DVWA中逻辑漏洞的发现与利用技巧
发布时间: 2024-03-07 13:38:52 阅读量: 23 订阅数: 21 
# 1. DVWA简介与逻辑漏洞概述
## 1.1 DVWA是什么?
DVWA(Damn Vulnerable Web Application)是一个用于练习Web应用渗透测试的开源项目,旨在帮助Web开发者和安全研究者熟悉常见的Web安全漏洞类型。
## 1.2 逻辑漏洞的定义与常见类型
逻辑漏洞指的是在应用程序的业务逻辑中存在的漏洞,导致用户可以绕过正常的授权机制进行未授权操作。常见的逻辑漏洞类型包括未授权访问、绕过支付验证、重放攻击等。
## 1.3 为什么逻辑漏洞在Web应用中如此重要?
逻辑漏洞往往被忽视,但实际上可能对系统安全造成严重威胁。因为逻辑漏洞不依赖于技术漏洞,而是基于应用程序自身的设计缺陷,攻击者可以通过模拟正常用户的行为路径来绕过常规安全防护措施,造成未被授权的访问或操作。因此,逻辑漏洞的存在对Web应用的安全性构成巨大挑战。
# 2. DVWA逻辑漏洞的发现技巧
在DVWA中发现逻辑漏洞是Web应用安全测试的重要一环。通过业务逻辑分析,我们可以找出潜在的逻辑漏洞。另外,利用工具如Burp Suite也能帮助我们进行逻辑漏洞扫描,提高漏洞发现的效率。
### 2.1 通过业务逻辑分析发现潜在的逻辑漏洞
在进行逻辑漏洞分析时,我们需要深入理解DVWA的业务逻辑,包括用户权限控制、数据交互流程等。通过模拟用户行为,了解每个操作的影响,从而找出可能存在漏洞的地方。举个例子,当用户在DVWA中修改个人信息时,是否进行了足够的合法性验证?是否存在绕过权限进行恶意操作的可能性?
下面是使用Python的示例代码,模拟用户修改个人信息的操作:
```python
# 模拟用户修改个人信息的代码
def modify_personal_info(user_id, new_info):
if check_user_permission(user_id):
# 执行更新操作
update_personal_info(user_id, new_info)
return "个人信息修改成功!"
else:
return "权限不足,无法修改个人信息!"
def check_user_permission(user_id):
# 检查用户权限,返回True或False
pass
def update_personal_info(user_id, new_info):
# 更新用户的个人信息
pass
# 模拟用户操作
user_id = "123"
new_info = {"username": "Alice", "email": "alice@example.com"}
result = modify_personal_info(user_id, new_info)
print(result)
```
**代码解析:**
- `modify_personal_info()`函数模拟用户修改个人信息的过程,首先检查用户权限,如果权限足够则执行更新操作。
- `check_user_permission()`函数用于检查用户权限是否符合要求。
- `update_personal_info()`函数用于实际更新用户的个人信息。
- 最后,模拟了用户操作并输出操作结果。
### 2.2 利用Burp Suite等工具进行逻辑漏洞扫描
除了手动分析业务逻辑外,工具也是发现逻辑漏洞的利器。Burp Suite是一款功能强大的渗透测试工具,其中的Intruder功能可以帮助我们进行定制化的漏洞扫描,包括逻辑漏洞的扫描。
以下是使用Burp Suite进行逻辑漏洞扫描的简单步骤:
1. 设置Burp Suite的代理,拦截DV

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【CListCtrl行高设置终极指南】:从细节到整体,确保每个环节的完美

# 摘要
CListCtrl是一种常用的列表控件,在用户界面设计中扮演重要角色。本文围绕CListCtrl行高设置展开了详细的探讨,从基本概念到高级应用,深入解析了行高属性的工作原理,技术要点以及代码实现步骤。文章还涉及了多行高混合显示技术、性能优化策略和兼容性问题。通过实践案例分析,本文揭示了常见问题的诊断与解决方法,并探讨了行高设置的
从理论到实践:AXI-APB桥性能优化的关键步骤

# 摘要
本文首先介绍了AXI-APB桥的基础架构及其工作原理,随后深入探讨了性能优化的理论基础,包括性能瓶颈的识别、硬件与软件优化原理。在第三章中,详细说明了性能测试与分析的工具和方法,并通过具体案例研究展示了性能优化的应用。接下来,在第四章中,介绍了硬件加速、缓存
邮件管理自动化大师:SMAIL中文指令全面解析

# 摘要
本文详细介绍了SMAIL邮件管理自动化系统的全面概述,基础语法和操作,以及与文件系统的交互机制。章节重点阐述了SMAIL指令集的基本组成、邮件的基本处理功能、高级邮件管理技巧,以及邮件内容和附件的导入导出操作。此外,文章还探讨了邮件自动化脚本的实践应用,包括自动化处理脚本、邮件过滤和标签自动化、邮件监控与告警。最后一章深入讨论了邮件数据的分析与报告生成、邮件系统的集成与扩展策
车载网络测试新手必备:掌握CAPL编程与应用

# 摘要
CAPL(CAN Application Programming Language)是一种专门为CAN(Controller Area Network)通信协议开发的脚本语言,广泛应用于汽车电子和车载网络测试中。本文首先介绍了CAPL编程的基础知识和环境搭建方法,然后详细解析了CAPL的基础语法结构、程序结构以及特殊功能。在此基础上,进一步探讨了CAPL的高级编程技巧,包括模块化
一步到位!CCU6嵌入式系统集成方案大公开

# 摘要
本文全面介绍了CCU6嵌入式系统的设计、硬件集成、软件集成、网络与通信集成以及综合案例研究。首先概述了CCU6系统的架构及其在硬件组件功能解析上的细节,包括核心处理器架构和输入输出接口特性。接着,文章探讨了硬件兼容性、扩展方案以及硬件集成的最佳实践,强调了高效集成的重要性和集成过程中的常见问题。软件集成部分,分析了软件架构、
LabVIEW控件定制指南:个性化图片按钮的制作教程
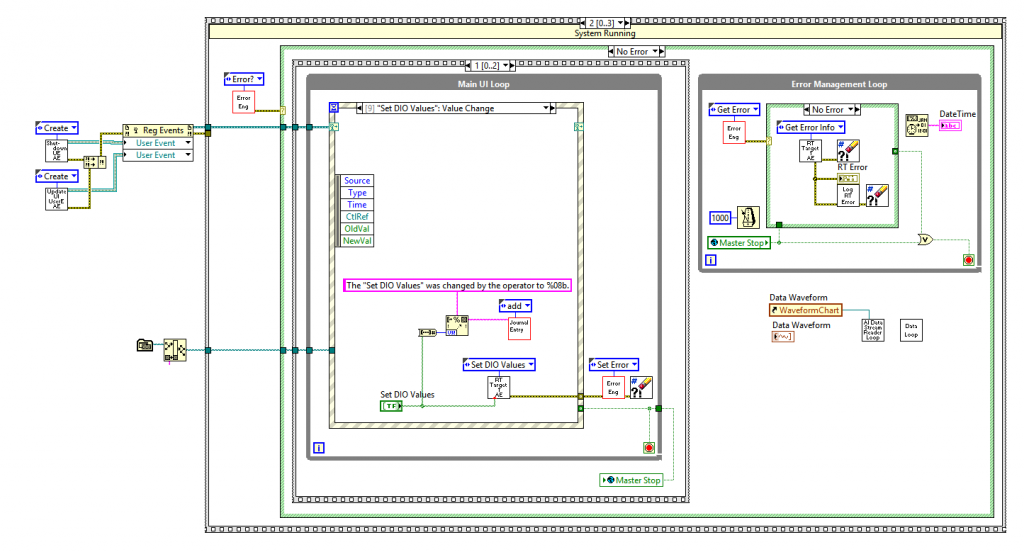
# 摘要
LabVIEW作为一种图形编程环境,广泛应用于数据采集、仪器控制及工业自动化等领域。本文首先介绍了LabVIEW控件定制的基础,然后深入探讨了创建个性化图片按钮的理论和实践。文章详细阐述了图片按钮的界面设计原则、功能实现逻辑以及如何通过LabVIEW控件库进行开发。进一步,本文提供了高级图片按钮定制技巧,包括视觉效果提升、代码重构和模块化设计,以及在复杂应用中的运用
【H3C 7503E多业务网络集成】:VoIP与视频流配置技巧
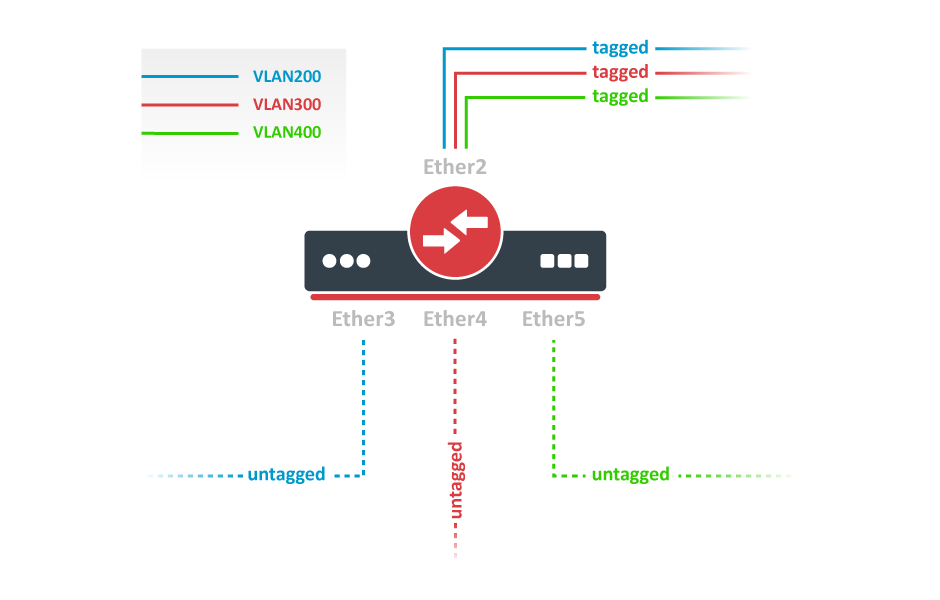
# 摘要
本论文详细介绍了H3C 7503E多业务路由器的功能及其在VoIP和视频流传输领域的应用。首先概述了H3C 7503E的基本情况,然后深入探讨了VoIP技术原理和视频流传输技术的基础知识。接着,重点讨论了如何在该路由器上配置VoIP和视频流功能,包括硬
Word中代码的高级插入:揭秘行号自动排版的内部技巧
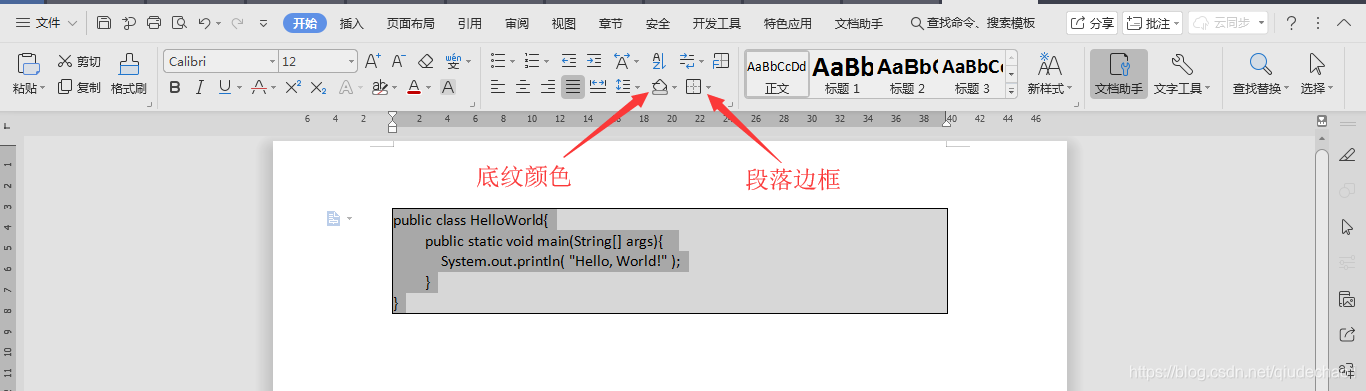
# 摘要
在技术文档和软件开发中,代码排版对于提升文档的可读性和代码的维护性至关重要。本文首先探讨了在Microsoft Word中实现代码排版的常规方法,包括行号自动排版
【PHY62系列SDK技能升级】:内存优化、性能提升与安全加固一步到位

# 摘要
本文针对PHY62系列SDK在实际应用中所面临的内存管理挑战进行了系统的分析,并提出了相应的优化策略。通过深入探讨内存分配原理、内存泄漏的原因与检测,结合内存优化实践技巧,如静态与动态内存优化方法及内存池技术的应用,本文提供了理论基础与实践技巧相结合的内存管理方案。此外,本文还探讨了如何通过性能评估和优化提升系统性能,并分析了安全加固措施,包括安全编程基础、数据加密、访问控制
【JMeter 负载测试完全指南】:如何模拟真实用户负载的实战技巧
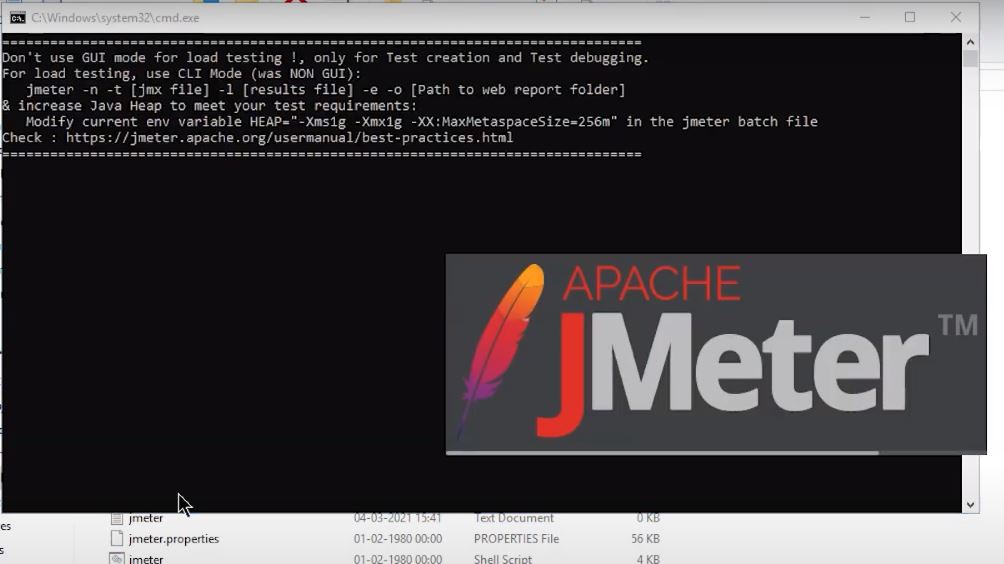
# 摘要
本文对JMeter负载测试工具的使用进行了全面的探讨,从基础概念到高级测试计划设计,再到实际的性能测试实践与结果分析报告的生成。文章详细介绍了JMeter测试元素的应用,测试数据参数化技巧,测试计划结构的优化,以及在模拟真实用户场景下的负载测试执行和监控。此外,本文还探讨了JMeter在现代测试环境中的应用,包括与CI/CD的集成,云服务与分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )