【精通Python时间处理】:从入门到专家的time模块案例与技巧
发布时间: 2024-10-07 06:28:23 阅读量: 6 订阅数: 9 

# 1. Python时间处理基础介绍
在编程的世界里,时间处理是一个不可或缺的功能。Python作为一种流行的编程语言,为开发者提供了丰富的工具和模块来处理时间相关的任务。本章将介绍Python处理时间的基本概念和方法,为深入学习后续章节打下坚实的基础。
## 时间和日期在Python中的表示
Python通过内置的`datetime`和`time`模块提供了对日期和时间的处理功能。在Python中,日期和时间可以被表示为`date`和`time`对象。而`datetime`对象则结合了日期和时间。
```python
from datetime import date, time, datetime
# 创建日期对象
d = date(2023, 4, 1)
print(d) # 输出: 2023-04-01
# 创建时间对象
t = time(13, 37, 42)
print(t) # 输出: 13:37:42
# 创建 datetime 对象
dt = datetime(2023, 4, 1, 13, 37, 42)
print(dt) # 输出: 2023-04-01 13:37:42
```
以上代码展示了如何使用`datetime`模块创建日期、时间和datetime对象。通过这种方式,我们可以轻松地在程序中表示和使用时间数据。
# 2. 深入解析Python time模块
## 2.1 时间表示与转换
### 2.1.1 理解时间戳的概念
时间戳是一个整数,表示从1970年1月1日00:00:00 UTC到现在的秒数,有时称为“Unix时间”或“POSIX时间”。在Python中,time模块提供了函数`time()`,它返回当前时间的时间戳。
```python
import time
timestamp = time.time()
print(f"当前时间的时间戳是:{timestamp}")
```
时间戳在进行时间计算、时间序列分析时非常有用,因为它提供了一种便于计算机处理的时间表示方法。
### 2.1.2 时间格式化和解析
时间的格式化指的是将时间表示为人类可读的字符串形式,而解析则是指将这样的字符串转换回时间数据结构。Python的`time`模块提供了`strftime`函数用于格式化时间和`strptime`函数用于解析时间字符串。
```python
import time
# 时间格式化示例
current_time = time.localtime()
formatted_time = time.strftime("%Y-%m-%d %H:%M:%S", current_time)
print(f"当前时间格式化为:{formatted_time}")
# 时间解析示例
time_string = "2023-03-14 12:34:56"
parsed_time = time.strptime(time_string, "%Y-%m-%d %H:%M:%S")
print(f"解析的时间为:{parsed_time}")
```
格式化和解析是处理时间数据时常见的需求,尤其是在处理日志文件和用户输入数据时。
## 2.2 时间计算与操作
### 2.2.1 基本的时间加减操作
Python的`time`模块提供了一系列函数,如`time.sleep(secs)`用于暂停当前程序的执行,`time.altzone`返回本地时区与UTC的偏移秒数,`time.daylight`表示是否实行夏令时等。
```python
import time
# 休眠操作示例
print("程序开始休眠10秒...")
time.sleep(10)
print("程序休眠结束。")
# 时区操作示例
print(f"本地时区偏移量(秒): {time.altzone}")
print(f"是否实行夏令时: {time.daylight}")
```
### 2.2.2 时间间隔和时区处理
处理时间间隔通常需要了解两个时间点之间的差异,Python的`time`模块提供了`time.perf_counter()`,可以用来测量高精度的时间间隔。
对于时区的处理,`time`模块中的`time.timezone`提供了本地时间与UTC时间的偏移量,但需要注意的是,现代Python开发更推荐使用`pytz`库来处理时区相关的问题,因为它提供了更为全面的时区数据。
```python
import time
# 高精度计时器示例
start_time = time.perf_counter()
# 执行一些操作
end_time = time.perf_counter()
elapsed_time = end_time - start_time
print(f"操作耗时:{elapsed_time}秒")
# 时区处理示例(推荐使用pytz库)
print(f"本地时间与UTC的偏移量(秒): {time.timezone}")
```
## 2.3 高级时间函数应用
### 2.3.1 本地时间和UTC时间转换
在处理时间数据时,经常需要在本地时间和UTC时间之间进行转换。`time.gmtime()`函数将时间戳转换为UTC时间,而`time.localtime()`将时间戳转换为本地时间。
```python
import time
# 将当前本地时间转换为UTC时间
local_time = time.localtime()
utc_time = time.gmtime()
print(f"本地时间: {local_time}")
print(f"UTC时间: {utc_time}")
```
### 2.3.2 时间的结构化表示
时间的结构化表示通常指的是将时间分解为年、月、日、时、分、秒等单独的部分。`time`模块中的`time.mktime()`函数可以将时间元组转换为时间戳,而`time.strptime()`用于将时间字符串解析成时间元组。
```python
import time
# 创建时间元组
time_tuple = time.strptime("2023-03-14 15:30:45", "%Y-%m-%d %H:%M:%S")
print(f"时间元组:{time_tuple}")
# 将时间元组转换为时间戳
timestamp = time.mktime(time_tuple)
print(f"对应的时间戳:{timestamp}")
```
以上就是对Python time模块的深入解析,覆盖了时间表示与转换、时间计算与操作以及高级时间函数应用的各个方面。掌握这些基础知识对于进行更复杂的时间处理任务至关重要。
# 3. Python datetime模块应用
时间是编程中不可或缺的数据类型之一,Python通过其标准库中的datetime模块提供了丰富的功能来处理日期和时间。这个模块集成了时间处理的核心功能,包括日期、时间、时间增量、时间格式化与解析以及时区处理等。本章将重点介绍datetime模块的创建、操作、高级特性和综合案例分析。
## 3.1 datetime对象的创建与操作
datetime模块中的datetime类是处理日期和时间最常用的一个类。它包含了有关日期和时间的信息,并允许对日期和时间进行比较、排序等操作。
### 3.1.1 datetime对象的生成
datetime对象可以使用其构造函数直接生成,也可以通过其他函数如today()、now()、 utcnow()等方法间接生成。
```python
from datetime import datetime
# 通过构造函数直接创建datetime对象
dt1 = datetime(2023, 4, 1, 12, 0, 0) # 2023年4月1日12点
# 获取当前时间的datetime对象
dt2 = datetime.now() # 结合时区信息
# 获取当前UTC时间的datetime对象
dt3 = datetime.utcnow() # 与dt2类似,但是没有时区信息
```
在创建datetime对象时,需要注意时间参数的顺序是年、月、日、时、分、秒(以及微秒,如果需要的话)。另外,now()和utcnow()方法可以获取当前时间和UTC时间,它们是根据系统的时间设置自动决定的,因此每次调用可能得到不同的结果。
### 3.1.2 datetime对象的比较和排序
datetime对象不仅表示时间的点,还支持比较操作。这意味着我们可以确定两个时间点哪个在前哪个在后,这对于排序时间序列数据尤为重要。
```python
from datetime import datetime
# 创建两个datetime对象
dt1 = datetime(2023, 4, 1, 12, 0, 0)
dt2 = datetime(2023, 4, 2, 12, 0, 0)
# 比较两个时间对象
if dt1 < dt2:
print("dt1 is earlier than dt2.")
elif dt1 > dt2:
print("dt2 is earlier than dt1.")
else:
print("dt1 and dt2 are equal.")
```
当处理包含datetime对象的列表时,可以通过sort()函数来对它们进行排序。
```python
from datetime import datetime
# 创建一些datetime对象
datetime_list = [
datetime(2023, 4, 3, 12, 0, 0),
datetime(2023, 4, 1, 12, 0, 0),
datetime(2023, 4, 2, 12, 0, 0)
]
# 对datetime对象列表进行排序
datetime_list.sort()
# 打印排序后的列表
for dt in datetime_list:
print(dt)
```
## 3.2 datetime类的高级特性
datetime类除了创建和操作日期时间对象外,还包含了一些高级特性,这些特性使得在处理日期和时间时更加灵活和强大。
### 3.2.1 时间的精度控制
在某些情况下,可能只需要日期或时间到特定的精度,比如只到年或月,或者只需要小时和分钟。datetime类提供了date()和time()这两个方法来分别获取日期和时间部分。
```python
from datetime import datetime
# 创建一个datetime对象
dt = datetime(2023, 4, 1, 12, 30, 45, 123456)
# 获取日期部分
date_part = dt.date() # datetime.date(2023, 4, 1)
# 获取时间部分
time_part = dt.time() # datetime.time(12, 30, 45, 123456)
```
### 3.2.2 深入理解strftime与strptime
strftime和strptime是datetime类中非常重要的两个方法,它们提供了字符串和datetime对象之间的转换功能。strftime用于将datetime对象格式化为字符串,而strptime则用于将字符串解析为datetime对象。
```python
from datetime import datetime
# 创建一个datetime对象
dt = datetime.now()
# 使用strftime将datetime对象格式化为字符串
formatted_str = dt.strftime('%Y-%m-%d %H:%M:%S') # 格式化为年-月-日 时:分:秒
# 使用strptime将字符串解析为datetime对象
dt_from_str = datetime.strptime(formatted_str, '%Y-%m-%d %H:%M:%S') # 从字符串解析datetime对象
```
strftime和strptime方法提供了非常丰富的格式化选项,可以使开发者精确控制日期时间的格式和解析规则。
## 3.3 综合案例分析
在实际应用中,datetime模块经常被用来处理时间序列数据,解决时间处理中的实际问题,或者在大型项目中应用。
### 3.3.1 解决实际问题的时间处理方法
假设我们有一个日志文件,其中每行记录了事件发生的时间戳。我们可以使用datetime模块来解析这些时间戳,并根据事件的时间来排序或过滤日志。
```python
from datetime import datetime
# 假设日志文件中的日志条目,每条记录的时间戳格式为YYYY-MM-DD HH:MM:SS
log_entries = [
"2023-04-01 12:00:00 Event1 happened.",
"2023-04-01 11:30:00 Event2 happened.",
"2023-04-02 13:45:00 Event3 happened."
]
# 解析时间戳,并创建datetime对象
parsed_entries = []
for entry in log_entries:
dt_str = entry.split()[0] # 提取时间字符串
dt = datetime.strptime(dt_str, "%Y-%m-%d %H:%M:%S") # 格式化为datetime对象
parsed_entries.append((dt, entry))
# 根据时间排序日志条目
sorted_entries = sorted(parsed_entries, key=lambda x: x[0])
# 打印排序后的日志条目
for entry in sorted_entries:
print(entry[1])
```
### 3.3.2 datetime模块在大型项目中的应用
在大型项目中,时间处理往往需要精确到毫秒或者更小的单位,以满足实时或近乎实时的业务需求。例如,在金融应用中处理交易时间,或者在社交媒体应用中记录用户行为的准确时间。datetime模块能够提供这种高精度的时间处理功能。
```python
from datetime import datetime
# 记录交易的datetime对象,精确到微秒
trade_datetime = datetime.now()
# 存储交易时间到数据库
# (这里只展示逻辑,并未展示实际的数据库操作代码)
```
使用datetime对象存储这些时间数据,可以确保时间的准确性和一致性。另外,当需要对时间数据进行查询、分析或其他操作时,datetime模块可以提供必要的支持。
通过本章的介绍,我们已经深入了解了Python datetime模块的应用,从创建和操作datetime对象到利用其高级特性解决实际问题。下一章我们将继续探索Python时间处理的实践技巧,包括时间序列数据处理、异常处理、边界条件处理以及第三方库的应用等。
# 4. Python时间处理的实践技巧
时间处理是软件开发中不可或缺的一部分,熟练掌握时间处理技巧对于开发高效率、高质量的应用程序至关重要。本章将通过实践案例分析和具体技巧介绍,带你走进Python时间处理的进阶世界。
## 4.1 时间序列数据处理
在处理时间序列数据时,我们通常需要生成时间序列,并对序列中的时间数据进行解析和分析。这种方法在金融分析、日志记录、数据科学等领域应用广泛。
### 4.1.1 序列生成与解析
Python标准库中包含了`datetime`和`timedelta`类,可以用于生成连续的时间序列。例如,我们可以使用`timedelta`来计算过去或未来特定时间长度的日期和时间。
```python
from datetime import datetime, timedelta
# 生成一个时间序列
start_date = datetime.now()
sequence_dates = [start_date + timedelta(days=x) for x in range(5)]
# 输出时间序列
for d in sequence_dates:
print(d)
```
在生成序列时,可能会遇到跨越夏令时调整等情况。这种情况下,时间序列中的时间戳可能会出现重复或者跳变,处理这种情况需要特别注意。
### 4.1.2 序列数据的时间分析
时间序列数据的分析包括计算周期性事件、识别趋势和季节性因素等。在Python中,pandas库提供了强大的时间序列分析工具。
```python
import pandas as pd
# 创建时间序列数据
dates = pd.date_range(start='***', periods=5, freq='D')
data = [100, 105, 110, 120, 130]
series = pd.Series(data, index=dates)
# 计算日均值
print(series.resample('D').mean())
# 计算周趋势
print(series.resample('W').mean())
```
在这个例子中,`resample`函数用于对时间序列数据进行重新采样,计算不同周期的平均值。
## 4.2 时间处理中的异常和边界条件
在时间处理过程中,会遇到各种异常和边界条件。有效处理这些情况是保证程序健壮性的重要一环。
### 4.2.1 错误处理机制
在进行时间计算时,可能会遇到如日期格式不正确、时间戳超出可处理范围等错误。Python的时间处理模块提供了异常处理机制来捕捉和解决这些错误。
```python
from datetime import datetime
try:
# 尝试解析一个非法的日期字符串
date_time = datetime.strptime("2023-02-30", "%Y-%m-%d")
except ValueError as e:
print("Error:", e)
```
在上述代码中,`ValueError`异常被用来捕获因日期字符串格式不正确而无法解析的情况。
### 4.2.2 边界条件下的时间处理
处理夏令时、闰年以及日期的边界值(如1月1日或12月31日)等问题,需要程序员考虑这些特殊的边界条件。
```python
from datetime import datetime, timedelta
# 处理闰年情况
def is_leap_year(year):
return year % 4 == 0 and (year % 100 != 0 or year % 400 == 0)
# 示例
if is_leap_year(2020):
print("2020 is a leap year")
else:
print("2020 is not a leap year")
```
此函数判断给定的年份是否是闰年,能够帮助处理涉及日期计算时的边界条件。
## 4.3 第三方库的补充功能
Python的第三方库提供了额外的功能,能够帮助我们更高效地处理时间数据。
### 4.3.1 pandas在时间数据处理中的应用
pandas库提供了数据框(DataFrame)和时间序列(Series)对象,这些对象对于时间数据的处理非常有用。
```python
import pandas as pd
# 创建时间序列DataFrame
dates = pd.date_range('***', periods=5)
df = pd.DataFrame({'Value': [100, 105, 110, 120, 130]}, index=dates)
# 重采样并计算周平均值
weekly_avg = df['Value'].resample('W').mean()
print(weekly_avg)
```
### 4.3.2 使用arrow库进行更高效的时间处理
`arrow`库是对Python标准库中`datetime`的增强,它提供了更简单的API和更好的国际化支持。
```python
import arrow
# 获取当前时间
current_time = arrow.now()
# 转换为特定时区
new_york_time = current_time.to('America/New_York')
print(new_york_time)
```
在这个例子中,`to`函数用来转换时间到指定的时区,这对于处理跨时区的时间数据特别有用。
第四章内容到此结束,通过本章的介绍,我们已经了解了时间序列数据的处理方法、异常和边界条件的处理技巧,以及如何使用pandas和arrow等第三方库提高时间处理的效率。接下来,第五章将深入探讨Python时间处理的性能优化方法,帮助开发者编写出更加快速和高效的代码。
# 5. Python时间处理的性能优化
性能优化是编程中不可或缺的一环,尤其是在处理大规模数据集时,时间处理的效率尤为重要。在Python中,虽然标准库提供了丰富的时间处理功能,但在实际应用中,开发者可能会遇到性能瓶颈。本章将从性能分析入手,探索优化策略,并通过实战案例来展示如何将这些优化策略应用到实际问题中。
## 5.1 时间处理性能分析
性能分析是优化过程的第一步。了解当前时间处理的性能状况,才能有的放矢地进行优化。
### 5.1.1 理解时间处理的性能瓶颈
在时间处理中,性能瓶颈可能出现在多个环节。例如,在使用`datetime`对象进行大量日期时间计算时,频繁的内存分配和释放可能成为性能的拖累。此外,对于需要频繁进行字符串与时间对象转换的操作,性能问题同样不容忽视。
为了更好地理解性能瓶颈,可以使用Python的`timeit`模块来测量代码片段的执行时间。以下是一个使用`timeit`模块的简单例子:
```python
import datetime
import timeit
# 测试时间创建的性能
timeit_setup = "from datetime import datetime"
timeit_code = """
now = datetime.datetime.now()
execution_time = timeit.timeit(stmt=timeit_code, setup=timeit_setup, number=100000)
print(f"创建10万个datetime对象的平均时间: {execution_time / 100000:.6f} 秒")
```
### 5.1.2 性能基准测试和分析
基准测试为开发者提供了一个量化的数据基础,用以对比不同优化方法的效果。在Python中,可以使用`timeit`进行微观基准测试,而`benchit`等第三方库则提供了一套完整的基准测试框架。
为了进行时间处理的基准测试,我们可以设置一系列具有代表性的任务,例如时间的解析、格式化、加减运算等,并分别测量它们的执行时间。
```python
import benchit
# 定义需要进行基准测试的函数
def time_format():
for _ in range(1000):
datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def time_strptime():
for _ in range(1000):
datetime.datetime.strptime("2023-01-01 12:00:00", "%Y-%m-%d %H:%M:%S")
# 创建一个benchit对象
t = benchit.Benchit()
# 将函数添加到基准测试
t.add("format", time_format)
t.add("strptime", time_strptime)
# 执行基准测试并打印结果
print(t.run().mean())
```
以上代码将会输出每个函数的平均运行时间,为性能优化提供依据。
## 5.2 优化策略与技巧
了解了性能瓶颈之后,接下来我们探讨一些常见的优化策略和技巧。
### 5.2.1 算法优化
算法优化通常是提升性能最直接的方式。例如,使用更高效的时间计算方法,减少不必要的内存分配,或者通过缓存技术来避免重复计算。
以下是一个简单的缓存例子,使用Python的`functools.lru_cache`装饰器来缓存`datetime`对象格式化的结果:
```python
from datetime import datetime
from functools import lru_cache
@lru_cache(maxsize=None)
def format_date(date):
return date.strftime("%Y-%m-%d %H:%M:%S")
# 大规模数据集的时间处理优化实例
for date in [datetime.now() for _ in range(100000)]:
format_date(date)
```
### 5.2.2 使用Cython等技术提升性能
Cython是一个优化过的Python超集,它可以将Python代码编译成C代码,从而提高执行速度。对于时间处理的性能敏感的应用,可以考虑使用Cython来重写性能瓶颈部分的代码。
```cython
# 编译后的Cython代码示例
import cython
@cython.boundscheck(False)
@cython.wraparound(False)
def cython_format_date(cython.declare(datetime.datetime) date):
return date.strftime("%Y-%m-%d %H:%M:%S")
# 测量Cython编译后函数的性能
execution_time_cython = timeit.timeit("cython_format_date(datetime.datetime.now())", setup="import cython", number=100000)
print(f"Cython版本的函数执行时间: {execution_time_cython:.6f} 秒")
```
## 5.3 实战案例与总结
最后,我们将通过实战案例来综合运用性能优化策略,并对整个章节进行总结。
### 5.3.1 大规模数据集的时间处理优化实例
假设我们有一个需求,需要处理一个包含10万条记录的日志文件,每条记录都包含一个时间戳,我们需要将其转换为可读的日期时间格式。
在未经优化的情况下,使用标准库的`datetime`模块进行处理可能会非常缓慢。为了优化这一过程,我们可以采用多线程技术以及批处理的方式来加速处理过程。
```python
import threading
from queue import Queue
def thread_task(q):
while not q.empty():
date_str = q.get()
datetime.datetime.strptime(date_str, "%Y-%m-%d %H:%M:%S")
q.task_done()
# 创建队列并填充数据
date_queue = Queue()
for _ in range(100000):
date_queue.put("2023-01-01 12:00:00")
# 创建并启动线程
threads = []
for i in range(10):
t = threading.Thread(target=thread_task, args=(date_queue,))
t.start()
threads.append(t)
# 等待所有任务完成
date_queue.join()
# 等待所有线程完成
for t in threads:
t.join()
print("时间处理完毕")
```
在这个案例中,我们使用了线程池来处理任务,而队列则用于任务分配和结果收集,从而实现了并行处理,提高了性能。
### 5.3.2 时间处理经验总结与展望
通过本章节的介绍,我们了解了性能分析的重要性以及多种优化策略。开发者应根据实际应用的需求和场景,选择合适的优化技术。在未来,随着硬件的发展和Python语言的进步,时间处理将会变得更加高效。例如,Python的异步编程模式为时间处理提供了新的可能性,这值得开发者持续关注。
以上就是关于Python时间处理的性能优化的介绍。在实际应用中,性能优化可能还需要考虑很多其他的因素,例如系统架构、硬件资源和并发模型等。但无论如何,性能分析和优化策略的运用都应作为开发者工具箱中的重要工具。
# 6. Python时间处理的高级应用
随着技术的发展,Python在时间处理方面不断更新迭代,引入了更多高级特性和应用。本章将探讨Python时间处理的国际化处理、在Web框架中的应用以及未来的发展趋势。
## 6.1 时间的国际化处理
国际化处理是软件开发中不可或缺的一个环节,它确保应用程序可以适应不同地区的用户。Python的时间处理同样遵循这一原则,提供了多种机制来支持时间的本地化表示。
### 6.1.1 本地化的时间表示
Python的`locale`模块可以让我们根据不同的地区来设置时间和日期的显示格式。这对于创建多语言应用程序是至关重要的。
```python
import locale
import time
# 设置地区为美国英语
locale.setlocale(locale.LC_TIME, 'en_US.UTF-8')
# 打印本地化的星期表示
for i in range(7):
print(time.strftime('%A', time.gmtime(time.localtime().tm_wday == i)))
```
上述代码将输出星期几的本地化表示,例如"Monday"、"Tuesday"等。
### 6.1.2 时区的复杂转换与应用
处理时区可以使用`pytz`库,它提供了对时区数据的丰富支持。通过`pytz`库,可以轻松实现不同地区的时间转换。
```python
import pytz
from datetime import datetime
# 创建一个时区感知的datetime对象
eastern = pytz.timezone('US/Eastern')
naive_datetime = datetime(2023, 4, 1, 12, 0, 0)
localized_datetime = eastern.localize(naive_datetime)
# 转换为另一个时区
pacific = pytz.timezone('US/Pacific')
pacific_time = localized_datetime.astimezone(pacific)
print(pacific_time)
```
这段代码首先创建了一个位于美国东部时区的时间对象,然后将其转换为太平洋时区的时间。
## 6.2 时间在Web框架中的应用
Web开发中,时间处理经常出现在用户界面、API端点等位置。Python的两大主要Web框架Django和Flask对时间处理提供了广泛的支持。
### 6.2.1 Django和Flask中的时间处理
在Django中,模型的`DateTimeField`可以自动处理时间的存储和检索。同时,Django还提供了`timezone`模块来支持时区处理。
```python
from django.utils import timezone
# 获取当前时间,时区感知
now = timezone.now()
# 使用Django模板中的日期过滤器格式化时间
from django.template import Template, Context
t = Template('{{ now|date:"Y-m-d H:i" }}')
c = Context({'now': now})
print(t.render(c))
```
对于Flask,`moment.js`是一个流行的JavaScript库,用于处理日期和时间。Flask结合`moment.js`可以提供强大的前端时间处理功能。
### 6.2.2 时间验证和格式化在API中的应用
在设计RESTful API时,经常需要处理和验证客户端发送的时间数据。Python的`marshmallow`库可以定义序列化方案来验证和格式化时间数据。
```python
from marshmallow import Schema, fields, validate
class EventSchema(Schema):
start_time = fields.DateTime(
format='%Y-%m-%dT%H:%M:%SZ',
required=True,
validate=validate.Range(
min=timezone.now()
)
)
# 示例数据
event_data = {'start_time': '2023-04-01T14:30:00Z'}
# 验证数据
schema = EventSchema()
result = schema.load(event_data)
print(result)
```
上述代码定义了一个事件序列化器,确保时间格式正确并满足特定的时间条件。
## 6.3 时间处理的未来趋势
随着时间处理需求的不断增长,Python也在不断地引入新的特性和改进来适应这一需求。
### 6.3.1 新兴Python版本的时间特性
Python的未来版本中,可能会出现新的时间处理特性,例如更细粒度的时间精度、新的时区处理机制,或者对旧有API的改进。
### 6.3.2 时间处理在人工智能中的应用
人工智能(AI)领域需要处理大量的时间序列数据,Python在这一方面也具有强大的支持。例如,使用`scikit-learn`处理时间序列数据,或者在深度学习模型中处理时间依赖关系。
在所有这些趋势中,Python开发者需要保持对语言更新的关注,并且灵活地应用新工具和库来满足日益增长的时间处理需求。随着时间处理技术的不断发展,Python社区也会持续提供支持,帮助开发者更高效、准确地处理时间数据。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Python编程实践】:Winreg模块在应用配置管理中的巧妙运用

# 1. Winreg模块的简介与配置管理基础
在现代IT运营中,Windows注册表管理是一个不可或缺的环节。Winreg模块是Python标准库的一部分,旨在提供对Windows注册表的访问和操作。通过它,开发者可以以编程方式读取、修改、创建或删除注册表项和值,这对于系统配置、应用部署和软件维护至关重
【Django缓存安全性探讨】

# 1. Django缓存机制概述
在Web开发中,缓存是提升性能和扩展性的关键技术之一。Django,作为一个功能强大的Python Web框架,提供了丰富的缓存支持,可以帮助开发者减轻数据库的
Twisted Python中的日志记录和监控:实时跟踪应用状态的高效方法

# 1. Twisted Python概述和日志记录基础
## 1.1 Twisted Python简介
Twisted是Python编程语言的一个事件驱动的网络框架。它主要用于编写基于网络的应用程序,支持多种传输层协议。Twisted的优势在
【django.views.generic.list_detail与第三方服务集成】:邮件、消息推送等服务的无缝集成

# 1. Django视图基础与通用类视图介绍
在这一章中,我们将从基础层面了解Django框架的视图系统,并深入探讨其通用类视图的组成和作用。Django作为一款流行的Python Web框架,其内置的通用类视图(generic class-based views)极大地方便了开发者的编程工作,通过继承已有的类视图,可以
【Python时间模块的创新应用】:开发独特功能的时间相关技巧
# 1. Python时间模块基础
Python作为一门强大的编程语言,不仅提供了丰富的模块库,而且还内置了一些非常实用的功能模块。其中,Python的时间模块是一个经常被应用到各种项目中的功能模块,它提供了多种处理日期和时间的工具。掌握时间模块的基础知识是进行更高级时间处理的先决条件。本章节将带你了解Python时间模块的基本用法,让你在编程时能够轻松处理时间数据。
## 1.1 获取当前时间
要开始使用Python的时间模块,第一步通常是要获取当前时间。Python标准库中的`datetime`模块可以轻松完成这一任务。以下是一段示例代码:
```python
import dat
【os模块与Numpy】:提升数据处理速度,文件读写的优化秘籍

# 1. os模块与Numpy概述
在现代数据科学和软件开发中,对文件系统进行有效管理以及高效地处理和分析数据是至关重要的。Python作为一种广泛使用的编程语言,提供了一系列内置库和工具以实现这些任务。其中,`os`模块和`Numpy`库是两个极其重要的工具,分别用于操作系统级别的文件和目录管理,以及数值计算。
`os`模块提供了丰富的方法和函数,这些方法和函数能够执行各种文件系统操作,比如目录和文件
Python datetime模块时间序列分析:深入理解时间周期性的10个技巧
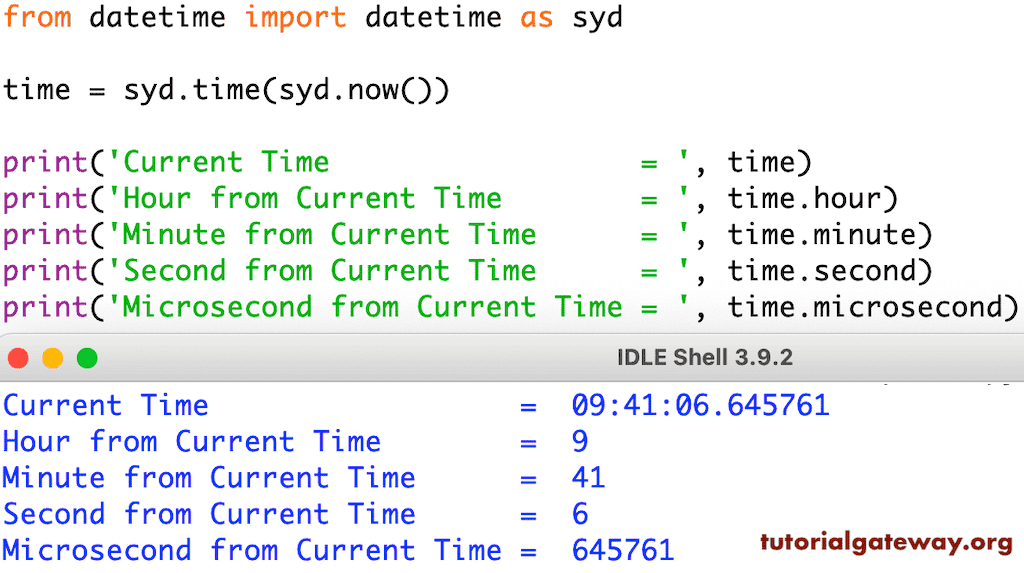
# 1. Python datetime模块概述
## 1.1 datetime模块的作用与重要性
Python的datetime模块是处理日期和时间的标准库之一。它提供了一套丰富的接口,用于获取系统当前时间、创建日期时间对象、执行时间计算以及格式化日期时间数据等。无论是在数据分析、日志记录还是系统监控等众多场景中,datetime模块都扮演着至关重要的角色,使得开发人员能够更加简便地处理时间信息,
【国际化随机数生成】:应对文化差异的Python随机数处理策略
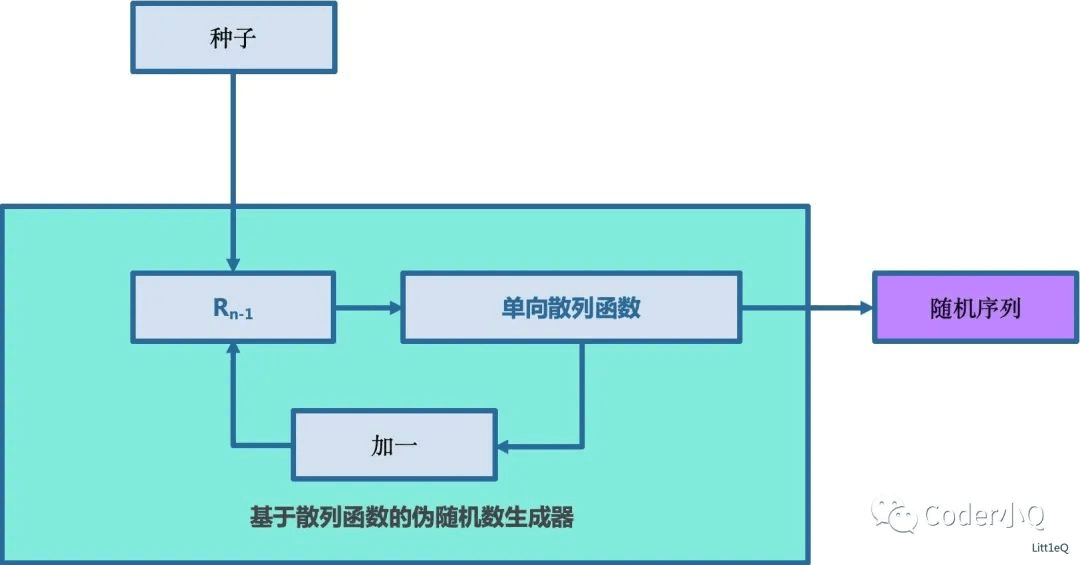
# 1. 随机数生成基础与文化差异概述
## 1.1 随机数的重要性与应用场景
随机数在软件开发、数据分析、游戏设计、安全加密等多个领域扮演着至关重要的角色。例如,密码学中的密钥生成、模拟测试中的数据构建、游戏中的事件触发等都离不开随机数。了解随机数的生成原理和应用方法,对于提高程序的健壮性和用户体验至关重要。
## 1.2 随机数的文化差异
不同文化背景下对随机性的看法不同,这些差异影响了随机数的
【Site模块扩展与自定义】:打造个性化模块加载解决方案

# 1. Site模块扩展与自定义概述
Site模块扩展与自定义是IT行业中,特别是开发领域不断被讨论的话题。它涉及到软件系统灵活度的提升、功能的扩展以及用户个性化需求的满足。本章节将简明扼要地介绍Site模块扩展与自定义的概念、目的以及在实际工作中的应用。
## 1.1 Site模块扩展与自定义的意义
Site模块扩展与自定义意味着开发者可以根据业务需求或技术创新,对现有的模块进行二次开发或个性化定制。这样做不仅能够提高产品的市
Python正则表达式高级分析:模式识别与数据分析实战指南

# 1. 正则表达式基础概述
正则表达式是一套用于字符串操作的规则和模式,它允许用户通过特定的语法来定义搜索、替换以及验证文本的规则。这使得对数据的提取、分析和处理工作变得简单高效。无论你是进行简单的数据验证还是复杂的文本分析,正则表达式都是不可或缺的工具。
在本章中,我们将带您从零基础开始,了解正则表达式的基本概念、构成及其在数据处理中的重要性。我们将浅入深地介绍正则
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )