二叉树遍历算法全攻略:掌握前中后序的奥秘
发布时间: 2025-01-06 00:07:57 阅读量: 9 订阅数: 15 

matlab实现二叉树遍历算法(源代码)

# 摘要
本文系统地综述了二叉树遍历算法,包括基本概念、理论基础、实现方法及优化策略。首先介绍了二叉树的定义、性质和存储结构,进而探讨了前序、中序、后序遍历的分类、特性和递归模型。文中详细阐述了各遍历算法的代码实现,并通过案例分析展示了它们在树构建、二叉搜索树应用、树删除等实际场景中的应用。此外,本文还探讨了遍历算法的优化方法,如Morris算法、尾递归优化以及层序遍历等高级技巧,并结合实际案例,讨论了二叉树遍历在解决问题、面试和算法竞赛中的应用。本文旨在为读者提供全面、深入的二叉树遍历算法理解,并指导其在实际编程中的正确应用和优化。
# 关键字
二叉树遍历;递归算法;非递归实现;Morris算法;空间优化;实际应用案例
参考资源链接:[数据结构与算法学习指南:刘斌教授讲解](https://wenku.csdn.net/doc/55y4kz8bct?spm=1055.2635.3001.10343)
# 1. 二叉树遍历算法概述
二叉树作为数据结构的重要组成部分,其遍历算法在计算机科学领域中占据着举足轻重的位置。本章将为读者提供一个二叉树遍历算法的整体概览,并将引出后续章节中关于理论基础、实践应用、优化策略和实际案例等更深层次的探讨。
## 1.1 遍历算法的重要性
二叉树遍历算法是递归与迭代的经典应用案例,它不仅是理解树结构和算法的基石,而且也是许多高级数据结构和算法的先决条件。掌握这些算法对于解决更复杂的编程挑战至关重要。
## 1.2 常见的遍历方法
二叉树遍历主要有三种方式:前序遍历、中序遍历和后序遍历。每种遍历方法都反映了树中节点访问的不同顺序,这直接关系到算法的输出结果。更深入地理解这些遍历方法,将有助于我们对树形数据结构的操作和分析。
## 1.3 本章结构
本章将概括二叉树遍历算法的基本概念和应用场景,为读者构建一个坚实的基础,以便在接下来的章节中更加深入地探索和应用这些核心算法。
二叉树遍历算法不仅在数据结构的学习中占有重要地位,同时也是IT行业中后端开发、系统设计以及算法竞赛等方面不可或缺的一部分。因此,本章内容将帮助读者建立起二叉树遍历的基础知识框架,为掌握和运用更复杂的树遍历技巧打下坚实的基础。
# 2. 理论基础与算法推演
## 2.1 二叉树的基本概念
### 2.1.1 二叉树的定义和性质
二叉树是每个节点最多有两个子树的树结构,通常子树被称作“左子树”和“右子树”。在计算机科学中,二叉树被广泛用于搜索和排序算法中。
- **性质一**:在二叉树的第 i 层上最多有 2^(i-1) 个节点(i >= 1)。
- **性质二**:深度为 k 的二叉树最多有 2^k - 1 个节点(k >= 1)。
- **性质三**:对于任何非空二叉树,若叶节点的数目为 n0,度为 2 的节点数目为 n2,则 n0 = n2 + 1。
二叉树的这些基本性质是设计和优化二叉树遍历算法的基础。
### 2.1.2 二叉树的存储结构
为了在计算机中存储二叉树,有几种常见的存储方式:
- **顺序存储结构**:使用数组存储二叉树的节点,适合完全二叉树或满二叉树。
- **链式存储结构**:使用节点指针表示树的父子关系,适合任何二叉树。
在算法实现中,链式存储因为其灵活性而被更多使用。
## 2.2 遍历算法的理论基础
### 2.2.1 遍历算法的分类和特性
遍历二叉树的过程可以分为三种基本方式:
- **前序遍历**:根节点 -> 左子树 -> 右子树
- **中序遍历**:左子树 -> 根节点 -> 右子树
- **后序遍历**:左子树 -> 右子树 -> 根节点
每种遍历方式都反映了对二叉树节点访问的不同顺序,从而可以实现不同的算法功能,例如中序遍历可以得到二叉搜索树的排序输出。
### 2.2.2 递归遍历的理论模型
递归遍历是通过函数自身调用自身来简化问题的一种技术。其基本模型可以表示为:
```plaintext
void traverse(Node node) {
if (node == null) return;
visit(node);
traverse(node.left);
traverse(node.right);
}
```
递归模型简单易懂,但也有局限性,比如可能会导致栈溢出等。
## 2.3 算法推演与伪代码实现
### 2.3.1 前序遍历的原理和步骤
前序遍历的核心在于“先访问根节点”,然后对左子树和右子树进行同样的操作。伪代码如下:
```plaintext
void preorderTraversal(Node node) {
if (node == null) return;
visit(node);
preorderTraversal(node.left);
preorderTraversal(node.right);
}
```
### 2.3.2 中序遍历的原理和步骤
中序遍历的顺序是“先访问左子树,然后是根节点,最后是右子树”。伪代码如下:
```plaintext
void inorderTraversal(Node node) {
if (node == null) return;
inorderTraversal(node.left);
visit(node);
inorderTraversal(node.right);
}
```
### 2.3.3 后序遍历的原理和步骤
后序遍历按照“先访问左子树,然后是右子树,最后是根节点”的顺序进行。伪代码如下:
```plaintext
void postorderTraversal(Node node) {
if (node == null) return;
postorderTraversal(node.left);
postorderTraversal(node.right);
visit(node);
}
```
在每种遍历方式中,`visit(node)`代表访问节点的操作,它可以打印节点值、累加节点值等。
二叉树的遍历是数据结构中的基础算法,掌握了遍历算法,就为解决更复杂的树形结构问题打下了坚实的基础。
# 3. 前序、中序、后序遍历的实践应用
在深入理解了二叉树遍历算法的理论基础之后,本章节我们将探讨前序、中序、后序遍历在实际应用中的实现和案例分析。这些遍历方法在处理树形结构数据时具有重要的作用,理解并掌握它们的实现,将有助于我们解决许多实际问题。
## 3.1 前序遍历的代码实现与案例分析
### 3.1.1 栈实现的非递归前序遍历
前序遍历是二叉树遍历中最为直观的一种方式,其过程为:访问根节点 -> 遍历左子树 -> 遍历右子树。在非递归的实现中,我们通常借助栈结构来实现深度优先遍历。
```python
def preorder_traversal(root):
stack, output = [root, ], []
while stack:
node = stack.pop()
if node is not None:
output.append(node.val)
# 注意栈是后进先出,先压入右子节点再压入左子节点
if node.right:
stack.append(node.right)
if node.left:
stack.append(node.left)
return output
```
逻辑分析:
1. 创建一个栈用于存储遍历过程中的节点,同时创建一个列表用于存储遍历结果。
2. 将根节点压入栈中。
3. 当栈不为空时,循环执行以下操作:
- 弹出栈顶元素并将其值添加到输出列表中。
- 因为栈的后进先出特性,我们先将右子节点压栈,再将左子节点压栈,这样可以保证先遍历左子树,再遍历右子树。
### 3.1.2 前序遍历的树构建应用
前序遍历的输出结果可以用来构建一棵二叉树,这一点在解析一些表达式或文件结构时尤其有用。通过前序遍历的输出我们可以知道根节点在哪里,左子树的节点是哪些,右子树的节点是哪些,从而递归地构建出原始的二叉树结构。
```python
def construct_tree(preorder, inorder):
if not preorder or not inorder:
return None
# 前序遍历的第一个值是根节点
root_value = preorder[0]
root = TreeNode(root_value)
# 在中序遍历中找到根节点的位置
mid_idx = inorder.index(root_value)
# 递归构建左子树和右子树
root.left = construct_tree(preorder[1:mid_idx+1], inorder[:mid_idx])
root.right = construct_tree(preorder[mid_idx+1:], inorder[mid_idx+1:])
return root
```
逻辑分析:
1. 如果前序或中序遍历序列为空,则返回None,表示没有节点可以构建。
2. 根据前序遍历的第一个元素确定根节点。
3. 在中序遍历中找到根节点的位置,这将中序遍历序列分为左子树和右子树。
4. 递归构建左子树和右子树。
5. 返回构建好的根节点。
## 3.2 中序遍历的代码实现与案例分析
### 3.2.1 中序遍历的二叉搜索树应用
中序遍历二叉搜索树时,由于二叉搜索树的性质(左子树节点值 < 根节点值 < 右子树节点值),输出的遍历结果是有序的。这种遍历方式在处理二叉搜索树时尤其有用,例如在二分查找中。
```python
def inorder_traversal(root):
return inorder_traversal(root.left) + [root.val] + inorder_traversal(root.right) if root else []
```
逻辑分析:
1. 对于空节点,直接返回空列表。
2. 对于非空节点,递归地进行左子树的中序遍历,将结果列表与根节点值连接,再递归进行右子树的中序遍历,并将结果列表连接。
### 3.2.2 利用中序遍历解决实际问题
中序遍历不仅可以用来获取有序的值序列,还可以用来检查二

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“数据结构课件”专栏深入浅出地讲解了数据结构和算法的基本概念和应用技巧。它包含了从入门到进阶的全面内容,包括数组、链表、堆栈、二叉树、红黑树和图论。专栏通过详尽的解释、生动的示例和清晰的图表,帮助读者掌握数据结构的原理和算法的实现。无论是编程新手还是经验丰富的开发者,都可以从这个专栏中受益匪浅,提升自己的编程能力和算法思维。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【KepServerEX V6高级定制】:创建个性化的OPC UA数据交换方案
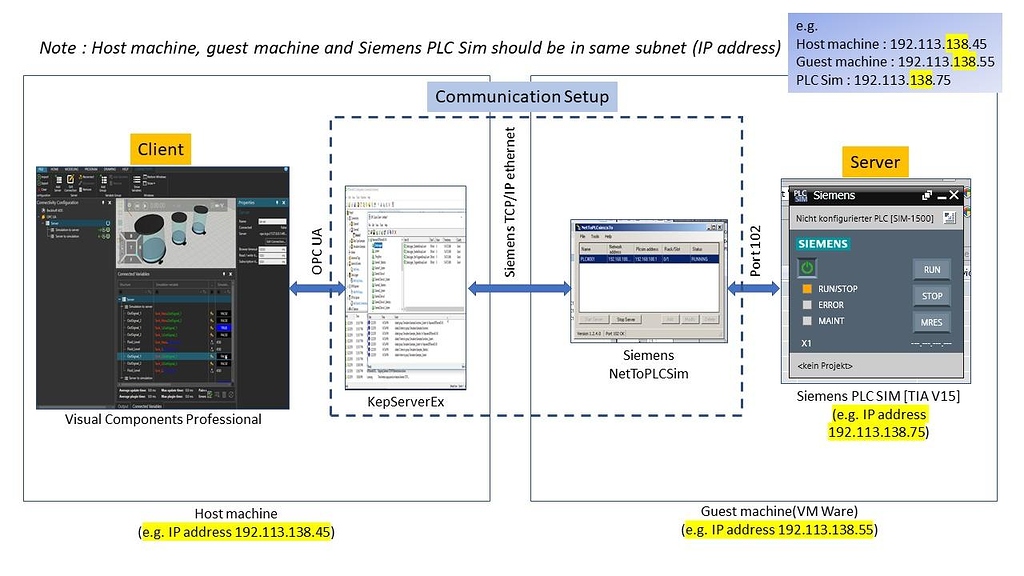
# 摘要
本论文详细介绍了KepServerEX V6的概览与架构,并深入探讨了其对OPC UA(统一架构)标准的支持和定制化配置。章节内容涵盖了OPC UA的基础知识、定制化需求分析、OPC UA服务器配置实践以及客户端开发。同时,论文也提供了性能调优与故障排除
同步间隔段深度解码:STM32F103RCT6开发板性能与稳定性的秘密

# 摘要
本文旨在深入探讨STM32F103RCT6开发板的性能特点、稳定性提升策略以及实际应用案例。首先对STM32F103RCT6开发板进行概述,随后详尽解析其核心性能,包括Cortex-M3内核架构、内存和存储技术、时钟系统和电源管理等方面。文章接着针对提升STM32F103RCT6的稳定性提供了硬件和软件方面的设计策略,并阐述了RTOS在该平台上的应用和优化。通过性能与稳定性测
温度对半导体器件的影响:跨导gm依赖性的挑战与应对

# 摘要
本文探讨了温度如何影响半导体器件的性能,特别是对跨导gm的作用。首先介绍了跨导gm的基本理论及其在半导体器件中的作用,随后分析了温度对跨导gm的影响,并提出了温度依赖性原理。本文还讨论了温度波动和极端温度条件对器件稳定性和寿命的影响,以及高温和低温环境下半导体器件面临的实践挑战。最后,文章探讨了应对温度影响的设计与优化策略,包括材料选择、温度补偿技术以及热模拟与仿真技术的应用,并展
西门子PID指令新手指南:从零开始的基础教程

# 摘要
西门子PLC与PID控制在工业自动化领域拥有广泛的应用,本文首先概述了西门子PLC和PID控制的基本概念,接着深入探讨了PID控制的理论基础,包括其原理、参数的物理意义以及不同控制模式。文章详细介绍了西门子PLC中PID指令的结构、功能以及应用场景,并讨论了其高级功能,例如自适应PID控制和PID参数的自动调整。通过对实现PID控制的步骤、常见问题解决以及系统的优化进行分析,本文展现了如何在实践中应用
【编码器数据解读速成课】:从ST段SSI到高阶应用的精进之路
# 摘要
编码器作为一种精确测量位置和速度的传感器,在多个行业中都有广泛应用。本文首先介绍了编码器的基础知识和SSI协议的概述,然后深入探讨了编码器数据解读的理论基础,包括数据类型与结构、数据同步与时序分析、以及数学基础如信号处理和傅里叶变换的应用。在SSI编码器数据解读与实践章节,详细介绍了SSI信号的解码处理、实时数据采集分析及实际
【USB 3.0连接器的机械强度测试】:保障连接稳定性

# 摘要
USB 3.0连接器作为现代电子设备中广泛应用的数据传输接口,其理论基础、设计要求、测试方法及强度测试案例是确保连接器性能的关键。本文概述了USB 3.0连接器的基础知识,深入分析了其技术标准、机械强度的重要性,以及设计要求。此外,本文详细介绍了USB 3.0连接器的实验室测试流程和现场测试方法,包括测试设备的使用和数据记录分析。通过强度测试案例分析,本文展
【Kepware性能监控宝典】:实时监控DL645设备状态的技巧
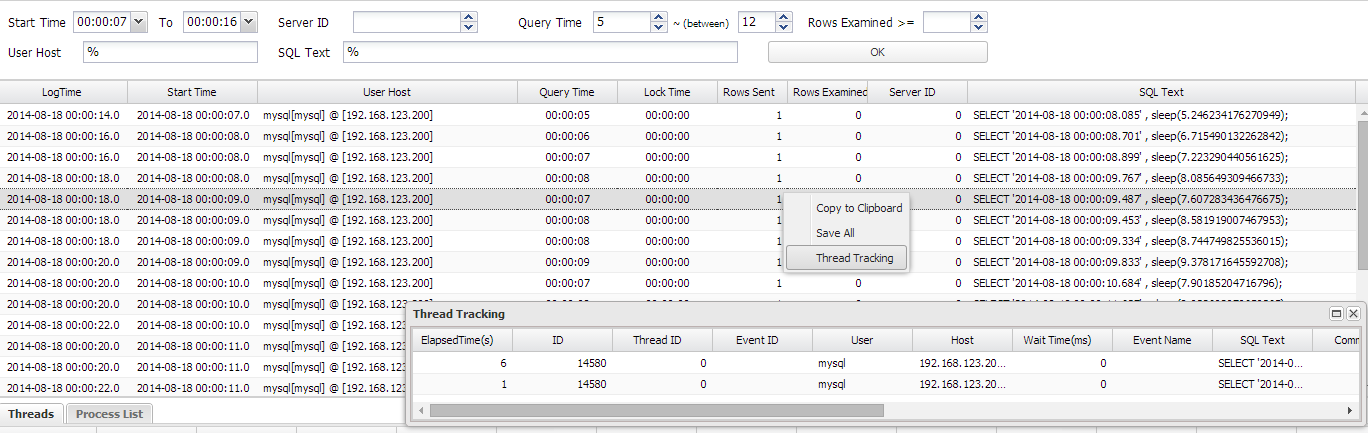
# 摘要
本文详细介绍了Kepware技术和DL645设备的集成与监控方法。首先概述了Kepware技术及DL645设备的特点和要求。其次,系统阐述了Kepware监控系统的安装过程、配置文件的管理以及与DL645设备的集成通信设置。随后,文章深入探讨了实时监控DL645设备状态的策略,包括监控参数选择、数据采集、分析工具以及报警通知机制的建立。接着,本文论述了监控数据的可视化展示和报告生成的策略,着重介
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )