Solr 8.x 数据聚合与统计分析
发布时间: 2024-02-22 17:14:23 阅读量: 37 订阅数: 31 
# 1. Solr 8.x 简介和基础概念
## 1.1 Solr 8.x 概述
Apache Solr 是一个基于Apache Lucene的开源搜索平台,提供了强大的全文搜索和分析功能。Solr 8.x 是Solr的最新版本,具有许多新的特性和改进,使其成为当前流行的企业级搜索引擎之一。
Solr 8.x 主要特性包括分布式搜索、实时索引更新、动态集群节点添加和删除、内容复制和故障恢复、丰富的插件支持等。这些特性使得Solr 8.x 在处理大规模数据时表现出色,并且能够轻松集成到现有的企业应用中。
## 1.2 Solr 8.x 主要特性
Solr 8.x 主要特性包括:
- 增强的集群维护和自动容错能力
- 更快的实时更新性能
- 支持更多的语言和数据格式
- 支持更丰富的统计分析和数据聚合功能
- 优化的查询性能和更好的扩展性
- 改进的安全性和监控功能
## 1.3 Solr 8.x 数据聚合与统计分析概念简介
Solr 8.x 提供了强大的数据聚合和统计分析功能,通过使用聚合查询和统计分析查询,用户可以方便地从海量数据中获取有用的统计信息和分析结果。本章将介绍Solr 8.x中数据聚合和统计分析的基本概念,为后续章节的具体功能介绍做铺垫。
# 2. Solr 8.x 数据聚合功能介绍
在 Solr 8.x 中,数据聚合功能是非常重要的一部分,它可以帮助用户对大量数据进行快速、有效的聚合分析。本章将介绍 Solr 8.x 中数据聚合的基本功能、复杂功能以及聚合查询语法,帮助读者更深入地了解 Solr 8.x 数据聚合的应用和实践。
#### 2.1 基本聚合功能
Solr 8.x 提供了丰富的基本聚合功能,包括但不限于:
- Count 聚合:统计匹配文档的数量
- Sum 聚合:计算匹配文档某个字段的数值总和
- Average 聚合:计算匹配文档某个字段的平均值
- Min/Max 聚合:寻找匹配文档某个字段的最小/最大值
- 范围统计:统计某个字段在一定范围内的文档数量
以下是一个简单的 Solr 聚合查询示例(基于Python):
```python
import requests
url = 'http://localhost:8983/solr/my_collection/select?q=*:*&wt=json&indent=true&rows=0'
url += '&json.facet={ category_count:"termsfield:category" }'
response = requests.get(url)
data = response.json()
print(data['facets']['category_count'])
```
代码总结:上述代码通过 Solr 的 JSON facet API 实现了对字段 category 的计数聚合,并通过 Python 发起 HTTP 请求并解析 JSON 响应数据。
结果说明:以上代码将返回字段 category 的聚合统计结果,包括每个不同类别的文档数量。
#### 2.2 复杂聚合功能
除了基本聚合功能外,Solr 8.x 还支持复杂聚合功能,如:
- 嵌套聚合:在一个聚合结果的基础上执行另一个聚合
- 多字段聚合:对多个字段进行联合聚合分析
- 统计信息聚合:计算标准差、方差等统计信息
以下是一个 Solr 嵌套聚合的示例(基于Java):
```java
SolrClient solr = new HttpSolrClient.Builder("http://localhost:8983/solr/my_collection").build();
SolrQuery query = new SolrQuery("*:*");
query.setRows(0);
query.setParam("json.facet", "{ category_count:{ terms:{ field:category, limit:5, facet:{ avg_price:\"avg:price\" } } } }");
QueryResponse response = solr.query(query);
SimpleOrderedMap<Object> categoryCount = (SimpleOrderedMap<Object>) response.getResponse().findRecursive("category_count");
for (int i = 0; i < categoryCount.size(); i++) {
SimpleOrderedMap<Object> category = (SimpleOrderedMap<Object>) categoryCount.getVal(i);
System.out.println("Category: " + category.get("val") + ", Count: " + category.get("count") + ", Avg Price: " + category.get("avg_price"));
}
```
代码总结:上述 Java 代码利用 Solr 的 Java 客户端实现了嵌套聚合查询,统计了每个 category 下的文档数量,并计算了平均价格。
结果说明:以上代码将输出每个 category 的文档数量和平均价格。
#### 2.3 聚合查询语法介绍
除了上述的基本和复杂聚合功能外,Solr 8.x 还提供了丰富多样的聚合查询语法,例如 JSON Facet API、Bucket

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Apache Solr 8.x索引和搜索技术,旨在帮助读者全面了解并掌握Solr 8.x的使用。从介绍基本概念、快速安装配置到文档分析器详解,查询语法入门,再到高级查询技巧与索引性能调优,每篇文章都囊括了重要主题。此外,专栏还深入讨论了分页与结果分析、文本分析与多核索引管理等内容,涵盖了Solr 8.x的各个方面。不仅如此,还介绍了分布式索引与搜索架构、数据统计分析以及实时索引更新技术。最后,还提供了自定义插件开发指南,帮助读者更好地定制和优化Solr 8.x的应用。愿本专栏能为您提供全面、系统的Solr 8.x学习之路。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
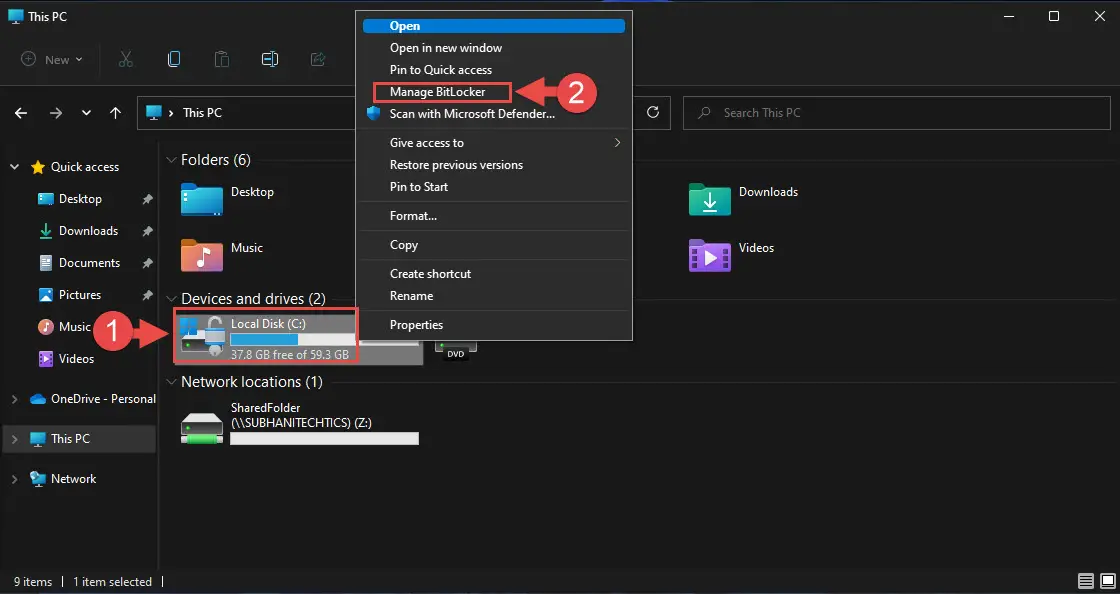
【数据安全必修课】:揭秘BitLocker加密下的WIN10系统重装数据恢复黄金策略(权威指南)
# 摘要
本文系统介绍了数据安全与BitLocker加密技术的概述、机制解析、WIN10系统重装前的数据备份策略、重装过程中的数据保护以及数据恢复黄金策略的实战演练。文章深入探讨了BitLocker的工作原理、部署与配置、以及安全特性,强调了BitLocker在数据备份与系统重装中的关键作用。同时,本文详细阐述了数据备份的重要性和BitLoc
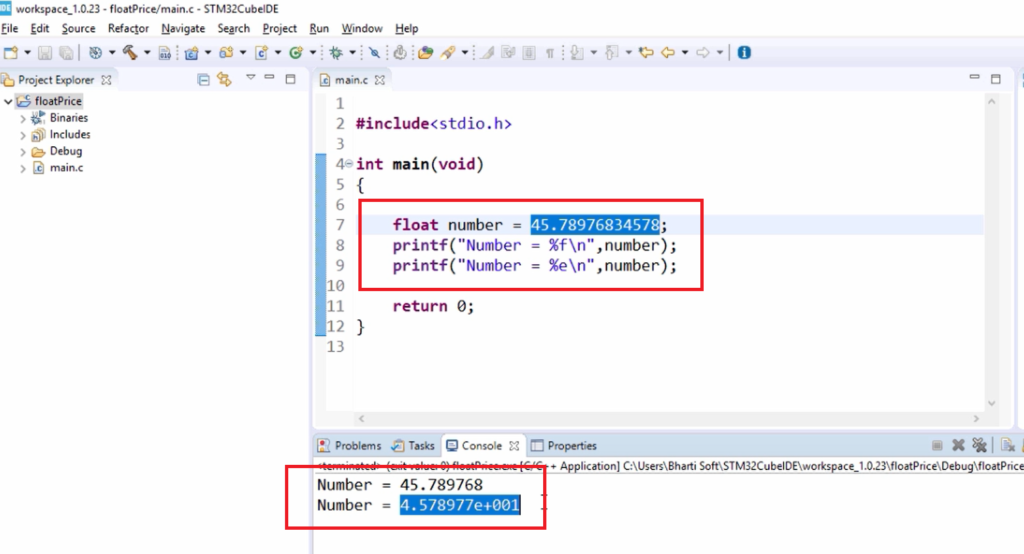
【C语言入门到精通】:掌握10个pta答案,从基础到实战的跨越式成长(一)
# 摘要
C语言作为一种广泛使用的编程语言,其基础和高级特性的掌握对于软件开发者至关重要。本文从C语言的基础语法讲起,逐步深入到核心语法和高级话题,包括变量、数据类型、运算符、控制结构、函数定义、指针、结构体联合体、动态内存管理以及文件操作和预处理器的使用。随后,文章通过实战演练章节深入浅出地介绍了开发环境的搭建、多种项目案例以及调试、优化和安全编程的最佳实践。本
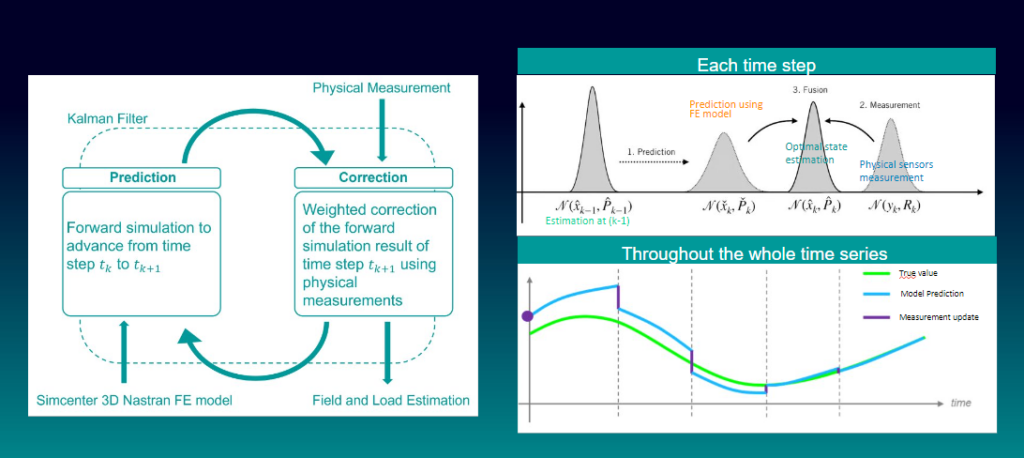
伯努利滤波器实践课:噪声消减技术的探索之旅(噪音终结者特训营)
# 摘要
噪声消减技术是提高信号质量的重要手段,尤其在语音和视频处理中起着至关重要的作用。本文首先概述了噪声消减技术的基础知识和应用背景。继而深入探讨了伯努利滤波器的理论基础,包括统计信号处理的基本概念、伯努利分布与过程,以及滤波器的设计原理和工作方式。通过实践章节,我们展示了伯努利滤波器的具体实现步骤、实验环境的
E2000变频器高级使用技巧:性能优化与故障处理

# 摘要
E2000变频器是工业自动化领域广泛应用的设备,本文对其进行全面概述,并详细介绍基础操作、性能优化策略、故障诊断与处理技巧,以及系统集成与网络通信的能力。重点探讨了硬件优化方法和软件参数设置,以提升变频器的运行效率和稳定性。同时,本文还分享了故障诊断的工具与方法,并提出了有效的故障排除和预防措施。此外,系统集成与网络通信章节强调了E2000变频器与上位机的集成及其远程监控与维护功能的
Element-ui el-tree局部刷新:提升用户体验的关键操作(快速解决数据变更问题)

# 摘要
Element-ui的el-tree组件是构建复杂树形结构用户界面的重要工具。本文全面介绍了el-tree组件的基本概念、局部刷新机制、实践操作方法、在实际项目中的应用以及高级功能定制。通过对el-tree组件的基础使用、局部刷新技术的实现和高级定制进行深入分析,本文不仅提供了节点操作与状态管理的最佳实
【坐标转换精通】:ZMap宗海图制作系统投影技术深入解析

# 摘要
本文系统地介绍了ZMap宗海图制作系统中的投影技术,涵盖从坐标转
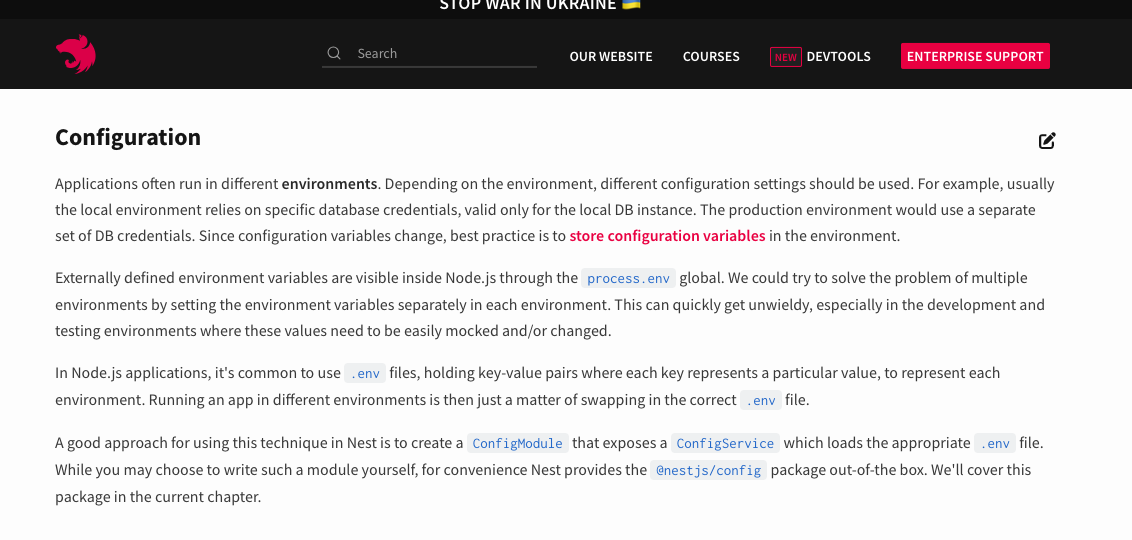
【环境变量终极指南】:对IT专业人士至关重要的配置解析
# 摘要
环境变量在软件开发和系统管理中扮演着关键角色,它们影响着程序行为和配置。本文详细介绍了环境变量的基础知识和配置管理方法,包括在不同操作系统中的具体实践,如Unix/Linux和Windows系统的特定配置。同时,探讨
ADS与实际电路对接:理论与实践的无缝融合技术
# 摘要
本论文系统介绍了高级设计系统(ADS)的原理与应用,从基础简介到模拟环境搭建,再到高频与射频微波电路设计的仿真技巧和实践,全面覆盖了ADS在电子工程设计中的关键作用。通过分析信号完整性分析和综合应用案例,本文强调了ADS在电路设计优化中的重要性,并提出了相应的设计优化方法。研究结果表明,ADS能有效辅助工程师解决复杂的电路设计挑
快速掌握Radiant:5个高级操作技巧提高工作效率

# 摘要
本文详细介绍了一款名为Radiant的集成开发环境(IDE)的核心功能及其应用。第一章介绍了Radiant的基本介绍和安装配置方法,第二章涵盖了界面布局和项目管理,强调了个性化定制和高效项目导航的重要性。第三章深入探讨了Radiant的高级编辑功能,包括文本处理、代码片段与模板的使用,以及调试工具。第四章涉及自动化工作流和插件生态,着重于任务自动化和插
【高性能计算可视化】:在ParaView中实现的高级技巧
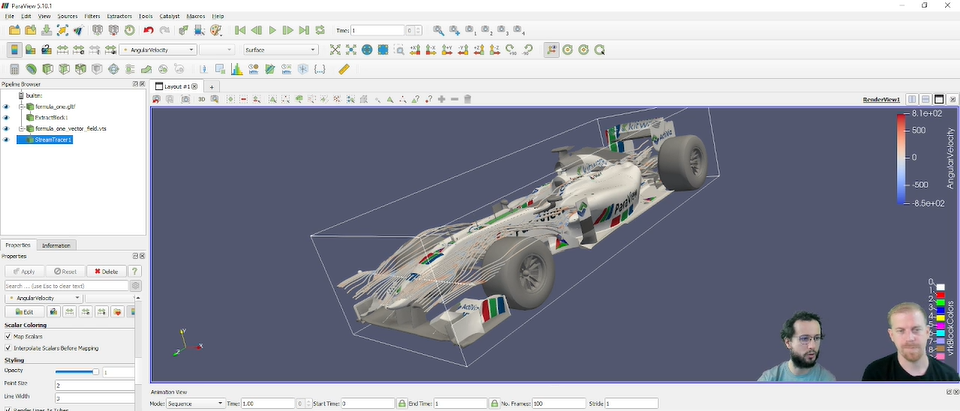
# 摘要
本文旨在为技术人员提供高性能计算可视化工具ParaView的全面指南。文章从基础理论和安装配置开始,逐步深入探讨数据处理、可视化技术,再到高级应用与实践案例分析。针对大规模数据集的处理技术、自定义过滤器开发及与HPC集群的集成,都提供了详细的策略和解决方案。此外,文章还展望了ParaView的未来发展趋势,讨论了其面临的技术挑战,并强调了开源社区在推动ParaView发展中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )