Data Backup and Recovery Strategies in DBeaver
发布时间: 2024-09-13 19:29:53 阅读量: 18 订阅数: 23 
# 1. Introduction
## 1.1 What is a Data Backup and Recovery Strategy
A data backup and recovery strategy refers to a set of plans and measures devised to cope with data loss, corruption, or accidental deletion, with the aim of ensuring data security and reliability. By backing up different versions or states of data, it becomes possible to restore data promptly in the event of an意外, thereby preventing the permanent loss of important data.
In the realm of IT, a data backup and recovery strategy is a crucial aspect that safeguards data integrity and availability, and is also a vital component of information security management. Different backup strategies must be formulated for various data types and application scenarios to meet data protection requirements.
A data backup and recovery strategy generally includes steps such as developing a backup plan, selecting backup tools, executing backup operations, monitoring backup tasks, and performing periodic recovery tests, providing a comprehensive and systematic protection of data security. This article will focus on implementing an effective data backup and recovery strategy in DBeaver.
## 1.2 Why Implement an Effective Backup Strategy in DBeaver
DBeaver is a powerful, general-purpose database management tool that supports a variety of database systems, including MySQL, PostgreSQL, Oracle, etc., offering rich database operation features, such as data backup and recovery.
In real-world production environments, the data within databases is often one of the most critical assets of an organization or enterprise. Therefore, ensuring the security and reliability of database data is particularly important. By implementing an effective backup strategy in DBeaver, the safety of important data within databases can be protected, and data can be promptly restored in the face of data loss or corruption, minimizing the losses caused by data risks as much as possible.
DBeaver provides convenient and robust data backup and recovery functionality, helping users easily devise and execute data backup strategies to safeguard vital information within databases. Hence, implementing an effective backup strategy in DBeaver is not only a necessary measure but also an effective means of ensuring data security.
# 2. Overview of DBeaver Data Backup Tools
DBeaver is a powerful database management tool that supports various database types and offers rich data backup and recovery features. In this section, we will discuss the basic functions of backup and recovery in DBeaver and the supported data backup formats.
### 2.1 Basic Functions of Backup and Recovery in DBeaver
DBeaver provides a simple and intuitive interface, making data backup and recovery very easy. Here are the commonly used data backup and recovery functions in DBeaver:
- **Manual Backup and Recovery:** Users can perform manual backup and recovery operations through the graphical interface.
- **Scheduled Backup:** You can set up scheduled tasks to automatically perform backup operations, enhancing data security.
- **Backup History Records:** DBeaver records backup history information, facilitating the viewing and management of previous backup files.
- **Compressed Backup:** Users can choose to compress backup files to save storage space.
### 2.2 Supported Data Backup Formats
DBeaver supports a variety of data backup formats, including but not limited to:
| Data Backup Format | Description |
| ------------------ | ----------- |
| SQL | Backup data in the form of SQL statements, which is easy for cross-database migration |
| CSV | Backup data in comma-separated values format, which is easy for importing and exporting |
| Excel | Backup data in Excel file format, suitable for data analysis |
| XML | Backup data in XML format, suitable for storing structured data |
With support for multiple backup formats, DBeaver can meet the diverse needs of users and perform data backup and recovery operations flexibly.
```java
// Sample code: SQL format data backup in DBeaver
// Assuming the connection has been established and a specific database is selected
// Execute SQL backup operation
String backupFilePath = "C:/backup/backup.sql";
String tableName = "my_table";
String sqlQuery = "BACKUP TABLE " + tableName + " TO '" + backupFilePath + "';";
Statement stmt = connection.createStatement();
stmt.execute(sqlQuery);
stmt.close();
```
This is an overview of the basic functions of backup and r

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【特征工程稀缺技巧】:标签平滑与标签编码的比较及选择指南
# 1. 特征工程简介
## 1.1 特征工程的基本概念
特征工程是机器学习中一个核心的步骤,它涉及从原始数据中选取、构造或转换出有助于模型学习的特征。优秀的特征工程能够显著提升模型性能,降低过拟合风险,并有助于在有限的数据集上提炼出有意义的信号。
## 1.2 特征工程的重要性
在数据驱动的机器学习项目中,特征工程的重要性仅次于数据收集。数据预处理、特征选择、特征转换等环节都直接影响模型训练的效率和效果。特征工程通过提高特征与目标变量的关联性来提升模型的预测准确性。
## 1.3 特征工程的工作流程
特征工程通常包括以下步骤:
- 数据探索与分析,理解数据的分布和特征间的关系。
- 特
自然语言处理中的独热编码:应用技巧与优化方法
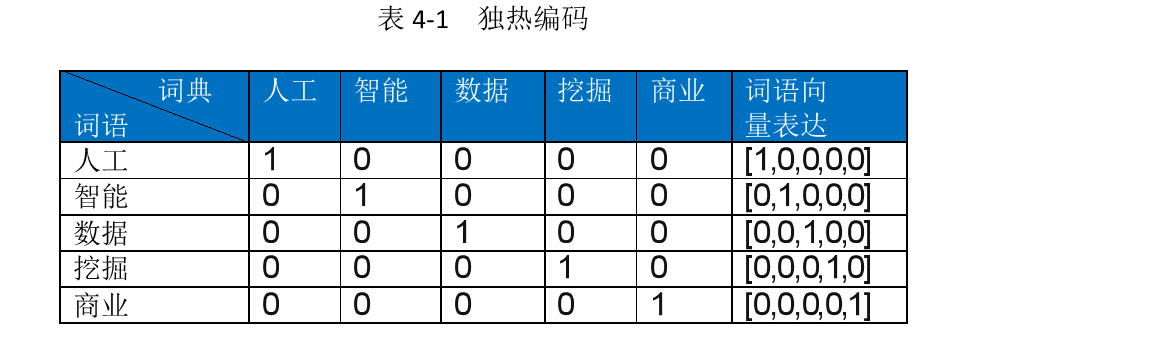
# 1. 自然语言处理与独热编码概述
自然语言处理(NLP)是计算机科学与人工智能领域中的一个关键分支,它让计算机能够理解、解释和操作人类语言。为了将自然语言数据有效转换为机器可处理的形式,独热编码(One-Hot Encoding)成为一种广泛应用的技术。
## 1.1 NLP中的数据表示
在NLP中,数据通常是以文本形式出现的。为了将这些文本数据转换为适合机器学习模型的格式,我们需要将单词、短语或句子等元
【统计学意义的验证集】:理解验证集在机器学习模型选择与评估中的重要性
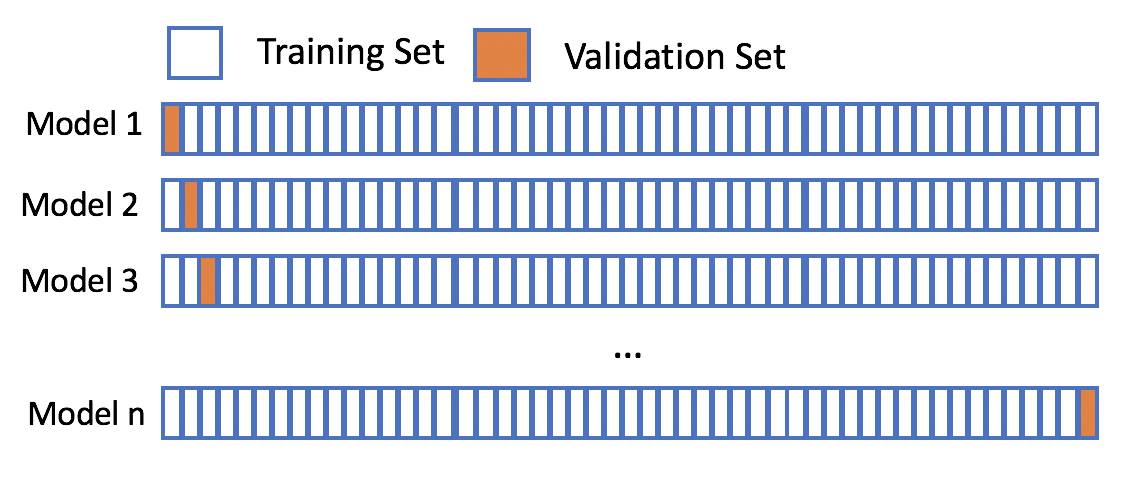
# 1. 验证集的概念与作用
在机器学习和统计学中,验证集是用来评估模型性能和选择超参数的重要工具。**验证集**是在训练集之外的一个独立数据集,通过对这个数据集的预测结果来估计模型在未见数据上的表现,从而避免了过拟合问题。验证集的作用不仅仅在于选择最佳模型,还能帮助我们理解模型在实际应用中的泛化能力,是开发高质量预测模型不可或缺的一部分。
```markdown
## 1.1 验证集与训练集、测试集的区
【PCA算法优化】:减少计算复杂度,提升处理速度的关键技术

# 1. PCA算法简介及原理
## 1.1 PCA算法定义
主成分分析(PCA)是一种数学技术,它使用正交变换来将一组可能相关的变量转换成一组线性不相关的变量,这些新变量被称为主成分。
## 1.2 应用场景概述
PCA广泛应用于图像处理、降维、模式识别和数据压缩等领域。它通过减少数据的维度,帮助去除冗余信息,同时尽可能保
【交互特征的影响】:分类问题中的深入探讨,如何正确应用交互特征

# 1. 交互特征在分类问题中的重要性
在当今的机器学习领域,分类问题一直占据着核心地位。理解并有效利用数据中的交互特征对于提高分类模型的性能至关重要。本章将介绍交互特征在分类问题中的基础重要性,以及为什么它们在现代数据科学中变得越来越不可或缺。
## 1.1 交互特征在模型性能中的作用
交互特征能够捕捉到数据中的非线性关系,这对于模型理解和预测复杂模式至关重要。例如
探索性数据分析:训练集构建中的可视化工具和技巧
# 1. 探索性数据分析简介
在数据分析的世界中,探索性数据分析(Exploratory Dat
过拟合的统计检验:如何量化模型的泛化能力

# 1. 过拟合的概念与影响
## 1.1 过拟合的定义
过拟合(overfitting)是机器学习领域中一个关键问题,当模型对训练数据的拟合程度过高,以至于捕捉到了数据中的噪声和异常值,导致模型泛化能力下降,无法很好地预测新的、未见过的数据。这种情况下的模型性能在训练数据上表现优异,但在新的数据集上却表现不佳。
## 1.2 过拟合产生的原因
过拟合的产生通常与模
失败是成功之母:从欠拟合案例中学到的经验
# 1. 欠拟合的定义和影响
## 1.1 欠拟合的基本概念
在机器学习领域,欠拟合(Underfitting)是一个常见的问题,它发生在模型无法捕捉到数据中
【时间序列分析】:如何在金融数据中提取关键特征以提升预测准确性

# 1. 时间序列分析基础
在数据分析和金融预测中,时间序列分析是一种关键的工具。时间序列是按时间顺序排列的数据点,可以反映出某
测试集在兼容性测试中的应用:确保软件在各种环境下的表现

# 1. 兼容性测试的概念和重要性
## 1.1 兼容性测试概述
兼容性测试确保软件产品能够在不同环境、平台和设备中正常运行。这一过程涉及验证软件在不同操作系统、浏览器、硬件配置和移动设备上的表现。
## 1.2 兼容性测试的重要性
在多样的IT环境中,兼容性测试是提高用户体验的关键。它减少了因环境差异导致的问题,有助于维护软件的稳定性和可靠性,降低后
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )