【从零开始构建HDFS】:新手也能搭建环境并执行读写测试
发布时间: 2024-10-25 19:13:22 阅读量: 17 订阅数: 34 

从零开始设计并构建网站防护系统

# 1. Hadoop和HDFS简介
## 1.1 Hadoop的定义和功能
Hadoop是一个开源的分布式计算框架,它允许用户存储和处理大量的数据。Hadoop的核心是HDFS(Hadoop Distributed File System),它是一种高容错的系统,设计用来在廉价硬件上运行。Hadoop还包括MapReduce算法框架,用于大规模数据集(大于1TB)的并行运算。
## 1.2 Hadoop的应用场景
Hadoop广泛应用于数据仓库、日志分析、推荐系统、数据挖掘等领域。它的优点在于处理大规模数据集时的扩展性和经济性。Hadoop能够从简单的服务器集群中提取出巨大的计算和存储能力。
## 1.3 Hadoop的组件
Hadoop生态系统包括了多个组件,其中最核心的是HDFS和MapReduce。除此之外,还包括YARN(Yet Another Resource Negotiator,另一种资源协调者)用于资源管理和作业调度,以及HBase、Hive等项目,它们提供了对结构化和半结构化数据的高级操作。
```mermaid
graph LR
Hadoop[Hadoop] --> HDFS[(HDFS)]
Hadoop --> YARN
Hadoop --> MapReduce
YARN -.-> |资源管理| HBase[(HBase)]
YARN -.-> |作业调度| Hive[(Hive)]
YARN --> Tez[(Tez)]
HBase -.-> |NoSQL数据库| Phoenix[(Phoenix)]
Hive -.-> |SQL-like查询语言| Pig[(Pig)]
Hive -.-> |数据仓库工具| Oozie[(Oozie)]
```
通过这个框架图,可以看出Hadoop的组件之间是如何相互协作的。每一个组件都是为了处理大数据而设计的,它们各自解决不同层面的问题,从而形成一个完整的生态系统。
# 2. 搭建Hadoop环境
## 2.1 安装前的准备工作
### 2.1.1 系统要求和依赖包
为了顺利搭建和运行Hadoop环境,必须先确认你的系统环境满足一系列基本要求。Hadoop可以运行在多种操作系统上,但最常用的是类Unix系统,如Ubuntu或CentOS。对于硬件要求,Hadoop集群中的每个节点应具备足够的内存和磁盘空间来处理数据。
在依赖包方面,Hadoop的运行需要Java环境。因此,你的系统必须安装有Java Development Kit (JDK)。除了JDK,根据你的Hadoop版本,可能还需要安装其他如`libtool`、`ssh`等依赖包。你可以通过包管理器安装这些依赖,例如,在Ubuntu上使用`apt`,在CentOS上使用`yum`或`dnf`。
命令示例(在Ubuntu系统上安装JDK):
```bash
sudo apt-get update
sudo apt-get install openjdk-8-jdk
```
### 2.1.2 安装Java环境
安装Java环境是搭建Hadoop环境的先决条件。Hadoop需要Java环境来运行其服务,比如HDFS和MapReduce。Java版本的选择应基于你安装的Hadoop版本的要求。例如,如果你使用的是Hadoop 3.x,你应该安装Java 8或更高版本。
以下是安装Java的步骤:
1. 下载最新的Java JDK包。
2. 解压到指定目录。
3. 配置Java的环境变量。
下载Java JDK:
```bash
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" ***
```
解压到指定目录:
```bash
mkdir -p /usr/lib/jvm
tar -xzf jdk-8u231-linux-x64.tar.gz -C /usr/lib/jvm
```
配置Java环境变量:
```bash
vim /etc/profile
```
在profile文件末尾添加如下内容:
```bash
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_231
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
```
重载配置文件,使更改生效:
```bash
source /etc/profile
```
通过`java -version`确认Java安装成功。如果系统返回了Java的版本信息,说明环境变量配置正确。
安装和配置Java环境是搭建Hadoop环境的基础,接下来,我们将根据Hadoop的版本进行安装和配置。
## 2.2 Hadoop安装与配置
### 2.2.1 下载和解压Hadoop
现在我们已经准备好了系统和Java环境,接下来进行Hadoop的下载和安装。从官方网站(***)下载Hadoop的稳定版本,然后将其解压到系统中。
下载Hadoop:
```bash
wget ***
```
解压Hadoop:
```bash
mkdir -p /opt/hadoop
tar -xzf hadoop-3.2.1.tar.gz -C /opt/hadoop
```
解压后,你将看到一系列Hadoop组件的目录,包括`bin`、`etc`、`lib`等。
### 2.2.2 配置Hadoop环境变量
为了让系统能够识别Hadoop命令,需要设置环境变量。在你的用户目录下找到`.bashrc`或`.bash_profile`文件,并在文件的末尾添加以下内容:
```bash
export HADOOP_HOME=/opt/hadoop/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
```
为了使这些更改立即生效,你可能需要重新加载配置文件:
```bash
source ~/.bashrc
```
此时,运行`hadoop version`命令,如果看到Hadoop的版本信息,说明环境变量已正确设置。
### 2.2.3 验证安装和启动Hadoop集群
安装验证后,我们开始启动Hadoop集群,观察是否能正常运行。Hadoop集群的启动和停止涉及到多个组件,主要包括NameNode和DataNode,它们负责管理HDFS文件系统的命名空间和存储数据。
启动Hadoop集群:
```bash
start-dfs.sh
```
在成功启动集群之后,你可以通过访问 `***<your-node-ip>:9870/` 来查看HDFS的状态,使用 `***<your-node-ip>:9864/` 来检查YARN的状态。其中 `<your-node-ip>` 应该替换为你的节点IP地址。
停止Hadoop集群:
```bash
stop-dfs.sh
```
在启动和停止Hadoop集群时,确保相关服务正常运行,没有报错信息。如果有任何问题,检查日志文件进行故障诊断。
## 2.3 配置HDFS文件系统
### 2.3.1 格式化NameNode
在启动HDFS之前,需要格式化文件系统的NameNode。这是首次安装时必须的操作,因为NameNode是HDFS的主节点,负责维护文件系统的元数据。
格式化前确保停止正在运行的Hadoop服务:
```bash
stop-dfs.sh
```
格式化NameNode:
```bash
hdfs namenode -format
```
如果看到提示“Fo

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析了 HDFS 的读写流程,从数据块在集群中的流转路径到数据一致性问题的解决策略,全面解析了 HDFS 的读写机制。此外,专栏还提供了专家级的优化策略、性能调优实践、监控与报警策略,以及故障诊断和异常处理指南。通过深入理解 HDFS 的读写流程和优化技巧,读者可以提升大数据集群的 IO 效率和稳定性,并设计支持大规模集群的读写流程。专栏还探讨了 HDFS 与 MapReduce 的协同效应,以及与 HBase 的混合使用方案,为读者提供了从架构到实施的全面专家级解析,帮助读者充分发挥 HDFS 的潜力,满足大数据处理的复杂需求。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【16位加法器设计秘籍】:全面揭秘高性能计算单元的构建与优化

# 摘要
本文对16位加法器进行了全面的研究和分析。首先回顾了加法器的基础知识,然后深入探讨了16位加法器的设计原理,包括二进制加法基础、组成部分及其高性能设计考量。接着,文章详细阐述
三菱FX3U PLC编程:从入门到高级应用的17个关键技巧

# 摘要
三菱FX3U PLC是工业自动化领域常用的控制器之一,本文全面介绍了其编程技巧和实践应用。文章首先概述了FX3U PLC的基本概念、功能和硬件结构,随后深入探讨了
【Xilinx 7系列FPGA深入剖析】:掌握架构精髓与应用秘诀
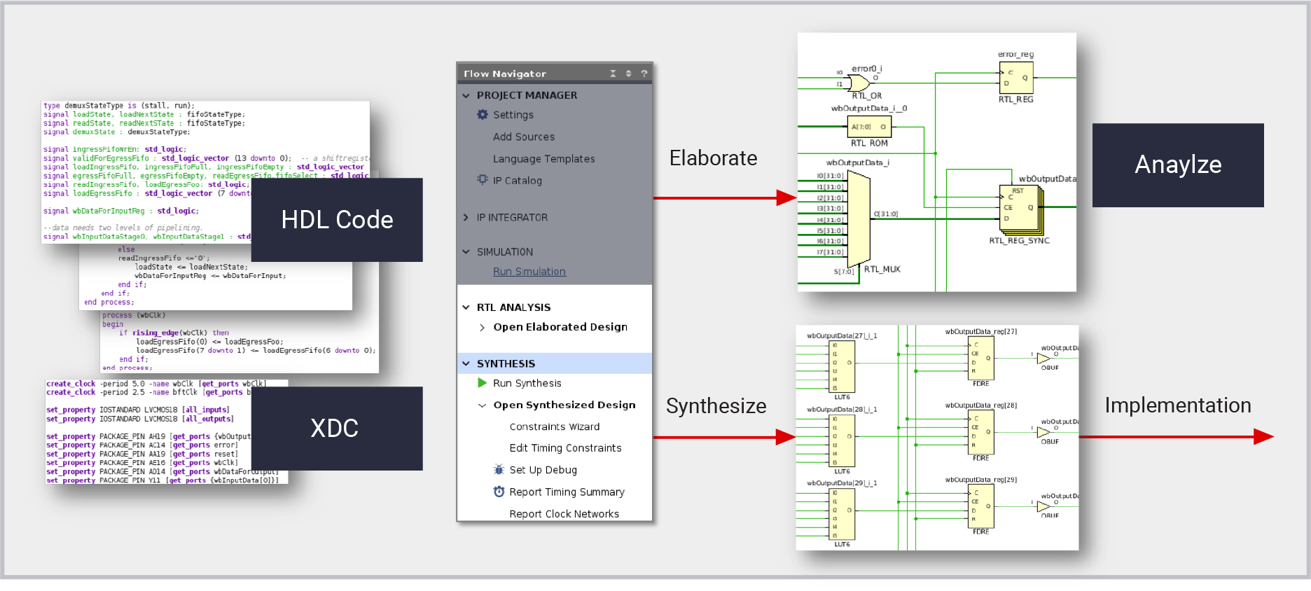
# 摘要
本文详细介绍了Xilinx 7系列FPGA的关键特性及其在工业应用中的广泛应用。首先概述了7系列FPGA的基本架构,包括其核心的可编程逻辑单元(PL)、集成的块存储器(BRAM)和数字信号处理(DSP)单元。接着,本文探讨了使用Xilinx工具链进行FPGA编程与配置的流程,强调了设计优化和设备配置的重要性。文章进一步分析了7系列FPGA在
【图像技术的深度解析】:Canvas转JPEG透明度保护的终极策略

# 摘要
随着Web技术的不断发展,图像技术在前端开发中扮演着越来越重要的角色。本文首先介绍了图像技术的基础和Canvas绘
【MVC标准化:肌电信号处理的终极指南】:提升数据质量的10大关键步骤与工具
# 摘要
MVC标准化是肌电信号处理中确保数据质量的重要步骤,它对于提高测量结果的准确性和可重复性至关重要。本文首先介绍肌电信号的生理学原理和MVC标准化理论,阐述了数据质量的重要性及影响因素。随后,文章深入探讨了肌电信号预处理的各个环节,包括噪声识别与消除、信号放大与滤波技术、以及基线漂移的校正方法。在提升数据质量的关键步骤部分,本文详细描述了信号特征提取、MVC标准化的实施与评估,并讨论了数据质量评估与优化工具。最后,本文通过实验设计和案例分析,展示了MVC标准化在实践应用中的具
ISA88.01批量控制:电子制造流程优化的5大策略

# 摘要
本文首先概述了ISA88.01批量控制标准,接着深入探讨了电子制造流程的理论基础,包括原材料处理、制造单元和工作站的组成部分,以及流程控制的理论框架和优化的核心原则。进一步地,本文实
【Flutter验证码动画效果】:如何设计提升用户体验的交互

# 摘要
随着移动应用的普及和安全需求的提升,验证码动画作为提高用户体验和安全性的关键技术,正受到越来越多的关注。本文首先介绍Flutter框架下验证码动画的重要性和基本实现原理,涵盖了动画的类型、应用场景、设计原则以及开发工具和库。接着,文章通过实践篇深入探讨了在Flutter环境下如何具体实现验证码动画,包括基础动画的制作、进阶技巧和自定义组件的开发。优化篇
ENVI波谱分类算法:从理论到实践的完整指南
# 摘要
ENVI软件作为遥感数据处理的主流工具之一,提供了多种波谱分类算法用于遥感图像分析。本文首先概述了波谱分类的基本概念及其在遥感领域的重要性,然后介绍了ENVI软件界面和波谱数据预处理的流程。接着,详细探讨了ENVI软件中波谱分类算法的实现方法,通过实践案例演示了像元级和对象级波谱分类算法的操作。最后,文章针对波谱分类的高级应用、挑战及未来发展进行了讨论,重点分析了高光谱数据分类和深度学习在波谱分类中的应用情况,以及波谱分类在土地覆盖制图和农业监测中的实际应用。
# 关键字
ENVI软件;波谱分类;遥感图像;数据预处理;分类算法;高光谱数据
参考资源链接:[使用ENVI进行高光谱分
【天线性能提升密籍】:深入探究均匀线阵方向图设计原则及案例分析
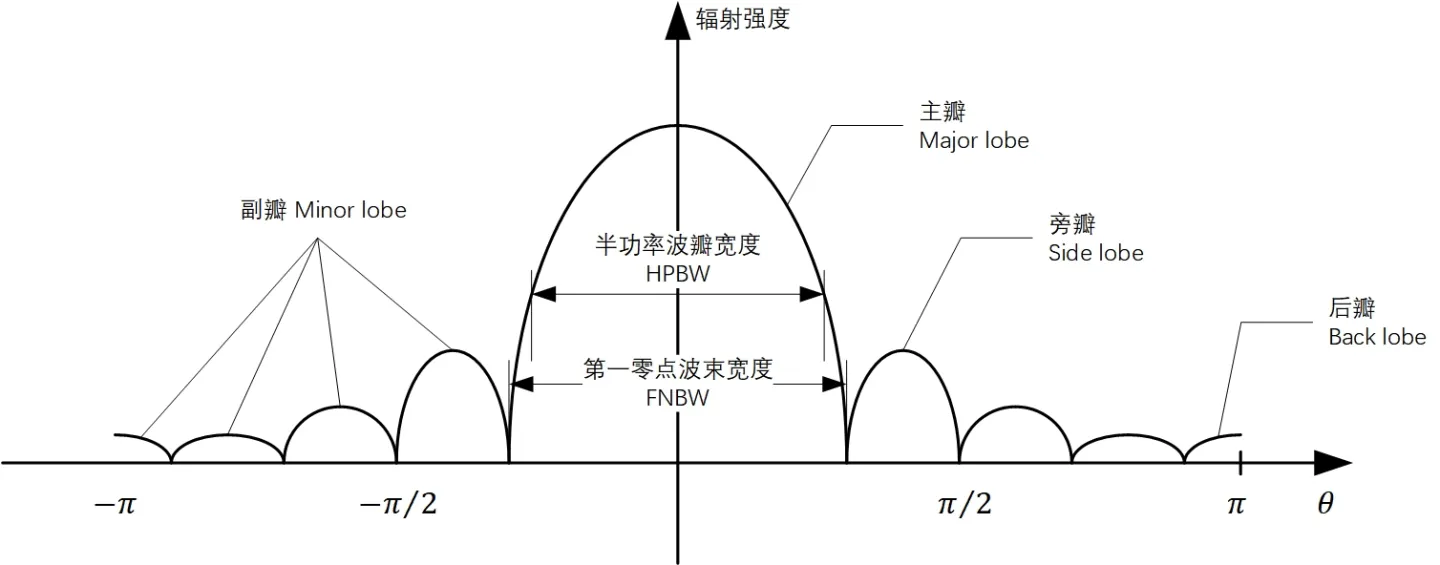
# 摘要
本文深入探讨了均匀线阵天线的基础理论及其方向图设计,旨在提升天线系统的性能和应用效能。文章首先介绍了均匀线阵及方向图的基本概念,并阐述了方向图设计的理论基础,包括波束形成与主瓣及副瓣特性的控制。随后,论文通过设计软件工具的应用和实际天线系统调试方法,展示了方向图设计的实践技巧。文中还包含了一系列案例分析,以实证研究验证理论,并探讨了均匀线阵性能
【兼容性问题】快解决:专家教你确保光盘在各设备流畅读取
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/L/w/I3DfXKTAmrqNi0rGtG5A/2014-06-24-cd-dvd-bluray.png)
# 摘要
光盘作为一种传统的数据存储介质,其兼容性问题长
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )