【GPU集群部署指南】:Horovod的硬件配置与软件设置
发布时间: 2024-11-17 17:58:14 阅读量: 22 订阅数: 26 

PyTorch在AI&GPU并行计算集群上部署与使用.docx
# 1. GPU集群基础与Horovod简介
## 1.1 GPU集群概述
在深度学习和高性能计算领域,GPU集群已经成为不可或缺的基础设施。它由多个GPU节点组成,这些节点通过高速网络连接,共同执行大规模的并行计算任务。GPU集群的构建目的是为了提供强大的计算能力,加快模型训练速度,缩短产品开发周期,同时提高数据处理和分析的效率。
## 1.2 GPU集群的应用场景
GPU集群被广泛应用于机器学习、深度学习、科学模拟、图像处理、大数据分析等多个领域。它可以在短时间内处理巨大的数据集,并通过分布式计算技术进行复杂的数学计算,从而实现高吞吐量的并行处理。
## 1.3 Horovod简介
Horovod是一个开源的框架,用于在多GPU和多节点上实现分布式深度学习训练。它由Uber推出,其目的是为了简化分布式训练的复杂性,并允许研究人员和工程师们使用常见的框架进行快速扩展。Horovod能够利用MPI(消息传递接口)作为后端,实现高效的节点间通信。其设计理念是通过减少代码变更来轻松实现代码的并行化,进而加速模型训练过程。
# 2. GPU集群硬件配置
### 2.1 GPU硬件选择与评估
GPU的选择是构建高效集群的关键步骤之一。选择合适的GPU能够显著影响到机器学习任务的运行效率和成本效益。在本章节中,我们将详细解析GPU的性能指标,并探讨如何根据不同的机器学习任务来选择适当的GPU硬件。
#### 2.1.1 GPU性能指标解析
在分析GPU性能时,我们需要考虑以下几个关键指标:
- **计算能力**:指的是GPU能够进行浮点运算的能力,通常用FLOPS(每秒浮点运算次数)来表示。对于深度学习任务来说,高计算能力是必要的。
- **内存容量**:GPU的显存大小决定了能够处理的数据量,对于复杂模型和大规模数据集来说尤其重要。
- **内存带宽**:决定了GPU内存在单位时间内能够读取和写入数据的速度,高带宽意味着更快的数据处理能力。
- **能效比**:指的是单位瓦特功耗下的计算能力,良好的能效比能够降低运行成本并减少散热需求。
- **CUDA核心数量**:CUDA核心数量越多,处理并行任务时的性能越强。
在选择GPU时,还需要考虑硬件的兼容性和驱动支持情况,以及厂商提供的生态链支持和服务。
#### 2.1.2 GPU与机器学习任务适配性
根据机器学习任务的特点,选择合适的GPU至关重要。例如:
- 对于图像处理任务,需要选择具有高带宽和大显存的GPU,以支持大型卷积神经网络(CNN)模型。
- 自然语言处理任务可能更依赖于计算能力和较小的显存容量。
- 在训练超大型模型时,可能需要多GPU甚至多节点的集群配合,以提供足够的计算力和内存。
### 2.2 网络架构与存储配置
#### 2.2.1 高速网络技术对比
高速网络是GPU集群中数据传输的高速公路,选择合适的网络技术对于集群的性能至关重要。下面是一些常见的高速网络技术:
- **InfiniBand**:一种高性能、低延迟的网络技术,广泛应用于高性能计算(HPC)领域,支持RDMA(远程直接内存访问)。
- **Ethernet**:最普遍的局域网络技术,成本相对较低,但延迟通常高于InfiniBand。
- **RoCE(RDMA over Converged Ethernet)**:在标准Ethernet上实现RDMA的技术,兼具Ethernet的广泛部署和InfiniBand的高性能特点。
不同应用场景需要根据成本、性能和生态系统支持来选择合适的网络技术。
#### 2.2.2 分布式存储解决方案
在GPU集群中,分布式存储是管理大量数据和模型的核心。以下是几个流行的分布式存储解决方案:
- **Ceph**:一个开源的分布式存储系统,具备高可靠性和高性能,支持块存储、文件系统和对象存储。
- **NFS**:网络文件系统,支持多用户共享存储,易于管理,但性能可能不如专用的分布式存储系统。
- **GPUDirect Storage**:NVIDIA提供的技术,允许GPU直接与存储设备通信,显著减少数据传输的开销。
选择合适的存储解决方案对于实现高效的I/O性能至关重要,尤其是在大规模数据处理场景中。
### 2.3 冷却系统与供电管理
#### 2.3.1 GPU集群散热需求分析
GPU集群运行时会产生大量热量,这要求有有效的冷却系统来维持设备温度在安全范围内。以下是几个常见的冷却系统方案:
- **直接液冷(Direct Liquid Cooling, DLC)**:通过液体直接冷却GPU,效率高,但成本和维护成本也高。
- **空冷**:使用风扇和散热片来散发GPU产生的热量,成本低,但可能无法处理极高密度的GPU配置。
选择冷却系统时,需要考虑到成本、散热效率、维护难易程度等因素。
#### 2.3.2 供电系统的规划与设计
一个高效的供电系统是GPU集群稳定运行的基石。以下是供电系统的一些关键要素:
- **电力容量**:确保供电系统有足够的电流和电压容量来满足集群的最大功耗。
- **冗余设计**:设计冗余电源来防止单点故障,确保系统的持续运行。
- **PUE(Power Usage Effectiveness)**:衡量数据中心能源利用效率的指标,PUE越低,表示能源使用越高效。
在规划供电系统时,需要考虑到能耗管理、电源的稳定性和可靠性、以及可能的扩展性需求。
通过以上各小节的深入讨论,我们可以看到,GPU集群的硬件配置是一个涉及多个方面的复杂过程,每个环节都需要仔细考虑,以确保集群在性能、成本、稳定性和扩展性方面达到最优配置。在接下来的章节中,我们将继续深入探讨如何使用Horovod来优化分布式深度学习训练任务。
# 3. Horovod软件设置
## 3.1 Horovod的安装与配置
### 3.1.1 Docker与Singularity容器部署
Docker和Singularity是两种流行的容器技术,它们对于在GPU集群中部署Horovod提供了极大的便利。它们允许用户创建隔离的运行环境,确保应用的可移植性和一致性。
在使用Docker部署Horovod时,首先要安装Docker引擎。在每个GPU节点上运行的Docker容器需要访问本地GPU资源,因此需要在Docker配置中启用nvidia-container-runtime。
```bash
# 安装nvidia-container-runtime
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L ***$distribution/nvidia-container-runtime.list | \
sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list
sudo apt-get update
sudo apt-get install -y nvidia-container-runtime
# 在Docker配置中添加如下行
{
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
```
通过上述配置,Docker便可以利用nvidia-container-runtime来运行支持GPU的应用程序。接下来是构建一个包含Horovod和其他依赖的Docker镜像。
Singularity是另一种选择,特别适合在集群环境中运行。Singularity可以在用户空间中构建镜像,这意味着它不需要root权限来创建和执行容器。安装Singularity的步骤如下:
```bash
# 安装Singularity
sudo apt-get install -y build-essential uuid-dev squashfs-tools libgpgme-dev python3-dev \
libseccomp-dev wget pkg-config squashfs-tools cryptsetup
# 下载并安装最新版本的Singularity
wget ***
```
Singularity镜像通常使用定义文件(def)来创建。对于Horovod,您可以创建一个定义文件来安装所有必要的依赖,包括TensorFlow或PyTorch,然后将它们一起打包到一个Singularity容器中。
在定义文件中指定Horovod及其依赖项,确保以root用户权限运行,因为某些步骤可能需要超级用户权限来安装必要的包和设置系统。
### 3.1.2 Horovod与TensorFlow、PyTorch集成
Horovod能够与TensorFlow、PyTorch等主流深度学习框架无缝集成,从而简化了多GPU和多节点训练过程。对于TensorFlow,集成步骤涉及安装Horovod库,并在训练脚本中初始化Horovod的MPI运行器。对于PyTorch,集成过程大致相同,但可能会涉及一些特定的API调用。
对于TensorFlow集成,首先需要安装Horovod包。通过以下命令,我们可以安装Horovod及其依赖项:
```bash
# 使用pip安装Horovod
HOROVOD_WITH_TENSORFLOW=1 HOROVOD_WITHOUT_PYTORCH=1 pip install horovod
```
安装完成后,在TensorFlow训练脚本中初始化Horovod:
```python
import horovod.tensorflow as hvd
# 初始化Horovod
hvd.init()
# 在每个进程中分配一个唯一的GPU ID
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# 使用上面的配置创建一个会话
keras.backend.set_session(tf.Session(config=config))
```
在PyTorch中集成Horovod的过程类似,但使用的是PyTorch的后端:
```python
import horovod.torch as hvd
# 初始化Horovod
hvd.init()
# 根据当前进程的local_rank将特定的GPU分配给当前进程
torch.cuda.set_device(hvd.local_rank())
# 初始化分布式优化器
optimizer = optim.SGD(model.parameters(), ... )
optimizer = hvd.DistributedOptimizer(optimizer, ...)
```
接下来的训练循环将使用这个优化器,这样训练过程就可以在多个GPU上并行进行了。
## 3.2 环境变量与资源配置
### 3.2.1 MPI环境设置与调优
MPI(消息传递接口)是并行计算中常用的一种标准,它允许在多个计算节点之间进行高效的消息传递。在使用Horovod进行分布式训练时,MPI环境的设置与调优至关重要,它直接影响到程序的性能。
为了优化MPI环境,需要关注以下方面:
- 网络通信后端的优化
-

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Horovod分布式训练》专栏深入探讨了Horovod分布式训练框架的各个方面,提供了一系列全面的指南和深入的分析。从性能调优到容错机制,从数据并行技术到PyTorch集成,专栏涵盖了广泛的主题,为读者提供了全面了解Horovod及其在分布式训练中的应用。此外,专栏还探讨了Horovod在深度学习之外的AI框架中的跨界应用,以及在多机多卡训练环境中高效使用Horovod的策略。通过提供透明化的训练过程管理、模型压缩和优化技巧以及资源调度优化建议,专栏为读者提供了在分布式训练中充分利用Horovod的全面指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CPCI规范中文版避坑指南:解决常见问题,提升实施成功率

# 摘要
CPCI(CompactPCI)规范作为一种国际标准,已被广泛应用于工业和通信领域的系统集成中。本文首先概述了CPCI规范中文版的关键概念、定义及重要性,并比较了其与传统PCI技术的差异。接着,文章深入分析了中文版实施过程中的常见误区、挑战及成功与失败的案例。此外,本文还探讨了如何提升CPCI规范中文版实施成功率的策略,包括规范的深入理解和系统化管理。最后,文章对未来CPCI技术的发展趋势以及在
电池散热技术革新:高效解决方案的最新进展

# 摘要
电池散热技术对于保障电池性能和延长使用寿命至关重要,同时也面临诸多挑战。本文首先探讨了电池散热的理论基础,包括电池热产生的机理以及散热技术的分类和特性。接着,通过多个实践案例分析了创新散热技术的应用,如相变材料、热管技术和热界面材料,以及散热系统集成与优化的策略。最后,本文展望了未来电池散热技术的发展方向,包括可持续与环境友好型散热技术的探索、智能散热管理系统的设计以及跨学科技术融合的
【深入剖析Cadence波形功能】:提升电路设计效率与仿真精度的终极技巧

# 摘要
本文对Cadence波形功能进行了全面介绍,从基础操作到进阶开发,深入探讨了波形查看器的使用、波形信号的分析理论、仿真精度的优化实践、系统级波形分析以及用户定制化波形工具的开发。文中不仅详细解析了波形查看器的主要组件、基本操作方法和波形分析技巧,还着重讲解了仿真精度设置对波形数据精度的影
【数据库系统原理及应用教程第五版习题答案】:权威解读与实践应用指南
# 摘要
数据库系统是现代信息系统的核心,它在组织、存储、检索和管理数据方面发挥着至关重要的作用。本文首先概述了数据库系统的基本概念,随后深入探讨了关系数据库的理论基础,包括其数据结构、完整性约束、关系代数与演算以及SQL语言的详细解释。接着,文章着重讲述了数据库设计与规范化的过程,涵盖了需求分析、逻辑设计、规范化过程以及物理设计和性能优化。本文进一步分析了数据库管理系统的关键实现技术,例如存储引擎、事务处理、并发控制、备份与恢复技术。实践应用章
系统稳定运行秘诀:CS3000维护与监控指南

# 摘要
本文全面介绍CS3000系统的日常维护操作、性能监控与优化、故障诊断与应急响应以及安全防护与合规性。文章首先概述了CS3000系统的基本架构和功能,随后详述了系统维护的关键环节,包括健康检查、软件升级、备份与灾难恢复计划。在性能监控与优化章节中,讨论了有效监控工具的使用、性能数据的分析以及系统调优的实践案例。故障诊断与应急响应章节
HiGale数据压缩秘籍:如何节省存储成本并提高效率
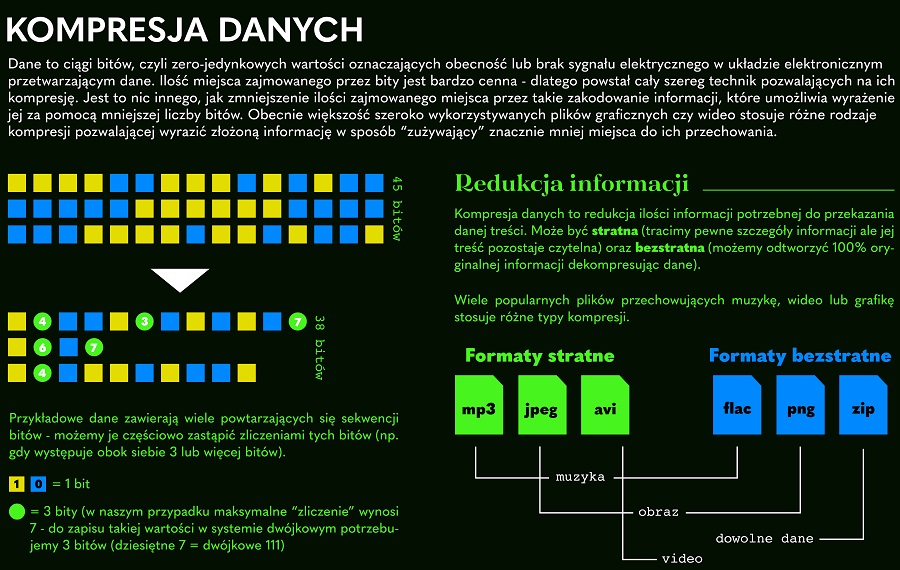
# 摘要
随着数据量的激增,数据压缩技术显得日益重要。HiGale数据压缩技术通过深入探讨数据压缩的理论基础和实践操作,提供了优化数据存储和传输的方法。本论文概述了数据冗余、压缩算法原理、压缩比和存储成本的关系,以及HiGale平台压缩工具的使用和压缩效果评估。文中还分析了数据压缩技术在
WMS功能扩展:适应变化业务需求的必备技能(业务敏捷,系统灵活)
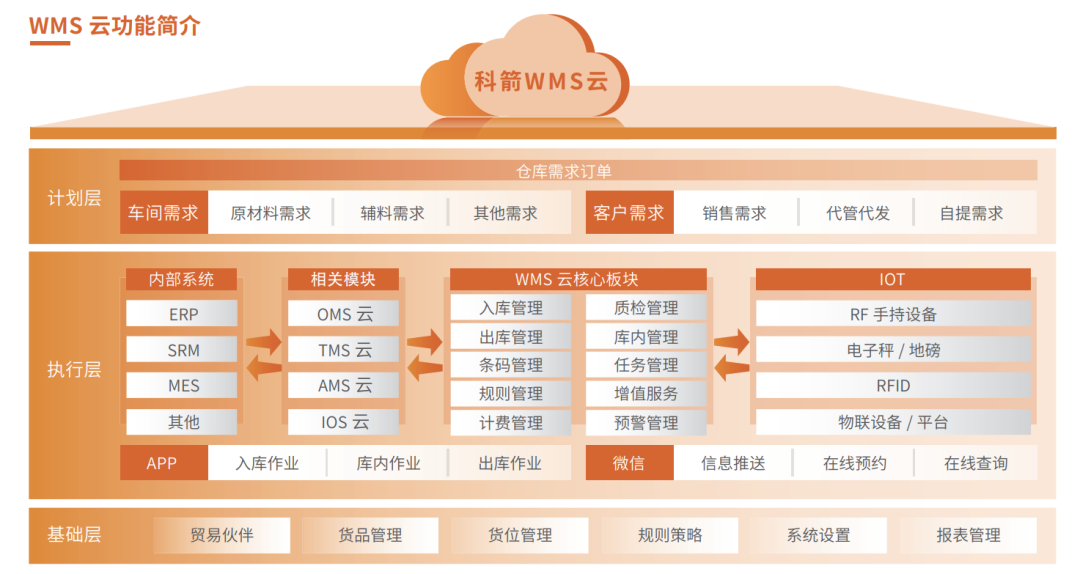
# 摘要
本文详细介绍了WMS系统的业务需求适应性及其对业务敏捷性的理论基础和实践策略。首先概述了WMS系统的基本概念及其与业务需求的匹配度。接着探讨了业务敏捷性的核心理念,并分析了提升敏捷性的方法,如灵活的工作流程设计和适应性管理。进一步,文章深入阐述了系统灵活性的关键技术实现,包括模块化设计、动态配置与扩展以及数据管理和服务化架构。在功能扩展方面,本文提供
【数据结构实例分析】:清华题中的应用案例,你也能成为专家
# 摘要
本文全面探讨了数据结构在解决复杂问题中的应用,特别是线性结构、树结构、图结构、散列表和字符串的综合应用。文章首先介绍了数据结构的基础知识,然后分别探讨了线性结构、树结构和图结构在处理特定问题中的理论基础和实战案例。特别地,针对线性结构,文中详细阐述了数组和链表的原理及其在清华题中的应用;树结构的分析深入到二叉树及其变种;图结构则涵盖了图的基本理论、算法和高级应用案例。在散列表和字符串综合应用章节,文章讨论了散列表设计原理、
【精密工程案例】:ASME Y14.5-2018在精密设计中的成功实施
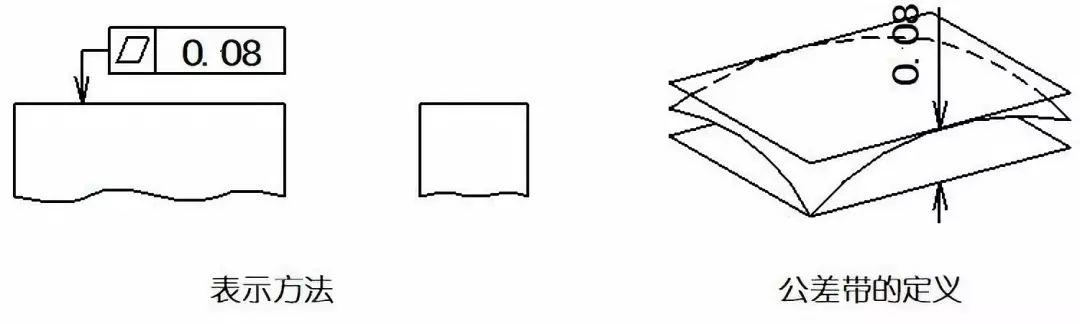
# 摘要
ASME Y14.5-2018标准作为机械设计领域内的重要文件,为几何尺寸与公差(GD&T)提供了详细指导。本文首先概述了ASME Y14.5-2018标准,并从理论上对其进行了深入解析,包括GD&T的基本概念、术语定义及其在设计中的应用。接着,文章讨论了ASME Y14.5-2018在机械设计实际应用中的实施,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )