【C++标准库全面解析】:从Hello World到高效数据处理的20个关键技巧
发布时间: 2024-10-22 05:46:39 阅读量: 18 订阅数: 28 

HelloWorld:Erstes C ++测试宙斯

# 1. C++标准库概述
C++标准库是为C++编程语言提供的一个全面的软件库集合,它包含广泛的功能,涵盖了从数据结构到算法,从数值计算到文本处理等各个方面。本章将对标准库进行概览,为后续章节的深入探讨打下基础。
## 标准库的组成
C++标准库由多个头文件组成,每个头文件定义了一系列相关的功能。例如,`<iostream>` 头文件支持基本的输入输出操作;`<vector>`、`<list>`、`<map>` 等定义了各种容器;`<algorithm>` 提供了算法库等。标准库还提供了对异常处理的支持,定义了异常类层次结构。
## 标准库的设计原则
标准库的设计遵循了几项关键原则,包括类型安全、可扩展性、效率和易用性。通过模板和泛型编程,标准库提供了非常灵活和强大的功能,同时保证了运行时的效率。库的接口设计简洁,易于学习和使用,但又不失强大和灵活性。
在后续的章节中,我们将详细探讨标准库的各个主要组件,了解它们的工作原理和最佳实践。这将帮助你更好地利用C++标准库,编写出高效、健壮且可维护的代码。
# 2. 输入输出操作
### 2.1 标准输入输出流
#### 2.1.1 I/O流的使用与原理
C++标准库中的输入输出流(I/O流)是用于处理数据流的抽象。I/O流的核心组件包括输入流(istream)、输出流(ostream)以及输入输出流(iostream)。在使用I/O流之前,需要包含相应的头文件,如 `<iostream>`,这样才能使用标准输入输出流对象如 `std::cin`(标准输入)和 `std::cout`(标准输出)。
I/O流的基本操作是提取(extraction)和插入(insertion)。提取操作是从输入流中读取数据,而插入操作是向输出流中写入数据。这些操作都是通过重载的流插入运算符(`<<`)和流提取运算符(`>>`)来实现。
下面是一个简单的例子,展示了如何使用I/O流进行基本的输入输出操作:
```cpp
#include <iostream>
int main() {
int number;
std::cout << "Enter a number: ";
std::cin >> number;
std::cout << "You entered: " << number << std::endl;
return 0;
}
```
在上述代码中,`std::cin` 被用来从标准输入读取一个整数值,而 `std::cout` 则用于输出这个值到标准输出。
I/O流不仅限于控制台输入输出,还可以用于文件I/O操作。当涉及到文件输入输出时,`std::fstream` 类用于同时进行文件读写操作,而 `std::ifstream` 和 `std::ofstream` 类分别用于文件读取和文件写入操作。
#### 2.1.2 文件I/O操作
文件I/O操作允许用户从文件中读取数据,或者将数据写入到文件中。C++提供了文件流类,如 `std::ifstream`、`std::ofstream` 和 `std::fstream`,它们继承自 `std::istream`、`std::ostream` 和 `std::iostream`。这些类提供了读取文件和写入文件所需的成员函数。
以下是一个文件读写的简单示例:
```cpp
#include <fstream>
#include <iostream>
int main() {
std::ofstream outfile("example.txt");
if (outfile.is_open()) {
outfile << "Writing to a file.\n";
outfile.close();
} else {
std::cerr << "Unable to open file";
}
std::ifstream infile("example.txt");
std::string line;
if (infile.is_open()) {
while (getline(infile, line)) {
std::cout << line << '\n';
}
infile.close();
} else {
std::cerr << "Unable to open file";
}
return 0;
}
```
在这个例子中,我们首先创建了一个 `std::ofstream` 对象并打开文件 `example.txt` 用于写入。写入操作完成后,我们关闭文件。接下来,我们创建了一个 `std::ifstream` 对象并打开同一文件用于读取。通过 `getline` 函数逐行读取文件内容,并输出到控制台。
I/O流提供了许多高级功能,包括异常处理、格式化输出、缓冲区控制等,这些将在后续章节中进一步探讨。
### 2.2 字符串流与格式化
#### 2.2.1 字符串流的创建与应用
C++中的字符串流(也称为内存流)允许程序将数据直接读取或写入到一个字符串对象中,而不需要使用临时的文件。这使得数据操作更加灵活和方便。字符串流主要通过 `std::stringstream` 类来实现。
创建字符串流的代码示例如下:
```cpp
#include <sstream>
#include <iostream>
#include <string>
int main() {
std::string str = "Some example text.";
std::stringstream ss(str);
std::string buffer;
while (getline(ss, buffer, ' ')) {
std::cout << buffer << '\n';
}
return 0;
}
```
在上面的代码中,我们首先创建了一个 `std::stringstream` 对象,并用一个字符串初始化它。然后,使用 `getline` 函数从字符串流中读取数据,以空格为分隔符,并输出到控制台。
字符串流在处理字符串数据时非常方便,尤其是对于数据的临时存储和格式化转换。例如,可以将各种类型的数据写入 `std::stringstream`,然后通过格式化函数输出为格式化的字符串。这在构造复杂的字符串输出时非常有用。
#### 2.2.2 格式化输出的技巧与实践
格式化输出是使用 `std::ostream` 和其派生类(例如 `std::cout`)时的一个重要特性。C++标准库提供了多种方法来控制输出的格式,包括设置填充字符、调整对齐方式、指定精度、控制小数点的显示等。
例如,可以通过 `std::setprecision` 来指定浮点数输出时的小数位数,使用 `std::fixed` 来控制固定的小数点表示法。下面是一个展示如何使用这些格式化技巧的例子:
```cpp
#include <iostream>
#include <iomanip>
int main() {
double value = 123.456789;
std::cout << "Default output: " << value << std::endl;
std::cout << std::fixed << std::setprecision(2);
std::cout << "Fixed notation with 2 decimal places: " << value << std::endl;
std::cout << std::scientific << std::setprecision(4);
std::cout << "Scientific notation with 4 significant figures: " << value << std::endl;
return 0;
}
```
在上述代码中,我们使用 `std::setprecision` 来设置精度,并通过 `std::fixed` 和 `std::scientific` 来控制输出格式。
格式化输出对于数据的展示特别重要,特别是当需要将数据以易于阅读的方式呈现时。灵活掌握格式化工具是高效编程不可或缺的一部分。接下来,我们将讨论一些高级的I/O特性。
### 2.3 高级I/O特性
#### 2.3.1 自定义输入输出操作
虽然标准库提供了大量的预定义的输入输出操作,但往往某些特定格式的数据处理需要自定义I/O操作。C++允许用户通过重载输入输出运算符来实现这一点。这通常需要重载 `operator>>` 和 `operator<<`,使得它们能够处理自定义类型的输入输出。
下面是一个简单的例子,展示如何为一个结构体类型自定义输出操作:
```cpp
#include <iostream>
struct Point {
double x, y;
// 重载 << 运算符
friend std::ostream& operator<<(std::ostream& os, const Point& point) {
os << "(" << point.x << ", " << point.y << ")";
return os;
}
};
int main() {
Point p = {1.2, 3.4};
std::cout << "Point: " << p << std::endl;
return 0;
}
```
在这个例子中,我们定义了 `Point` 结构体,并为它重载了输出运算符 `<<`。这样,我们可以直接使用 `std::cout` 输出 `Point` 对象的值。
自定义输入操作会稍微复杂一些,通常需要考虑错误检查和异常处理。
#### 2.3.2 I/O流状态检查与异常处理
I/O流具有状态标记来指示流的状态,如成功、失败、无错误等。例如,`eofbit` 表示到达文件末尾,`failbit` 表示输入/输出失败,`badbit` 表示发生严重错误,如硬件故障等。了解和检查这些状态标记对于编写健壮的I/O操作非常重要。
下面是一个检查I/O流状态的示例:
```cpp
#include <iostream>
#include <fstream>
int main() {
std::ifstream file("example.txt");
if (!file.is_open()) {
std::cerr << "Unable to open file";
return 1;
}
while (!file.eof()) {
std::string line;
if (getline(file, line)) {
std::cout << line << std::endl;
} else if (file.eof()) {
std::cout << "End of file reached" << std::endl;
} else {
std::cerr << "Error reading from file";
break;
}
}
file.close();
return 0;
}
```
在此代码中,我们打开一个文件,并使用循环读取每一行直到文件末尾。我们检查 `eofbit` 来判断是否到达了文件末尾,并检查 `failbit` 以确认读取操作是否失败。
此外,C++标准库还支持通过异常处理来响应I/O错误。使用 `try`、`catch` 和 `throw` 关键字可以捕获和处理I/O流操作中可能出现的异常情况。
通过检查状态和处理异常,可以显著提高I/O操作的可靠性,确保程序在面对I/O错误时能够优雅地处理。
在本章中,我们介绍了C++标准库中的输入输出操作,从标准输入输出流的基本使用到自定义I/O操作和流状态检查,涵盖了I/O操作的基本和高级特性。下一章,我们将深入探讨C++标准库中的容器和迭代器,这对于有效管理数据集合和遍历数据集来说至关重要。
# 3. 容器和迭代器
在C++中,容器和迭代器是算法操作数据的核心组件。容器提供了数据存储和管理的方式,而迭代器则是一种提供对容器中元素访问的抽象。本章节将深入探讨标准容器的特性和用途,迭代器的类型与操作,以及容器适配器和关联容器的效率分析。
## 3.1 标准容器概览
### 3.1.1 常见容器的特性和用途
C++标准模板库(STL)提供了丰富的容器类型,使得程序设计更为高效和方便。最常用的容器有:
- **vector**:动态数组,可以快速地在尾部插入或删除元素,随机访问元素速度快。
- **list**:双向链表,元素插入或删除操作效率高,但随机访问速度慢。
- **deque**(双端队列):支持首尾两端的插入和删除操作,是vector和list的折中选择。
- **set/multiset**:基于红黑树实现,可以快速进行元素查找、插入和删除。
- **map/multimap**:以键值对的形式存储数据,提供了高效的数据查找和排序功能。
- **unordered_map/unordered_multimap**:基于哈希表实现,提供了平均常数时间复杂度的查找性能。
### 3.1.2 容器的选择指南
选择合适的容器是高效编程的关键。在选择容器时,应考虑以下因素:
- **元素的访问速度**:如果需要频繁随机访问元素,则vector或deque可能是更好的选择。
- **元素的插入和删除操作**:若操作主要集中在容器的前端或后端,则考虑使用deque或list。
- **元素的唯一性**:如果数据中不允许有重复的元素,set或map会是不错的选择。
- **内存占用和性能**:对于空间和性能有严格要求的场景,可以考虑使用unordered_set或unordered_map。
## 3.2 迭代器的深入理解
### 3.2.1 迭代器类型和操作
迭代器是用于遍历容器中元素的指针。常见的迭代器类型包括:
- **input iterator**:单遍输入迭代器,用于单向遍历容器中的数据。
- **output iterator**:单遍输出迭代器,用于单向输出数据。
- **forward iterator**:正向迭代器,可以进行多次遍历,并可向前移动。
- **bidirectional iterator**:双向迭代器,可以向前和向后移动。
- **random access iterator**:随机访问迭代器,提供对容器内元素的快速随机访问。
迭代器的操作通常包括:
- **解引用操作**:使用`*`操作符获取迭代器指向的元素。
- **成员访问操作**:使用`->`操作符访问迭代器指向对象的成员。
- **比较操作**:迭代器之间的`==`、`!=`、`<`、`>`、`<=`和`>=`比较。
- **算术操作**:对随机访问迭代器可以进行`+`、`-`等算术运算,用于移动指针位置。
### 3.2.2 迭代器失效和相关问题
在某些情况下,迭代器可能会失效,导致程序出现运行时错误。常见的迭代器失效情形包括:
- 在使用vector和deque时,当容器的内存重新分配后,原有的迭代器可能失效。
- 在使用list时,当元素被删除后,指向该元素的迭代器失效。
- 在使用map和set时,当元素被删除或容器被清空后,所有迭代器都会失效。
为了防止迭代器失效导致的错误,可以在操作前对迭代器进行检查,或者使用`erase()`方法返回新的有效迭代器。
## 3.3 容器适配器与关联容器
### 3.3.1 栈、队列和优先队列的使用
容器适配器是一种封装了特定数据结构的容器,提供了更为专一的操作接口。C++标准库中常见的容器适配器有:
- **stack**:后进先出(LIFO)的栈容器适配器。常用的接口包括`push()`、`pop()`、`top()`等。
- **queue**:先进先出(FIFO)的队列容器适配器。常用的接口包括`front()`、`back()`、`push()`、`pop()`等。
- **priority_queue**:具有优先级的队列,最高优先级的元素始终位于队列的前端。常用的接口包括`top()`、`push()`、`pop()`、`empty()`等。
### 3.3.2 二叉搜索树和哈希表的效率分析
关联容器提供了元素的快速查找和有序存储。最典型的关联容器包括基于二叉搜索树的set/multiset和map/multimap,以及基于哈希表的unordered_set/unordered_multiset和unordered_map/unordered_multimap。
- **二叉搜索树**:在最佳情况下,操作的时间复杂度为O(log n),适用于有序元素的快速查找。
- **哈希表**:哈希函数可以将元素映射到容器中,实现平均常数时间复杂度的查找性能。
下面是一个简单的二叉搜索树的实现代码示例,用于理解其结构和操作:
```cpp
#include <iostream>
#include <algorithm>
#include <vector>
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
};
class BST {
public:
BST() : root(nullptr) {}
void insert(int val) {
root = insertIntoBST(root, val);
}
TreeNode* search(int val) {
return searchBST(root, val);
}
private:
TreeNode *root;
TreeNode* insertIntoBST(TreeNode* node, int val) {
if (node == nullptr) return new TreeNode(val);
if (val < node->val)
node->left = insertIntoBST(node->left, val);
else if (val > node->val)
node->right = insertIntoBST(node->right, val);
return node;
}
TreeNode* searchBST(TreeNode* node, int val) {
if (node == nullptr || node->val == val) return node;
return (val < node->val) ? searchBST(node->left, val) : searchBST(node->right, val);
}
};
int main() {
BST bst;
bst.insert(5);
bst.insert(3);
bst.insert(7);
bst.insert(2);
bst.insert(4);
bst.insert(6);
bst.insert(8);
TreeNode* result = bst.search(4);
if (result != nullptr) {
std::cout << "Found: " << result->val << std::endl;
} else {
std::cout << "Not Found" << std::endl;
}
return 0;
}
```
请注意,上述代码段主要用来演示二叉搜索树的插入和查找操作,并未处理节点的删除和内存管理等细节问题。
在本小节的末尾,我们将总结关联容器的选择标准,并结合性能分析,提供一个实用的容器适配器和关联容器使用指南。
# 4. 算法与函数对象
## 4.1 算法库的原理与应用
### 4.1.1 算法的分类和选择
C++标准库中的算法库是算法和函数对象的集合,它提供了丰富的方法来进行数据处理。这些算法可以分为四类:非修改性序列操作(如for_each)、修改性序列操作(如transform)、排序操作(如sort)和数值算法(如accumulate)。合理地选择和应用这些算法对于编写高效、清晰的代码至关重要。
选择合适的算法通常基于数据的类型、数据结构以及对性能的要求。例如,当需要在容器中查找特定元素时,可以根据容器类型和数据组织来选择线性查找或二分查找等。理解算法的特性与限制,能够帮助开发者在不同情境中做出正确决策。
```cpp
#include <algorithm>
#include <vector>
#include <iostream>
int main() {
std::vector<int> data{3, 1, 4, 1, 5, 9, 2, 6, 5, 3};
// 使用非修改性算法 for_each 来打印容器中的每个元素
std::for_each(data.begin(), data.end(), [](int x){ std::cout << x << ' '; });
return 0;
}
```
上述代码使用了`std::for_each`算法遍历并打印`vector`中的每个元素。
### 4.1.2 算法复杂度分析与优化
算法复杂度分析帮助我们了解算法在不同输入大小下的性能表现,它通常以时间复杂度和空间复杂度来描述。良好的算法设计应当在满足功能需求的前提下,尽可能降低复杂度。
优化算法性能,常常意味着降低算法的时间复杂度或者减少空间消耗。例如,对于排序操作,如果数据量非常大,应考虑使用`std::sort`替代`std::stable_sort`,因为`std::sort`通常具有更好的平均时间复杂度。此外,针对特定问题,还可以通过自定义比较函数来优化算法的执行效率。
## 4.2 函数对象与Lambda表达式
### 4.2.1 函数对象的创建与使用
函数对象是重载了`operator()`的类实例。在C++中,函数对象不仅可以像普通函数那样被调用,还可以携带状态。这使得函数对象在某些场合比普通函数或Lambda表达式更具灵活性。
创建函数对象时,通常会定义一个类并在其中实现`operator()`。这种对象可以用于算法,作为参数传递给其他函数。函数对象的一个常见用例是在排序算法中提供自定义的比较逻辑。
```cpp
#include <algorithm>
#include <vector>
struct Compare {
bool operator()(const int& a, const int& b) const {
return a < b; // 返回 true 当 a 小于 b
}
};
int main() {
std::vector<int> data{3, 1, 4, 1, 5, 9, 2, 6, 5, 3};
// 使用函数对象作为排序操作的比较器
std::sort(data.begin(), data.end(), Compare());
return 0;
}
```
在这个例子中,我们创建了一个函数对象`Compare`,它被用来对一个整数`vector`进行升序排序。
### 4.2.2 Lambda表达式的优势与用法
Lambda表达式在C++11中引入,提供了一种创建匿名函数对象的便捷方式。Lambda表达式非常适合用在需要小段代码块的场合,例如排序操作中自定义比较函数或在算法中传递行为参数。
Lambda表达式的基本语法是`[capture](parameters) -> return_type { body }`。捕获列表决定了Lambda能否访问其定义时的外部变量,参数列表和返回类型与普通函数类似。
```cpp
#include <algorithm>
#include <vector>
int main() {
std::vector<int> data{3, 1, 4, 1, 5, 9, 2, 6, 5, 3};
// 使用Lambda表达式来对数据进行降序排序
std::sort(data.begin(), data.end(), [](int a, int b){ return a > b; });
return 0;
}
```
在这个代码块中,我们使用了一个简单的Lambda表达式来对整数`vector`进行降序排序。
## 4.3 高级算法技巧
### 4.3.1 算法的自定义与扩展
C++标准库的算法非常强大,但在实际应用中,我们可能需要对它们进行自定义或扩展以适应特殊需求。自定义算法通常意味着结合已有的标准库算法,并根据具体问题提供特定的实现细节。
扩展算法可以是通过模板函数来改变算法的行为,或者是通过组合算法来解决更复杂的问题。理解标准算法的工作原理和实现方式是进行自定义和扩展的基础。
```cpp
template<typename Iterator, typename Predicate>
Iterator custom_find_if(Iterator first, Iterator last, Predicate p) {
for (; first != last; ++first) {
if (p(*first)) {
return first;
}
}
return last;
}
```
以上是一个简单的自定义算法示例,它通过模板参数提供了查找满足条件的元素的功能。
### 4.3.2 算法组合与复杂数据处理
组合算法是指将两个或多个算法结合起来,以解决更复杂的逻辑。这种技术在处理复杂数据结构时尤为有用,例如在一个图数据结构上进行遍历和搜索。
在进行算法组合时,重要的是要理解每个算法的内部机制,并清晰地定义它们如何协同工作。这需要对算法库有深入的理解和丰富的实践经验。
```cpp
#include <vector>
#include <algorithm>
#include <iostream>
int main() {
std::vector<int> data{3, 1, 4, 1, 5, 9, 2, 6, 5, 3};
// 组合算法:先排序再去重
std::sort(data.begin(), data.end());
auto last = std::unique(data.begin(), data.end());
data.erase(last, data.end());
for (auto elem : data) {
std::cout << elem << ' ';
}
return 0;
}
```
在这个示例中,我们首先对数据进行排序,然后使用`std::unique`来移除连续重复的元素,最后删除了被移除元素后的剩余部分。
通过组合不同的算法,我们能够更高效地解决问题,并编写出既紧凑又强大的代码。这展现了算法与函数对象在实际应用中的灵活性与力量。
# 5. 内存管理与智能指针
C++语言为开发者提供了强大的内存管理功能,以及智能指针等资源管理工具,这有助于我们更好地控制内存使用,防止内存泄漏等常见错误。本章将深入探讨C++内存模型,智能指针的使用,以及如何实现自定义内存管理器。
## 5.1 C++内存模型
### 5.1.1 内存分配与释放
在C++中,内存管理是通过运算符 `new` 和 `delete` 来进行的。例如:
```cpp
int* p = new int(10); // 动态分配内存
delete p; // 释放内存
```
这种方法能够提供精确的内存控制,但也带来了潜在的内存泄漏问题,尤其是当 `delete` 被忘记调用时。为了简化内存管理,C++11引入了智能指针,它们能够自动释放内存。
### 5.1.2 内存泄漏的预防和检测
内存泄漏是C++开发中最常见的问题之一。预防内存泄漏的方法包括:
- 使用智能指针如 `std::unique_ptr` 和 `std::shared_ptr`。
- 实现RAII(Resource Acquisition Is Initialization)模式,通过构造函数获取资源,在析构函数中释放资源。
检测内存泄漏可以使用一些工具,如 `valgrind`、`AddressSanitizer` 等。
## 5.2 智能指针的应用
### 5.2.1 unique_ptr、shared_ptr和weak_ptr的比较
智能指针是C++11标准库提供的,用于自动管理内存的模板类。`std::unique_ptr` 是一个独占所有权的智能指针,不能被复制但可以被移动。`std::shared_ptr` 允许多个指针共享同一对象的所有权,对象会在最后一个 `shared_ptr` 被销毁时自动释放。`std::weak_ptr` 是一个不拥有对象的智能指针,它是为了打破 `shared_ptr` 的循环引用而设计的。
示例代码:
```cpp
std::unique_ptr<int> unique_int = std::make_unique<int>(10);
std::shared_ptr<int> shared_int = std::make_shared<int>(10);
std::weak_ptr<int> weak_int = shared_int;
```
### 5.2.2 智能指针在资源管理中的实践
智能指针在资源管理中非常实用,它们确保了当智能指针超出作用域时,内存能够被自动释放。例如,当一个函数返回一个对象时,使用 `std::unique_ptr` 可以保证资源不会泄漏:
```cpp
std::unique_ptr<Foo> create_foo() {
std::unique_ptr<Foo> foo = std::make_unique<Foo>();
// ... 初始化foo
return foo; // foo的生命周期被自动管理
}
```
## 5.3 自定义内存管理器
### 5.3.1 内存池的设计与实现
内存池是一种预先分配一块较大的内存块,然后根据需要从中分配小块内存的技术。这样可以减少内存分配的次数,提高性能。内存池的一个基本实现可以是:
```cpp
class MemoryPool {
private:
char* pool;
std::size_t poolSize;
std::size_t allocationsSize;
std::size_t allocationCount;
public:
MemoryPool(std::size_t size) : poolSize(size) {
pool = new char[size];
allocationsSize = 0;
allocationCount = 0;
}
void* allocate(std::size_t size) {
if (allocationsSize + size > poolSize) {
throw std::bad_alloc();
}
void* ret = pool + allocationsSize;
allocationsSize += size;
allocationCount++;
return ret;
}
~MemoryPool() {
delete[] pool;
}
};
```
### 5.3.2 内存分配器的自定义与优化
在C++中,我们可以自定义内存分配器,通过继承 `std::allocator` 并重载分配和释放内存的函数。自定义分配器可以在特定的硬件平台或应用程序中进行优化,以提高性能。
示例代码:
```cpp
template<typename T>
class MyAllocator : public std::allocator<T> {
public:
T* allocate(std::size_t num, const void* hint = 0) {
// 自定义分配逻辑
return std::allocator<T>::allocate(num, hint);
}
void deallocate(T* ptr, std::size_t num) {
// 自定义释放逻辑
std::allocator<T>::deallocate(ptr, num);
}
};
```
总结,内存管理是C++编程中的核心部分,智能指针的引入以及自定义内存管理器的实现,都大大增强了程序的稳定性和效率。通过本章的介绍,我们可以了解到C++内存管理的高级使用方法和优化技巧。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
C++标准库专栏深入解析了C++编程语言的强大功能,涵盖了从基础到高级的20个关键技巧。它从Hello World程序开始,逐步介绍了输入输出流、STL容器、函数对象、算法、迭代器、异常处理、字符串处理、正则表达式、并发编程、文件系统、内存管理、国际化、信号处理、环境控制、数学函数和随机数生成等主题。通过这些技巧,开发者可以提升代码效率、灵活性、可维护性和可移植性,从而构建出健壮且高效的C++应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
西门子V20变频器安装到调试:工业企业必备的5步骤指南

# 摘要
本文详细介绍了西门子V20变频器的基础知识、安装流程、参数配置、调试步骤以及维护与故障排除的方法。首先,概述了变频器的基本概念及其在工业自动化中的重要性。接着,系统地阐述了变频器的安装前准备、实际安装过程、以及安装后的检查与测试方法。文章还深入讲解了参数配置的原理、实践操作和验证优化过程,以及调试过程中可能遇到的问题和故障诊断技巧。最后,讨论了变频器
【PID调节技术深度剖析】:从理论到实战的完整指南

# 摘要
本文全面概述了PID调节技术的理论基础、实践应用以及高级优化策略。首先,介绍了PID控制器的工作原理和误差信号的处理机制。随后,深入分析了PID参数对系统性能的影响,并提供了参数调整的实验方法和案例。文章还探讨了PID控制器的稳定性问题,包括稳定性分析的数学模型和图形方法。在实践应用部分,本文详细论述了PID技术在工业控制、软件系统和自动化系统中的应用实例。最后
【文献管理大师课】:EndNote X7高级定制技巧全解析
# 摘要
本文旨在全面介绍EndNote X7软件的核心功能和高级应用,涵盖文献管理、格式化引用、协同合作和未来发展趋势。第一章概述了EndNote X7的基本使用和个性化设置方法。第二章深入探讨了高级文献导入与管理技巧,包括文献数据处理、分类系统建立和检索技术提升。第三章详细说明了引用样式的定制与管理,以及如何在不同文档格式中应用这些引用。第四章着重介绍了高级搜索功能和与其他研究工具的集成,以及如何实现高效文献共享和协作。最后一章预测了EndNote
【SCSI技术革新】:如何在现代存储系统中应用SPC-4提升性能

# 摘要
本文系统性地介绍了SCSI技术及其在现代存储系统中的应用,并深入阐述了SPC-4协议的原理、特性、性能指标、兼容性问题以及在存储系统中的实际应用实践。通过分析SPC-4环境的配置和部署步骤,性能优化技巧,以及灾难恢复与数据完整性的保证措施,本文为读者提供了全面的SPC-4实施指南。此外,本文探讨了SPC-4技术与新兴技术的融合前景,行业标准的更新挑战,并通过案例研究,展望了SPC-
【时序逻辑基石】:扭环形计数器设计原理及应用案例(进阶技术全解读)
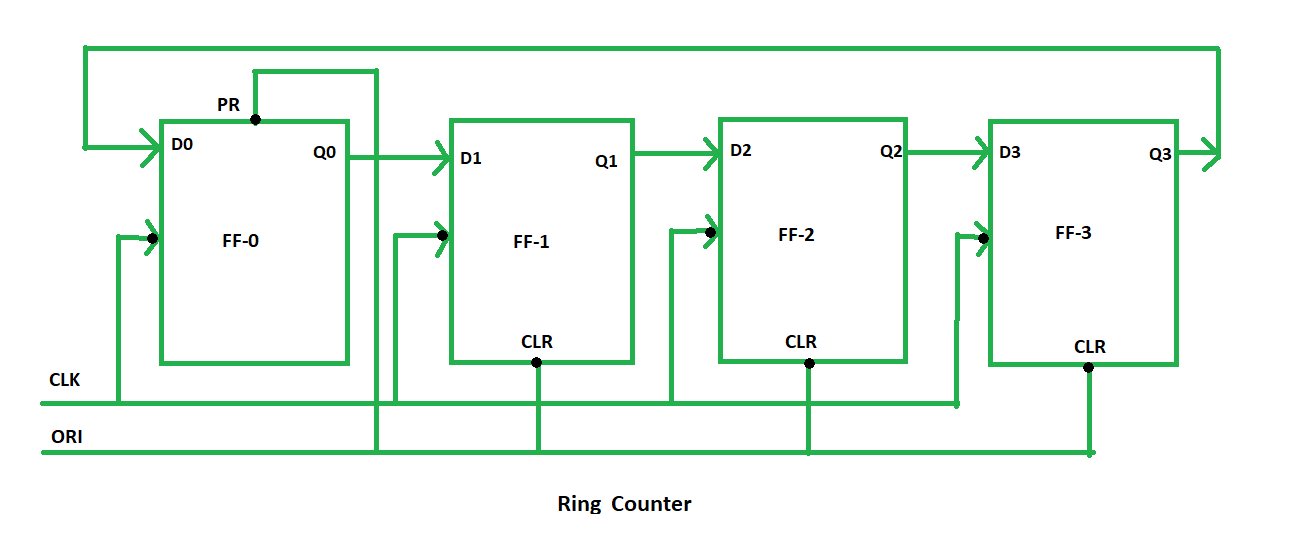
# 摘要
本文系统地介绍了扭环形计数器的设计原理、理论基础、设计实践、应用案例以及面临的未来趋势与挑战。文章首先概述了扭环形计数器的设计原理,随后深入探讨了其理论基础,包括数字电路与计数器的分类、环形计数器的工作机制以及扭环形计数器的设计要点。在此基础上,文中进一步阐释了扭环形计数器的设计过程、仿真测试和硬件实现,同时提供了工业自动化、数字通信系统以及特定领域应用的案例分析。最后,文章展望了扭环形
PUMA560轨迹规划艺术(5):精准高效操作的秘密
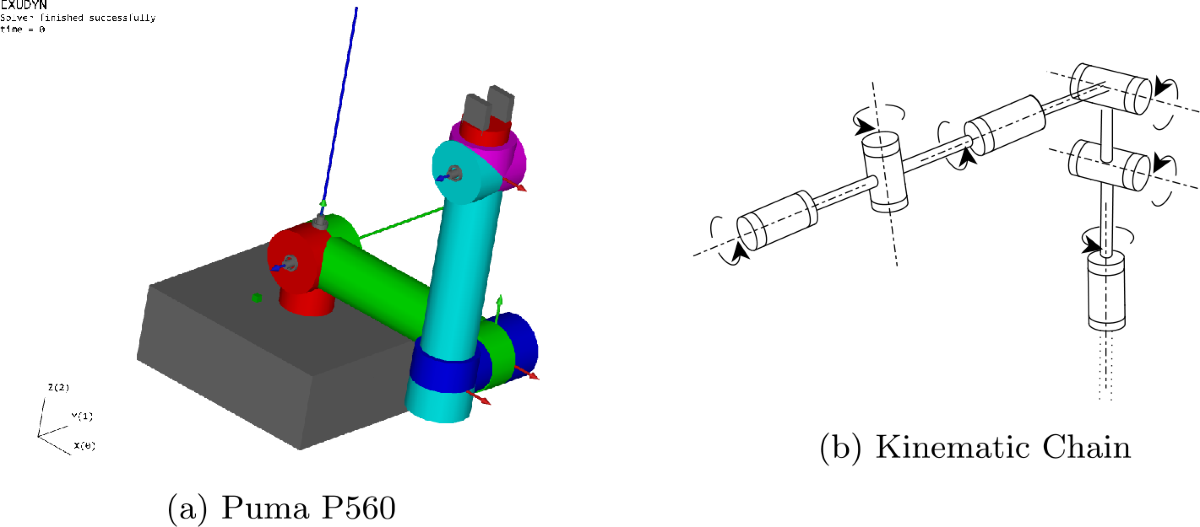
# 摘要
本论文对PUMA560机械臂的轨迹规划进行了全面的研究与分析。首先概述了机械臂的基本情况,随后介绍了轨迹规划的基础理论,包括机械臂运动学原理、轨迹规划的数学模型以及关键性能指标。论文详细探讨了离线和实时轨迹规划算法的设计与实现,并对轨迹优化技术及其应用进行了深入分析
揭秘FAE技术:GC0328手册中的性能提升秘诀及案例研究
# 摘要
FAE技术作为行业的重要组成部分,其性能优化对提升系统效率和稳定性具有关键作用。本文以GC0328为例,首先介绍了性能优化的基础概念、硬件特性及其对性能的影响,接着深入探讨了性能调优策略和监控分析技术。第二部分着重于GC0328在软件优化和硬件配置方面的性能提升实践案例。进一步,文章分析了GC0328的高级技术,包括并行处理、内存管理优化以及高级调试技术。最后,
【数据模型与性能优化】:住院管理数据库的高级架构设计

# 摘要
本文首先概述了住院管理数据库的基本概念与重要性,随后深入探讨了数据模型设计原理,涵盖了理论基础如实体关系模型和数据库规范化理论,同时介绍了高级数据模型技术如对象关系模型和多维数据模型,并探讨了设计实践中的实体识别与属性划分等关键步骤。性能优化的基本策略部
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )