xml.dom.minidom进阶指南:提升XML数据处理的六大技巧
发布时间: 2024-10-01 02:07:08 阅读量: 45 订阅数: 36 

Python3使用xml.dom.minidom和xml.etree模块儿解析xml文件封装函数的方法

# 1. XML与DOM解析基础
## 1.1 XML技术概述
XML(Extensible Markup Language,可扩展标记语言)是一种标记语言,用于存储和传输数据。它以文本形式呈现,易于人类阅读和编写,同时也被计算机程序处理。与HTML不同,XML没有预定义的标签,允许开发者定义自己的标签结构,从而描述数据的层次关系。
## 1.2 DOM解析模型
DOM(Document Object Model,文档对象模型)是XML和HTML文档的编程接口。它将文档视为树形结构,每个节点代表文档中的元素或属性。通过DOM解析器,开发者可以创建、遍历、修改和删除节点,实现对XML文档的动态操作。
## 1.3 XML与DOM的关联
XML文档通过DOM解析后,形成树形的数据结构,其中每个节点对应文档中的元素、属性或文本。这种结构使得开发者能够以面向对象的方式访问和处理XML数据。下一章将深入探讨XML DOM MiniDOM的详细特性,以及它在实际应用中如何提高效率和性能。
# 2. 深入理解XML DOM MiniDOM
### 2.1 XML DOM MiniDOM的结构和特点
#### 2.1.1 MiniDOM与其他DOM解析器的对比
MiniDOM是一个轻量级的DOM解析器,它的主要特点是占用内存少,加载速度快。与流行的DOM解析库相比,如Java中的`JDOM`和.NET中的`System.Xml`,MiniDOM在处理大型XML文件时表现更佳,因为它采用了更为高效的内存管理机制和事件驱动模型。
在对比中,我们可以看到,传统DOM解析器通常需要将整个文档加载到内存中,然后构建一棵完整的DOM树。这种方法虽然易于编程,但在处理大文件时会造成显著的性能问题。MiniDOM提供了一种更为高效的方式来读取和处理XML文档,它允许用户在解析XML文件的过程中直接操作节点,而不需要事先将整个文档加载到内存中。
### 2.2 XML文档的加载和解析
#### 2.2.1 从字符串和文件加载XML
加载XML文档到MiniDOM可以通过不同的接口进行,支持从内存中的字符串或者文件系统中的XML文件加载。以下是使用MiniDOM从字符串加载XML文档的代码示例:
```java
import com.example.minidom.*;
public class MiniDOMExample {
public static void main(String[] args) {
String xmlContent = "<note><to>Tove</to><from>Jani</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>";
try {
Document document = MiniDOM.loadXML(xmlContent);
// 接下来的代码可以从document对象中进行操作
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
这个示例展示了一个简单的从字符串加载XML的过程。通过`MiniDOM.loadXML`方法,我们可以将XML字符串转换成一个文档对象,之后便可以利用MiniDOM提供的API进行节点的访问和操作。
#### 2.2.2 解析过程中的异常处理
在XML解析过程中,可能会遇到各种异常情况,如格式错误的XML或者不支持的编码。MiniDOM提供了异常处理机制,允许用户捕获并处理这些错误。
下面是一个异常处理的例子:
```java
try {
Document document = MiniDOM.loadXML(xmlContent);
} catch (DOMException e) {
// 处理解析错误
System.out.println("解析异常: " + e.getMessage());
// 可以根据异常类型进行不同的处理
} catch (IOException e) {
// 处理IO错误
System.out.println("IO异常: " + e.getMessage());
} catch (Exception e) {
// 其他异常处理
System.out.println("未知异常: " + e.getMessage());
}
```
在这个代码块中,我们通过多个`catch`语句来捕获不同的异常类型,并进行相应的处理。这使得程序在遇到错误时能够优雅地恢复或者提供有用的错误信息。
### 2.3 元素和节点的操作
#### 2.3.1 创建、修改和删除元素
在MiniDOM中,可以使用不同的方法来创建、修改和删除XML文档的元素和节点。以下是一些基本的操作示例。
创建元素:
```java
Document doc = MiniDOM.newDocument();
Element root = doc.createElement("root");
doc.appendChild(root);
```
修改元素:
```java
Element element = doc.getElementById("myElement");
element.setText("New Content");
```
删除元素:
```java
Node parent = element.getParentNode();
parent.removeChild(element);
```
这些操作展示了如何使用MiniDOM的API来修改XML文档的内容。其中,`getElementById`方法是用来获取具有特定ID的元素,`setText`方法用来更新文本内容,而`removeChild`方法则用于从其父节点中移除一个节点。
#### 2.3.2 节点遍历与查询
节点遍历是XML处理中的一个重要操作,它允许我们访问XML文档树中的每一个节点。MiniDOM提供了多种遍历方法,包括但不限于`getElementsByTagName`, `getElementsByAttribute`, 和`getChildren`等。
下面是一个遍历并打印所有元素名称的例子:
```java
NodeList elements = doc.getElementsByTagName("*");
for (int i = 0; i < elements.getLength(); i++) {
System.out.println("Element Name: " + elements.item(i).getNodeName());
}
```
这段代码使用了`getElementsByTagName`方法来获取所有元素节点,并遍历这些节点打印出它们的名称。
节点查询:
```java
NodeList nodes = doc.querySelectorAll("[attr='value']");
for (int i = 0; i < nodes.getLength(); i++) {
System.out.println("Found Element: " + nodes.item(i).getNodeName());
}
```
这段代码演示了如何使用CSS选择器语法`querySelectorAll`方法在MiniDOM中进行节点查询。这个方法非常强大,能够执行复杂的XPATH查询,但语法更加简洁明了。
在本章节中,我们探讨了MiniDOM的核心特性、加载和解析XML文档的方法、元素和节点操作技术,以及如何进行节点遍历和查询。通过实例代码和异常处理,我们展示了MiniDOM如何在实际应用中高效地解析和处理XML数据。接下来的章节将深入介绍XML数据处理的技巧,让我们继续探索XML的更多潜能。
# 3. XML数据处理技巧
## 3.1 节点属性的操作
### 3.1.1 设置和获取属性
在处理XML数据时,节点属性的操作是不可或缺的一部分。每个节点可能具有多个属性,这些属性通常用于存储节点的附加信息。使用MiniDOM,我们可以轻松地设置和获取节点属性。
以下是设置和获取节点属性的代码示例:
```python
import minidom
# 解析XML字符串
doc = minidom.parseString('<root><item id="123">Example</item></root>')
item = doc.documentElement.firstChild
# 设置属性
item.getAttributeNode('id').value = '456'
# 获取属性
print(item.getAttribute('id')) # 输出: 456
```
### 3.1.2 属性与节点的关系处理
处理节点属性时,需要注意属性和节点之间的关系。属性是节点的子元素,但通常不包含子节点。此外,属性不能直接添加子节点,因为它们本身就是不可再分的键值对。
```python
# 为属性添加子节点会导致错误
try:
attr = item.getAttributeNode('id')
subnode = doc.createElement('sub')
attr.appendChild(subnode) # 这里会抛出异常
except TypeError as e:
print(e) # 输出: Node cannot be inserted at the specified point in the hierarchy
```
## 3.2 文本内容的提取和编辑
### 3.2.1 提取特定节点的文本
提取特定节点的文本内容是XML数据处理中的常见任务。MiniDOM提供了`getData()`方法来获取节点的文本内容。
```python
# 提取特定节点的文本内容
item_text = item.firstChild.data
print(item_text) # 输出: Example
```
### 3.2.2 文本节点的修改与格式化
文本节点的修改是处理XML数据时的重要环节。我们可以直接修改文本节点的数据,并且还可以进行格式化处理。
```python
# 修改文本节点的内容
item.firstChild.data = 'New Example'
# 格式化文本节点
import xml.dom.minidom
from xml.dom import Node
# 定义一个格式化函数,这里仅为示例
def format_text(node):
if node.nodeType == Node.TEXT_NODE:
node.data = node.data.strip() # 移除文本节点前后空格
else:
for child in node.childNodes:
format_text(child) # 递归处理所有子节点
# 格式化整个文档的文本内容
format_text(doc.documentElement)
```
## 3.3 事件监听与处理
### 3.3.1 事件机制简介
在XML数据处理中,事件机制提供了一种动态响应

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“Python 库文件学习之 xml.dom.minidom”专栏!本专栏将深入探讨 xml.dom.minidom 库,它是一个强大的 Python 库,用于处理 XML 数据。
从入门基础到高级应用,我们将逐步引导您掌握 xml.dom.minidom 的方方面面。您将学习如何解析、创建、修改和验证 XML 文档,并探索其在各种场景中的应用。我们还将涵盖性能优化、命名空间处理、事件驱动编程、schema 验证、XSLT 转换、序列化和内存管理等高级主题。
无论您是 XML 数据处理的新手还是经验丰富的开发者,本专栏都将为您提供宝贵的见解和实用技巧。通过深入了解 xml.dom.minidom,您将提升自己的 XML 数据处理能力,并为您的 Python 项目增添新的维度。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Java代码审计核心教程】:零基础快速入门与进阶策略
-Concept-in-Java.webp)
# 摘要
Java代码审计是保障软件安全性的重要手段。本文系统性地介绍了Java代码审计的基础概念、实践技巧、实战案例分析、进阶技能提升以及相关工具与资源。文中详细阐述了代码审计的各个阶段,包括准备、执行和报告撰写,并强调了审计工具的选择、环境搭建和结果整理的重要性。结合具体实战案例,文章
【Windows系统网络管理】:IT专家如何有效控制IP地址,3个实用技巧

# 摘要
本文主要探讨了Windows系统网络管理的关键组成部分,特别是IP地址管理的基础知识与高级策略。首先概述了Windows系统网络管理的基本概念,然后深入分析了IP地址的结构、分类、子网划分和地址分配机制。在实用技巧章节中,我们讨论了如何预防和解决IP地址冲突,以及IP地址池的管理方法和网络监控工具的使用。之后,文章转向了高级
【技术演进对比】:智能ODF架与传统ODF架性能大比拼

# 摘要
随着信息技术的快速发展,智能ODF架作为一种新型的光分配架,与传统ODF架相比,展现出诸多优势。本文首先概述了智能ODF架与传统ODF架的基本概念和技术架构,随后对比了两者在性能指标、实际应用案例、成本与效益以及市场趋势等方面的不同。智能ODF架通过集成智能管理系统,提高了数据传输的高效性和系统的可靠性,同时在安全性方面也有显著增强。通过对智能ODF架在不同部署场景中的优势展示和传统ODF架局限性的分析,本文还探讨
化工生产优化策略:工业催化原理的深入分析
# 摘要
本文综述了化工生产优化的关键要素,从工业催化的基本原理到优化策略,再到环境挑战的应对,以及未来发展趋势。首先,介绍了化工生产优化的基本概念和工业催化理论,包括催化剂的设计、选择、活性调控及其在工业应用中的重要性。其次,探讨了生产过程的模拟、流程调整控制、产品质量提升的策略和监控技术。接着,分析了环境法规对化工生产的影响,提出了能源管理和废物处理的环境友好型生产方法。通过案例分析,展示了优化策略在多相催化反应和精细化工产品生产中的实际应用。最后,本文展望了新型催化剂的开发、工业4.0与智能化技术的应用,以及可持续发展的未来方向,为化工生产优化提供了全面的视角和深入的见解。
# 关键字
MIPI D-PHY标准深度解析:掌握规范与应用的终极指南
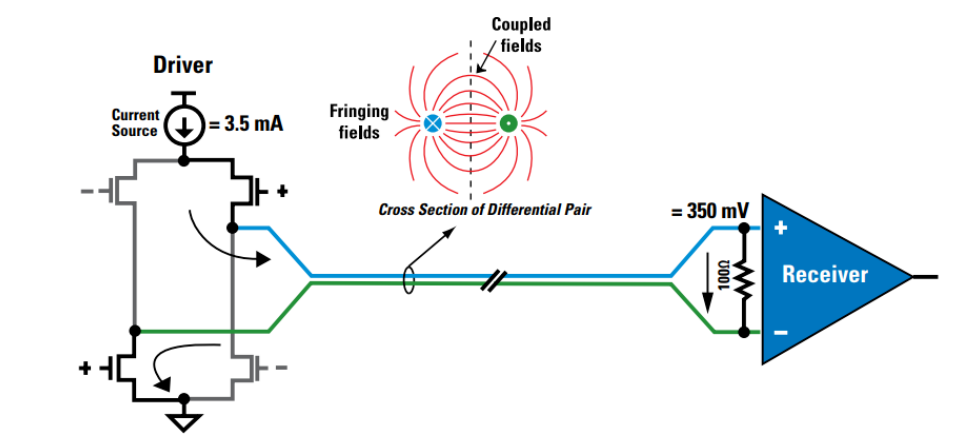
# 摘要
MIPI D-PHY作为一种高速、低功耗的物理层通信接口标准,广泛应用于移动和嵌入式系统。本文首先概述了MIPI D-PHY标准,并深入探讨了其物理层特性和协议基础,包括数据传输的速率、通道配置、差分信号设计以及传输模式和协议规范。接着,文章详细介绍了MIPI D-PHY在嵌入式系统中的硬件集成、软件驱动设计及实际应用案例,同时提出了性能测试与验
【SAP BASIS全面指南】:掌握基础知识与高级技能

# 摘要
SAP BASIS是企业资源规划(ERP)解决方案中重要的技术基础,涵盖了系统安装、配置、监控、备份、性能优化、安全管理以及自动化集成等多个方面。本文对SAP BASIS的基础配置进行了详细介绍,包括系统安装、用户管理、系统监控及备份策略。进一步探讨了高级管理技
【Talend新手必读】:5大组件深度解析,一步到位掌握数据集成
# 摘要
Talend是一款强大的数据集成工具,本文首先介绍了Talend的基本概念和安装配置方法。随后,详细解读了Talend的基础组件,包括Data Integration、Big Data和Cloud组件,并探讨了各自的核心功能和应用场景。进阶章节分析了Talend在实时数据集成、数据质量和合规性管理以及与其他工
网络安全新策略:Wireshark在抓包实践中的应用技巧

# 摘要
Wireshark作为一款强大的网络协议分析工具,广泛应用于网络安全、故障排除、网络性能优化等多个领域。本文首先介绍了Wireshark的基本概念和基础使用方法,然后深入探讨了其数据包捕获和分析技术,包括数据包结构解析和高级设置优化。文章重点分析了Wireshark在网络安全中的应用,包括网络协议分析、入侵检测与响应、网络取证与合规等。通过实
三角形问题边界测试用例的测试执行与监控:精确控制每一步

# 摘要
本文针对三角形问题的边界测试用例进行了深入研究,旨在提升测试用例的精确性和有效性。文章首先概述了三角形问题边界测试用例的基础理论,包括测试用例设计原则、边界值分析法及其应用和实践技巧。随后,文章详细探讨了三角形问题的定义、分类以及测试用例的创建、管理和执行过程。特别地,文章深入分析了如何控制测试环境与用例的精确性,并探讨了持续集成与边界测试整合的可能性。在测试结果分析与优化方面,本文提出了一系列故障分析方法和测试流程改进策略。最后,文章展望了边界
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )