跨语言NLP处理必知:多语言文本数据处理全攻略
发布时间: 2024-11-21 14:39:29 阅读量: 78 订阅数: 45 

基于springboot的在线答疑系统文件源码(java毕业设计完整源码+LW).zip

# 1. 多语言NLP概述
## 1.1 自然语言处理的多语言挑战
随着全球化的深入发展,跨语言信息交流的需求日益增长。多语言自然语言处理(NLP)作为一个涵盖不同语言信息处理的学科,它的出现和发展是应时代之需。多语言NLP的核心在于能够处理和理解多种语言,从而使得机器能够跨语言地获取、处理和生成信息。
## 1.2 多语言NLP技术的应用场景
多语言NLP的应用广泛,包括跨语言信息检索、机器翻译、跨文化情感分析、多语种的语音识别与合成等。这些应用场景不仅要求算法能够处理语言的多样性,还要能够抓住不同语言间的细微差别和共性。
## 1.3 发展趋势与未来挑战
目前,多语言NLP技术正朝着深度学习、大规模语料库和跨语言预训练模型的方向发展。这些进步为提升多语言NLP性能打下了基础,但仍然面临着诸如资源分配不均、低资源语言处理能力低下等问题。未来的发展将更加侧重于如何让多语言NLP技术更为普惠,让小语种也能受益于先进的语言处理技术。
# 2. 多语言文本预处理技术
## 2.1 文本清洗
### 2.1.1 消除噪声和异常值
文本数据在采集和存储过程中往往会引入噪声,例如错误的字符、不必要的空白、格式不一致等。消除这些噪声和异常值是文本预处理的第一步,它有助于提高后续处理步骤的效率和准确性。
在Python中,可以利用正则表达式和字符串处理函数来识别和处理噪声。例如,去除文本中的非打印字符和多余空格:
```python
import re
def clean_text(text):
# 移除非打印字符和多余的空格
text = re.sub(r'\n', ' ', text)
text = re.sub(r'\r', '', text)
text = re.sub(r'\s+', ' ', text)
return text.strip()
# 示例文本
example_text = "\tExample string with \nnewlines\tand\rextra white space. \f"
cleaned_text = clean_text(example_text)
print(cleaned_text)
```
**代码逻辑解读分析:**
- `re.sub(r'\n', ' ', text)`:将换行符替换为空格。
- `re.sub(r'\r', '', text)`:将回车符删除。
- `re.sub(r'\s+', ' ', text)`:将多个连续空格替换为单个空格。
- `text.strip()`:移除字符串两端的空格。
在多语言NLP处理中,特别是当涉及多语种混合文本时,还可能需要根据特定语言的规则来清除不相关的字符集或标记。
### 2.1.2 处理文本编码问题
文本编码问题常常导致乱码,尤其是在处理多种语言的文本时。例如,UTF-8和ISO-8859-1编码的文本,在未正确处理的情况下显示或处理时可能会出现乱码。
确保文本数据使用统一的编码标准是处理编码问题的关键。在Python中,可以使用内置的编码处理方法来转换和标准化文本编码:
```python
def ensure_utf8_encoding(text):
if isinstance(text, str):
return text
else:
return text.decode('utf-8', 'ignore')
# 示例文本
example_bytes = b'\x61\x62\x63' # 这是字符串"abc"的UTF-8编码
decoded_text = ensure_utf8_encoding(example_bytes)
print(decoded_text)
```
**代码逻辑解读分析:**
- `text.decode('utf-8', 'ignore')`:尝试将字节字符串按照UTF-8编码解码。如果编码不匹配,使用'ignore'参数忽略错误的字节。
- `isinstance(text, str)`:检查`text`是否已经是字符串类型,如果是,则直接返回原字符串;如果不是(例如字节序列),则先解码。
在多语言处理环境中,应优先使用UTF-8编码,因为它支持世界上几乎所有语言的字符。
## 2.2 分词技术
### 2.2.1 单语言分词技术
分词(Tokenization)是将连续的文本分割为有意义的最小单位(tokens)。在单语言分词中,这一过程通常包括将句子分解为单词、数字或其他符号。
以英语为例,分词通常相对简单,主要分为空格分隔和标点符号识别。而在某些亚洲语言如中文中,分词则需要复杂的算法来处理没有空格分隔的字符序列。
以下是一个简单的英文分词示例:
```python
def tokenize_english(text):
return text.split()
english_text = "Natural Language Processing is an exciting field."
tokens = tokenize_english(english_text)
print(tokens)
```
**代码逻辑解读分析:**
- `text.split()`:根据空白字符(空格、换行、制表符等)进行分词,返回一个包含所有tokens的列表。
中文分词则通常需要专门的工具,如jieba分词:
```python
import jieba
def tokenize_chinese(text):
return list(jieba.cut(text))
chinese_text = "自然语言处理是一个令人兴奋的领域。"
tokens = tokenize_chinese(chinese_text)
print(tokens)
```
### 2.2.2 多语言分词的挑战和方法
多语言分词面临的挑战远比单语言分词复杂。首先,不同语言的语法规则差异巨大,有的语言如中文没有明确的空格分隔;有的语言如日语和韩语具有复杂的分词规则。此外,跨语言分词还需要处理来自不同语言文本的混合。
为了解决这些问题,多语言分词通常采用以下方法:
- **基于规则的分词**:利用预先定义的语言特定规则来处理分词。
- **统计模型**:应用如隐马尔可夫模型(HMM)等统计模型进行分词。
- **深度学习方法**:如使用双向长短时记忆网络(BiLSTM)进行分词。
在多语言NLP系统中,多语言分词通常是通过集成多种语言资源和工具来实现的。例如,NLTK库提供了多种语言的分词器,而spaCy也支持多语言模型。
## 2.3 文本标准化
### 2.3.1 词形还原与词干提取
词形还原(Lemmatization)和词干提取(Stemming)是两种常见的文本标准化方法,用于将词汇还原为其词根形式。
- **词形还原**:利用语言学知识库将单词还原为原形,如将“running”还原为“run”。
- **词干提取**:一种更为粗暴的方法,通常使用启发式算法将单词还原为词干,而不会考虑词的具体含义或语法作用。
在Python中,可以使用NLTK库来执行词形还原和词干提取:
```python
import nltk
from nltk.stem import WordNetLemmatizer, PorterStemmer
lemmatizer = WordNetLemmatizer()
stemmer = PorterStemmer()
def lemmatize_stemming(text):
return [stemmer.stem(lemmatizer.lemmatize(token)) for token in text]
# 示例文本
tokens = ['running', 'runner', 'ran']
lemmatized_tokens = lemmatize_stemming(tokens)
print(lemmatized_tokens)
```
**代码逻辑解读分析:**
- `WordNetLemmatizer.lemmatize(token)`:对单词进行词形还原。
- `PorterStemmer.stem(token)`:对单词进行词干提取。
- `nltk`库需要下载`wordnet`和`punkt`数据包,使用`nltk.download('wordnet')`和`nltk.download('punkt')`进行下载。
### 2.3.2 语言特有字符的处理
处理语言特有字符是文本标准化的重要步骤。例如,在处理德语文本时,可能会遇到特殊字符如"ü", "ä", "ö"等。这些字符需要正确处理以避免信息丢失。
一个常见的处理方法是使用Unicode标准化,将特殊字符转换为其NFC或NFD形式:
```python
import unicodedata
def normalize_text(text):
# 将文本转换为NFC形式
text = unicodedata.normalize(
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨自然语言处理(NLP)领域,提供从初学者到进阶者的全面指南。专栏涵盖核心概念、实战技巧、词法句法分析、词向量技术、情感分析、语音识别、知识图谱构建、文本摘要和数据增强等主题。通过深入的剖析和实战应用,专栏旨在帮助读者掌握NLP的精髓,打造高效的NLP应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SENT协议故障诊断不求人:SAE J2716标准常见问题速解

# 摘要
SENT协议与SAE J2716标准是汽车电子领域内广泛应用的技术,用于传感器数据传输。本文首先概述了SENT协议和SAE J2716标准的基本概念和应用场景,随后深入分析了SENT协议的工作原理、数据包结构以及故障诊断的基础方法。文章接着详细探讨了SAE J2716标准的技术要求、测试验证以及故障诊断实践,进阶技术部分则侧重于SENT协
从零开始:EP4CE10教程带你走进FPGA编程的世界

# 摘要
本文介绍了FPGA(现场可编程门阵列)的基础知识及其在EP4CE10芯片上的应用。从开发环境的搭建、基础编程理论到复杂逻辑设计及优化技巧,本文逐步深入讲解了FPGA开发的各个方面。同时,通过数字时钟和简易计算器的实战项目,阐述了理论知识的实
PADS高级设计技巧揭秘:提升PCB效率的5大关键步骤

# 摘要
本文综述了PADS软件在电路设计中的高级技巧和应用。首先概述了PADS高级设计技巧,然后详细探讨了原理图设计与优化、PCB布局与布线技巧、设计仿真与分析,以及制造准备与后期处理的策略和方法。通过深入分析原理图和PCB设计中常见问题的解决方法,提出提高设计效率的实用技巧。本文还强调了设计仿真对于确保电路设计质量的重要性,并探讨了如
深入浅出DevOps文化:7个秘诀打造极致高效IT团队

# 摘要
DevOps作为一种文化和实践,着重于打破传统开发与运营之间的壁垒,以提升软件交付的速度、质量和效率。本文首先概述了DevOps文化及其核心原则,包括其定义、起源、核心价值观和实践框架。随后,深入探讨了DevOps实践中关键工具和技术的应用,如持续集成与持续部署、配置管理、基础设施自动化、监控与日志管理。文中进一步分析了DevOps在团队建设与管理中的重要性,以及如何在不同行业中落地实施。最后,展望了Dev
【TDC-GP21手册常见问题解答】:行业专家紧急排错,疑难杂症秒解决
# 摘要
TDC-GP21手册是针对特定设备的操作与维护指南,涵盖了从基础知识到深度应用的全方位信息。本文首先对TDC-GP21手册进行了概览,并详细介绍了其主要功能和特点,以及基本操作指南,包括操作流程和常见问题的解决方法。随后,文章探讨了TDC-GP21手册在实际工作中的应用情况和应用效果评估,以及手册高级
Allwinner A133应用案例大揭秘:成功部署与优化的不传之秘
# 摘要
本文全面介绍了Allwinner A133芯片的特点、部署、应用优化策略及定制案例,并展望了其未来技术发展趋势和市场前景。首先概述了A133芯片的基本架构和性能,接着详细探讨了基于A133平台的硬件选择、软件环境搭建以及初步部署测试方法。随后,本文深入分析了针对Allwinner A133的系统级性能调优和应用程序适配优化,包括内核调整、文件系统优化、应用性能分析以及能耗管理等方面。在深度定制案例方面,文章探讨了定制化操作系统构建、多媒体和AI功能集成以及安全隐私保护措施。最后,文章展望了Allwinner A133的技术进步和行业挑战,并讨论了社区与开发者支持的重要性。
# 关键
宇视EZVMS数据安全战略:备份与恢复的最佳实践
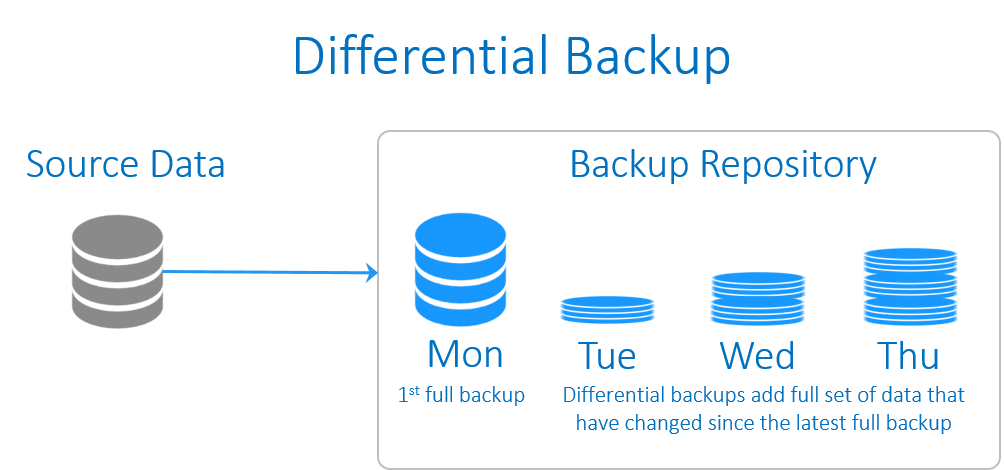
# 摘要
随着信息技术的快速发展,数据安全成为了企业和组织管理中的核心议题。宇视EZVMS作为一个成熟的视频管理系统,在数据备份与恢复方面提供了全面的技术支持和实践方案。本文首先概述了数据安全的重要性,并对宇视EZVMS的备份技术进行了理论探讨与实际操作分析。接着,本文深入讨论了数据恢复的重要性、挑战以及实际操作步骤,并提出了高级备份与恢复策略。通过案例分析,本文分享了宇视
【AD与DA转换终极指南】:数字与模拟信号转换的全貌解析
# 摘要
本文系统性地介绍了模数转换(AD)和数模转换(DA)的基础理论、实践应用及性能优化,并展望了未来的发展趋势与挑战。首先,概述了AD和DA转换的基本概念,随后深入探讨了AD转换器的理论与实践,包括其工作原理、类型及其特点,以及在声音和图像信号数字化中的应用。接着,详细分析了DA转换器的工作原理、分类和特点,以及其在数字音频播放和数字控制系统中的应用。第四章重点讨论了AD与DA转换在现代技术中
Innovus用户必读:IEEE 1801标准中的DRC与LVS高级技巧
# 摘要
本文详细介绍了IEEE 1801标准的概况,深入探讨了设计规则检查(DRC)的基础知识和高级技巧,并展示了如何优化DRC规则的编写和维护。文章还分析了布局与验证(LVS)检查的实践应用,以及如何在DRC和LVS之间实现协同验证。此外,本文阐述了在Innovus工具中采用的多核并行处理、层次化设计验证技术以及故障排除和性能调优的策略。最后,通过具体案例分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )