VSCode与Jupyter Notebook:机器学习工作流的终极构建
发布时间: 2024-12-12 04:20:33 阅读量: 6 订阅数: 12 
# 1. VSCode与Jupyter Notebook简介
## 1.1 VSCode简介
Visual Studio Code(VSCode)是由微软开发的一款轻量级但功能强大的源代码编辑器,支持多种编程语言的语法高亮、代码补全、Git控制等特性。对于Python开发,VSCode提供了丰富的插件和工具支持,成为了开发者广泛采用的集成开发环境(IDE)之一。
## 1.2 Jupyter Notebook简介
Jupyter Notebook是一个开源的Web应用程序,允许用户创建和共享包含代码、方程、可视化和解释性文本的文档。这些文档被称作笔记本,非常适合数据清洗和转换、数值模拟、统计建模、机器学习等应用场景。
## 1.3 VSCode与Jupyter Notebook的互补性
VSCode和Jupyter Notebook各有其独特之处,但它们也可以互补。VSCode提供了一个全面的编程环境,而Jupyter Notebook则专注于交互式数据分析。在接下来的章节中,我们将探讨如何搭建这两者的环境,并探索它们在机器学习等领域的应用。
# 2. VSCode与Jupyter Notebook的环境搭建
在开始任何复杂的数据科学或机器学习项目之前,建立一个稳定且高效的开发环境是至关重要的。本章节将详细说明如何在你的系统中搭建VSCode和Jupyter Notebook环境。我们将从VSCode环境搭建开始,然后转到Jupyter Notebook的配置。
## 2.1 VSCode环境搭建
### 2.1.1 安装VSCode
Visual Studio Code(VSCode)是微软开发的一个免费的、开源的代码编辑器,它支持多种编程语言的开发,尤其在Python开发领域获得了广泛的认可。
1. 访问VSCode官方网站下载页面。
2. 选择适合你操作系统的版本进行下载。
3. 下载完成后,执行安装程序并遵循安装向导完成安装。
安装过程中,推荐安装如下组件:
- Python支持:这将使VSCode能够识别并运行Python代码。
- Pylance:这是微软的Python语言服务器,提供了快速而丰富的语言支持。
- Jupyter:允许直接在VSCode中运行Jupyter Notebook。
```bash
# 检查Python版本的命令行指令
python --version
```
安装VSCode后,运行该编辑器,进入扩展市场安装上述推荐组件。
### 2.1.2 配置VSCode以支持Python开发
Python在VSCode中的配置至关重要,它决定了你能否有效地编写、调试和运行Python代码。
1. 打开VSCode,安装Python扩展。
2. 打开命令面板(`Ctrl+Shift+P`或`Cmd+Shift+P`),输入`Python: Select Interpreter`选择合适的Python解释器。
3. 配置`settings.json`文件,设置Python路径和一些开发环境的偏好设置。
```json
// settings.json 示例配置
{
"python.pythonPath": "/usr/bin/python",
"python.terminal.activateEnvironment": true,
"python.linting.enabled": true,
"python.linting.pylintEnabled": true
}
```
4. 安装Jupyter扩展,以便VSCode可以支持Jupyter Notebook的运行。
```bash
# 检查Jupyter扩展是否安装的命令行指令
code --list-extensions | grep jupyter
```
完成以上步骤后,你的VSCode环境就已经配置完毕,可以进行Python和Jupyter Notebook的开发了。
## 2.2 Jupyter Notebook环境搭建
### 2.2.1 安装Jupyter Notebook
Jupyter Notebook是一个开放源代码的Web应用程序,允许你创建和共享包含实时代码、方程、可视化和文本的文档。
1. 安装Anaconda或Miniconda。Anaconda是一个包含了180多个科学包及其依赖项的发行版,适合数据科学和机器学习项目。Miniconda是Anaconda的一个精简版本,只包含conda包管理器和Python。
2. 安装完成后,在终端或命令提示符中输入以下命令安装Jupyter Notebook:
```bash
conda install jupyter notebook
```
或者,使用pip安装:
```bash
pip install notebook
```
3. 安装完毕后,可以使用以下命令启动Jupyter Notebook服务:
```bash
jupyter notebook
```
### 2.2.2 配置Jupyter Notebook的扩展和主题
Jupyter Notebook的可扩展性和主题的选择能大幅提高工作效率和用户体验。
1. 访问Jupyter Notebook的扩展页面,搜索并安装常用的扩展,比如`jupyterlab-variableInspector`用于变量检查、`jupyterlab-code_formatter`用于代码格式化等。
2. 在JupyterLab的设置中找到主题选项,选择你喜欢的外观风格。JupyterLab支持多种主题,包括黑暗主题,可以有效降低长时间使用时的眼睛疲劳。
安装扩展后,重启Jupyter Notebook服务以使新扩展生效。使用扩展和主题,可以大幅提高Jupyter Notebook的使用体验和开发效率。
通过本章节的介绍,读者已经了解了如何在本地环境中搭建VSCode和Jupyter Notebook,并进行了基础配置,接下来我们将深入探讨如何在机器学习领域应用这些工具。
# 3. VSCode与Jupyter Notebook在机器学习中的应用
## 3.1 数据预处理与探索
### 3.1.1 使用VSCode进行数据预处理
在机器学习项目中,数据预处理是至关重要的步骤,它决定了数据的质量和后续模型的性能。VSCode凭借其强大的编辑器功能和丰富的Python插件,成为进行数据预处理的理想环境。
为了在VSCode中有效地进行数据预处理,首先需要确保已经安装了Python及其相关的数据处理库,如Pandas和NumPy。接着,可以利用VSCode中的Jupyter Notebook扩展来编写和测试数据预处理的代码。
数据预处理通常包括缺失值处理、异常值检测、数据标准化、数据类型转换、特征编码等。下面是一个简单的示例,展示了如何使用Pandas在VSCode中进行数据预处理:
```python
import pandas as pd
# 读取数据集
data = pd.read_csv('data.csv')
# 查看数据集基本信息
data.info()
# 查找缺失值并进行填充或删除
data = data.fillna(method='ffill') # 前向填充
# 异常值处理(这里以某列为例,超过3个标准差的为异常值)
z_scores = (data['feature'] - data['feature'].mean()) / data['feature'].std()
data = data[(z_scores.abs() < 3).all(axis=1)]
# 数据标准化(归一化)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data_scaled = pd.DataFrame(scaler.fit_transform(data), columns=data.columns)
# 特征编码
data_encoded = pd.get_dummies(data_scaled, drop_first=True)
# 保存处理后的数据集
data_encoded.to_csv('processed_data.csv', index=False)
```
在这段代码中,我们首先导入了Pandas库,并读取了一个CSV格式的数据集。使用`fillna`方法处理缺失值,`abs`方法结合条件筛选来处理异常值,`MinMaxScaler`进行数据标准化,以及`get_dummies`方法进行特征的独热编码(one-hot encoding)。每一步处理后,都使用`data.info()`来查看数据集的概览,确保数据被正确处理。
为了更深入地理解代码逻辑,下面是对关键步骤的逐行解释:
- `pd.read_csv('data.csv')`: 读取名为`data.csv`的数据集文件。
- `data.info()`: 输出数据集的基本信息,如列名、非空值的数量、数据类型等。
- `data = data.fillna(method='ffill')`: 使用前向填充的方式填充缺失值。
- `z_scores = ...`: 计算每行数据在`feature`列中的Z分数,即数据与平均值的偏差除以标准差。
- `data = ...`: 筛选出Z分数绝对值小于3的行,即删除或保留异常值。
- `scaler = MinMaxScaler()`: 创建一个MinMaxScaler实例。
- `data_scaled = pd.DataFrame(scaler.fit_transform(data), columns=data.columns)`: 使用MinMaxScaler对数据进行归一化处理。
- `data_encoded = pd.get_dummies(data_scaled, drop_first=True)`: 对归一化后的数据进行独热编码。
- `data_encoded.to_csv('processed_data.csv', index=False)`: 将处理后的数据保存到`processed_data.csv`文件中。
完成数据预处理后,数据通常会更加适合机器学习模型的训练和分析。VSCode的便捷性使得这一过程更加高效,通过交互式的笔记本环境,可以快

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到专栏,深入探讨 VSCode 中 Jupyter Notebook 的强大功能。在这个专栏中,我们将探索各种主题,包括协作技巧、高级调试、机器学习集成、代码片段、性能优化、细胞单元使用、主题自定义等。通过我们的文章,您将掌握利用 VSCode 和 Jupyter Notebook 提升工作效率和项目成果所需的知识和技巧。无论您是数据科学家、机器学习工程师还是开发人员,这个专栏都将为您提供宝贵的见解,帮助您充分利用这些工具,释放您的工作潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【16位加法器设计秘籍】:全面揭秘高性能计算单元的构建与优化

# 摘要
本文对16位加法器进行了全面的研究和分析。首先回顾了加法器的基础知识,然后深入探讨了16位加法器的设计原理,包括二进制加法基础、组成部分及其高性能设计考量。接着,文章详细阐述
三菱FX3U PLC编程:从入门到高级应用的17个关键技巧

# 摘要
三菱FX3U PLC是工业自动化领域常用的控制器之一,本文全面介绍了其编程技巧和实践应用。文章首先概述了FX3U PLC的基本概念、功能和硬件结构,随后深入探讨了
【Xilinx 7系列FPGA深入剖析】:掌握架构精髓与应用秘诀
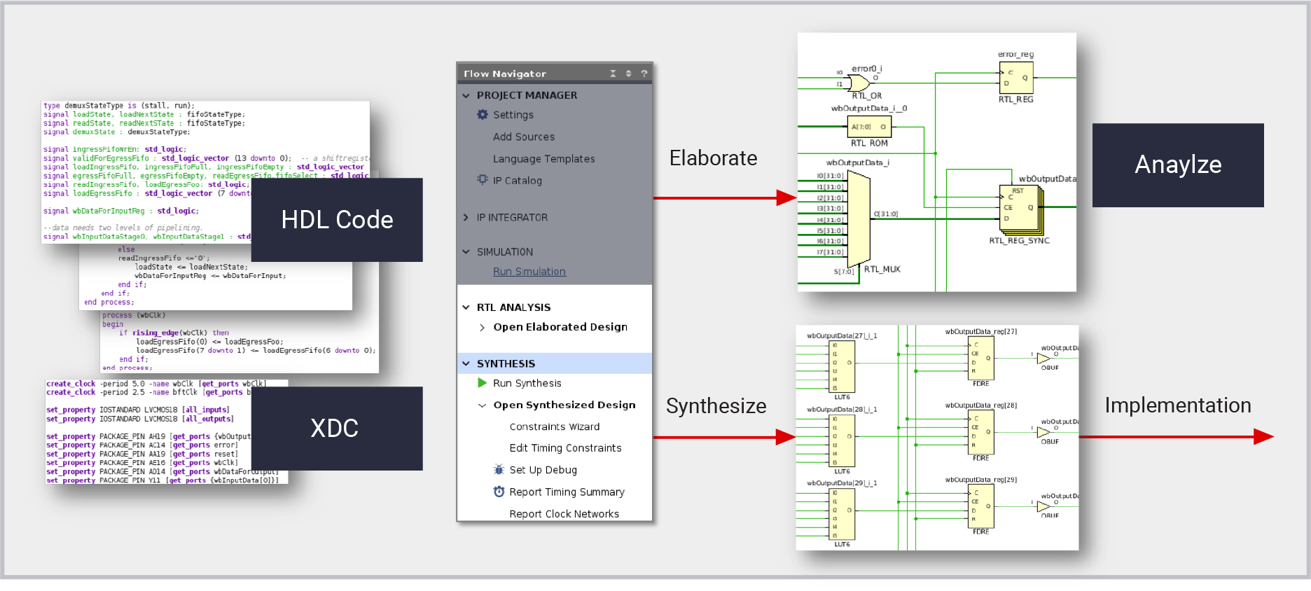
# 摘要
本文详细介绍了Xilinx 7系列FPGA的关键特性及其在工业应用中的广泛应用。首先概述了7系列FPGA的基本架构,包括其核心的可编程逻辑单元(PL)、集成的块存储器(BRAM)和数字信号处理(DSP)单元。接着,本文探讨了使用Xilinx工具链进行FPGA编程与配置的流程,强调了设计优化和设备配置的重要性。文章进一步分析了7系列FPGA在
【图像技术的深度解析】:Canvas转JPEG透明度保护的终极策略

# 摘要
随着Web技术的不断发展,图像技术在前端开发中扮演着越来越重要的角色。本文首先介绍了图像技术的基础和Canvas绘
【MVC标准化:肌电信号处理的终极指南】:提升数据质量的10大关键步骤与工具
# 摘要
MVC标准化是肌电信号处理中确保数据质量的重要步骤,它对于提高测量结果的准确性和可重复性至关重要。本文首先介绍肌电信号的生理学原理和MVC标准化理论,阐述了数据质量的重要性及影响因素。随后,文章深入探讨了肌电信号预处理的各个环节,包括噪声识别与消除、信号放大与滤波技术、以及基线漂移的校正方法。在提升数据质量的关键步骤部分,本文详细描述了信号特征提取、MVC标准化的实施与评估,并讨论了数据质量评估与优化工具。最后,本文通过实验设计和案例分析,展示了MVC标准化在实践应用中的具
ISA88.01批量控制:电子制造流程优化的5大策略

# 摘要
本文首先概述了ISA88.01批量控制标准,接着深入探讨了电子制造流程的理论基础,包括原材料处理、制造单元和工作站的组成部分,以及流程控制的理论框架和优化的核心原则。进一步地,本文实
【Flutter验证码动画效果】:如何设计提升用户体验的交互

# 摘要
随着移动应用的普及和安全需求的提升,验证码动画作为提高用户体验和安全性的关键技术,正受到越来越多的关注。本文首先介绍Flutter框架下验证码动画的重要性和基本实现原理,涵盖了动画的类型、应用场景、设计原则以及开发工具和库。接着,文章通过实践篇深入探讨了在Flutter环境下如何具体实现验证码动画,包括基础动画的制作、进阶技巧和自定义组件的开发。优化篇
ENVI波谱分类算法:从理论到实践的完整指南
# 摘要
ENVI软件作为遥感数据处理的主流工具之一,提供了多种波谱分类算法用于遥感图像分析。本文首先概述了波谱分类的基本概念及其在遥感领域的重要性,然后介绍了ENVI软件界面和波谱数据预处理的流程。接着,详细探讨了ENVI软件中波谱分类算法的实现方法,通过实践案例演示了像元级和对象级波谱分类算法的操作。最后,文章针对波谱分类的高级应用、挑战及未来发展进行了讨论,重点分析了高光谱数据分类和深度学习在波谱分类中的应用情况,以及波谱分类在土地覆盖制图和农业监测中的实际应用。
# 关键字
ENVI软件;波谱分类;遥感图像;数据预处理;分类算法;高光谱数据
参考资源链接:[使用ENVI进行高光谱分
【天线性能提升密籍】:深入探究均匀线阵方向图设计原则及案例分析
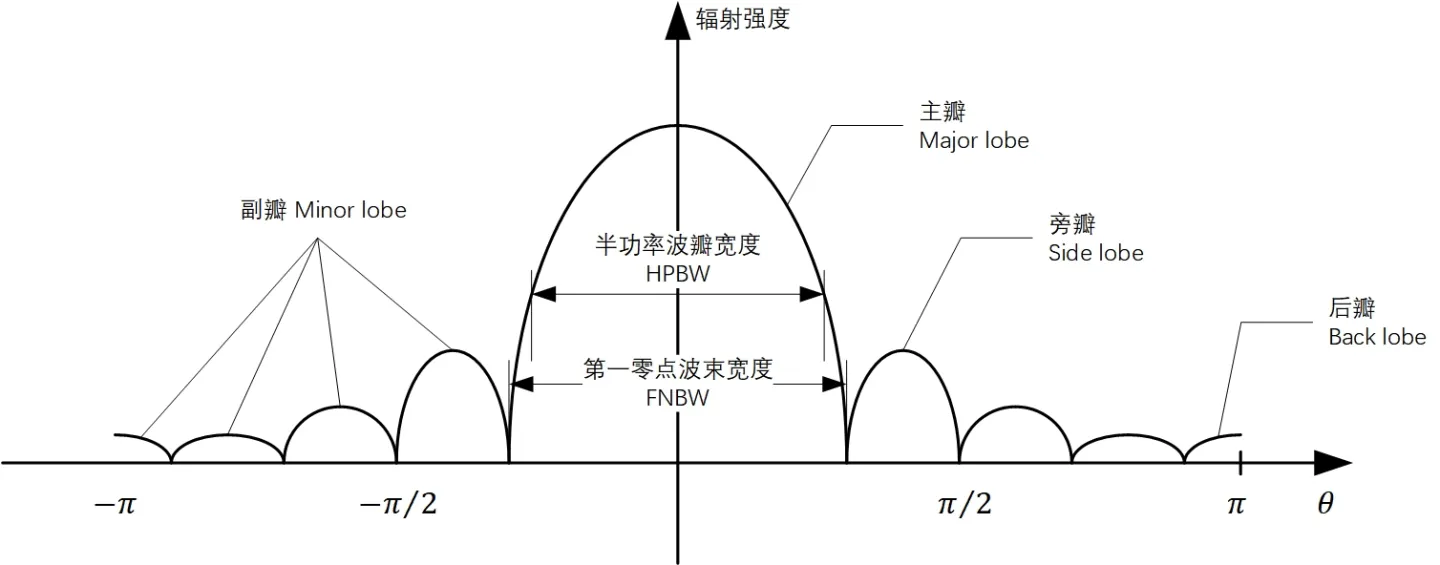
# 摘要
本文深入探讨了均匀线阵天线的基础理论及其方向图设计,旨在提升天线系统的性能和应用效能。文章首先介绍了均匀线阵及方向图的基本概念,并阐述了方向图设计的理论基础,包括波束形成与主瓣及副瓣特性的控制。随后,论文通过设计软件工具的应用和实际天线系统调试方法,展示了方向图设计的实践技巧。文中还包含了一系列案例分析,以实证研究验证理论,并探讨了均匀线阵性能
【兼容性问题】快解决:专家教你确保光盘在各设备流畅读取
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/L/w/I3DfXKTAmrqNi0rGtG5A/2014-06-24-cd-dvd-bluray.png)
# 摘要
光盘作为一种传统的数据存储介质,其兼容性问题长
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )