C++环境和程序控制:系统级交互的高级技巧
发布时间: 2024-10-22 07:03:03 阅读量: 18 订阅数: 28 

C++程序设计:高级程序设计大作业图书管理系统.zip

# 1. C++环境搭建与基础配置
在本章中,我们将开始探索C++编程的基础。首先,我们会介绍如何搭建一个稳定且高效的C++开发环境,包括必要的软件安装和配置步骤。然后,我们会简要介绍C++编译器的选择及其相关配置选项,为你打造一个坚实的编程基石。
## 1.1 开发环境安装
搭建C++开发环境的第一步是选择合适的编译器。目前最为广泛使用的编译器有GCC、Clang以及MSVC。用户需要根据自己的操作系统,选择合适的安装包进行下载并安装。
## 1.2 编译器配置
安装完成后,你需要配置编译器的路径,并设置环境变量,以便在任何目录下通过命令行调用编译器。例如,在Windows系统中,你可能需要添加编译器路径到系统的Path环境变量中。
## 1.3 基础开发工具链
除了编译器之外,一个完整的开发工具链还应该包括代码编辑器或集成开发环境(IDE)、调试工具、版本控制系统等。在本章中,我们将介绍如何配置这些工具,使得开发者可以顺利进行C++编程。
```bash
# 示例:添加GCC编译器路径到Path环境变量
# 在Windows的CMD中输入
set PATH=%PATH%;C:\path\to\gcc\bin
```
以上代码块展示了如何在Windows环境下添加GCC编译器的路径到Path环境变量中,确保用户可以全局访问到编译器命令。这只是环境配置的第一步,接下来,我们将继续深入到C++程序的控制流程与逻辑中去。
# 2. C++程序控制流程与逻辑
## 2.1 基本控制结构
### 2.1.1 条件语句
在C++中,条件语句允许我们基于特定条件执行不同的代码块。最常见的条件语句是`if-else`结构,它允许我们根据一个布尔表达式的结果来选择执行哪段代码。此外,`switch`语句提供了另一种处理多个可能值的方法。
C++中的`if-else`语句的一般形式如下所示:
```cpp
if (condition) {
// 条件为真时执行的代码
} else if (another_condition) {
// 如果上面的条件为假,但这个条件为真时执行的代码
} else {
// 如果上述条件都为假时执行的代码
}
```
使用`switch`语句时,我们需要一个表达式,通常是一个变量或一个返回值的表达式,然后根据该表达式的值跳转到`case`标签处执行。
```cpp
switch (expression) {
case value1:
// 当表达式结果等于value1时执行的代码
break;
case value2:
// 当表达式结果等于value2时执行的代码
break;
// 可以有更多的case标签
default:
// 当没有任何case标签匹配时执行的代码
}
```
### 2.1.2 循环语句
循环语句允许我们重复执行代码块,直到满足某个条件为止。C++提供了几种不同类型的循环语句,其中最常见的包括`for`循环、`while`循环和`do-while`循环。
`for`循环的一般形式如下:
```cpp
for (initialization; condition; update) {
// 循环体中的代码
}
```
`while`循环和`do-while`循环主要用于当不知道要执行多少次循环的情况下:
```cpp
while (condition) {
// 循环体中的代码
}
do {
// 循环体中的代码
} while (condition);
```
## 2.2 高级控制技巧
### 2.2.1 异常处理机制
异常处理是C++中一种处理错误的机制。当程序执行发生异常情况时,可以抛出异常,然后由异常处理器捕获并处理。异常可以是任何类型,通常它们是从`std::exception`类派生的对象,这个类提供了`what()`方法,返回一个描述异常的字符串。
```cpp
try {
// 尝试执行的代码
if (some_error_condition) {
throw std::runtime_error("An error occurred");
}
} catch (const std::exception& e) {
// 捕获并处理异常
std::cerr << "Caught exception: " << e.what() << '\n';
}
```
### 2.2.2 函数指针和回调函数
函数指针是指向函数的指针变量,通过函数指针可以调用该指针指向的函数。回调函数是一种用户定义的函数,它被用作参数传递给另一个函数,而后者在适当的时候调用前者。
```cpp
// 函数声明
void my_callback(int parameter);
// 使用函数指针
void (*callback_ptr)(int) = my_callback;
callback_ptr(10);
// 将my_callback作为回调函数传递给另一个函数
void process_data(int data, void (*callback)(int)) {
callback(data);
}
process_data(10, my_callback);
```
## 2.3 系统级交互控制
### 2.3.1 系统调用
系统调用是操作系统内核提供给用户程序的一组预定义的函数,允许用户程序请求内核提供的服务。在C++中,可以使用系统调用来完成诸如文件操作、进程管理等任务。
```cpp
#include <iostream>
#include <sys/types.h>
#include <unistd.h>
int main() {
// 系统调用 fork 创建一个新进程
pid_t pid = fork();
if (pid == -1) {
// fork 失败
perror("fork failed");
return 1;
} else if (pid == 0) {
// 子进程
std::cout << "This is the child process\n";
} else {
// 父进程
std::cout << "This is the parent process, child PID is " << pid << '\n';
}
return 0;
}
```
### 2.3.2 多线程控制与同步
多线程编程允许程序同时执行多个任务。C++11标准引入了对线程的原生支持,允许开发者创建和管理线程。线程同步是确保并发线程安全访问共享资源的一种机制。
```cpp
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mtx;
void print_ids(int id) {
mtx.lock(); // 上锁
std::cout << "Hello from thread " << id << '\n';
mtx.unlock(); // 解锁
}
int main() {
std::thread threads[10];
// 创建并启动10个线程
for (int i = 0; i < 10; ++i) {
threads[i] = std::thread(print_ids, i);
}
// 等待所有线程完成
for (auto& th : threads) {
th.join();
}
return 0;
}
```
在本章节中,我们学习了C++的基本控制结构,包括条件语句和循环语句,以及如何使用异常处理机制和函数指针。接着,我们探讨了系统级的交互控制,包括系统调用和多线程控制与同步。所有这些基础知识为学习更高级的编程技巧奠定了坚实的基础。
# 3. C++系统级编程实践
## 3.1 文件系统交互
### 3.1.1 文件读写操作
在C++中,文件读写操作是系统级编程中的一项基础技能,它涉及到文件的打开、读取、写入以及关闭等操作。C++提供了多种方式来处理文件系统,其中最常用的是C++标准库中的`<fstream>`头文件所包含的`ifstream`、`ofstream`和`fstream`类。
下面是一个简单的文件写入操作示例:
```cpp
#include <fstream>
#include <iostream>
int main() {
// 创建并打开一个文件用于写入,如果文件不存在会创建它,存在则清空内容
std::ofstream outFile("example.txt");
// 检查文件是否成功打开
if (!outFile.is_open()) {
std::cerr << "无法打开文件" << std::endl;
return 1;
}
// 向文件写入内容
outFile << "Hello, World!" << std::endl;
// 关闭文件流
outFile.close();
return 0;
}
```
在上述代码中,我们首先包含了`<fstream>`头文件,然后创建了`ofstream`类的实例`outFile`,用于输出内容到文件。使用`open`函数打开文件(在这里文件名为`example.txt`),然后通过`<<`运算符向文件中写入字符串`"Hello, World!"`。使用`close`函数关闭文件流。
与之相对应的,文件的读取可以通过`ifstream`类完成:
```cpp
#include <fstream>
#include <iostream>
#include <string>
int main() {
std::ifstream inFile("example.txt");
if (!inFile.is_open()) {
std::cerr << "无法打开文件" << std::endl;
return 1;
}
std::string line;
// 逐行读取文件直到文件结束
while (std::getline(inFile, line)) {
std::cout << line << std::endl;
}
inFile.close();
return 0;
}
```
在这里,我们用`ifstream`打开文件用于读取,通过循环使用`getline`函数逐行读取文件内容,并将每行输出到标准输出流中。最后,同样别忘了关闭文件流。
### 3.1.2 目录管理与遍历
目录管理包括了创建、删除目录以及遍历目录中的文件和子目录。在C++中,可以使用`<filesystem>`库(C++17起支持)进行目录操作。下面是几个基本操作的例子:
```cpp
#include <filesystem>
#include <iostream>
namespace fs = std::filesystem;
int main() {
// 创建目录
fs::create_directory("newdir");
// 遍历当前目录下的所有文件和子目录
for (const auto& entry : fs::directory_iterator(fs::current_path())) {
std::cout << entry.path() << '\n';
}
// 删除目录
if (fs::remove("newdir")) {
std::cout << "目录删除成功" << std::endl;
} else {
std::cout << "目录删除失败" << std::endl;
}
return 0;
}
```
在这个例子中,我们首先创建了一个名为`newdir`的目录,然后遍历了当前工作目录下的所有文件和子目录,并将它们的路径输出到标准输出。最后,我们尝试删除了刚才创建的`newdir`目录。
目录遍历的代码段使用了`directory_iterator`,它可以迭代给定路径下的所有条目,并允许我们在循环中逐个访问它们。
## 3.2 网络编程应用
### 3.2.1 套接字编程基础
网络编程的基础是套接字(Socket)编程,它允许我们在计算机网络上的不同主机间通过网络进行通信。C++中可以使用Berkeley套接字API进行网络编程。一个简单的TCP客户端示例如下:
```cpp
#include <iostream>
#include <sy
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
C++标准库专栏深入解析了C++编程语言的强大功能,涵盖了从基础到高级的20个关键技巧。它从Hello World程序开始,逐步介绍了输入输出流、STL容器、函数对象、算法、迭代器、异常处理、字符串处理、正则表达式、并发编程、文件系统、内存管理、国际化、信号处理、环境控制、数学函数和随机数生成等主题。通过这些技巧,开发者可以提升代码效率、灵活性、可维护性和可移植性,从而构建出健壮且高效的C++应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数据链路层深度剖析:帧、错误检测与校正机制,一次学懂

# 摘要
数据链路层是计算机网络架构中的关键组成部分,负责在相邻节点间可靠地传输数据。本文首先概述了数据链路层的基本概念和帧结构,包括帧的定义、类型和封装过程。随后,文章详细探讨了数据链路层的错误检测机制,包括检错原理、循环冗余检验(CRC)、奇偶校验和校验和,以及它们在错误检测中的具体应用。接着,本文介绍了数据链路层的错误校正技术,如自动重传请求(ARQ
【数据完整性管理】:重庆邮电大学实验报告中的关键约束技巧
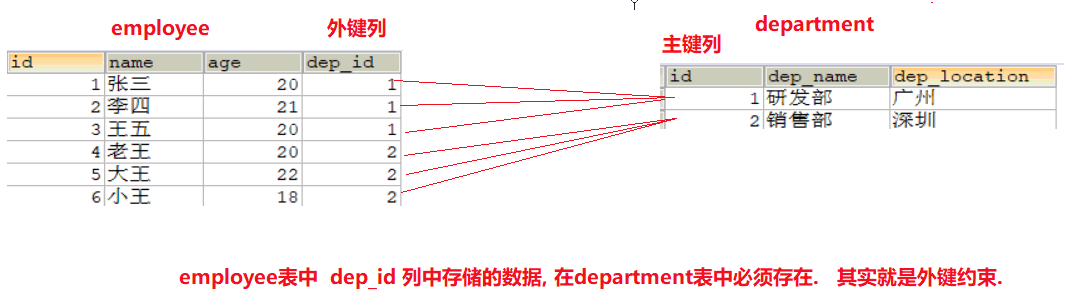
# 摘要
数据完整性是数据库管理系统中至关重要的概念,它确保数据的质量和一致性。本文首先介绍了数据完整性的概念、分类以及数据库约束的基本原理和类型。随后,文章深入探讨了数据完整性约束在实践中的具体应用,包括主键和外键约束的设置、域约束的管理和高级技巧如触发器和存储过程的运用。接着,本文分析了约束带来的性能影响,并提出了约束优化与维护的策略。最后,文章通过案例分析,对数据完整性管理进行了深度探讨,总结了实际操作中的
深入解析USB协议:VC++开发者必备的8个关键点
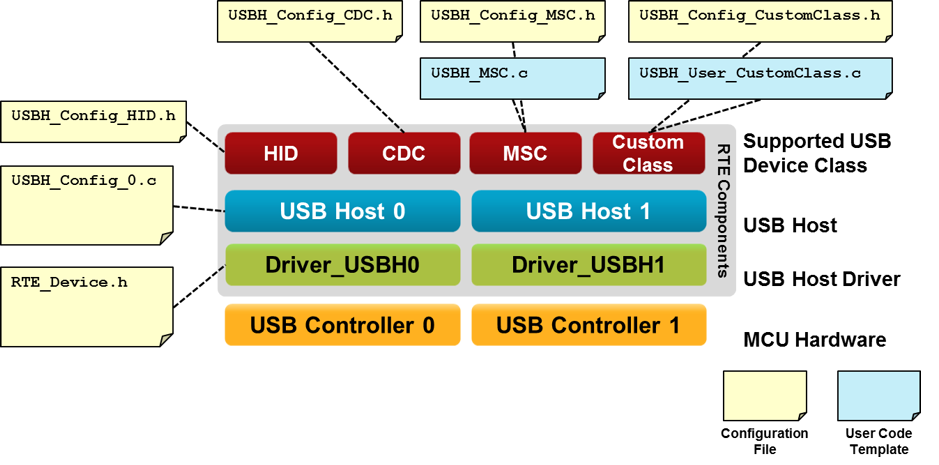
# 摘要
本文系统地介绍了USB协议的基础知识、硬件基础、数据传输机制、在VC++中的实现以及高级特性与编程技巧。首先概述USB协议的基础,然后详细探讨了USB硬件的物理接口、连接规范、电源管理和数据传输的机制。文章接着阐述了在VC++环境下USB驱动程序的开发和与USB设备通信的编程接口。此外,还涉及了USB设备的热插拔与枚举过程、性能优化,以及USB协议高级特性和编程技巧。最后,本文提供了USB设备的调试工具和方法,以
【科东纵密性能调优手册】:监控系统到极致优化的秘笈

# 摘要
性能调优是提高软件系统效率和响应速度的关键环节。本文首先介绍了性能调优的目的与意义,概述了其基本原则。随后,深入探讨了系统性能评估的方法论,包括基准测试、响应时间与吞吐量分析,以及性能监控工具的使用和系统资源的监控。在硬件优化策略方面,详细分析了CPU、内存和存储的优化方法。软件与服务优化章节涵盖了数据库、应用程序和网络性能调
【FPGA引脚规划】:ug475_7Series_Pkg_Pinout.pdf中的引脚分配最佳实践

# 摘要
本文全面探讨了FPGA引脚规划的关键理论与实践方法,旨在为工程师提供高效且可靠的引脚配置策略。首先介绍了FPGA引脚的基本物理特性及其对设计的影响,接着分析了设计时需考虑的关键因素,如信号完整性、热管理和功率分布。文章还详细解读了ug475_7S
BY8301-16P语音模块全面剖析:从硬件设计到应用场景的深度解读
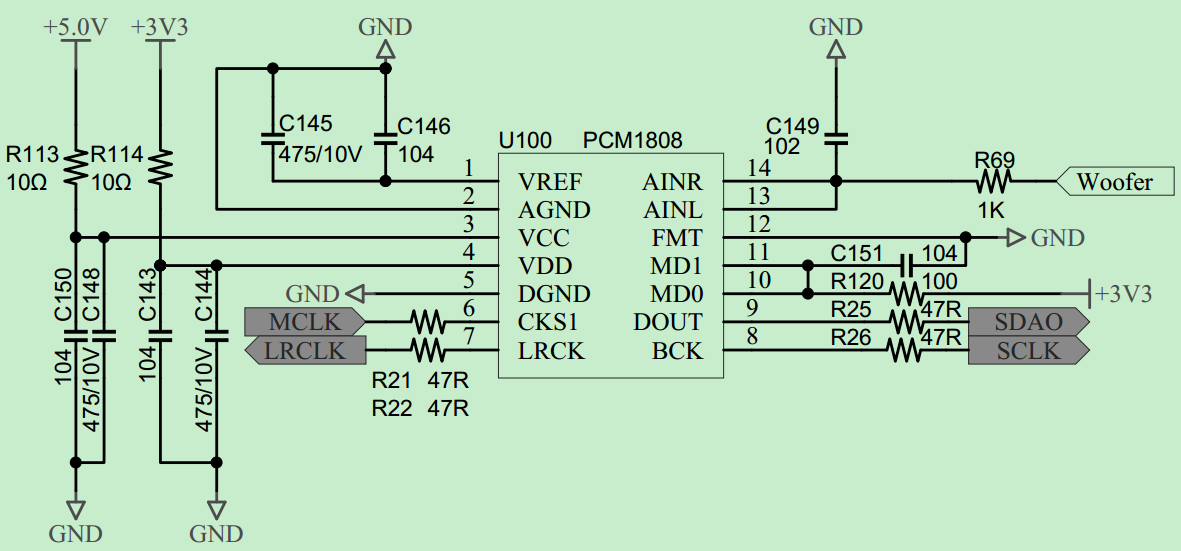
# 摘要
本文详细介绍了BY8301-16P语音模块的技术细节、硬件设计、软件架构及其应用场景。首先概述了该模块的基本功能和特点,然后深入解析其硬件设计,包括主控芯片、音频处理单元、硬件接口和电路设计的优化。接着,本文探讨了软件架构、编程接口以及高级编程技术,为开发者提供了编程环境搭建和
【Ansys命令流深度剖析】:从脚本到高级应用的无缝进阶
# 摘要
本文深入探讨了Ansys命令流的基础知识、结构和语法、实践应用、高级技巧以及案例分析与拓展应用。首先,介绍了Ansys命令流的基本构成,包括命令、参数、操作符和分隔符的使用。接着,分析了命令流的参数化、数组操作、嵌套命令流和循环控制,强调了它们在提高命令流灵活性和效率方面的作用。第三章探讨了命令流在材料属性定义、网格划分和结果后处理中的应用,展示了其在提高仿真精度和效率上的实际价值。第四章介绍了命令流的高级技巧,包括宏定义、用户自定义函数、错误处理与调试以及并行处理与性能优化。最后,第五章通过案例分析和扩展应用,展示了命令流在复杂结构模拟和多物理场耦合中的强大功能,并展望了其未来趋势
【Ubuntu USB转串口驱动安装】:新手到专家的10个实用技巧

# 摘要
本文详细介绍了在Ubuntu系统下安装和使用USB转串口驱动的方法。从基础介绍到高级应用,本文系统地探讨了USB转串口设备的种类、Ubuntu系统的兼容性检查、驱动的安装步骤及其验证、故障排查、性能优化、以及在嵌入式开发和远程管理中的实际应用场景。通过本指南,用户可以掌握USB转串口驱动的安装与管理,确保与各种USB转串口设备的顺畅连接和高效使用。同时,本文还提
RH850_U2A CAN Gateway高级应用速成:多协议转换与兼容性轻松掌握

# 摘要
本文全面概述了RH850_U2A CAN Gateway的技术特点,重点分析了其多协议转换功能的基础原理及其在实际操作中的应用。通过详细介绍协议转换机制、数据封装与解析技术,文章展示了如何在不同通信协议间高效转换数据包。同时,本文还探讨了RH850_U2A CAN Gateway在实际操作过程中的设备初始化、协议转换功能实现以及兼容性测试等关键环节。此外,文章还介
【FPGA温度监测:Xilinx XADC实际应用案例】

# 摘要
本文探讨了FPGA在温度监测中的应用,特别是Xilinx XADC(Xilinx Analog-to-Digital Converter)的核心
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )