【分布式训练新境界】:Horovod实战技巧与最佳实践
发布时间: 2024-11-17 17:43:35 阅读量: 24 订阅数: 26 

Vue + Vite + iClient3D for Cesium 实现限高分析
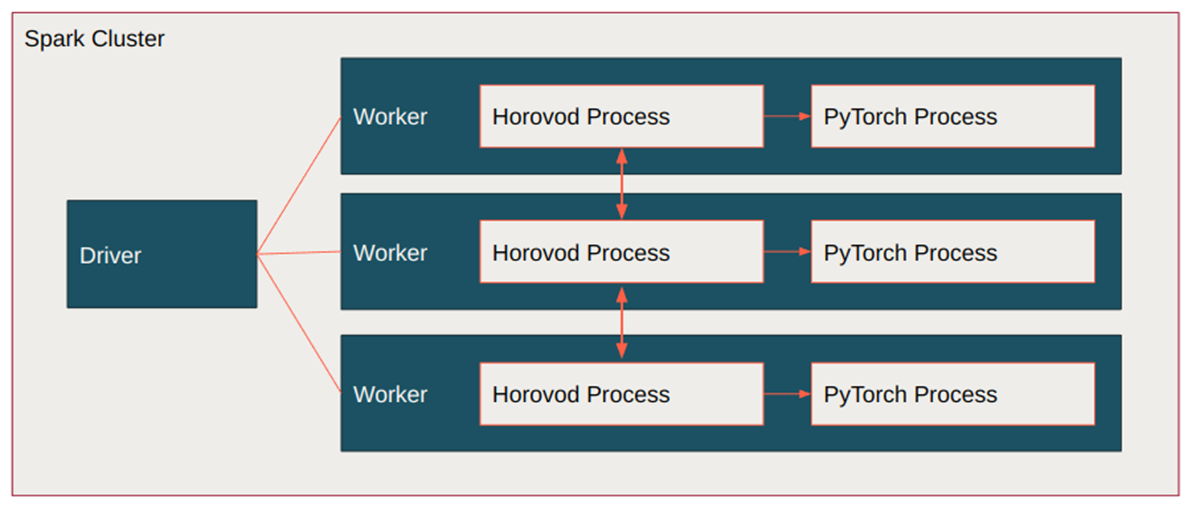
# 1. 分布式训练与Horovod概述
在当今快速发展的IT行业,随着数据量的日益增加和深度学习模型的持续复杂化,分布式训练已经成为加速大规模机器学习任务的重要途径。分布式训练允许我们将计算任务分配到多个计算节点上,从而实现速度的提升和计算资源的高效利用。Horovod作为一个开源的分布式训练框架,其设计目标是简化分布式深度学习的实现过程,让开发者能够更快地部署和运行分布式模型。
分布式训练的核心优势在于通过横向扩展来提高训练效率。然而,实现有效的分布式训练并不简单,涉及到的数据并行、模型并行、通信优化、资源管理等多个方面都需要综合考虑。Horovod通过提供一个简化的API,使得用户能够在多个GPU或节点上轻松扩展TensorFlow、Keras、PyTorch等框架训练出的模型。
通过本章的学习,我们将深入了解分布式训练的基本概念,并对Horovod框架有一个全面的认识。之后的章节将详细介绍Horovod的基础使用方法、性能优化技巧,以及如何将其应用于实际的训练场景中。
# 2. Horovod基础使用方法
## 2.1 Horovod的基本安装与配置
在大规模分布式训练中,Horovod作为一个开源的分布式深度学习框架,扮演着关键角色。安装Horovod前的准备工作和详细安装过程是入门的关键。
### 2.1.1 安装Horovod的前准备
为了使Horovod能够顺利安装,有几个前置条件需要满足:
- **系统环境要求**:首先需要安装支持MPI(Message Passing Interface)的系统,例如Linux系统。此外,还需要安装有Python环境,且建议版本在3.5以上。
- **依赖包**:需要安装如`numpy`、`tensorflow`或`pytorch`等深度学习框架,以及`mpi4py`,这些可以通过Python的包管理器pip来安装。
- **网络环境**:确保系统环境可以访问Horovod官方仓库或第三方镜像仓库,如PyPI。
确保以上条件得到满足后,就可以进行Horovod的安装了。
### 2.1.2 Horovod的安装过程详解
Horovod可以通过pip或conda命令进行安装。下面以pip为例:
```bash
pip install horovod
```
如果需要使用GPU加速,需要安装带有CUDA支持的版本:
```bash
HOROVOD_WITH_TORCH=1 HOROVOD_WITHOUT_MXNET=1 pip install horovod
```
安装过程中,可能需要根据系统环境和包依赖关系进行一些额外配置。例如,在使用GPU进行安装时,需要确保CUDA和cuDNN已经正确安装并配置在系统的环境变量中。
安装完毕后,可以通过运行一些简单的示例脚本来验证安装是否成功。
## 2.2 Horovod的初步运行示例
为了进一步理解Horovod的使用方法,我们可以从单节点和多节点运行示例开始。
### 2.2.1 单节点运行Horovod
在单节点上运行Horovod相对简单。以下是一个使用TensorFlow和Horovod的简单示例:
```python
import tensorflow as tf
import horovod.tensorflow as hvd
# 初始化Horovod
hvd.init()
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(hvd.local_rank())
tf.reset_default_graph()
with tf.Session(config=config) as sess:
# 在此处添加训练逻辑
# 例如,定义一个简单的神经网络
```
在这个示例中,首先导入了`horovod.tensorflow`模块,并使用`hvd.init()`初始化Horovod。然后,通过配置TensorFlow的会话来使Horovod能够使用指定的GPU。
### 2.2.2 多节点运行Horovod
多节点运行需要在所有参与计算的节点上进行初始化设置。通常需要一个启动脚本来启动所有节点的训练进程。例如,使用SSH和mpirun启动集群节点:
```bash
mpirun -np 4 -H server1:2,server2:2 -bind-to core -map-by slot \
-mca pml ob1 -mca btl openib \
-mca btl_tcp_if_include eth0 \
-mca oob_tcp_if_include eth0 \
-mca osc马丁 ob1 -mca plm_rsh_args "-p 22 -l 1 -t" \
-x LD_LIBRARY_PATH -x PATH -x PYTHONPATH -x CUDA_VISIBLE_DEVICES=0 \
python train.py
```
这个脚本利用`mpirun`来启动多个Horovod进程,并且通过指定参数来控制启动的节点、GPU等资源分配。
## 2.3 Horovod的核心概念和架构
了解Horovod的核心概念和架构对于深入使用Horovod至关重要。
### 2.3.1 数据并行与模型并行
数据并行和模型并行是分布式训练中的两种核心思想。数据并行指的是将数据分为多个子集,每个子集被不同的计算节点处理。模型并行则是将模型的不同部分分布在不同的计算节点上处理。Horovod主要关注数据并行。
### 2.3.2 Horovod的运行时架构
Horovod的运行时架构主要基于MPI实现,使得其在多GPU环境下具有很好的扩展性和通信效率。Horovod内部使用NCCL(NVIDIA Collective Communications Library)进行高效的GPU间通信。在初始化阶段,Horovod会自动广播模型参数,并在训练过程中同步梯度信息。
### 小结
本章节深入探讨了Horovod的基础使用方法,包括了安装、配置和运行示例,以及理解其核心概念和架构。掌握这些基础知识,是深入学习Horovod的必经之路,也是优化和应用Horovod分布式训练的重要基石。接下来的章节将会进一步深入到提升Horovod性能的实战技巧和最佳实践案例分析中。
# 3. 提升Horovod性能的实战技巧
在分布式深度学习训练过程中,性能优化至关重要,直接影响到模型训练的速度、准确度和资源的利用效率。Horovod作为一个高效的分布式训练框架,提供了丰富的优化选项。本章将深入探讨如何通过多种策略来提升Horovod的性能,包括优化通信策略、资源管理和监控以及与深度学习框架的整合。
## 3.1 Horovod的通信策略优化
### 3.1.1 通信后端的选择与配置
在使用Horovod进行分布式训练时,通信后端的选择对于整体训练性能有着显著的影响。Horovod支持多种通信后端,包括MPI、NCCL等,其中NCCL(NVIDIA Collective Communications Library)针对NVIDIA GPU进行了优化,能够提供较高的通信效率。对于NVIDIA GPU环境,推荐使用NCCL作为通信后端。
```python
import horovod.tensorflow as hvd
# 初始化Horovod
hvd.init()
# 指定使用NCCL通信后端
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(hvd.local_rank())
tf.Session(config=config)
```
代码解释:
- `hvd.init()` 初始化Horovod环境。
- `config.gpu_options.allow_growth = True` 允许GPU内存动态增长,避免初始分配过多内存。
- `config.gpu_options.visible_device_list = str(hvd.local_rank())` 设置当前可见的GPU设备,即当前进程使用的GPU。
参数说明:
- `hvd.local_rank()` 表示当前进程在本地的排名。
### 3.1.2 网络参数的调优
网络参数的调优包括调整通信超时时间、控制消息的大小等。例如,可以增加通信超时时间来适应大规模集群中的网络波动。
```python
# 设置通信超时时间为60秒
hvd.set通信超时时间(60)
```
## 3.2 Horovod的资源管理与监控
### 3.2.1 资源调度器的集成
为了在多个节点上高效地分配计算资源,Horovod提供了对多种资源调度器的支持,比如Kubernetes、Slurm等。集成资源调度器能够帮助我们更好地管理作业队列、动态资源分配和容错。
```yaml
# 一个简单的Kubernetes作业配置示例
apiVersion: batch/v1
kind: Job
metadata:
name: horovod-tensorflow
spec:
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:nightly-gpu
command: ["mpirun", "-np", "4", "python", "train.py"]
resources:
limits:
***/gpu: 1
restartPolicy: Never
```
### 3.2.2 监控Horovod训练过程
监控训练过程可以帮助我们了解训练进度,诊断潜在问题,并提供实时反馈。Horovod与TensorBoard集成,可以实时显示训练的损失和指标。
```shell
# 启动TensorBoard来监控Horovod训练
horovodrun -np 4 -H server1:2,server2:2 python train.py --use-tfboard
```
## 3.3 Horovod与深度学习框架的整合
### 3.3.1 TensorFlow中的Horovod使用
在TensorFlow中整合Horovod可以利用`horovod.tensorflow`模块,它提供了对Horovod分布式训练支持的封装。
```python
# 在TensorFlow中使用Horovod
import horovod.tensorflow as hvd
import tensorflow as tf
# 初始化Horovod
hvd.init()
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(hvd.local_rank())
tf.Session(config=config)
```
### 3.3.2 PyTorch中的Horovod使用
对于PyTorch用户,Horovod也提供了很好的支持。通过使用`horovod.torch`模块,可以方便地在PyTorch代码中加入Horovod的分布式训练功能。
```python
# 在PyTorch中使用Horovod
import horovod.torch as hvd
import torch
# 初始化Horovod
hvd.init()
torch.cuda.set_device(hvd.local_rank())
```
## 总结
提升Horovod性能的技巧涉及到多个方面,从通信后端的选择和网络参数的调整,到资源管理的集成和监控,再到深度学习框架的整合。通过合理配置和使用,可以使Horovod在分布式训练中的表现更加出色。在实际应用中,应根据硬件条件和训练需求,灵活选择和调整这些优化策略。
# 4. Horovod的最佳实践案例分析
分布式训练已经成为深度学习领域的一个关键技术,而Horovod作为Uber开发的一款开源框架,极大地简化了大规模分布式训练的复杂性。在本章中,我们将深入探讨如何运用Horovod处理实际问题,以确保读者能够掌握在真实世界场景中使用Horovod的技巧和策略。
## 4.1 大规模数据集的分布式训练
在大规模数据集上进行分布式训练是机器学习发展的一个重要方向。Horovod通过简化通信操作,使得研究人员可以更容易地扩展单GPU训练到多GPU甚至多节点的训练。接下来将深入介绍在使用Horovod进行大规模数据集训练时需要采取的一些策略。
### 4.1.1 数据加载与预处理策略
在多GPU训练时,数据加载和预处理的效率直接影响整个训练过程的性能。以下是几种高效的数据加载和预处理策略:
- **多线程数据预取**:使用多线程或者进程来进行数据预取,以减少GPU在训练时的空闲时间。例如,PyTorch的`DataLoader`类支持多进程数据加载。
- **异步数据加载**:将数据加载与模型训练分到不同的线程或进程中,通过创建异步队列来平衡两者之间的工作负载。
- **数据集划分**:当数据集很大时,可以将数据集分片,每块数据由不同的进程或GPU加载。
以下是一个简单的`DataLoader`使用示例:
```python
import torch.utils.data as data
from torchvision import datasets, transforms
# 数据预处理
transform = ***pose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# 加载数据集
train_dataset = datasets.ImageFolder(root='path_to_train_dataset', transform=transform)
train_loader = data.DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)
for images, labels in train_loader:
# 训练过程
pass
```
### 4.1.2 批量大小调整与学习率缩放
在分布式训练中,一个关键的超参数调整是批量大小。如果模型在单GPU上工作得很好,那么在增加GPU数量时,直接等比例增加批量大小通常会降低模型性能。因此,需要根据并行度合理调整批量大小。
此外,学习率也需要根据并行化程度进行调整。通常情况下,可以保持学习率与批量大小成正比,从而保持训练的稳定性。例如,如果批量大小翻倍,那么学习率也可以相应翻倍。
```python
# 假设初始学习率为0.01,批量大小为32
base_lr = 0.01
batch_size = 32
# 如果批量大小改为64,那么学习率应调整为:
new_lr = base_lr * (64 / 32)
```
## 4.2 超参数调优和模型验证
超参数调优和模型验证是机器学习中不可或缺的步骤。在分布式训练的场景下,这些步骤变得更加复杂。接下来,我们将讨论如何高效地进行这些任务。
### 4.2.1 分布式超参数搜索方法
分布式超参数搜索可以显著提高搜索过程的效率。常用的分布式超参数搜索方法包括:
- **网格搜索**:并行化网格中的每一个点。
- **随机搜索**:并行化随机搜索的不同迭代。
- **贝叶斯优化**:利用贝叶斯优化算法对超参数进行优化,同时并行化探索过程。
这里是一个使用Horovod进行网格搜索的简化代码示例:
```python
import horovod.torch as hvd
# 初始化Horovod
hvd.init()
torch.cuda.set_device(hvd.local_rank())
torch.manual_seed(42)
# 模型定义
model = MyModel()
# 分布式优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
# 分布式损失函数
def train_loss():
# 计算训练损失
pass
# 分布式超参数搜索
for param1 in param1_values:
for param2 in param2_values:
optimizer.param_groups[0]['lr'] = param1
optimizer.param_groups[0]['weight_decay'] = param2
# 训练过程
train_loss()
# 验证过程
validate_loss()
```
### 4.2.2 模型验证和测试的分布式方法
模型验证和测试是评估模型性能的重要环节。在分布式环境中,需要确保评估过程的准确性和一致性。下面是一些关键点:
- **数据一致性**:保证在所有节点上使用相同的数据进行验证和测试。
- **结果汇总**:在所有节点上并行地进行验证和测试,然后汇总结果。
- **标准化的评估协议**:确保评估过程遵循统一的标准和协议,使得结果具有可比较性。
## 4.3 Horovod在云计算环境的应用
随着云计算服务的普及,如何在云环境中有效地部署Horovod成为了一个新的挑战。本节将探讨云环境中Horovod的应用和潜在的挑战。
### 4.3.1 云服务商的Horovod支持和限制
不同的云服务商对Horovod的支持程度不尽相同。一些服务商可能已经提供了Horovod的镜像或者集成好的解决方案,例如:
- **AWS**:通过其Deep Learning AMI支持Horovod。
- **Azure**:提供直接运行Horovod的虚拟机镜像。
- **Google Cloud Platform**:通过AI Platform Notebook,可以在Jupyter环境中使用Horovod。
同时,每个云平台都有其特有的限制。例如,某些平台可能对GPU实例类型有限制,或者在资源配额和网络配置上有所限制。
### 4.3.2 部署Horovod到云平台实例
部署Horovod到云平台涉及到几个步骤:
- **选择正确的实例类型**:选择含有合适GPU和充足内存的实例类型。
- **配置网络**:确保所有实例间的通信不受限制。
- **安装和配置Horovod**:根据上文所述的方法安装和配置Horovod。
下面是一个在AWS EC2实例上部署Horovod的示例流程:
```bash
# 创建EC2实例并连接
ssh -i "your_key.pem" ***
# 安装Horovod的依赖
sudo apt-get update && sudo apt-get install -y \
build-essential \
cmake \
git \
curl \
libfreetype6-dev \
libpng16-dev \
libzmq3-dev \
pkg-config \
software-properties-common \
unzip \
wget \
zlib1g-dev \
libhdf5-dev \
libxml2-dev \
cython \
libopenblas-dev \
liblapack-dev
# 克隆Horovod仓库并安装
git clone --recursive ***
```
以上就是Horovod在云计算环境部署的基础流程。
在本章中,我们探讨了如何使用Horovod进行大规模数据集的分布式训练,并介绍了超参数调优和模型验证的最佳实践。同时,我们也讨论了在云计算环境中部署Horovod时需要注意的问题和方法。通过以上内容的学习,读者应该能够更加熟练地应用Horovod解决分布式训练中遇到的实际问题。
# 5. Horovod的扩展与未来展望
随着人工智能与深度学习的快速发展,分布式训练成为不可或缺的技术,Horovod作为这一领域的佼佼者,正在不断地扩展其应用范围并与更多技术集成。本章将探讨Horovod的扩展以及对未来的展望,以及如何在个人和社区层面做出贡献。
## 5.1 Horovod与其他技术的集成
Horovod的核心是实现高效的分布式训练,而为了进一步提升其实用性和灵活性,与容器化技术及AI服务的集成变得尤为重要。
### 5.1.1 Horovod与Kubernetes的集成
Kubernetes作为容器编排的工业标准,具有强大的资源管理和调度能力。Horovod与Kubernetes的结合可以极大地简化大规模分布式训练的部署和运维过程。以下是如何集成Horovod与Kubernetes的步骤:
1. **容器化应用**: 将训练应用和依赖打包成Docker镜像。
2. **编写Kubernetes部署配置**: 利用Kubernetes Deployment和Service等资源定义Horovod训练任务。
3. **资源调度与分配**: 通过Kubernetes的资源请求和限制配置合理的资源分配给训练任务。
4. **服务发现与负载均衡**: 使用Kubernetes的Service和Ingress资源保证服务的发现和负载均衡。
代码示例:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: horovod-training
spec:
replicas: 4
selector:
matchLabels:
app: horovod-training
template:
metadata:
labels:
app: horovod-training
spec:
containers:
- name: horovod-training
image: your-horovod-image
resources:
requests:
cpu: "1"
memory: "2Gi"
limits:
cpu: "4"
memory: "8Gi"
env:
- name: WORLD_SIZE
value: "4"
- name: RANK
valueFrom:
fieldRef:
fieldPath: metadata.annotations['pod-index']
apiVersion: v1
kind: Service
metadata:
name: horovod-training-service
spec:
type: NodePort
selector:
app: horovod-training
ports:
- protocol: TCP
port: 8888
targetPort: 8888
```
### 5.1.2 Horovod与AI服务的融合
将Horovod与AI服务如TensorBoard、JupyterHub等集成,可以进一步增强其在数据可视化、交互式研究与开发方面的功能。例如,将TensorBoard集成到Horovod训练中,可以让用户实时监控模型训练进度和性能指标。
代码示例:
```python
from horovod.tensorflow import train
# 配置TensorBoard回调函数
callbacks = [tf.keras.callbacks.TensorBoard(log_dir='./logs')]
# 初始化Horovod分布式训练器
opt = tf.train.AdagradOptimizer(learning_rate=0.01 * hvd.size())
# 使用Horovod的分布式优化器
opt = hvd.DistributedOptimizer(opt)
# 编译模型并设置优化器、损失和评价指标
***pile(loss=tf.keras.losses.sparse_categorical_crossentropy,
optimizer=opt,
metrics=['accuracy'])
# 使用train方法开始训练并指定回调函数
model.fit(x_train, y_train, epochs=10, callbacks=callbacks)
```
## 5.2 分布式训练的挑战与机遇
分布式训练为深度学习模型的扩展提供了途径,但同时也带来了新的技术挑战。未来的发展趋势预示着可能的机遇。
### 5.2.1 当前分布式训练面临的问题
1. **通信开销**: 在大规模训练中,节点间的通信开销往往成为性能瓶颈。
2. **同步延迟**: 节点处理速度不一致导致的同步延迟问题,影响了训练效率。
3. **容错机制**: 在长周期的训练过程中,节点故障会导致训练失败,需要有更好的容错机制。
### 5.2.2 分布式训练技术的发展趋势
- **异步训练**: 异步训练通过减少同步频率来降低通信开销,但可能影响模型收敛速度和质量。
- **模型并行**: 通过分布在不同节点上的模型片段并行处理,可以进一步提升训练规模。
- **更优的容错策略**: 研究更高效的检查点保存机制和任务迁移策略,以支持大规模分布式训练。
## 5.3 个人与社区贡献
Horovod社区欢迎来自各方的贡献,无论是经验分享还是代码提交,都有助于推动Horovod的发展。
### 5.3.1 如何为Horovod做出贡献
1. **报告问题**: 使用Horovod时遇到的问题,可以通过GitHub Issues进行报告。
2. **编写文档**: 协助撰写或改进Horovod的官方文档和教程。
3. **代码贡献**: 编写功能代码或提交bug修复,参与代码审查过程。
### 5.3.2 贡献者指南与资源分享
Horovod提供了一系列工具和文档,以帮助贡献者更好地参与项目。可以在GitHub的贡献者指南中找到提交代码、反馈问题的具体流程。同时,社区定期举办线上会议和研讨会,分享最新的开发进展和研究成果。
通过上述章节的阐述,我们从Horovod与其他技术的集成开始,探讨了分布式训练所面临的挑战与机遇,并详细介绍了个人和社区如何为Horovod项目做出贡献。Horovod未来的发展需要更多的开发者和用户的共同参与,为深度学习领域的分布式训练提供更加强大和高效的技术支撑。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Horovod分布式训练》专栏深入探讨了Horovod分布式训练框架的各个方面,提供了一系列全面的指南和深入的分析。从性能调优到容错机制,从数据并行技术到PyTorch集成,专栏涵盖了广泛的主题,为读者提供了全面了解Horovod及其在分布式训练中的应用。此外,专栏还探讨了Horovod在深度学习之外的AI框架中的跨界应用,以及在多机多卡训练环境中高效使用Horovod的策略。通过提供透明化的训练过程管理、模型压缩和优化技巧以及资源调度优化建议,专栏为读者提供了在分布式训练中充分利用Horovod的全面指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【面试杀手锏】:清华数据结构题,提炼面试必杀技

# 摘要
本文系统地探讨了数据结构在软件工程面试中的重要性和应用技巧。首先介绍了数据结构的理论基础及其在面试中的关键性,然后深入分析了线性结构、树结构和图论算法的具体概念、特点及其在解决实际问题中的应用。文章详细阐述了各种排序和搜索算法的原理、优化策略,并提供了解题技巧。最
WMS系统集成:ERP和CRM协同工作的智慧(无缝对接,高效整合)

# 摘要
随着信息技术的发展,企业资源规划(ERP)和客户关系管理(CRM)系统的集成变得日益重要。本文首先概述了ERP系统与仓库管理系统(WMS)的集成,并分析了CRM系统与WMS集成的协同工作原理。接着,详细探讨了ERP与CRM系统集成的技术实现,包括集成方案设计、技术挑战
HiGale数据压缩秘籍:如何节省存储成本并提高效率
# 摘要
随着数据量的激增,数据压缩技术显得日益重要。HiGale数据压缩技术通过深入探讨数据压缩的理论基础和实践操作,提供了优化数据存储和传输的方法。本论文概述了数据冗余、压缩算法原理、压缩比和存储成本的关系,以及HiGale平台压缩工具的使用和压缩效果评估。文中还分析了数据压缩技术在
温度传感器校准大师课:一步到位解决校准难题

# 摘要
温度传感器校准对于确保测量数据的准确性和可靠性至关重要。本文从温度传感器的基础概念入手,详细介绍了校准的分类、工作原理以及校准过程中的基本术语和标准。随后,本文探讨了校准工具和环境的要求,包括实验室条件、所需仪器设备以及辅助软件和工具。文章第三章深入解析了校准步骤,涉及准备工作、测量记录以及数据
CPCI规范中文版深度解析:掌握从入门到精通的实用技巧
# 摘要
CPCI规范作为一种在特定行业内广泛采用的技术标准,对工业自动化和电子制造等应用领域具有重要影响。本文首先对CPCI规范的历史和发展进行了概述,阐述了其起源、发展历程以及当前的应用现状。接着,深入探讨了CPCI的核心原理,包括其工作流程和技术机制。本文还分析了CPCI规范在实际工作中的应用,包括项目管理和产品开发,并通过案例分析展示了CPCI规范的成功应用与经验教训。此外,文章对CPCI规范的高级应用技
【UML用户体验优化】:交互图在BBS论坛系统中的应用技巧
# 摘要
UML交互图作为软件开发中重要的建模工具,不仅有助于理解和设计复杂的用户交互流程,还是优化用户体验的关键方法。本文首先对UML交互图的基础理论进行了全面介绍,包括其定义、分类以及在软件开发中的作用。随后,文章深入探讨了如何在论坛系统设计中实践应用UML交互图,并通过案例分析展示了其在优化用户体验方面的具体应用。接着,本文详细讨论了UML交互图的高级应用技巧,包括与其他UML图的协同工作、自动化工具的运用以及在敏捷开发中的应用。最后,文章对UML交互图在论坛系统中的深入优化策略进行了研究,并展望了其未来的发展方向。
# 关键字
UML交互图;用户体验;论坛系统;软件开发;自动化工具;
【CRYSTAL BALL软件全攻略】:从安装到高级功能的进阶教程
# 摘要
CRYSTAL BALL软件是一套先进的预测与模拟工具,广泛应用于金融、供应链、企业规划等多个领域。本文首先介绍了CRYSTAL BALL的安装和基本操作,包括界面布局、工具栏、菜单项及预测模型的创建和管理。接着深入探讨了其数据模拟技术,涵盖概率分布的设定、模拟结果的分析以及风险评估和决策制定的方法。本文还解析了CRYSTAL BALL的
【复杂设计的公差技术】:ASME Y14.5-2018高级分析应用实例
# 摘要
公差技术是确保机械组件及装配精度的关键工程方法。本文首先
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )