Pandas数据处理秘籍:20个实战技巧助你从菜鸟到专家
发布时间: 2024-09-18 13:05:07 阅读量: 147 订阅数: 65 
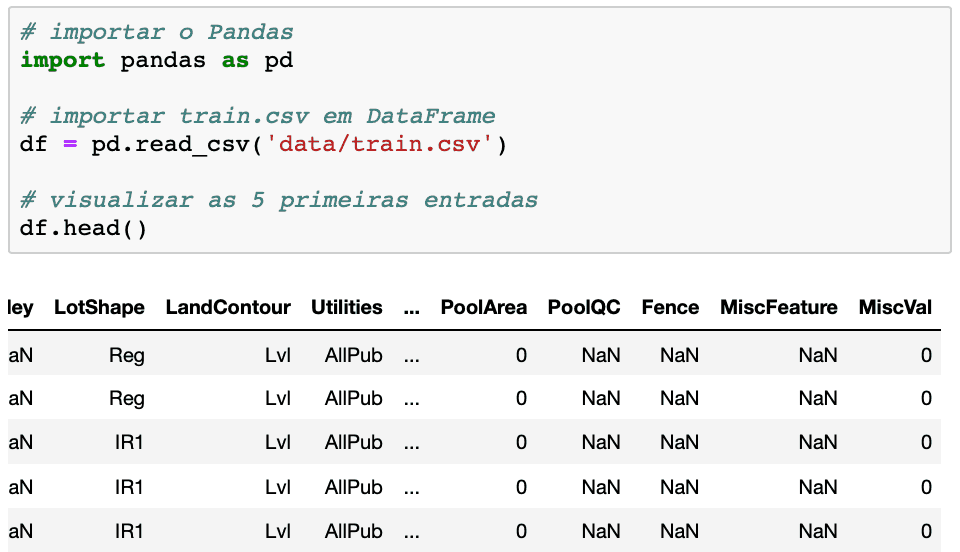
# 1. Pandas数据处理概览
## 1.1 数据处理的重要性
在当今的数据驱动世界里,高效准确地处理和分析数据是每个IT从业者的必备技能。Pandas,作为一个强大的Python数据分析库,它提供了快速、灵活和表达力丰富的数据结构,旨在使“关系”或“标签”数据的处理变得简单和直观。通过Pandas,用户能够执行数据清洗、准备、分析和可视化等操作,从而为深入的数据挖掘和机器学习任务打下基础。
## 1.2 Pandas基本构成
Pandas库的核心数据结构包括**Series**和**DataFrame**。Series是一维的标签化数组,能够储存任何数据类型(整数、字符串、浮点数、Python对象等)。而DataFrame是二维的标签化数据结构,可以看作是一个表格,其中的每一列可以是不同的数据类型。
## 1.3 Pandas的安装和导入
要开始使用Pandas,首先需要确保已经安装了该库。可以通过pip安装:
```bash
pip install pandas
```
安装完成后,通过以下Python代码导入Pandas库:
```python
import pandas as pd
```
以"pd"作为别名是该社区的常见约定,便于简洁地引用Pandas中的函数和方法。接下来,我们就可以使用Pandas处理各种数据集了。
# 2. 数据清洗与准备技巧
### 2.1 数据类型和结构的理解
#### 2.1.1 Pandas中的数据类型
在使用Pandas进行数据清洗之前,理解其支持的数据类型至关重要。Pandas支持的数据类型包括但不限于数值类型、字符串类型、时间序列类型、布尔类型等。在Pandas中,这些数据类型通常与NumPy的数据类型紧密相关,因为Pandas底层是基于NumPy构建的。
举例来说,Pandas中的数值类型可以通过`float32`, `float64`, `int32`, `int64`等表示,而对象类型(object)通常用于表示字符串数据。时间序列数据被特殊处理,使用`datetime64`和`timedelta[ns]`类型来表示具体的时间点和时间间隔。
```python
import pandas as pd
# 创建一个DataFrame示例
df = pd.DataFrame({
'A': [1, 2, 3],
'B': ['foo', 'bar', 'baz'],
'C': [True, False, True]
})
print(df.dtypes)
```
上述代码中,`dtypes`方法用于查看每个列的数据类型。你会发现`A`列为整数类型(可能是`int64`),`B`列为字符串类型(`object`),`C`列为布尔类型(`bool`)。
#### 2.1.2 数据结构Series与DataFrame
Pandas的两个基础数据结构是`Series`和`DataFrame`。`Series`是一种一维数组结构,用于存储单个列的数据,而`DataFrame`是一种二维标签化数据结构,用于处理表格数据,其中可以存储多个`Series`。
```python
# 创建一个Series示例
s = pd.Series([1, 2, 3])
# 创建一个DataFrame示例
df = pd.DataFrame({
'A': [1, 2, 3],
'B': ['foo', 'bar', 'baz']
})
print(s)
print(df)
```
在这个示例中,我们首先创建了一个包含三个元素的`Series`,然后创建了一个包含两列`A`和`B`的`DataFrame`。每个`Series`和`DataFrame`都有一个索引,可以通过`index`属性查看或修改。
### 2.2 缺失数据处理
#### 2.2.1 缺失数据的识别与处理
在数据集中,经常会出现缺失值,即数据中某些值未知或者未被记录。Pandas提供了多种方法来识别、处理这些缺失值。缺失值在Pandas中通常用`NaN`(Not a Number)表示。
Pandas提供了`isnull()`和`notnull()`方法来检测数据中的缺失值。此外,`fillna()`方法用于填充缺失值,而`dropna()`用于删除含有缺失值的行或列。
```python
import numpy as np
# 创建一个包含缺失值的DataFrame
df = pd.DataFrame({
'A': [1, np.nan, 3],
'B': [4, 5, np.nan]
})
# 检测缺失值
print(df.isnull())
# 填充缺失值
df_filled = df.fillna(0)
# 删除含有缺失值的行
df_dropped_rows = df.dropna(axis=0)
# 删除含有缺失值的列
df_dropped_columns = df.dropna(axis=1)
```
在上述代码中,我们首先创建了一个包含缺失值的`DataFrame`。然后,我们使用`isnull()`来检测数据中的缺失值。接着,我们使用`fillna()`方法将所有缺失值填充为0。最后,我们分别展示了如何删除含有缺失值的行和列。
#### 2.2.2 使用fillna和dropna进行操作
`fillna`和`dropna`是Pandas中处理缺失数据的两大主要方法。
`fillna`可以接受一个常数值、一个字典(列名到值的映射)、或是一个方法(如`mean`或`median`)来填充缺失值。例如,假设我们希望用该列的平均值来填充缺失值:
```python
# 使用平均值填充缺失值
df_filled_mean = df.fillna(df.mean())
```
另一方面,`dropna()`提供了一系列参数来控制何时删除数据。例如,`axis`参数可以用来指定是删除行(`axis=0`)还是列(`axis=1`),`how`参数可以用来指定是删除含有任何缺失值的行或列(默认`how='any'`),还是仅在某行或列全部是缺失值时删除(`how='all'`)。
```python
# 删除含有任何缺失值的行
df_dropped_any = df.dropna(axis=0, how='any')
# 删除全部是缺失值的列
df_dropped_all = df.dropna(axis=1, how='all')
```
在处理缺失数据时,选择合适的方法至关重要,因为不同的方法可能会对数据集产生不同的影响。
### 2.3 数据合并与重塑
#### 2.3.1 合并数据集:concat、merge和join
在数据清洗过程中,经常需要合并多个数据集以形成一个统一的数据框架。Pandas提供了三种主要的数据合并方法:`concat`, `merge`, 和 `join`。
`concat`用于沿着一个轴简单地拼接多个对象,通过`axis`参数指定是按行(`axis=0`)还是按列(`axis=1`)拼接。
```python
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'], 'B': ['B0', 'B1', 'B2']})
df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'], 'B': ['B3', 'B4', 'B5']})
# 按列合并
df_concat_columns = pd.concat([df1, df2], axis=1)
```
`merge`则提供了类似于数据库中join操作的能力,它可以根据一个或多个键将不同`DataFrame`对象的行连接起来。`merge`默认根据索引或列名对齐,但也可以通过`on`, `left_on`, `right_on`等参数指定键值。
```python
df1 = pd.DataFrame({'A': ['foo', 'bar'], 'B': [1, 2]})
df2 = pd.DataFrame({'A': ['foo', 'baz'], 'C': [3, 4]})
# 按键合并
df_merged = pd.merge(df1, df2, on='A')
```
`join`方法在行为上类似于`merge`,但默认是根据索引进行合并的。它的参数与`merge`相似,但`join`通常用于将一个`DataFrame`的列与另一个具有共同索引的`DataFrame`的列合并。
```python
df1 = pd.DataFrame({'A': ['foo', 'bar'], 'B': [1, 2]})
df2 = pd.DataFrame({'C': [3, 4]}, index=['foo', 'bar'])
# 按索引合并
df_joined = df1.join(df2)
```
#### 2.3.2 数据重塑:stack、unstack和pivot
数据重塑是将数据从一种格式转换为另一种格式的过程,这在数据分析中是常见的需求。Pandas提供了`stack`, `unstack`和`pivot`方法来执行这些操作。
`stack`方法将`DataFrame`的列“压缩”成行,从而将列的列头“移动”到索引中去。相对的,`unstack`方法则执行相反的操作,将行转换成列。
```python
df = pd.DataFrame({'A': ['one', 'two'], 'B': ['x', 'y'], 'C': ['a', 'b']})
# 压缩DataFrame
df_stacked = df.set_index(['A', 'B']).stack()
# 反压缩DataFrame
df_unstacked = df_stacked.unstack()
```
`pivot`方法提供了一种基于列值创建一个新的“透视表”的方式。通过指定`index`, `columns`, 和 `values`参数,可以将数据重塑为所需格式。
```python
df = pd.DataFrame({
'A': ['foo', 'foo', 'foo', 'foo', 'bar', 'bar', 'bar', 'bar'],
'B': ['one', 'one', 'two', 'two', 'one', 'one', 'two', 'two'],
'C': ['small', 'large', 'small', 'large', 'small', 'large', 'small', 'large'],
'D': [1, 2, 3, 4, 5, 6, 7, 8],
'E': [2, 4, 5, 5, 6, 8, 9, 9]
})
# 创建透视表
df_pivoted = df.pivot(index='A', columns='B', values='C')
```
通过这些方法,Pandas能够高效地对数据进行重塑,以适应进一步的数据分析和处理需求。
# 3. 数据分析与探索性统计
## 3.1 描述性统计分析
### 3.1.1 基本的描述性统计函数
在Pandas库中,描述性统计分析是一组用于总结数据集中数值型变量的特征的方法。这些方法包括计算均值、标准差、最小值、最大值、四分位数等。Pandas提供了`describe()`方法,可以快速得到这些统计量。对于非数值型数据,`describe()`方法还会提供唯一值的数量和最常见值。
```python
import pandas as pd
# 创建一个DataFrame用于演示
data = {'height': [170, 180, 165, 190, 175],
'weight': [60, 80, 55, 90, 70]}
df = pd.DataFrame(data)
# 使用describe()方法获取描述性统计
descriptive_stats = df.describe()
print(descriptive_stats)
```
在上述代码中,`describe()`方法默认会计算数值型列的统计量。如果需要对特定列进行描述性统计分析,可以指定列名。
### 3.1.2 分组与聚合操作
Pandas的`groupby()`方法允许对数据进行分组,而聚合操作则是将分组后的数据按照一定的统计规则进行汇总。常见的聚合函数包括`sum()`、`mean()`、`median()`、`count()`、`std()`等。
```python
# 按身高分组计算体重的平均值
grouped = df.groupby('height')['weight'].mean()
print(grouped)
```
在上述示例中,我们按照身高对数据进行了分组,并计算了每个身高组的平均体重。`groupby()`方法可以搭配任何聚合函数使用,以适应不同的数据分析需求。
## 3.2 数据过滤与条件选择
### 3.2.1 基于条件的过滤
数据过滤是指根据特定条件筛选数据的过程。在Pandas中,这可以通过布尔索引实现,即创建一个布尔序列来表示每行数据是否满足条件。
```python
# 筛选身高大于175cm的数据
filtered_data = df[df['height'] > 175]
print(filtered_data)
```
上述代码中,`df['height'] > 175`创建了一个布尔序列,其中身高大于175cm的位置为True,其余为False。`df[...]`用于选择满足条件的数据。
### 3.2.2 使用query方法进行数据选择
Pandas中的`query()`方法提供了一种便捷的方式来根据条件过滤数据。使用`query()`方法时,可以直接在字符串中表达条件,无需显式地引用DataFrame对象。
```python
# 使用query方法按体重小于等于60kg筛选数据
query_data = df.query('weight <= 60')
print(query_data)
```
上述代码中,`'weight <= 60'`是一个条件表达式,`query()`方法根据这个表达式返回满足条件的数据。`query()`方法通常用于表达式较为复杂或更易于阅读的场景。
## 3.3 数据可视化
### 3.3.1 基于Pandas的图表绘制
Pandas集成了matplotlib库,可以轻松地绘制图表。这对于数据的初步可视化非常有帮助。Pandas提供了`plot`方法,可以通过调用它来绘制线图、柱状图、散点图等。
```python
import matplotlib.pyplot as plt
# 绘制身高和体重的散点图
df.plot(kind='scatter', x='height', y='weight')
plt.show()
```
上述代码中,`kind='scatter'`指定了图表的类型为散点图。`x`和`y`参数分别指定了数据的横轴和纵轴。
### 3.3.2 高级绘图技巧与定制化图表
在Pandas中,除了简单的图表绘制,还可以通过设置参数来定制更加复杂和美观的图表。例如,可以设置图表的标题、轴标签、图例、颜色等。
```python
# 绘制一个带有标题和轴标签的柱状图
df['height'].plot(kind='bar')
plt.title('Height Distribution')
plt.xlabel('Index')
plt.ylabel('Height (cm)')
plt.show()
```
上述代码绘制了一个柱状图,并通过`plt.title()`, `plt.xlabel()`, 和`plt.ylabel()`为图表添加了标题和轴标签。
通过上述各个章节的详细介绍,我们可以看到Pandas不仅在数据处理方面提供了丰富的功能,它在数据分析与可视化方面也展现出了强大的能力。无论是进行基本的描述性统计分析,还是根据条件过滤数据,Pandas都能有效地帮助我们完成任务,并且在数据可视化方面,它与matplotlib的无缝集成让生成图表变得简单高效。在下一章中,我们将进一步深入学习Pandas在高级数据处理方面的技术。
# 4. ```
# 第四章:高级数据处理技术
## 4.1 时间序列分析
### 4.1.1 时间数据的读取与处理
在处理时间序列数据时,Pandas 提供了强大的功能来帮助我们高效地读取和解析时间数据。首先,Pandas 的 `read_csv` 和 `read_excel` 函数支持一个参数 `parse_dates`,可以自动识别日期字段并将它们转换为 `DatetimeIndex` 类型。当遇到多个列组合成日期时,可以使用 `date_parser` 参数指定一个自定义函数来处理。
要查看和分析时间序列数据,Pandas 提供了 `to_datetime` 方法,它能够将包含日期信息的字符串转换为 `Datetime` 对象。例如:
```python
import pandas as pd
# 示例:将字符串转换为Datetime对象
date_str = '2023-01-01'
date_obj = pd.to_datetime(date_str)
print(date_obj)
```
该方法通常配合 `DataFrame` 使用,例如在读取 CSV 文件时将日期列转换为日期时间格式:
```python
df = pd.read_csv('timeseries_data.csv', parse_dates=['date_column'])
```
如果时间数据不规范或者格式复杂,我们还可以使用 `pandas.to_datetime` 函数的 `format` 参数来指定时间字符串的格式:
```python
df['date_column'] = pd.to_datetime(df['date_column'], format='%Y-%m-%d %H:%M:%S')
```
### 4.1.2 时间序列的重采样与频率转换
时间序列数据常常需要通过重采样(resampling)来转换其时间频率。Pandas 的 `resample` 方法允许我们按照时间间隔进行数据聚合。例如,将每分钟的温度数据转换为每小时的平均温度:
```python
temperature = df['temperature']
hourly_avg = temperature.resample('H').mean()
print(hourly_avg)
```
`resample` 方法的操作与 `groupby` 类似,但它专门用于时间序列数据。你可以指定不同的频率参数,如 'D' (天), 'W' (周), 'M' (月), 'Q' (季度), 'Y' (年) 等。
为了更细致地控制重采样过程,还可以使用 `asfreq` 方法来获取指定频率的时间索引,而不进行任何聚合操作:
```python
# 获取每月第一个工作日的数据
monthly_firstweekday = df['data_column'].asfreq('BMS')
```
## 4.2 分类数据与数据编码
### 4.2.1 分类数据的处理方法
在数据分析中,分类数据是常见的类型,它们通常表示离散的值。Pandas 提供了处理分类数据的方法,这对于性能优化和建模都是有益的。Pandas 使用 `Categorical` 数据类型来处理分类数据,它可以提高内存效率,并且允许有序和无序的分类。
首先,我们可以直接创建一个 `Categorical` 类型的列:
```python
df['category_column'] = pd.Categorical(['A', 'B', 'C', 'A'])
```
分类数据可以进行排序,但需要小心,因为默认情况下 `Categorical` 是无序的。如果需要有序分类,必须在创建时指定顺序:
```python
df['ordered_category_column'] = pd.Categorical(['low', 'medium', 'high'], ordered=True)
```
我们可以利用 `astype` 方法将一个列转换为分类数据类型:
```python
df['another_category_column'] = df['column_with_values'].astype('category')
```
### 4.2.2 编码和转换技巧
Pandas 提供了多种编码转换方法,如 `get_dummies`, `factorize` 和 `map`,用于将分类数据转换为数值数据,便于进行统计分析和机器学习建模。
使用 `get_dummies` 方法可以将分类变量转换为虚拟/指示变量,这对机器学习模型特别有用:
```python
df = pd.get_dummies(df, columns=['category_column'])
```
另一个有用的方法是 `factorize`,它为分类值分配一个唯一的整数:
```python
codes, unique = pd.factorize(df['category_column'])
```
在某些情况下,我们可能想要对分类数据应用自定义的映射规则,`map` 方法可以实现这一点:
```python
category_map = {'A': 1, 'B': 2, 'C': 3}
df['mapped_column'] = df['category_column'].map(category_map)
```
## 4.3 性能优化与并行处理
### 4.3.1 数据处理性能优化策略
数据处理是一个计算密集型的过程,合理优化可以显著提高效率。Pandas 的性能优化方法包括但不限于使用向量化操作、避免使用低效的循环、使用内建函数替代自定义函数等。
向量化操作比循环执行得快得多,因此优先使用如 `apply`、`applymap` 和 `vectorize` 等函数:
```python
df['new_column'] = df['existing_column'].apply(lambda x: x + 1)
```
此外,使用布尔索引代替 `where` 方法也是一个性能优化的技巧:
```python
df[df['column'] > 0]
```
### 4.3.2 使用Dask进行大规模数据处理
当数据集变得非常大,以至于无法一次性装入内存时,Dask 就成为了 Pandas 的一个强大的并行计算替代品。Dask 能够处理大于内存的数据集,并且可以轻松地并行化计算。
Dask 的 `DataFrame` 结构与 Pandas 非常相似,这使得它很容易上手。例如,使用 Dask 读取大文件时:
```python
import dask.dataframe as dd
dask_df = dd.read_csv('large_file.csv')
```
Dask 作业是惰性的,它们不会在创建时运行,而是在需要结果时运行。为了执行计算,你可以调用 `compute` 方法:
```python
result = dask_df.groupby('category_column').sum().compute()
```
Dask 还提供了 `dask.delayed` 装饰器,允许你编写常规的 Python 函数,然后作为延迟计算任务来运行:
```python
from dask import delayed
@delayed
def compute_sum(df):
return df.sum()
total = compute_sum(dask_df['some_column'])
result = ***pute()
```
通过这种方式,Dask 允许我们处理大规模数据集,同时保持了代码的简洁性和易读性。
```
# 5. Pandas项目实战案例
在IT行业中,数据分析是至关重要的一个环节,而Pandas库作为Python中强大的数据分析工具,广泛应用于金融、电商、生物信息学等多个领域。在本章节中,我们将通过几个实战案例,深入了解如何利用Pandas进行项目级的数据处理。
## 5.1 金融数据分析项目
金融领域对数据分析的准确性、及时性要求极高。我们将从金融数据的导入和初步清洗开始,到高级数据分析与报告的输出进行实战演练。
### 5.1.1 数据导入与初步清洗
在开始分析前,首先要导入数据并进行初步的清洗工作。
```python
import pandas as pd
# 假设数据存储在CSV文件中
data = pd.read_csv('financial_data.csv')
# 查看数据基本信息
***()
# 数据清洗过程
data.dropna(inplace=True) # 删除空值
data = data[data['amount'] > 0] # 过滤掉交易金额为0的记录
# 对日期进行转换,确保后续能正确处理
data['date'] = pd.to_datetime(data['date'], format='%Y-%m-%d')
```
### 5.1.2 高级数据分析与报告
清洗后,我们需要进行更深入的数据分析,并生成相应的报告。
```python
# 计算每个客户的总交易金额
total_by_customer = data.groupby('customer_id')['amount'].sum()
# 计算每月交易量
data['month'] = data['date'].dt.to_period('M')
monthly_volume = data.groupby('month')['id'].count()
# 输出报告
print("Top 10 Customers by Total Amount Spent:")
print(total_by_customer.sort_values(ascending=False).head(10))
print("\nMonthly Transaction Volume:")
print(monthly_volume)
```
通过上述步骤,我们完成了数据的导入、清洗、分析,并成功输出了报告。
## 5.2 电商客户行为分析项目
电商企业利用数据分析来优化营销策略、提高客户满意度和留存率。接下来,我们将了解如何进行电商数据的预处理和用户画像构建,以及行为趋势分析与预测模型的应用。
### 5.2.1 数据预处理与用户画像构建
在电商数据分析中,用户的行为数据尤为重要。
```python
# 数据预处理示例
ecommerce_data = pd.read_csv('ecommerce_data.csv')
ecommerce_data['purchase_date'] = pd.to_datetime(ecommerce_data['purchase_date'])
# 用户画像构建,假设我们根据用户的购买频次、平均购买金额等信息构建
user_profiles = ecommerce_data.groupby('user_id').agg({
'purchase_date': lambda x: (x.max() - x.min()).days,
'amount': 'mean'
})
user_profiles.rename(columns={'purchase_date': 'user_tenure', 'amount': 'avg_purchase'}, inplace=True)
```
### 5.2.2 行为趋势分析与预测模型应用
接下来,我们可以利用时间序列分析来预测未来的购买趋势。
```python
from statsmodels.tsa.api import ExponentialSmoothing
# 假设'purchase_date'是日期,'purchase_count'是每个日期的购买次数
time_series = ecommerce_data.groupby('purchase_date')['purchase_count'].sum()
# 使用指数平滑模型进行趋势预测
fit_model = ExponentialSmoothing(time_series, seasonal='mul', seasonal_periods=12).fit()
# 预测未来的趋势
forecast = fit_model.forecast(steps=6) # 预测未来6个时间点的趋势
print("Forecasted Purchase Trend:")
print(forecast)
```
## 5.3 生物信息学数据处理项目
生物信息学数据处理项目通常涉及到基因表达数据的整理和分析。我们将展示如何对这些数据进行整理,并利用Pandas生成可视化的图表以辅助研究。
### 5.3.1 基因表达数据的整理与分析
基因表达数据通常包含样本和基因的表达水平信息。
```python
# 假设基因表达矩阵存储在CSV文件中
expression_data = pd.read_csv('gene_expression_data.csv', index_col=0)
# 数据整理,例如标准化处理
expression_data = (expression_data - expression_data.mean()) / expression_data.std()
# 查找差异表达基因
mean_expression = expression_data.mean(axis=1)
differentially_expressed_genes = mean_expression[mean_expression > 1].index.tolist()
```
### 5.3.2 数据可视化与研究发现
最后,我们将使用Pandas内置的绘图工具来可视化基因表达数据。
```python
# 以箱形图可视化特定基因的表达情况
expression_data['Gene_A'].plot(kind='box', title='Expression Level of Gene A')
```
通过本章节的实战案例,我们深入理解了Pandas在处理不同类型数据项目中的应用和实际操作流程。这些案例展示了Pandas的强大功能,无论是在金融、电商还是生物信息学领域,它都提供了灵活而高效的解决方案。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python Pandas 专栏!本专栏旨在帮助您在 24 小时内掌握 Pandas 的绝技,从数据处理秘籍到数据清洗利器,从高效数据筛选手册到深入 Pandas 索引艺术。
您将学习如何使用 Pandas 进行时间序列分析、创建数据透视表、处理缺失数据,以及在机器学习预处理中应用 Pandas。此外,本专栏还将介绍 Python 与数据库交互、Pandas 性能优化、数据融合与合并操作、数据可视化、数据转换、数据分段与离散化处理、层级索引,以及大规模数据处理中的实践。
通过阅读本专栏,您将掌握 Pandas 的核心概念和高级技巧,成为数据分析领域的专家。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【软件管理系统设计全攻略】:从入门到架构的终极指南
# 摘要
随着信息技术的飞速发展,软件管理系统成为支持企业运营和业务创新的关键工具。本文从概念解析开始,系统性地阐述了软件管理系统的需求分析、设计、数据设计、开发与测试、部署与维护,以及未来的发展趋势。重点介绍了系统需求分析的方法论、系统设计的原则与架构选择、数据设计的基础与高级技术、以及质量保证与性能优化。文章最后
【硬盘修复的艺术】:西数硬盘检测修复工具的权威指南(全面解析WD-L_WD-ROYL板支持特性)

# 摘要
本文深入探讨了硬盘修复的基础知识,并专注于西部数据(西数)硬盘的检测修复工具。首先介绍了西数硬盘的内部结构与工作原理,随后阐述了硬盘故障的类型及其原因,包括硬件与软件方面的故障。接着,本文详细说明了西数硬盘检测修复工具的检测和修复理论基础,以及如何实践安装、配置和
【sCMOS相机驱动电路信号完整性秘籍】:数据准确性与稳定性并重的分析技巧

# 摘要
本文针对sCMOS相机驱动电路信号完整性进行了系统的研究。首先介绍了信号完整性理论基础和关键参数,紧接着探讨了信号传输理论,包括传输线理论基础和高频信号传输问题,以及信号反射、串扰和衰减的理论分析。本文还着重分析了电路板布局对信号完整性的影响,提出布局优化策略以及高速数字电路的布局技巧。在实践应用部分,本文提供了信号完整性测试工具的选择,仿真软件的应用,
能源转换效率提升指南:DEH调节系统优化关键步骤
# 摘要
能源转换效率对于现代电力系统至关重要,而数字电液(DEH)调节系统作为提高能源转换效率的关键技术,得到了广泛关注和研究。本文首先概述了DEH系统的重要性及其基本构成,然后深入探讨了其理论基础,包括能量转换原理和主要组件功能。在实践方法章节,本文着重分析了DEH系统的性能评估、参数优化调整,以及维护与故障排除策略。此外,本文还介绍了DEH调节系统的高级优化技术,如先进控制策略应用、系统集成与自适应技术,并讨论了节能减排的实现方法。最后,本文展望了DEH系统优化的未来趋势,包括技术创新、与可再生能源的融合以及行业标准化与规范化发展。通过对DEH系统的全面分析和优化技术的研究,本文旨在为提
【AT32F435_AT32F437时钟系统管理】:精确控制与省电模式

# 摘要
本文系统性地探讨了AT32F435/AT32F437微控制器中的时钟系统,包括其基本架构、配置选项、启动与同步机制,以及省电模式与能效管理。通过对时钟系统的深入分析,本文强调了在不同应用场景中实现精确时钟控制与测量的重要性,并探讨了高级时钟管理功能。同时,针对时钟系统的故障预防、安全机制和与外围设备的协同工作进行了讨论。最后,文章展望了时
【MATLAB自动化脚本提升】:如何利用数组方向性优化任务效率
# 摘要
本文深入探讨MATLAB自动化脚本的构建与优化技术,阐述了MATLAB数组操作的基本概念、方向性应用以及提高脚本效率的实践案例。文章首先介绍了MATLAB自动化脚本的基础知识及其优势,然后详细讨论了数组操作的核心概念,包括数组的创建、维度理解、索引和方向性,以及方向性在数据处理中的重要性。在实际应用部分,文章通过案例分析展示了数组方向性如何提升脚本效率,并分享了自动化
现代加密算法安全挑战应对指南:侧信道攻击防御策略
# 摘要
侧信道攻击利用信息泄露的非预期通道获取敏感数据,对信息安全构成了重大威胁。本文全面介绍了侧信道攻击的理论基础、分类、原理以及实际案例,同时探讨了防御措施、检测技术以及安全策略的部署。文章进一步分析了侧信道攻击的检测与响应,并通过案例研究深入分析了硬件和软件攻击手段。最后,本文展望了未来防御技术的发展趋势,包括新兴技术的应用、政策法规的作用以及行业最佳实践和持续教育的重要性。
# 关键字
侧信道攻击;信息安全;防御措施;安全策略;检测技术;防御发展趋势
参考资源链接:[密码编码学与网络安全基础:对称密码、分组与流密码解析](https://wenku.csdn.net/doc/64
【科大讯飞语音识别技术完全指南】:5大策略提升准确性与性能

# 摘要
本论文综述了语音识别技术的基础知识和面临的挑战,并着重分析了科大讯飞在该领域的技术实践。首先介绍了语音识别技术的原理,包括语音信号处理基础、自然语言处理和机器学习的应用。随
【现场演练】:西门子SINUMERIK测量循环在多样化加工场景中的实战技巧
# 摘要
本文旨在全面介绍西门子SINUMERIK测量循环的理论基础、实际应用以及优化策略。首先概述测量循环在现代加工中心的重要作用,继而深入探讨其理论原理,包括工件测量的重要性、测量循环参数设定及其对工件尺寸的影响。文章还详细分析了测量循环在多样化加工场景中的应用,特别是在金属加工和复杂形状零件制造中的挑战,并提出相应的定制方案和数据处理方法。针对多轴机床的测量循环适配,探讨了测量策略和同步性问题。此外,本文还探讨了测量循环的优化方法、提升精确度的技巧,以及西门子SINUMERIK如何融合新兴测量技术。最后,本文通过综合案例分析与现场演练,强调了理论与实践的结合,并对未来智能化测量技术的发展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )