessly connecting to different types of databases.
4. Graphical User Interface: DBeaver provides an intuitive user interface, making database operations and management user-friendly.
5. SQL Editor: DBeaver's SQL editor is feature-rich, offering syntax highlighting, code completion, and other functionalities.
### Installation and Configuration of DBeaver
To install and configure DBeaver, follow these steps:
- Download the installation file for DBeaver and install it on your computer.
- Open DBeaver and add a database connection.
- Configure the database connection parameters, including hostname, port number, username, password, etc.
- Test the connection to ensure the settings are correct and functional.
By following these steps, you can successfully install and configure DBeaver and begin utilizing its powerful database management and querying capabilities.
# 2. Connecting to a Database
In DBeaver, connecting to a database is the first step in performing any SQL queries and operations. Here, we will provide a detailed guide on how to connect to a database in DBeaver.
### Adding a Database Connection
First, open the DBeaver software. Select **Database** -> **New Database Connection** from the menu bar.
Next, choose the type of database you want to connect to, such as MySQL, PostgreSQL, SQLite, etc., from the pop-up window.
### Configuring Database Connection Parameters
When configuring the database connection parameters, you need to fill in the following information:
- **Hostname/IP Address**: The address of the host where the database resides.
- **Port Number**: The port number used by the database.
- **Database**: The specific database name you wish to connect to.
- **Username**: The username for logging into the database.
- **Password**: The corresponding login password.
### Testing the Connection
After filling in the parameters, click the **Test Connection** button. DBeaver will attempt to connect to the specified database. If the connection is successful, a message indicating success will be displayed.
Code Example:
```python
# Example code - connecting to a MySQL database
host = 'localhost'
port = '3306'
database = 'mydatabase'
username = 'myuser'
password = 'mypassword'
# Connecting to the database using DBeaver API
connection = dbeaver.connect(host, port, database, username, password)
if connection.is_connected():
print("Connected successfully!")
else:
print("Connection failed. Please check the parameters.")
```
Result Explanation:
- If the test connection is successful, a message indicating a successful connection will appear, and you can begin performing SQL queries.
- If the connection fails, an error message will be displayed, requiring a check of the parameters.
Mermaid Flowchart Example:
```mermaid
graph TD
A(Open DBeaver) --> B{Choose Database Type}
B --Choose--> C(Configure Parameters)
C --Fill in--> D(Test Connection)
D --Connection Successful--> E[Begin Querying]
```
By following these steps, you can successfully connect to a database and prepare to perform SQL queries and operations.
# 3. SQL Query Fundamentals
In this chapter, we will introduce the basic operations of SQL querying in DBeaver. Whether you are a beginner or an experienced user, by the end of this chapter, you will have learned how to write simple SELECT queries, sort and filter data, and use aggregate functions for data processing.
### Writing Simple SELECT Queries
In SQL, the SELECT statement is used to retrieve data from a database. Below is an example of a simple SELECT query:
```sql
SELECT * FROM users;
```
- **Scenario:** Retrieve information for all users.
- **Code Su

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
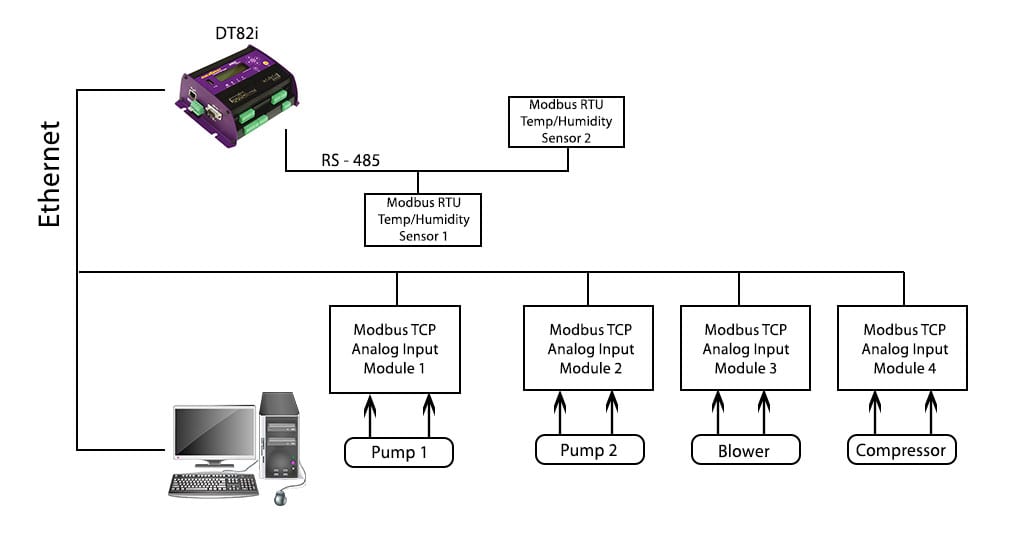
NModbus性能优化:提升Modbus通信效率的5大技巧
# 摘要
本文综述了NModbus性能优化的各个方面,包括理解Modbus通信协议的历史、发展和工作模式,以及NModbus基础应用与性能瓶颈的分析。文中探讨了性能瓶颈常见原因,如网络延迟、数据处理效率和并发连接管理,并提出了多种优化技巧,如缓存策略、批处理技术和代码层面的性能改进。文章还通过工业自动化系统的案例分析了优化实施过程和结果,包括性能对比和稳定性改进。最后,本文总结了优化经验,展望了NModbus性能优化技术的发展方向。
【Java开发者效率利器】:Eclipse插件安装与配置秘籍

# 摘要
Eclipse插件开发是扩展IDE功能的重要途径,本文对Eclipse插件开发进行了全面概述。首先介绍了插件的基本类型、架构及安装过程,随后详述了提升Java开发效率的实用插件,并探讨了高级配置技巧,如界面自定义、性能优化和安全配置。第五章讲述了开发环境搭建、最佳实践和市场推广策略。最后,文章通过案例研究,分析了成功插件的关键因素,并展望了未来发展趋势和面临的技
【性能测试:基础到实战】:上机练习题,全面提升测试技能

# 摘要
随着软件系统复杂度的增加,性能测试已成为确保软件质量不可或缺的一环。本文从理论基础出发,深入探讨了性能测试工具的使用、定制和调优,强调了实践中的测试环境构建、脚本编写、执行监控以及结果分析的重要性。文章还重点介绍了性能瓶颈分析、性能优化策略以及自动化测试集成的方法,并展望了
SECS-II调试实战:高效问题定位与日志分析技巧

# 摘要
SECS-II协议作为半导体设备通信的关键技术,其基础与应用环境对提升制造自动化与数据交换效率至关重要。本文详细解析了SECS-II消息的类型、格式及交换过程,包括标准与非标准消息的处理、通信流程、流控制和异常消息的识别。接着,文章探讨了SECS-II调试技巧与工具,从调试准备、实时监控、问题定位到日志分析
Redmine数据库升级深度解析:如何安全、高效完成数据迁移

# 摘要
随着信息技术的发展,项目管理工具如Redmine的需求日益增长,其数据库升级成为确保系统性能和安全的关键环节。本文系统地概述了Redmine数据库升级的全过程,包括升级前的准备工作,如数据库评估、选择、数据备份以及风险评估。详细介绍了安全迁移步骤,包括
YOLO8在实时视频监控中的革命性应用:案例研究与实战分析

# 摘要
YOLO8作为一种先进的实时目标检测模型,在视频监控应用中表现出色。本文概述了YOLO8的发展历程和理论基础,重点分析了其算法原理、性能评估,以及如何在实战中部署和优化。通过探讨YOLO8在实时视频监控中的应用案例,本文揭示了它在不同场景下的性能表现和实际应用,同时提出了系统集成方法和优化策略。文章最后展望了YOLO8的未来发展方向,并讨论了其面临的挑战,包括数据隐私和模型泛化能力等问题。本文旨在为研究人员和工程技术人员提供YOLO8
UL1310中文版深入解析:掌握电源设计的黄金法则

# 摘要
电源设计在确保电气设备稳定性和安全性方面发挥着关键作用,而UL1310标准作为重要的行业准则,对于电源设计的质量和安全性提出了具体要求。本文首先介绍了电源设计的基本概念和重要性,然后深入探讨了UL1310标准的理论基础、主要内容以及在电源设计中的应用。通过案例分析,本文展示了UL1310标准在实际电源设计中的实践应用,以及在设计、生产、测试和认证各阶段所面
Lego异常处理与问题解决:自动化测试中的常见问题攻略

# 摘要
本文围绕Lego异常处理与自动化测试进行深入探讨。首先概述了Lego异常处理与问题解决的基本理论和实践,随后详细介绍了自动化测试的基本概念、工具选择、环境搭建、生命周期管理。第三章深入探讨了异常处理的理论基础、捕获与记录方法以及恢复与预防策略。第四章则聚焦于Lego自动化测试中的问题诊断与解决方案,包括测试脚本错误、数据与配置管理,以及性
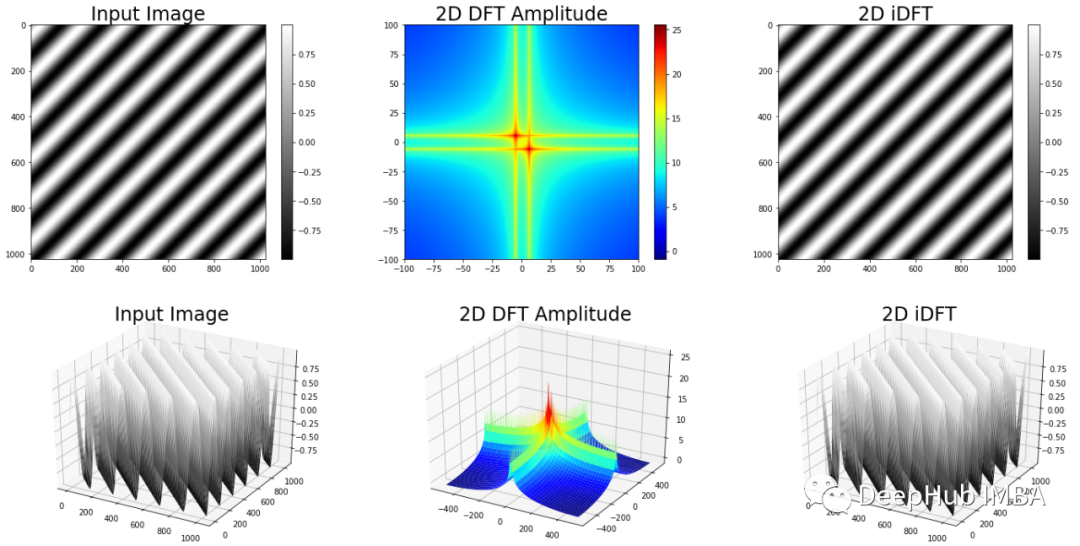
【Simulink频谱分析:立即入门】
# 摘要
本文系统地介绍了Simulink在频谱分析中的应用,涵盖了从基础原理到高级技术的全面知识体系。首先,介绍了Simulink的基本组件、建模环境以及频谱分析器模块的使用。随后,通过多个实践案例,如声音信号、通信信号和RF信号的频谱分析,展示了Simulink在不同领域的实际应用。此外,文章还深入探讨了频谱分析参数的优化,信号处理工具箱的使用,以及实时频谱分析与数据采
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )