线性方程组的LU分解
发布时间: 2024-01-31 03:03:18 阅读量: 38 订阅数: 29 

MATLAB报告用LU分解法求解线性方程组.doc
# 1. 线性方程组简介
## 1.1 什么是线性方程组
线性方程组是由一组线性方程组成的方程组,形式通常为:
\begin{cases}
a_{11}x_1 + a_{12}x_2 + \cdots + a_{1n}x_n = b_1 \\
a_{21}x_1 + a_{22}x_2 + \cdots + a_{2n}x_n = b_2 \\
\vdots \\
a_{m1}x_1 + a_{m2}x_2 + \cdots + a_{mn}x_n = b_m \\
\end{cases}
其中,$a_{ij}$ 为系数,$b_i$ 为常数,$x_i$ 为变量。解线性方程组就是要找到一组满足所有方程的变量值。
## 1.2 线性方程组的解法概述
解线性方程组有多种方法,比如数值法(如高斯消元法、追赶法等)和分解法(如LU分解、Cholesky分解等)。分解法是将系数矩阵分解为两个易于求逆的矩阵相乘的形式,从而简化线性方程组的求解过程。LU分解是其中的一种常用方法,接下来将介绍LU分解的基础知识。
# 2. LU分解基础
LU分解是解决线性方程组的一种重要方法,它将方程组的系数矩阵分解为一个下三角矩阵L和一个上三角矩阵U的乘积,从而简化了求解过程。本章将介绍LU分解的基础知识。
### 2.1 LU分解的定义
LU分解是指将一个矩阵A分解成一个下三角矩阵L和一个上三角矩阵U的乘积的过程,即A=LU。其中,L是一个单位下三角矩阵,U是一个上三角矩阵。分解后的方程组可以表示为LUx=b,其中x是未知向量,b是已知向量。
### 2.2 LU分解的原理
LU分解的原理基于高斯消元法。对于一个线性方程组Ax=b,我们可以通过一系列的行变换将其化为一个上三角方程组Ux=c,并记录下行变换的信息。然后,我们再通过逆向代入的方法,将上三角方程组化为一个下三角方程组Ly=b,得到LU分解的结果。
LU分解的原理可以用如下的伪代码表示:
```python
Input: 矩阵A, 向量b
Output: L, U, x
令n为A的行数和列数
初始化矩阵L为单位下三角矩阵,U为A的复制
初始化向量x为零向量
初始化向量c为零向量
for k from 1 to n-1 do:
for i from k+1 to n do:
L[i][k] = U[i][k] / U[k][k]
for j from k to n do:
U[i][j] = U[i][j] - L[i][k] * U[k][j]
c[i] = b[i] - L[i][k] * c[k]
解Ly = b得到向量c
解Ux = c得到向量x
返回L, U, x
```
以上就是LU分解的基础知识,下一章节我们将介绍LU分解的计算方法。
# 3. LU分解的计算方法
在前面的章节中,我们已经了解了LU分解的基础知识,接下来我们将详细介绍LU分解的计算方法,包括Crout分解、Doolittle分解和Cholesky分解。
#### 3.1 Crout分解
Crout分解是LU分解的一种方法,其基本思想是将系数矩阵A分解为一个下三角矩阵L和一个上三角矩阵U的乘积,即A=LU。具体的计算方法可以使用以下伪代码进行表示:
```python
def crout_decomposition(A):
n = len(A)
L = [[0.0] * n for _ in range(n)]
U = [[0.0] * n for _ in range(n)]
for i in range(n):
L[i][i] = 1.0
for j in range(i, n):
U[i][j] = A[i][j] - sum(L[i][k] * U[k][j] for k in range(i))
for j in range(i+1, n):
L[j][i] = (A[j][i] - sum(L[j][k] * U[k][i] for k in range(i))) / U[i][i]
return L, U
```
#### 3.2 Doolittle分解
Doolittle分解也是LU分解的一种常见方法,与Crout分解不同的是,Doolittle分解将L的对角元素设为1,即L的主对角线元素全部为1。下面是Doolittle分解的计算方法示例:
```java
public class DoolittleDecomposition {
public static void doolittleDecomposition(double[][] A, double[][] L, double[][] U) {
int n = A.length;
for (int i = 0; i < n; i++) {
L[i][i] = 1.0;
for (int j = i; j < n; j++) {
double sum = 0.0;
for (int k = 0; k < i; k++) {
sum += L[i][k] * U[k][j];
}
U[i][j] = A[i][j] - sum;
}
for (int j = i + 1; j < n; j++) {
double sum = 0.0;
for (int k = 0; k < i; k++) {
sum += L[j][k] * U[k][i];
}
L[j][i] = (A[j][i] - sum) / U[i][i];
}
}
}
}
```
#### 3.3 Cholesky分解
Cholesky分解是针对对称正定矩阵的一种特殊的LU分解方法,它将系数矩阵A分解为一个下三角矩阵L和其转置矩阵的乘积,即A=LL^T。Cholesky分解的计算方法如下所示:
```go
func CholeskyDecomposition(A [][]float64) ([][]float64, bool) {
n := len(A)
L := make([][]float64, n)
for i := range L {
L[i] = make([]float64, n)
}
for i := 0; i < n; i++ {
sum := 0.0
for k := 0; k < i; k++ {
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《计算方法》专栏涵盖了数值计算方法及其研究方向的多个主题。从基础概念如有效数字的定义及应用,到避免误差的基本原则及应用,专栏逐步引入更深入的内容如向量和矩阵范数的介绍,以及与之相关的矩阵m1范数和F-范数的解释。此外,专栏也重点介绍了算子范数的定义与应用,以及一些重要算子范数的简介。其中,矩阵范数性质的关键定理对于理解算子范数起到了关键作用。最后,专栏深入探讨了高斯消元法处理线性方程组的应用,线性方程组的LU分解,以及Doolittlte方法求解线性方程组。紧凑的LU分解原理和计算方法以及LU分解的存在性和独特性也是专栏的重要内容。《计算方法》专栏着重于介绍数值计算方法的理论和实际应用,旨在帮助读者更好地理解和应用计算方法。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【图书馆管理系统的UML奥秘】:全面解码用例、活动、类和时序图(5图表精要)
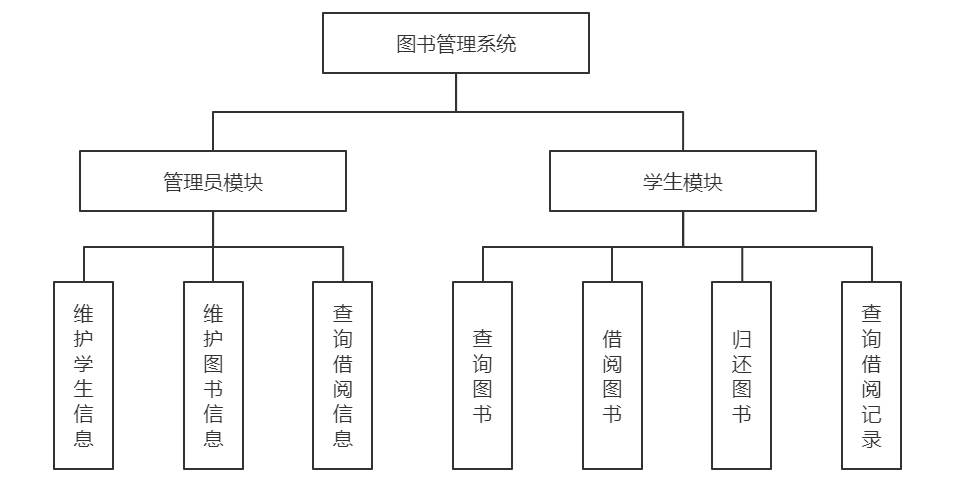
# 摘要
本文探讨了统一建模语言(UML)在图书馆管理系统设计中的重要性,以及其在分析和设计阶段的核心作用。通过构建用例图、活动图和类图,本文揭示了UML如何帮助开发者准确捕捉系统需求、设计交互流程和定义系统结构。文中分析了用例图在识别主要参与者和用例中的应用,活动图在描述图书检索、借阅和归还流程中的作用,以及类图在定义图书类、读者类和管理员类之间的关系。
NVIDIA ORIN NX开发指南:嵌入式开发者的终极路线图

# 摘要
本文详细介绍了NVIDIA ORIN NX平台的基础开发设置、编程基础和高级应用主题。首先概述了该平台的核心功能,并提供了基础开发设置的详细指南,包括系统要求、开发工具链安装以及系统引导和启动流程。在编程基础方面,文章探讨了NVIDIA GPU架构、CUDA编程模型以及并行计算框架,并针对系统性能调优提供了实用
【Sigma-Delta ADC性能优化】:反馈与前馈滤波器设计的精髓
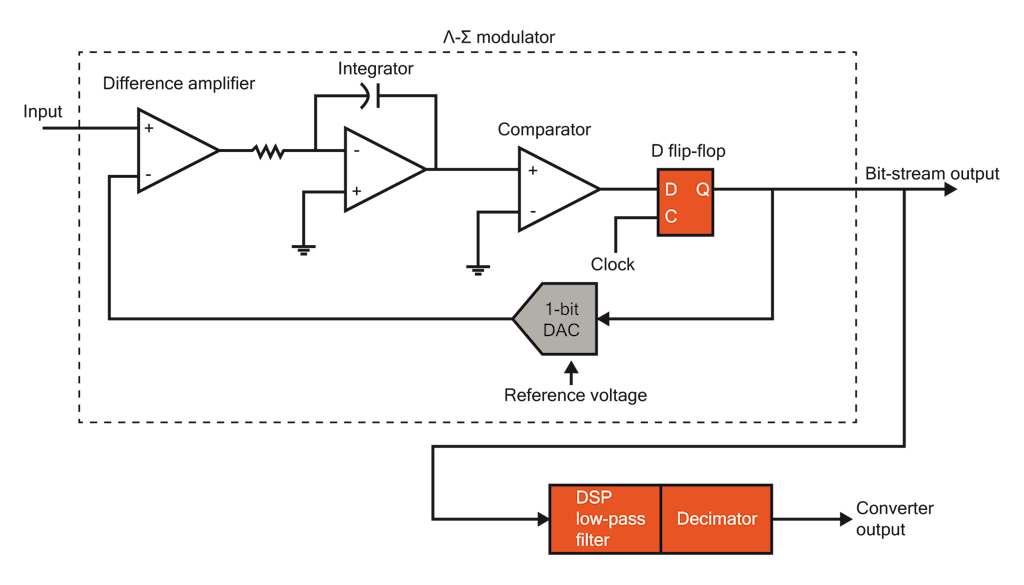
# 摘要
Sigma-Delta模数转换器(ADC)因其高分辨率和高信噪比(SNR)而广泛应用于数据采集和信号处理系统中。本文首先概述了Sigma-Delta ADC性能优化的重要性及其基本原理,随后重点分析了反馈和前馈滤波器的设计与优化,这两者在提高转换器性能方面发挥着关键作用。文中详细探讨了滤波器设计的理论基础、结构设计和性能优化策略,并对Sigma-Delta
【实战演练】:富士伺服驱动器报警代码全面解析与应对手册
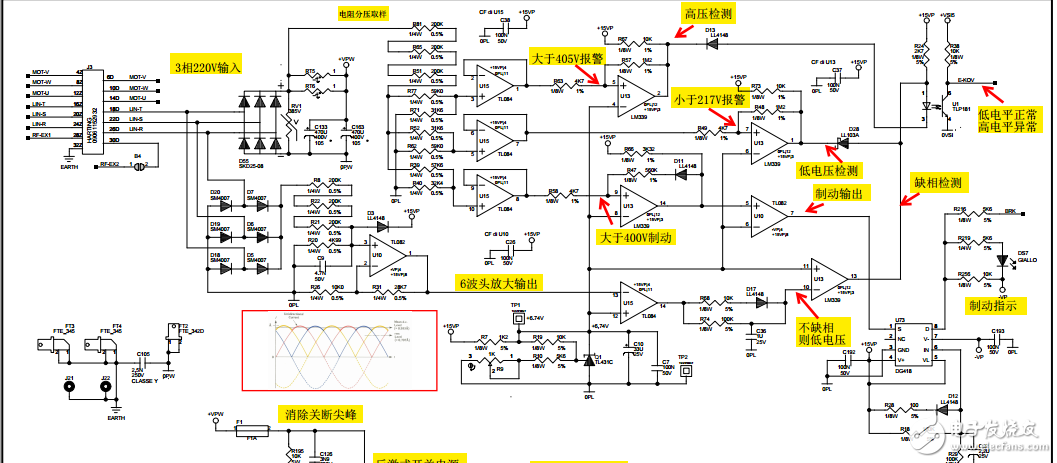
# 摘要
本文详细介绍了富士伺服驱动器及其报警代码的基础知识、诊断流程和应对策略。首先概述了伺服驱动器的结构和功能,接着深入探讨了报警代码的分类、定义、产生原因以及解读方法。在诊断流程章节中,提出了有效的初步诊断步骤和深入分析方法,包括使用富士伺服软件和控制程序的技巧。文章还针对硬件故障、软件配置错误提出具体的处理方法,并讨论了维护与预防措施的重要性。最后,通过案例分析和实战演练,展示了报警分析与故障排除的实际应用,并总结了相关经验与
【单片微机系统设计蓝图】:从原理到实践的接口技术应用策略
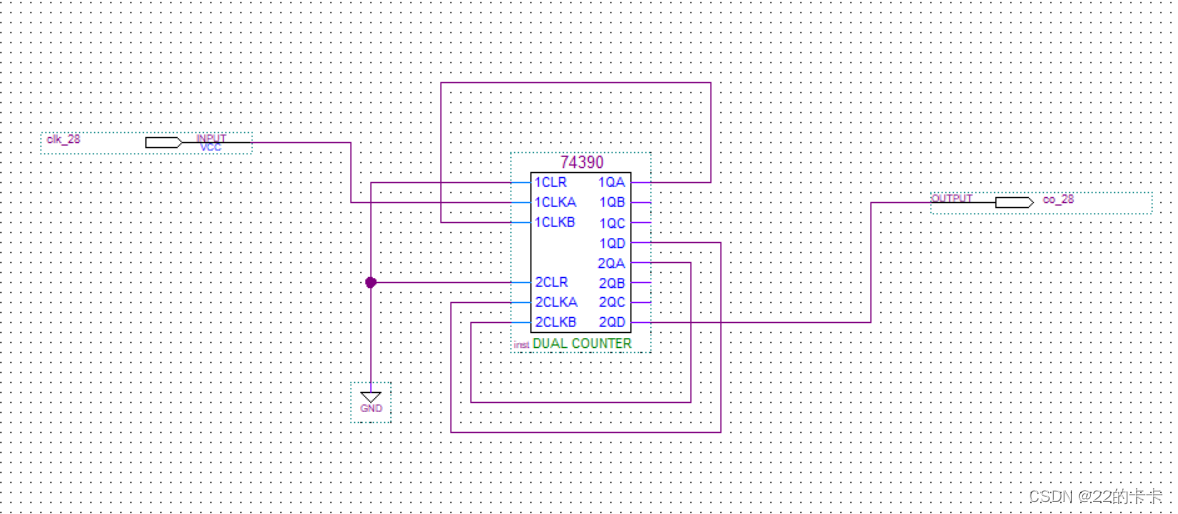
# 摘要
单片微机系统作为一种集成度高、功能全面的微处理器系统,广泛应用于自动化控制、数据采集、嵌入式开发和物联网等多个领域。本文从单片微机系统的基本原理、核心理论到接口设计和实践应用进行了全面的介绍,并探讨了在现代化技术和工业需求推动下该系统的创新发展方向。通过分析单片微机的工作原理、指令集、接口技术以及控制系统和数据采集系统的设计原理,本文为相关领域工程师和研究人员提供了理论支持和
【Java内存管理秘籍】:掌握垃圾回收和性能优化的艺术
# 摘要
本文全面探讨了Java内存管理的核心概念、机制与优化技术。首先介绍了Java内存管理的基础知识,然后深入解析了垃圾回收机制的原理、不同垃圾回收器的特性及选择方法,并探讨了如何通过分析垃圾回收日志来优化性能。接下来,文中对内存泄漏的识别、监控工具的使用以及性能调优的案例进行了详细的阐述。此外,文章还探讨了内存模型、并发编程中的内存管理、JVM内存参数调优及高级诊断工具的应用。最
信号处理进阶:FFT在音频分析中的实战案例研究

# 摘要
本文综述了信号处理领域中的快速傅里叶变换(FFT)技术及其在音频信号分析中的应用。首先介绍了信号处理与FFT的基础知识,深入探讨了FFT的理论基础和实现方法,包括编程实现与性能优化。随后,分析了音频信号的特性、采样与量化,并着重阐述了FFT在音频频谱分析、去噪与增强等方面的应用。进一步,本文探讨了音频信号的进阶分析技术,如时间-频率分析和高
FCSB1224W000升级秘籍:无缝迁移至最新版本的必备攻略

# 摘要
本文综述了FCSB1224W000升级的全过程,涵盖从理论分析到实践执行,再到案例分析和未来展望。首先,文章介绍了升级前必须进行的准备工作,包括系统评估、理论路径选择和升级后的系统验证。其次,详细阐述了实际升级过程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )