xml.dom.minidom与XSLT:自动化XML文档转换的终极方案
发布时间: 2024-10-01 02:53:10 阅读量: 18 订阅数: 27 

EDR( Endpoint Detection and Response:端点检测和响应)测试数据,这些数据可能来自主流工具 用于学习探索性分析

# 1. XML文档和XSLT的基础知识
## XML文档简介
可扩展标记语言(XML)是一种标记语言,它允许开发者设计和定义自己的标记集,这些标记可以用来描述数据,以一种易于人们阅读和编写,以及机器处理和解析的方式。XML被广泛应用于数据交换、配置文件、网络服务等众多领域,它具有自我描述性、平台无关性和易于扩展的特点。
## XSLT的定义和作用
XSLT(Extensible Stylesheet Language Transformations)是一种用于转换XML文档的样式表语言。XSLT通过定义一系列的规则,能够将一个XML文档转换成另一种格式,如HTML或另一个XML文档。XSLT为处理XML数据提供了高度的灵活性,它可以改变文档的结构,对内容进行重新排序或筛选,甚至进行条件处理。
## 从基础到实践
在本章中,我们将首先介绍XML的基本语法和结构,然后逐步深入理解XSLT的工作原理。通过对这两个技术的基础知识的探讨,我们将为后续章节中涉及的XML解析和XSLT应用打下坚实的基础。随着章节内容的推进,我们还将展示如何将这些理论知识应用到实际问题的解决中,例如数据转换和动态内容生成等场景。
# 2. XML DOM解析技术详解
### 2.1 DOM模型的基本概念
DOM(Document Object Model)模型是一种以层次节点树结构表示XML文档的编程接口。它允许程序和脚本动态地访问和更新文档的内容、结构以及样式。
#### 2.1.1 DOM模型的结构与组成
DOM树的结构由节点(Node)组成,这些节点代表了XML文档中的各个元素、属性、文本等。节点分为不同的类型,例如元素节点(Element)、属性节点(Attribute)、文本节点(Text)等。DOM的核心是一个树状结构,由以下主要组件构成:
- **Document节点**:树的根节点,代表整个文档。
- **Element节点**:代表XML文档中的元素,如`<person>`或`<book>`。
- **Attribute节点**:代表元素的属性。
- **Text节点**:代表元素或属性中的文本内容。
- **Comment节点**:代表文档中的注释。
- **DocumentFragment节点**:代表轻量级的Document节点,可以包含多个子节点,但不会被直接显示。
```mermaid
graph TD;
doc[Document] --> element[Element]
doc --> comment[Comment]
element --> attr(Attribute)
element --> text(Text)
element --> child[Child Elements]
```
DOM的层次结构设计允许我们通过编程方式遍历和修改文档,比如添加、删除或替换节点。
#### 2.1.2 DOM模型的操作接口概述
DOM提供了丰富的接口,允许开发者以编程方式操作文档。主要接口包括:
- **Node接口**:所有节点类型共有的基础接口,包含诸如`appendChild()`和`removeChild()`等方法。
- **Element接口**:继承自Node,为元素节点提供特有的属性和方法,比如`getAttribute()`和`setAttribute()`。
- **Document接口**:是整个DOM树的根接口,提供如`createElement()`, `createTextNode()`, `getElementById()`等方法,用于创建新的节点或获取现有节点。
使用这些接口,开发者可以在应用程序中创建动态的用户界面,响应用户交互或数据变化,也可以用在服务器端动态生成文档。
### 2.2 使用xml.dom.minidom解析XML
Python的xml.dom.minidom模块提供了一种轻量级方式来解析XML文档。它对于小型或中型的XML文档来说,是一个简单且高效的解析工具。
#### 2.2.1 xml.dom.minidom的安装与配置
`xml.dom.minidom`是Python标准库的一部分,因此不需要额外安装。要使用它,只需确保Python环境已经安装好。
#### 2.2.2 解析XML文档的步骤和方法
使用`xml.dom.minidom`解析XML文档的基本步骤包括:
1. 导入`xml.dom.minidom`模块。
2. 使用`parse()`函数来解析XML文件或字符串。
3. 通过`getElementsByTagName()`等方法获取文档中的元素。
4. 处理节点数据或遍历DOM树。
以下是一个简单的例子:
```python
from xml.dom.minidom import parse
# 解析XML文件
dom_tree = parse('example.xml')
# 获取根节点
root_element = dom_tree.documentElement
# 获取所有的person元素
persons = root_element.getElementsByTagName('person')
# 打印每个person的信息
for person in persons:
name = person.getElementsByTagName('name')[0].firstChild.data
print(f'Name: {name}')
```
#### 2.2.3 处理节点树和节点遍历技巧
遍历DOM树是一项基本技能,有助于开发者理解文档的结构和内容。节点遍历常用的遍历算法包括深度优先搜索(DFS)和广度优先搜索(BFS)。`xml.dom.minidom`提供了一些方法,如`firstChild`, `lastChild`, `nextSibling`, `previousSibling`等,这些都可以用来遍历DOM树。
### 2.3 xml.dom.minidom的高级应用
当处理更复杂的XML文档时,可能需要使用到事件处理和DOM解析效率优化等高级技巧。
#### 2.3.1 事件处理与DOM解析效率优化
事件处理允许开发者在解析过程中响应特定事件,例如开始解析元素或解析完成时。这通常需要使用到SAX风格的解析器。
DOM解析效率优化可以通过避免不必要的DOM树操作和使用DOM缓存来实现。`xml.dom.minidom`提供了一个简单的缓存机制,通过`getFeature()`和`setFeature()`方法可以控制缓存行为。
#### 2.3.2 DOM解析常见问题及解决方案
在使用DOM解析器时,开发者可能会遇到几个常见问题,如内存不足、解析速度慢以及处理大型XML文档时的性能问题。以下是一些解决方案:
- **内存不足**:可以采用懒加载(懒解析),即只有在真正需要时才加载解析XML文档的部分内容。
- **解析速度慢**:考虑使用基于事件的解析器而不是DOM解析器,如Python的`xml.sax`模块。
- **大型XML文档处理**:使用流式解析技术来处理大型文件,如Python的`xml.etree.ElementTree.iterparse()`方法。
通过上述方法,开发者可以针对不同的需求和环境选择合适的策略,从而提高应用程序的性能和效率。
# 3. XSLT技术的深入理解与应用
## 3.1 XSLT的基本原理与结构
### 3.1.1 XSLT模板和样式表的概念
XSLT(Extensible Stylesheet Language Transformations)是用于转换XML文档的一门语言。XSLT允许开发者定义一套规则,这套规则描述了如何从源XML文档中提取信息并转换成其他格式,比如HTML、纯文本或者其他XML。这些规则被编写在样式表中,样式表是一系列的模板匹配规则和指令。
一个XSLT样式表由一个或多个模板组成,每个模板定义了在何种条件下应用何种转换。当XSLT处理器执行转换时,它会遍历XML文档并尝试匹配模板规则,每当找到一个匹配,就会生成相应的输出。
### 3.1.2 XSLT转换过程的详细解析
转换过程分为几个基本步骤:
1. **解析源文档**:首先,源XML文档被加载并解析,通常使用一个DOM解析器。
2. **创建初始模板**:XSLT处理器查看样式表并找到初始模板。这个模板的匹配模式通常为根节点。
3. **应用模板**:根据模板中的规则,源文档的内容被逐步处理。对于每个匹配到的节点,模板定义了如何格式化节点以及如何生成输出。
4. **递归处理**:对于每个节点,可能会递归地应用更多的模板规则,直到文档树的每个部分都被转换。
5. **输出结果**:最终输出可以是文本、XML、HTML等其他格式。
### 3.1.3 代码块示例:XSLT样式表示例
```xml
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="***" version="1.0">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<head>
<title>Example Transformation</title>
</head>
<body>
<h1>My First XSLT Transformation</h1>
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
<xsl:template match="book">
<p>
<strong><xsl:value-
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“Python 库文件学习之 xml.dom.minidom”专栏!本专栏将深入探讨 xml.dom.minidom 库,它是一个强大的 Python 库,用于处理 XML 数据。
从入门基础到高级应用,我们将逐步引导您掌握 xml.dom.minidom 的方方面面。您将学习如何解析、创建、修改和验证 XML 文档,并探索其在各种场景中的应用。我们还将涵盖性能优化、命名空间处理、事件驱动编程、schema 验证、XSLT 转换、序列化和内存管理等高级主题。
无论您是 XML 数据处理的新手还是经验丰富的开发者,本专栏都将为您提供宝贵的见解和实用技巧。通过深入了解 xml.dom.minidom,您将提升自己的 XML 数据处理能力,并为您的 Python 项目增添新的维度。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Altera FPGA新手必读:EPCS4中文资料深度解析

# 摘要
本文详细介绍了Altera FPGA与EPCS4存储器的工作原理、结构、配置编程以及实际应用案例。首先,概述了EPCS4的基本概念和与FPGA的连接方式,随后深入探讨了其内部结构,包括存储单元与逻辑块的设计以及编程与配置机制。文章还分析了EPCS4的性能指标,强调了读写速度、容量、稳定性和可靠性对于系统整体性能的重要性。在配置与编程章节中,提出了配置过程中的常见问题及
Java期末考试全方位解析:深入理解内存管理和垃圾回收

# 摘要
Java内存管理是构建高效可靠Java应用程序的关键组成部分。本文从基础概念入手,深入探讨了Java的垃圾回收机制,分析了其必要性、判定标准以及常见的垃圾回收算法。同时,本文着重分析了内存泄漏的原因和预防措施,探讨了内存分配策略和内存模型,并提供了内存管理的实战技巧。最后
CIMCO Edit 2022快捷键大全:3倍提升工作效率的秘诀
# 摘要
CIMCO Edit 2022作为一款广泛使用的数控编程编辑软件,其快捷键功能在提高用户工作效率上起着至关重要的作用。本文首先提供了CIMCO Edit 2022快捷键的全面概览,随后深入探讨基础快捷键及其在文件操作、编辑修改、视图导航中的应用。接着,文章介绍了高级快捷键在代码分析、数据转换、宏命令录制等方面的高效使用。此外,还讨论了如何通过快捷键构建高效的工作流,并提供了学习与提升快捷键使用的资源。通过本文,读者可以全面了解和掌握CIMCO Edit 2022快捷键的使用技巧,进一步优化数控编程工作流程。
# 关键字
CIMCO Edit 2022;快捷键;数控编程;代码分析;自
Testbed工具与代码覆盖率:单元测试深度剖析与优化

# 摘要
随着软件工程的持续发展,单元测试与代码覆盖率成为了保证软件质量的关键手段。本文首先介绍了单元测试与代码覆盖率的基本概念和重要性,随后详细阐述了Testbed工具在实践中的应用,包括安装配置、测试环境搭建以及结果分析。文中深入探讨了代码覆盖率的理论基础,包括度量
【TMC5041控制专家】:理论实践双管齐下,性能升级不是梦

# 摘要
TMC5041驱动器作为一款先进电机驱动解决方案,已被广泛应用于各类高精度控制领域。本文首先介绍了TMC5041驱动器的基本概述和应用前景,然后详细探讨了其理论基础,包括技术参数、驱动原理以及集成环境等。通过实践操作章节,本文阐述了如何进行硬件连接、软件编程以及调试测试,进而提升TMC5041驱动器的性能。接着,本文分享了性能升级技巧,涉及硬件
【MBR数据恢复大师】:用Winhex轻松掌握MBR分析与修复技巧
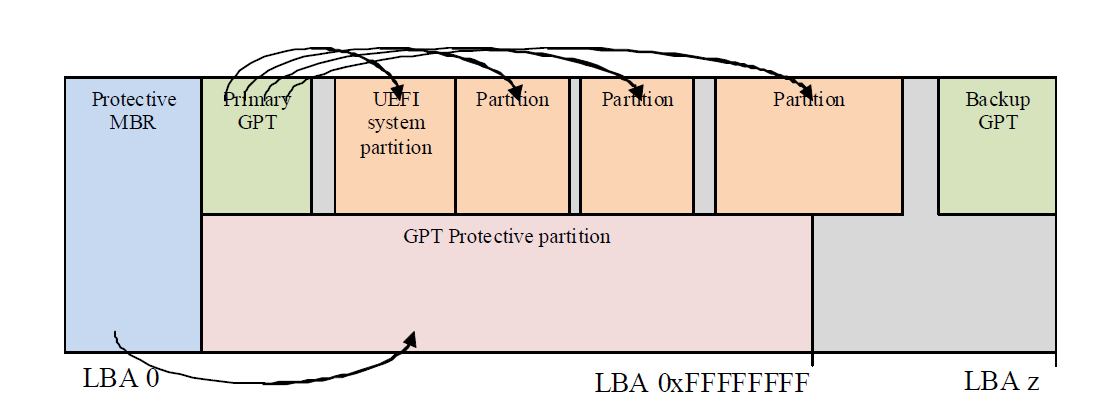
# 摘要
本文旨在介绍MBR(主引导记录)数据恢复的基础知识与高级技巧。首先,文章解释了MBR的基本结构,包括引导代码、分区表和标志字,以及这些组件如何影响计算机启动过程。随后深入探讨了MBR的详细数据结构,故障类型及其后果,并讲述了使用Winhex工具在MBR恢复中的具体应用。接着,文章分享了处理MBR引导问题、修复分区表损坏及系统启动问题的实践技巧。最后,提出了处理
【Mathematica图表设计必修课】:自定义刻度与标签,增强图表表现力
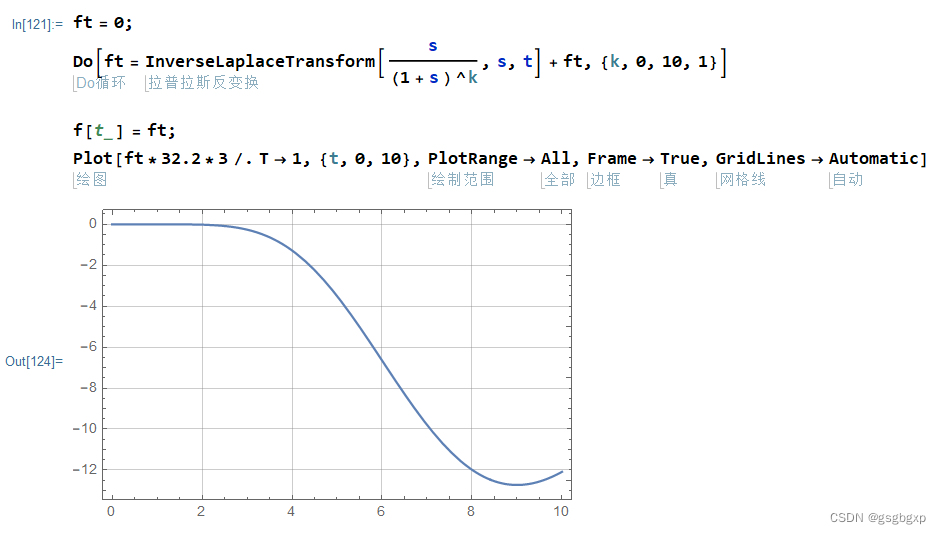
# 摘要
本文系统地介绍了Mathematica图表设计的基础知识和自定义刻度及标签的理论与实践。首先,阐述了图表设计的基本原则和提升图表表现力的策略,包括简洁明了、信息准确和视觉舒适等关键要点。随后,详细讨论了不同类型刻度和标签的特点与设置方法,如数值刻度、对数刻度、分类刻度以及自动、手动和格式化标签。进一步地,文章探索了高级应用,包括多维数据的图表设计和图表的交互式操作,如3D图表设计、
【ST75256高级配置秘籍】:掌握关键技巧,优化系统性能
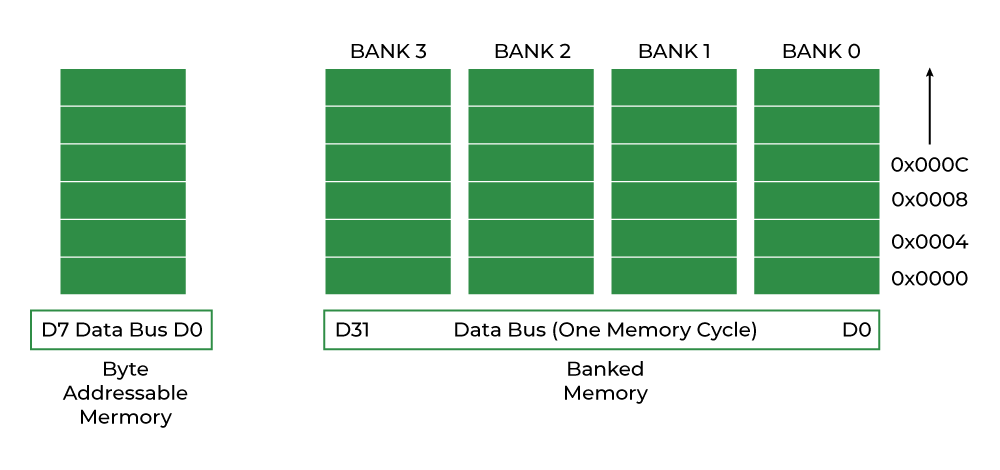
# 摘要
ST75256芯片作为一款功能丰富的集成电路,广泛应用于多种系统中。本文首先介绍了ST75256芯片的基本信息和基础应用,然后深入探讨了其寄存器结构及其配置、内存管理和内存优化策略。文章继续分析了如何通过时钟与中断优化、能耗管理来提升系统性能。此外,本文还详细阐述了ST75256的高级通信配置,包括高速通信接口技术和无线通信模块的集成。在软件开发方面,探讨了软件架构设计和模块
Teamcenter单点登录灾难恢复计划:保障业务连续性的最佳实践
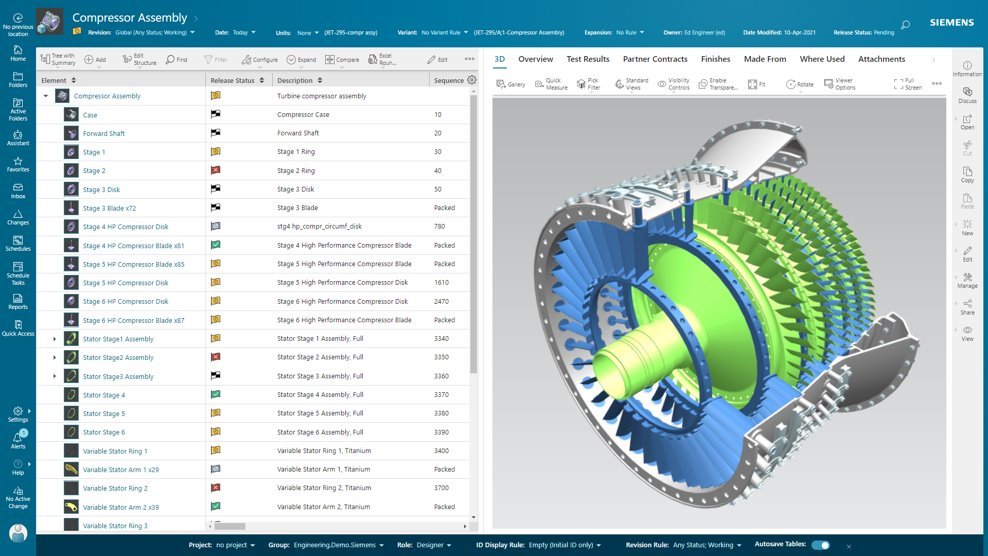
# 摘要
本文旨在探讨Teamcenter单点登录系统的灾难恢复实践与自动化监控,以提高系统的可靠性和业务连续性。首先介绍了单点登录的基础知识以及灾难恢复理论的重要性,然后深入分析了单点登录架构的关键组件与依赖性,并讨论了灾难恢复计划的制定与执行。接着,通过案例分析,展示了在Teamcenter环境中成功实施灾难恢复的具
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )