基于LSA的文本相似度计算
发布时间: 2024-04-05 21:57:33 阅读量: 73 订阅数: 24 
# 1. 介绍文本相似度计算
1.1 什么是文本相似度计算
1.2 相似度计算在自然语言处理中的应用
1.3 LSA在文本相似度计算中的作用
# 2. Latent Semantic Analysis(LSA)简介
LSA(Latent Semantic Analysis)是一种用于文本挖掘和信息检索的技术,它通过对文本内容的概念进行分析和建模,帮助提取文本中的隐含语义信息。在本章节中,我们将介绍LSA的基本原理、优缺点以及在文本处理中的典型应用。
# 3. LSA在文本相似度计算中的应用
Latent Semantic Analysis (LSA) 是一种常用的文本相似度计算方法,它通过对文本数据进行降维处理,发现文档之间的语义关系,进而计算它们之间的相似度。在自然语言处理领域,LSA在文本相似度计算中发挥着重要作用。
#### 3.1 如何使用LSA计算文本之间的相似度
在使用LSA计算文本相似度之前,首先需要对文本数据进行预处理,包括清洗数据、分词和词频统计等。接着,利用LSA对文本进行特征提取,然后通过计算文档的语义向量,最终使用余弦相似度等方法计算文本之间的相似度。
```python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
from sklearn.metrics.pairwise import cosine_similarity
# 假设docs是包含多个文档的列表
docs = ['文档1内容', '文档2内容', '文档3内容']
# 使用TfidfVectorizer进行文本特征提取
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(docs)
# 使用TruncatedSVD进行LSA降维处理
lsa = TruncatedSVD(n_components=100)
lsa_matrix = lsa.fit_transform(tfidf_matrix)
# 计算文档之间的相似度
similarity_matrix = cosine_similarity(lsa_matrix)
print(similarity_matrix)
```
#### 3.2 LSA在信息检索与推荐系统中的应用
LSA在信息检索和推荐系统中广泛应用,通过计算文本相似度,可以实现文档的相关性排序、相似文档推荐等功能。在信息检索领域,LSA可以提高搜索结果的准确性和覆盖范围;在推荐系统中,LSA能够为用户推荐与其兴趣相符的内容。
#### 3.3 LSA与传统相似度计算方法的对比
相较于传统的基于词频统计的文本相似度计算方法,LSA能够通过考虑语义信息,更准确地刻画文本之间的相似度关系。LSA在处理文本语料库规模较大、语义表达复杂的场景下,表现出更好的效果和鲁棒性。因此,在处理文本相似度计算问题时,LSA通常能够取得更好的结果。
# 4. 文本预处理与特征提取
在文本相似度计算中,文本预处理和特征提取是非常重要的步骤。下面将详细介绍文本数据清洗、文本分词与词频统计以及使用LSA进行特征提取的相关内容。
#### 4.1 文本数据清洗
在进行文本相似度计算之前,通常需要对文本数据进行清洗,包括去除特殊符号、停用词、数字等,以保证文本数据的纯净性。下面是一个简单的Python示例代码,演示如何进行文本数据清洗:
```python
import re
def clean_text(text):
# 去除特殊符号和数字
text = re.sub('[^A-Za-z]+', ' ', text)
# 转换
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了潜在语义分析 (LSA) 技术,一种广泛用于自然语言处理的强大工具。它涵盖了 LSA 的基础概念、优势和应用场景,并提供了构建基本 LSA 模型的分步指南。此外,它还探讨了文本预处理在 LSA 中的作用,并提供了使用 Python 实现简单 LSA 算法的示例。专栏深入探讨了 LSA 在信息检索、文档主题建模、文本相似度计算和情感分析中的实际应用。它还比较了 LSA 和 LDA 模型,并介绍了基于 LSA 的主题检测和聚类技术。此外,它还讨论了 LSA 技术的局限性、改进方向和在推荐系统中的应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Hi3798MV310芯片实战攻略】:从入门到精通,解锁多媒体处理及应用领域的全部秘密

# 摘要
Hi3798MV310芯片是一款专为多媒体处理而设计的高性能处理器,涵盖了从理论基础到实际应用的全方位内容。本文首先对Hi3798MV310芯片进行了概览,接着深入探讨了多媒体处理的理论和技术,包括数据格
深入揭秘ZYNQ架构:混合信号处理的艺术与系统级芯片设计技巧
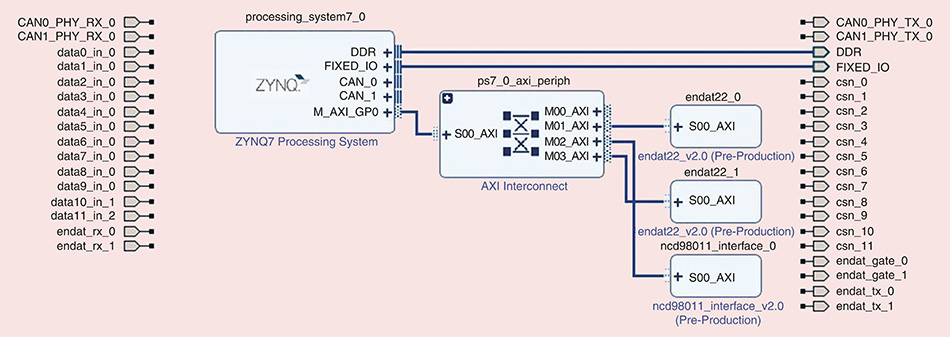
# 摘要
本文综述了ZYNQ架构的优势、基础组件、互连结构以及软件支持,详细解析了ZYNQ在混合信号处理方面的应用,包括模拟与数字信号处理的基础理论和ZYNQ平台的具体实现方式,并通过案例分析进一步阐述了其在实际应用中的表现。此外,本文还探讨了系统级芯片设计的技巧和优化策略,重点介绍了ZYNQ在
【快速掌握】TSC条码打印机基础教程:条码打印原理与操作大全

# 摘要
TSC条码打印机在现代商业和工业领域扮演着至关重要的角色,通过提供准确、高效的条码打印服务,它简化了信息追踪和管理流程。本文首先介绍了TSC条码打印机的基本概念和组成部分,随后深入讲解了条码的构成基础、印刷技术以及解码原理。文章还提供了一份详尽的操作指南,涵盖了硬件安装、软件操
【LTC2944高效电量监测系统构建】:技术要点与实战演练

# 摘要
本文全面介绍了LTC2944电量监测芯片的功能、设计要点及其在电量监测系统中的应用。首先概述了LTC2944的主要特性和工作原理,然后详细阐述了基于该芯片的硬件设计、软件开发和配置方法。文章进一步通过实验室测试和现场应用案例分析,提供了实战演练的深入见解。最后,探讨了故障排除和系统维护的实践,以及监测技术的未
【硬件设计的时序优化】:布局布线到延时控制的实战策略
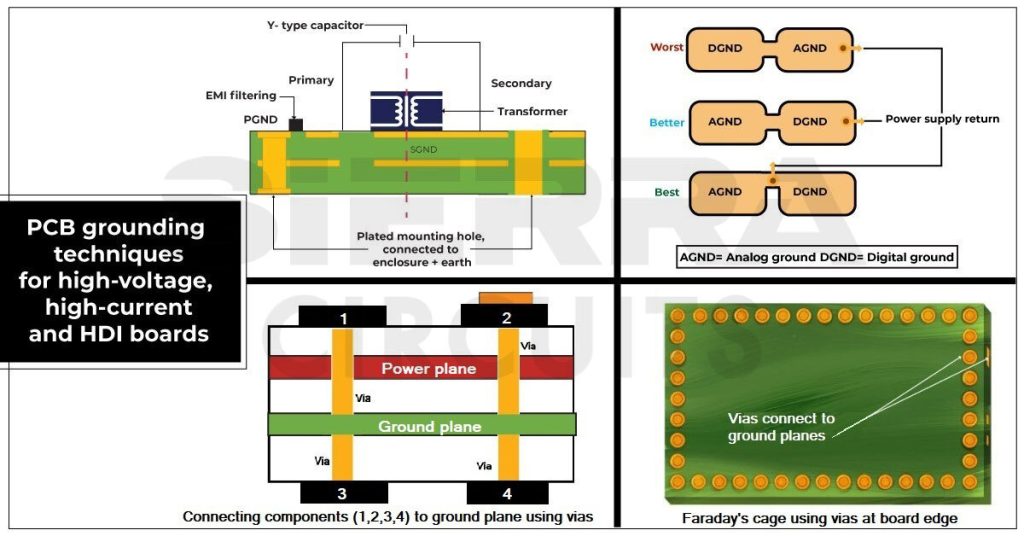
# 摘要
时序优化在硬件设计中起着至关重要的作用,直接影响到电路的性能和可靠性。本文首先强调了布局布线在硬件设计中的基础理论与实践的重要性,探讨了电路布局的关键因素和布线策略以确保信号完整性。接着,文章深入分析了延时控制的原理,包括时钟树的构建和优化以及信号传播时延的分析,
YRC1000性能提升攻略:代码效率优化的关键步骤

# 摘要
本论文首先评估并优化了YRC1000的性能基础,深入探讨了其硬件与软件架构,性能监控工具的使用,以及性能瓶颈。其次,本论文讨论了代码效率优化理论,包括性能评估、优化原则、分析方法和具体策略。在实践层面,本文详细阐述了编程语言的选择、算法优化和编译器技术对YRC1000性能的影响。此外,论文还涉及系统级性能调优,包括操作系统设置、硬件资源管理与系统监控。最后,通过案例研究,展示了YRC1000优化
【VLAN配置秘籍】:华为ENSP模拟器实战演练攻略

# 摘要
本文综合介绍了虚拟局域网(VLAN)的基础知识、配置、故障排除、安全策略及进阶技术应用。首先解析了VLAN的基本概念和原理,随后通过华为ENSP模拟器入门指南向读者展示了如何在模拟环境中创建和管理VLAN。文章还提供了VLAN配置的技巧与实践案例,重点讲
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )