【Horovod监控与日志】:透明化训练过程管理
发布时间: 2024-11-17 18:40:32 阅读量: 17 订阅数: 26 

Horovod分布式训练.pptx

# 1. Horovod简介与基础架构
Horovod是Uber开发的一个开源框架,用于在分布式环境中进行高效的模型训练。它被设计为一个易于使用的包装器,能够加速TensorFlow、Keras、PyTorch和Apache MXNet中的分布式训练。
## 1.1 Horovod的核心组件
Horovod的核心组件包括:
- **AllReduce**:一种减少和广播算法,用于在所有节点间平均梯度。
- **HorovodRing**:一种优化后的AllReduce操作,减少了网络通信的冗余。
## 1.2 基础架构详解
Horovod架构基于消息传递接口(MPI)构建,它允许你在多个GPU上运行同一模型。Horovod利用MPI的高效网络传输能力,实现了跨多个GPU的快速梯度交换。
```python
import horovod.tensorflow as hvd
# 初始化Horovod
hvd.init()
# 将所有变量绑定到Horovod的优化器
opt = hvd.DistributedOptimizer(optimizer)
```
以上代码片段展示了如何初始化Horovod并使用其分布式优化器来训练模型。Horovod的核心是它的分布式优化器,它能够处理多个工作节点上的训练任务,并在所有节点间同步梯度和模型参数。
# 2. Horovod训练过程监控
## 2.1 监控的重要性与方法
### 2.1.1 训练过程监控的目标
在分布式训练场景中,监控的目标是保证训练过程的稳定性和效率。Horovod作为分布式训练框架,对于监控的需要体现在以下几个方面:
- **资源使用效率**:实时跟踪计算资源(CPU、GPU、内存)的使用情况,确保资源不会被浪费。
- **训练速度与进度**:观察训练速度是否符合预期,分析是否有节点拖慢整体进度。
- **错误和异常**:捕捉并分析异常和错误,及时修正训练过程中的问题。
- **性能瓶颈**:识别性能瓶颈,帮助调整训练策略和资源分配。
### 2.1.2 系统资源监控工具选择
在众多系统资源监控工具中,有几种特别适合于与Horovod结合使用:
- **NVIDIA System Management Interface (nvidia-smi)**: 对于GPU资源监控非常直接,可以提供详细的GPU利用率、内存使用情况等。
- **Prometheus 和 Grafana**: 能够实现细粒度的监控,并通过可视化界面展示监控结果。
- **ELK Stack (Elasticsearch, Logstash, Kibana)**: 对于日志的收集、存储和分析非常强大。
## 2.2 Horovod的性能指标分析
### 2.2.1 常见性能指标简介
为了理解Horovod训练的性能,以下是一些关键的性能指标:
- **吞吐量(Throughput)**: 每秒钟完成训练的批量数量,反映训练效率。
- **延迟(Latency)**: 从提交批量到收到结果的时间,影响实时性。
- **扩展性(Scalability)**: 分布式训练的性能随着训练节点增加的表现。
- **资源利用率(Resource Utilization)**: 在训练过程中资源如CPU、GPU的利用率。
### 2.2.2 使用Horovod指标进行分析
Horovod提供了许多接口来获取性能指标。例如,可以使用Horovod的`hvd.size()`来获取总的节点数,`hvd.local_size()`来获取本地节点数。此外,也可以通过日志来记录这些指标:
```python
import horovod.tensorflow as hvd
from tensorflow import keras
# Initialize Horovod
hvd.init()
# Determine batch size dynamically based on the Horovod size
batch_size = 32 * hvd.size()
# Build model...
# Compile model...
# Train model...
```
通过上述代码片段,我们可以看到如何根据Horovod集群的大小动态调整批量大小,从而分析吞吐量和扩展性。
## 2.3 实时训练监控策略
### 2.3.1 日志级别与消息记录
在训练过程中记录日志可以帮助追踪和分析训练状态。根据需要的日志详细程度,可以设置不同的日志级别。以下是TensorFlow配合Horovod进行日志级别的设置代码示例:
```python
import logging
# Horovod: set logging level
hvd.init()
logging.basicConfig(level=*** + 10 * hvd.rank())
```
### 2.3.2 实时监控工具应用案例
为了实现Horovod训练的实时监控,可以使用Prometheus监控系统和Grafana数据可视化工具。下面的示例展示了如何将TensorFlow训练的状态和性能指标实时展示到Grafana仪表板。
首先,在训练脚本中集成Prometheus的记录器:
```python
from prometheus_client import Summary
import time
# Horovod: initialize Prometheus metrics.
horovod_training_time = Summary('horovod_training_time', 'Time spent in Horovod training')
@horovod_training_time.time()
def train_step():
# training logic
```
然后,使用Prometheus抓取这些指标,并通过Grafana进行展示。以下是一个基于Prometheus抓取的配置示例:
```yaml
scrape_configs:
- job_name: 'horovod_training'
static_configs:
- targets: ['<host_ip>:<port>']
```
结合这些监控工具,可以构建出一个完整的训练监控解决方案,实现对训练状态的实时跟踪和分析。
# 3. Horovod日志系统深入
## 3.1 Horovod日志机制
### 3.1.1 日志级别和格式
Horovod日志系统是分布式训练中不可或缺的组件。日志级别通常分为五个层次:DEBUG、INFO、WARNING、ERROR和CRITICAL,其中DEBUG级别提供了最详尽的信息,而CRITICAL级别只记录最严重的问题。在实际应用中,开发者可以根据需要设置日志级别,以便在调试时获得更多信息或在生产环境中保持日志的清洁。
在Horovod中,日志格式默认是文本形式,但也可以配置为JSON格式,这对于自动化工具和日志分析尤其有用。默认格式包括时间戳、日志级别、日志消息及附加信息,这为快速定位问题提供了便利。
```python
import horovod.tensorflow as hvd
import logging
# 设置日志格式为JSON格式
logging.basicConfig(level=logging.DEBUG, format='{"timestamp": "%(asctime)s", "level": "%(levelname)s", "message": "%(message)s"}')
# Horovod初始化
hvd.init()
```
代码执行后,日志将以JSON格式输出,例如:
```json
{
"timestamp": "2023-04-01 12:00:00",
"level": "INFO",
"message": "Horovod v0.22.1 initialized"
}
```
### 3.1.2 日志的收集与存储
在分布式训练环境中,日志的收集与存储尤为关键。Horovod日志系统能够将日志输出到标准输出(stdout)、标准错误(stderr)或者文件中。日志存储解决方案包括但不限于集中式日志服

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Horovod分布式训练》专栏深入探讨了Horovod分布式训练框架的各个方面,提供了一系列全面的指南和深入的分析。从性能调优到容错机制,从数据并行技术到PyTorch集成,专栏涵盖了广泛的主题,为读者提供了全面了解Horovod及其在分布式训练中的应用。此外,专栏还探讨了Horovod在深度学习之外的AI框架中的跨界应用,以及在多机多卡训练环境中高效使用Horovod的策略。通过提供透明化的训练过程管理、模型压缩和优化技巧以及资源调度优化建议,专栏为读者提供了在分布式训练中充分利用Horovod的全面指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CPCI规范中文版避坑指南:解决常见问题,提升实施成功率

# 摘要
CPCI(CompactPCI)规范作为一种国际标准,已被广泛应用于工业和通信领域的系统集成中。本文首先概述了CPCI规范中文版的关键概念、定义及重要性,并比较了其与传统PCI技术的差异。接着,文章深入分析了中文版实施过程中的常见误区、挑战及成功与失败的案例。此外,本文还探讨了如何提升CPCI规范中文版实施成功率的策略,包括规范的深入理解和系统化管理。最后,文章对未来CPCI技术的发展趋势以及在
电池散热技术革新:高效解决方案的最新进展

# 摘要
电池散热技术对于保障电池性能和延长使用寿命至关重要,同时也面临诸多挑战。本文首先探讨了电池散热的理论基础,包括电池热产生的机理以及散热技术的分类和特性。接着,通过多个实践案例分析了创新散热技术的应用,如相变材料、热管技术和热界面材料,以及散热系统集成与优化的策略。最后,本文展望了未来电池散热技术的发展方向,包括可持续与环境友好型散热技术的探索、智能散热管理系统的设计以及跨学科技术融合的
【深入剖析Cadence波形功能】:提升电路设计效率与仿真精度的终极技巧

# 摘要
本文对Cadence波形功能进行了全面介绍,从基础操作到进阶开发,深入探讨了波形查看器的使用、波形信号的分析理论、仿真精度的优化实践、系统级波形分析以及用户定制化波形工具的开发。文中不仅详细解析了波形查看器的主要组件、基本操作方法和波形分析技巧,还着重讲解了仿真精度设置对波形数据精度的影
【数据库系统原理及应用教程第五版习题答案】:权威解读与实践应用指南
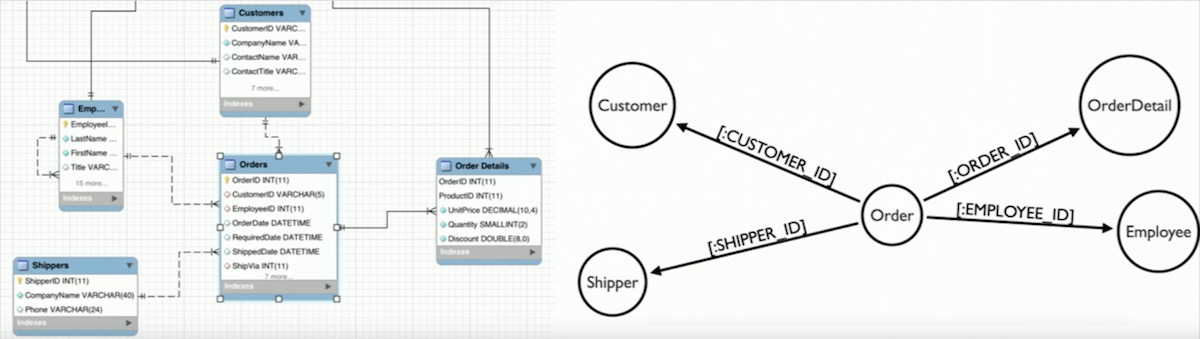
# 摘要
数据库系统是现代信息系统的核心,它在组织、存储、检索和管理数据方面发挥着至关重要的作用。本文首先概述了数据库系统的基本概念,随后深入探讨了关系数据库的理论基础,包括其数据结构、完整性约束、关系代数与演算以及SQL语言的详细解释。接着,文章着重讲述了数据库设计与规范化的过程,涵盖了需求分析、逻辑设计、规范化过程以及物理设计和性能优化。本文进一步分析了数据库管理系统的关键实现技术,例如存储引擎、事务处理、并发控制、备份与恢复技术。实践应用章
系统稳定运行秘诀:CS3000维护与监控指南

# 摘要
本文全面介绍CS3000系统的日常维护操作、性能监控与优化、故障诊断与应急响应以及安全防护与合规性。文章首先概述了CS3000系统的基本架构和功能,随后详述了系统维护的关键环节,包括健康检查、软件升级、备份与灾难恢复计划。在性能监控与优化章节中,讨论了有效监控工具的使用、性能数据的分析以及系统调优的实践案例。故障诊断与应急响应章节
HiGale数据压缩秘籍:如何节省存储成本并提高效率
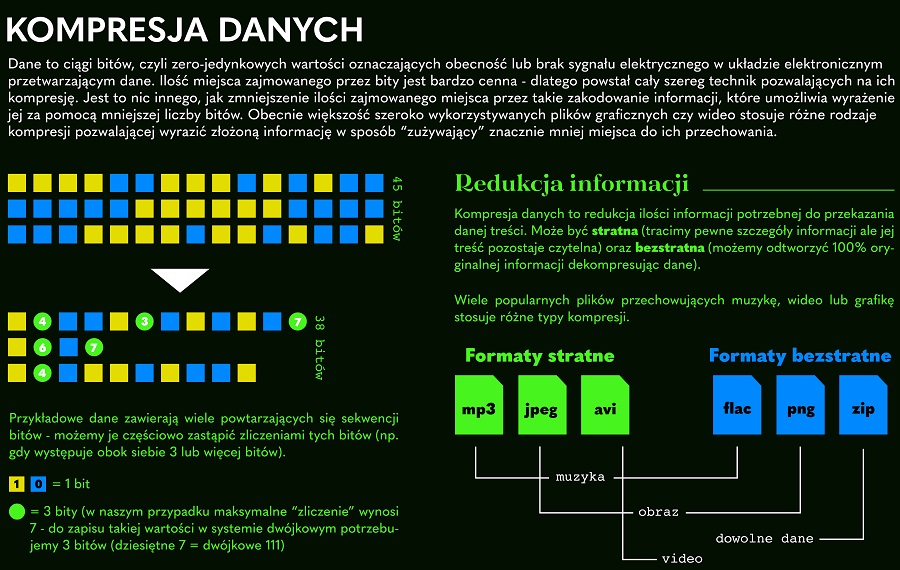
# 摘要
随着数据量的激增,数据压缩技术显得日益重要。HiGale数据压缩技术通过深入探讨数据压缩的理论基础和实践操作,提供了优化数据存储和传输的方法。本论文概述了数据冗余、压缩算法原理、压缩比和存储成本的关系,以及HiGale平台压缩工具的使用和压缩效果评估。文中还分析了数据压缩技术在
WMS功能扩展:适应变化业务需求的必备技能(业务敏捷,系统灵活)
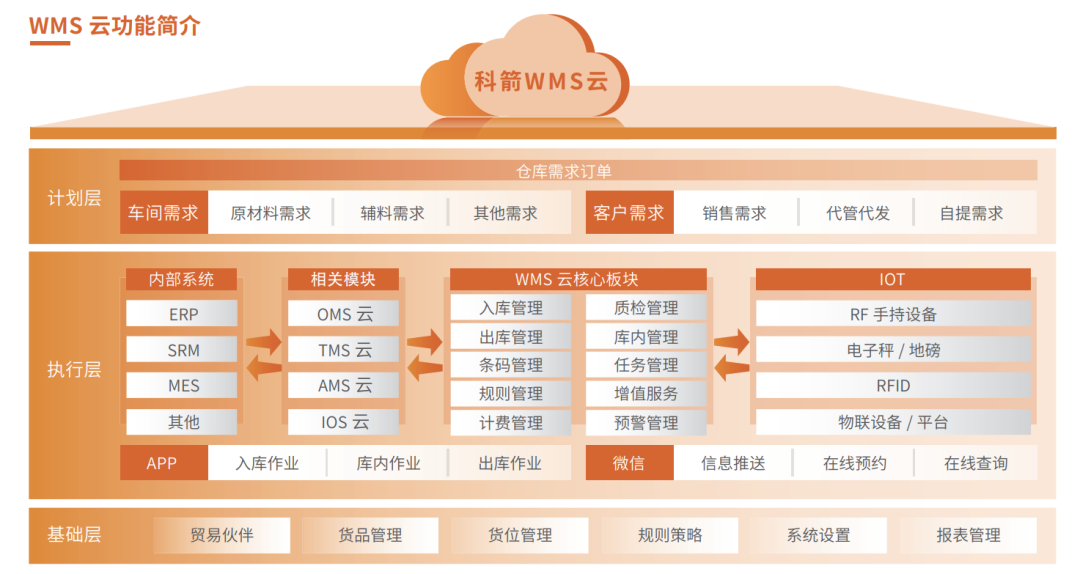
# 摘要
本文详细介绍了WMS系统的业务需求适应性及其对业务敏捷性的理论基础和实践策略。首先概述了WMS系统的基本概念及其与业务需求的匹配度。接着探讨了业务敏捷性的核心理念,并分析了提升敏捷性的方法,如灵活的工作流程设计和适应性管理。进一步,文章深入阐述了系统灵活性的关键技术实现,包括模块化设计、动态配置与扩展以及数据管理和服务化架构。在功能扩展方面,本文提供
【数据结构实例分析】:清华题中的应用案例,你也能成为专家
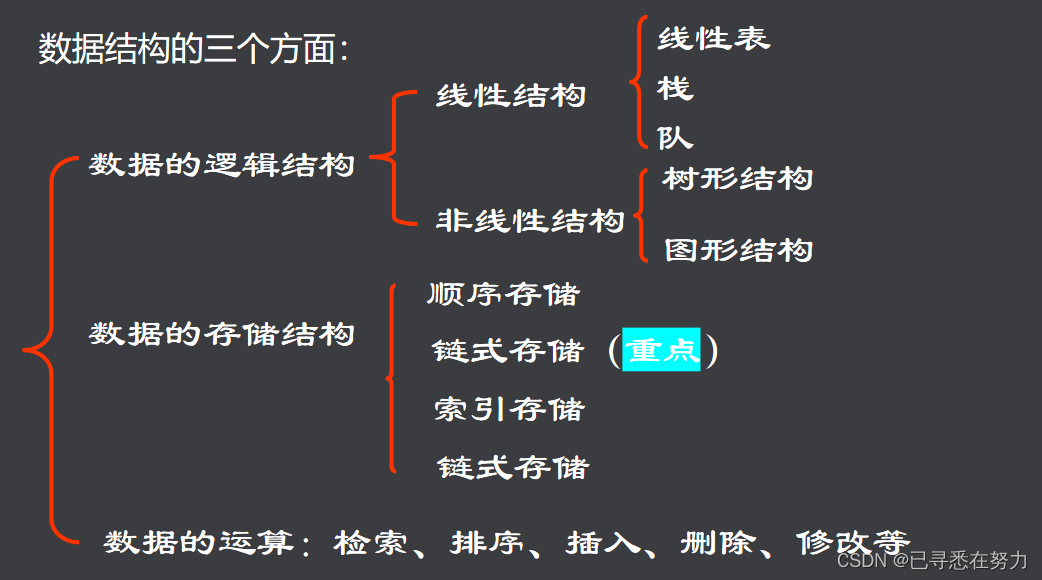
# 摘要
本文全面探讨了数据结构在解决复杂问题中的应用,特别是线性结构、树结构、图结构、散列表和字符串的综合应用。文章首先介绍了数据结构的基础知识,然后分别探讨了线性结构、树结构和图结构在处理特定问题中的理论基础和实战案例。特别地,针对线性结构,文中详细阐述了数组和链表的原理及其在清华题中的应用;树结构的分析深入到二叉树及其变种;图结构则涵盖了图的基本理论、算法和高级应用案例。在散列表和字符串综合应用章节,文章讨论了散列表设计原理、
【精密工程案例】:ASME Y14.5-2018在精密设计中的成功实施
# 摘要
ASME Y14.5-2018标准作为机械设计领域内的重要文件,为几何尺寸与公差(GD&T)提供了详细指导。本文首先概述了ASME Y14.5-2018标准,并从理论上对其进行了深入解析,包括GD&T的基本概念、术语定义及其在设计中的应用。接着,文章讨论了ASME Y14.5-2018在机械设计实际应用中的实施,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )