Dijkstra算法精讲:单源最短路径问题的高效解决
发布时间: 2025-01-06 01:20:51 阅读量: 11 订阅数: 15 

Dijkstra算法:单源最短路径的终极解答

# 摘要
本文全面综述了Dijkstra算法的原理、实现、应用以及改进方向。首先,文章介绍了Dijkstra算法在图论中的基础理论,阐述了算法的原理和与其他最短路径算法的比较。随后,深入探讨了算法实现中的数据结构选择、代码实现和常见问题解决策略。文章接着展示了Dijkstra算法在不同领域,如网络路由、地理信息系统和社交网络中的具体应用实例。最后,针对未来发展趋势,讨论了图计算框架的进步、理论扩展和对现代科技的长远影响。
# 关键字
Dijkstra算法;图论;最短路径;算法实现;应用实例;算法优化
参考资源链接:[数据结构与算法学习指南:刘斌教授讲解](https://wenku.csdn.net/doc/55y4kz8bct?spm=1055.2635.3001.10343)
# 1. Dijkstra算法概述
## 1.1 算法的历史与发展
Dijkstra算法是图论中用于寻找最短路径的经典算法之一。由荷兰计算机科学家艾兹赫尔·戴克斯特拉于1956年提出,最初用于解决荷兰的街道和道路网络中的最短路径问题。随着时间推移,这一算法因其简单和有效性被广泛应用于计算机科学和运筹学领域。
## 1.2 算法的重要性和应用领域
Dijkstra算法的重要性在于它的通用性和效率。其不仅能够处理城市交通网络中的路线规划,还能应用于计算机网络中的路由选择、社交网络分析、供应链优化等多个领域。该算法的核心价值在于能够在加权图中找到两点之间的最短路径,为复杂问题的解决提供了一个有效的工具。
## 1.3 算法的局限性
虽然Dijkstra算法非常实用,但它也有局限性,特别是在处理大规模网络数据和带时间约束的路径规划时,计算效率可能成为瓶颈。此外,该算法不适用于带有负权重边的图,这就限制了它在某些特定场景下的使用。接下来的章节将深入探讨图论基础和Dijkstra算法的理论,帮助读者更好地理解该算法的工作原理和实现方式。
# 2. 图论基础与算法理论
## 2.1 图论的基本概念
### 2.1.1 图的定义与分类
图是一种由顶点(节点)和边组成的数据结构,它用于建模两个对象之间的关系。在图论中,图可以是无向的(边没有方向),也可以是有向的(边有明确的方向)。根据边是否带权重,图可以进一步分类为无权图和有权图。无权图的边表示两个顶点之间仅存在关系,而有权图的每条边有一个与之关联的权重,常用于表示成本、距离或其他度量。
#### 图的定义
在数学和计算机科学中,图 G 可以形式化定义为 G = (V, E),其中:
- V 是顶点的有限集。
- E 是边的有限集,边是顶点对的集合。
对于无向图,边 (u, v) 和 (v, u) 是相同的;对于有向图,它们是不同的。
#### 图的分类
- 无向图:边不带方向。例如,社交网络中的朋友关系图。
- 有向图:边带方向。例如,网页链接关系图。
- 无权图:边没有权重值。例如,城市间的道路图,不考虑距离。
- 有权图:边有对应的权重值。例如,城市间的道路图,考虑距离或时间成本。
### 2.1.2 路径和回路
在图中,路径是由边依次连接起来的顶点序列。如果路径中的所有顶点都是唯一的,则称该路径为简单路径。回路是路径的一种特殊情况,其中起点和终点是相同的顶点。
#### 路径的定义
- 简单路径:不包含重复顶点的路径。
- 回路(闭合路径):起点和终点相同的路径。
在有权图中,寻找两点间的最短路径是图论中一个经典问题,也是Dijkstra算法的应用场景之一。
### 2.1.3 权重和距离
在有权图中,顶点间通过边关联的数值称为权重,该数值可以代表距离、成本、时间等。在路径上,权重的总和称为路径的长度或距离。
- 权重:边连接两个顶点的值。
- 距离:从一个顶点到另一个顶点的路径上的权重总和。
图的分析常常围绕如何计算顶点间的最短路径进行。Dijkstra算法就是一种有效的算法,用以寻找加权图中某个顶点到其他所有顶点的最短路径。
## 2.2 Dijkstra算法的原理
### 2.2.1 算法思想
Dijkstra算法由荷兰计算机科学家Edsger Dijkstra在1956年提出,用于解决单源最短路径问题。算法的基本思想是贪心策略:每次从未处理的顶点中选取距离当前顶点最近的顶点,更新其邻居顶点的最短路径估计值,直到所有顶点的最短路径都被计算出来。
#### 贪心策略
- 从未处理的顶点集合中选取当前距离源点最近的顶点。
- 更新当前顶点的邻居顶点的最短路径估计值。
### 2.2.2 算法过程详解
Dijkstra算法可以使用优先队列(如最小堆)来优化,算法的基本步骤如下:
1. 创建源点到所有其他顶点的距离表,初始时除了源点到自己的距离为0外,其余均为无穷大。
2. 创建一个未访问顶点集合。
3. 当未访问顶点集合不为空时,执行以下步骤:
a. 从未访问集合中选取距离源点最近的顶点u。
b. 将顶点u从未访问集合中移除。
c. 更新顶点u的每一个相邻顶点v的距离:如果通过顶点u到达顶点v的距离小于当前已知的距离,则更新它。
4. 重复步骤3,直到所有顶点都被访问过。
### 2.2.3 算法复杂度分析
Dijkstra算法的时间复杂度取决于使用的数据结构。通常有两种实现方式:
- 使用数组实现的邻接矩阵:时间复杂度为O(V^2),其中V是顶点的数量。
- 使用优先队列(如最小堆)实现的邻接表:时间复杂度为O((V+E)logV),其中E是边的数量。
通常情况下,对于稠密图(边的数量与顶点的平方成正比),邻接矩阵效率较高;对于稀疏图(边的数量远小于顶点平方),优先队列的邻接表效率更高。
## 2.3 Dijkstra算法与其他最短路径算法的比较
### 2.3.1 Bellman-Ford算法
Bellman-Ford算法可以处理带有负权边的图,而Dijkstra算法不可以。Bellman-Ford算法的基本思路是逐步逼近最短路径的长度,直到达到一个稳定状态。
- 能够处理负权重边。
- 时间复杂度为O(VE),适用于稀疏图。
### 2.3.2 Floyd-Warshall算法
Floyd-Warshall算法是一种动态规划算法,用于寻找图中所有顶点对之间的最短路径。
- 适用于计算所有顶点对的最短路径。
- 时间复杂度为O(V^3),适用于小型图。
### 2.3.3 A*搜索算法
A*算法是一种启发式搜索算法,它结合了Dijkstra算法的准确性和贪心算法的快速性。它使用一个估计函数来评估从当前顶点到目标顶点的最佳路径。
- 结合了Dijkstra的准确性和贪心算法的快速性。
- 适合有明确目标位置的应用,如地图导航。
通过比较,我们可以得出Dijkstra算法适用于没有负权边的稠密图,并且当需要快速找到单源最短路径时,Dijkstra算法是首选。每种算法都有其适用场景和限制,选择合适的算法需要根据具体问题的特性来确定。
# 3. Dijkstra算法的实现细节
## 3.1 数据结构的选择与优化
### 3.1.1 邻接矩阵与邻接表
在实现Dijkstra算法时,选择合适的数据结构对于算法性能至关重要。常用的两种数据结构是邻接矩阵和邻接表。
**邻接矩阵**是一个二维数组,其行和列分别代表图中的顶点,矩阵中的元素表示顶点之间的权重。例如,如果顶点i和顶点j之间没有直接的边,则对应的矩阵元素值为无穷大。邻接矩阵的存储空间需求与顶点数的平方成正比,即O(V^2),其中V是顶点的数量。对于稠密图,这是一种直观且有效的表示方法。
**邻接表**则更适合表示稀疏图。它由顶点数组和边的链表组成,每个顶点都有一个链表来存储所有邻接的顶点及其权重。邻接表的空间复杂度与边的数量成线性关系,即O(V+E),其中E是边的数量。在处理大规模稀疏图时,邻接表能显著减少内存的使用。
### 3.1.2 优先队列的实现方式
Dijkstra算法中使用优先队列来选择当前距离最小的未访问顶点。优先队列有多种实现方式,包括数组、链表、二叉堆等。二叉堆(通常使用最小堆实现)是目前公认的效率较高的数据结构。
数组和链表实现的优先队列,在查找和删除最小元素时,时间复杂度均为O(V),而使用二叉堆,这两种操作的时间复杂度可降低到O(logV)。二叉堆是通过堆化过程,根据元素的值(在这个场景中是距离)来调整其在堆中的位置,从而保证堆顶元素始终是最小的。
## 3.2 Dijkstra算法的代码实现
### 3.2.1 单源最短路径的代码示例
在单源最短路径问题中,我们寻找从单一源点到图中所有其他顶点的最短路径。以下是一个使用Python实现的单源最短路径的代码示例:
```python
import heapq
def dijkstra(graph, start):
distances = {vertex: float('infinity') for vertex in graph}
distances[start] = 0
priority_queue = [(0, start)]
while priority_queue:
current_distance, current_vertex = heapq.heappop(priority_queue)
if current_distance > distances[current_vertex]:
continue
for neighbor, weight in graph[current_vertex].items():
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(priority_queue, (distance, neighbor))
return distances
# 示例图
graph = {
'A': {'B': 1, 'C': 4},
'B': {'A': 1,
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“数据结构课件”专栏深入浅出地讲解了数据结构和算法的基本概念和应用技巧。它包含了从入门到进阶的全面内容,包括数组、链表、堆栈、二叉树、红黑树和图论。专栏通过详尽的解释、生动的示例和清晰的图表,帮助读者掌握数据结构的原理和算法的实现。无论是编程新手还是经验丰富的开发者,都可以从这个专栏中受益匪浅,提升自己的编程能力和算法思维。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【KepServerEX V6高级定制】:创建个性化的OPC UA数据交换方案
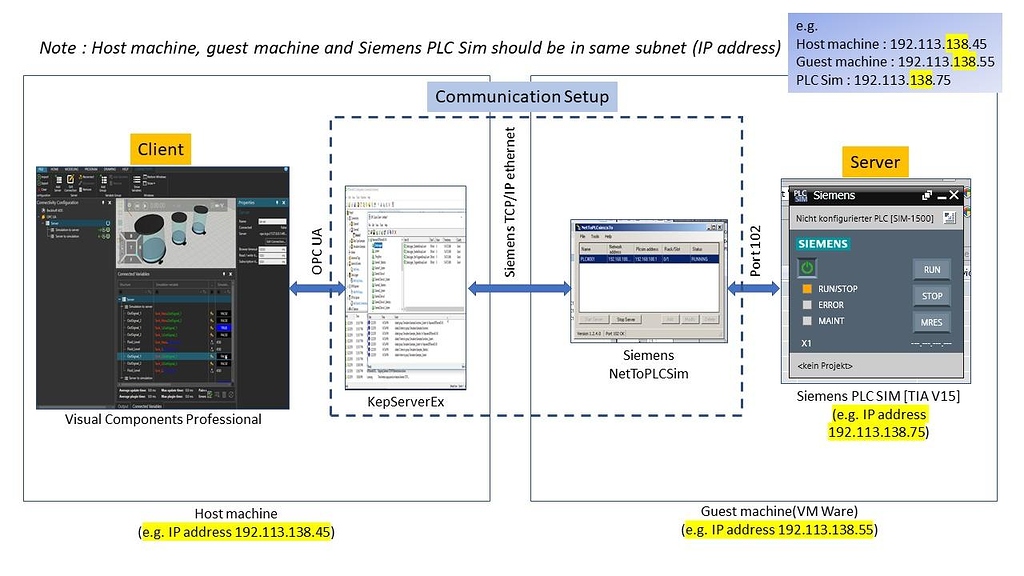
# 摘要
本论文详细介绍了KepServerEX V6的概览与架构,并深入探讨了其对OPC UA(统一架构)标准的支持和定制化配置。章节内容涵盖了OPC UA的基础知识、定制化需求分析、OPC UA服务器配置实践以及客户端开发。同时,论文也提供了性能调优与故障排除
同步间隔段深度解码:STM32F103RCT6开发板性能与稳定性的秘密

# 摘要
本文旨在深入探讨STM32F103RCT6开发板的性能特点、稳定性提升策略以及实际应用案例。首先对STM32F103RCT6开发板进行概述,随后详尽解析其核心性能,包括Cortex-M3内核架构、内存和存储技术、时钟系统和电源管理等方面。文章接着针对提升STM32F103RCT6的稳定性提供了硬件和软件方面的设计策略,并阐述了RTOS在该平台上的应用和优化。通过性能与稳定性测
温度对半导体器件的影响:跨导gm依赖性的挑战与应对

# 摘要
本文探讨了温度如何影响半导体器件的性能,特别是对跨导gm的作用。首先介绍了跨导gm的基本理论及其在半导体器件中的作用,随后分析了温度对跨导gm的影响,并提出了温度依赖性原理。本文还讨论了温度波动和极端温度条件对器件稳定性和寿命的影响,以及高温和低温环境下半导体器件面临的实践挑战。最后,文章探讨了应对温度影响的设计与优化策略,包括材料选择、温度补偿技术以及热模拟与仿真技术的应用,并展
西门子PID指令新手指南:从零开始的基础教程

# 摘要
西门子PLC与PID控制在工业自动化领域拥有广泛的应用,本文首先概述了西门子PLC和PID控制的基本概念,接着深入探讨了PID控制的理论基础,包括其原理、参数的物理意义以及不同控制模式。文章详细介绍了西门子PLC中PID指令的结构、功能以及应用场景,并讨论了其高级功能,例如自适应PID控制和PID参数的自动调整。通过对实现PID控制的步骤、常见问题解决以及系统的优化进行分析,本文展现了如何在实践中应用
【编码器数据解读速成课】:从ST段SSI到高阶应用的精进之路
# 摘要
编码器作为一种精确测量位置和速度的传感器,在多个行业中都有广泛应用。本文首先介绍了编码器的基础知识和SSI协议的概述,然后深入探讨了编码器数据解读的理论基础,包括数据类型与结构、数据同步与时序分析、以及数学基础如信号处理和傅里叶变换的应用。在SSI编码器数据解读与实践章节,详细介绍了SSI信号的解码处理、实时数据采集分析及实际
【USB 3.0连接器的机械强度测试】:保障连接稳定性

# 摘要
USB 3.0连接器作为现代电子设备中广泛应用的数据传输接口,其理论基础、设计要求、测试方法及强度测试案例是确保连接器性能的关键。本文概述了USB 3.0连接器的基础知识,深入分析了其技术标准、机械强度的重要性,以及设计要求。此外,本文详细介绍了USB 3.0连接器的实验室测试流程和现场测试方法,包括测试设备的使用和数据记录分析。通过强度测试案例分析,本文展
【Kepware性能监控宝典】:实时监控DL645设备状态的技巧
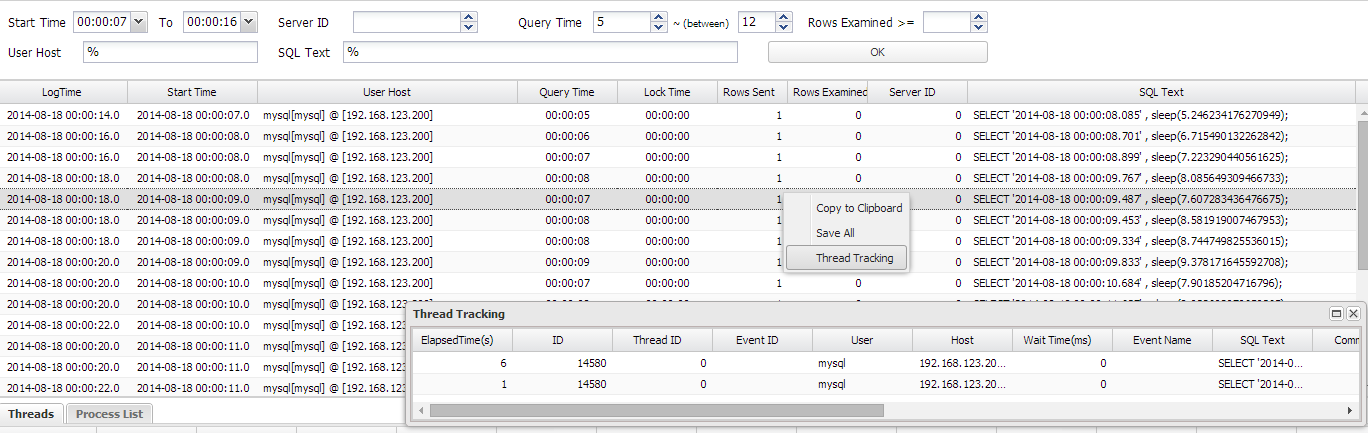
# 摘要
本文详细介绍了Kepware技术和DL645设备的集成与监控方法。首先概述了Kepware技术及DL645设备的特点和要求。其次,系统阐述了Kepware监控系统的安装过程、配置文件的管理以及与DL645设备的集成通信设置。随后,文章深入探讨了实时监控DL645设备状态的策略,包括监控参数选择、数据采集、分析工具以及报警通知机制的建立。接着,本文论述了监控数据的可视化展示和报告生成的策略,着重介
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )