【Django Admin第三方集成】:一站式后台体验的打造秘诀
发布时间: 2024-10-10 18:02:11 阅读量: 111 订阅数: 39 

django-foldable-admin:在Django Admin UI中折叠展开应用程序
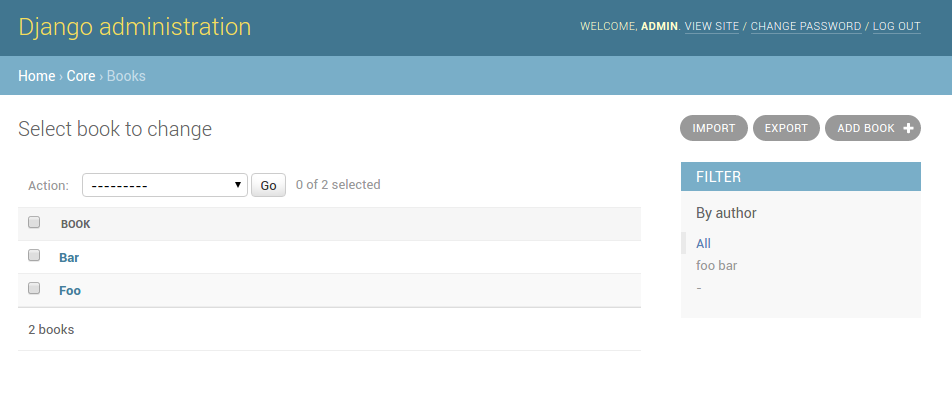
# 1. Django Admin基础与第三方集成概述
在本章中,我们将带您入门Django Admin的基本使用,并且概览如何将第三方工具集成到Django Admin中以增强其功能和用户体验。Django Admin是Django框架自带的模型后台管理工具,它为开发者提供了创建、读取、更新和删除(CRUD)操作的简便界面。尽管Django Admin提供了一套功能丰富的管理界面,但在实际应用中,我们往往需要通过定制和集成来满足特定的业务需求。本章将为您提供Django Admin与第三方工具集成的必要性和基本方法。
首先,我们会简要介绍Django Admin的核心功能,帮助您快速上手。随后,我们会探讨如何将第三方工具集成到Admin中,包括权限控制、表单小部件、验证以及模型工具等方面的实践操作,从而使得Django Admin更加符合您的业务需求。本章旨在为希望进一步深入了解Django Admin高级特性和第三方集成的读者提供基础理论和实践指南。
```python
# 示例代码块:Django Admin注册模型的基本方式
from django.contrib import admin
from .models import MyModel
@admin.register(MyModel)
class MyModelAdmin(admin.ModelAdmin):
list_display = ('field1', 'field2', 'created_at')
```
通过本章的学习,您将能够掌握Django Admin的基础知识,并能够开始对后台管理进行基本的第三方集成。接下来的章节将深入探讨定制化和高级优化技巧。
# 2. Django Admin界面定制技巧
## 2.1 理解Django Admin界面构成
### 2.1.1 自定义ModelAdmin类
Django Admin 的核心是 ModelAdmin 类,它将 Django 模型映射到后台管理界面。通过创建一个继承自 `admin.ModelAdmin` 的自定义类,我们可以控制模型在 Django 管理后台的行为和展示方式。
```python
from django.contrib import admin
from .models import MyModel
class MyModelAdmin(admin.ModelAdmin):
list_display = ('field1', 'field2', 'field3')
search_fields = ('field1', 'field2')
list_filter = ('field2',)
```
在上面的代码中,我们定义了一个名为 `MyModelAdmin` 的类,并设置了 `list_display` 以确定在列表页显示的字段;`search_fields` 指定了可以在 Admin 的搜索框中搜索的字段;`list_filter` 用于添加过滤器侧边栏,便于对特定字段进行过滤。
创建自定义 ModelAdmin 类后,需要在 `admin.py` 中将其注册到对应的模型上:
```***
***.register(MyModel, MyModelAdmin)
```
这样,当访问 Django Admin 站点时,可以看到按照我们的要求定制的管理界面。自定义 ModelAdmin 类还允许我们定义排序方式、添加额外的列表操作、控制表单行为等。
### 2.1.2 利用ModelAdmin选项优化界面
ModelAdmin 类提供了大量选项用于优化 Admin 界面,使其更适合特定的应用需求。除了上节提到的几个选项外,还有诸如 `exclude`, `readonly_fields`, `fields`, 和 `prepopulated_fields` 等。这些选项能够让管理员在创建、编辑和查看对象时有不同的体验。
例如,若想要使某个字段只在添加新记录时可编辑,在编辑现有记录时变为只读,可以使用 `readonly_fields`:
```python
class MyModelAdmin(admin.ModelAdmin):
...
readonly_fields = ('field4',) # 在编辑表单中,field4 将是只读的
...
```
而选项 `exclude` 可以用于指定不包括在默认的表单中的字段:
```python
class MyModelAdmin(admin.ModelAdmin):
...
exclude = ('field5',) # field5 将不会出现在添加/编辑表单中
...
```
在定制 Admin 界面时,合理使用这些选项能够大大提高界面的可用性和效率,同时也能减少管理员出错的机会。
## 2.2 扩展Django Admin功能
### 2.2.1 通过Admin actions增强管理功能
Admin actions 是 Django Admin 中用于对一组对象执行批量操作的函数。它们为管理员提供了强大的工具,能够同时对多个对象执行任务,比如激活或禁用一组用户。
创建一个 admin action,首先定义一个函数,该函数接受三个参数:当前的 `request` 对象、`queryset`(即将执行操作的对象集合),以及一个额外的参数,如果有的话:
```python
def make_active(modeladmin, request, queryset):
queryset.update(is_active=True)
make_active.short_description = "Mark selected users as active"
```
这里 `make_active` 函数将传入的 `queryset` 中所有对象的 `is_active` 字段设置为 True。`short_description` 是在后台管理界面中显示给管理员的操作名称。
接下来,将此 action 添加到 ModelAdmin 类中:
```python
class UserAdmin(admin.ModelAdmin):
...
actions = [make_active]
```
注册 `UserAdmin` 后,动作 `make_active` 将出现在操作下拉菜单中,并可供选择执行。Actions 是一种快速且有效的方法来扩展 Admin 功能,特别是处理需要对多个对象重复执行相同操作的场景。
### 2.2.2 使用Inlines和TabularInline添加关联对象
在很多情况下,我们需要在一个管理页面内编辑或查看多个相关的模型。通过 `Inlines`,Django 允许我们在一个父对象页面内管理其子对象,从而使得操作更加直观便捷。
有两种主要的内联方式:`TabularInline` 和 `StackedInline`。`TabularInline` 将相关对象以表格形式展示,而 `StackedInline` 则是垂直堆叠的形式。根据需要选择合适的一种。
以下是一个 `TabularInline` 的例子:
```python
from django.contrib import admin
from .models import Book, Author
class BookInline(admin.TabularInline):
model = Book
extra = 1 # 在内联部分额外显示的行数
class AuthorAdmin(admin.ModelAdmin):
inlines = [BookInline]
***.register(Author, AuthorAdmin)
```
在 `AuthorAdmin` 中,通过 `inlines` 属性将 `BookInline` 类注册进去。这样,每当用户访问作者的编辑页面时,就可以直接在页面上编辑和查看其书籍信息,而无需跳转到另一个页面。
### 2.2.3 管理员站点中间件的使用与自定义
Django Admin 中间件允许开发者对请求处理流程进行干预,从而对管理站点的行为进行自定义。中间件可以用于记录日志、权限检查、性能监控等。
在 `settings.py` 文件中,中间件被定义在 `MIDDLEWARE` 列表中。一个自定义中间件的示例可能是下面这样:
```python
from django.contrib import admin
from django.utils.deprecation import MiddlewareMixin
class AdminLogMiddleware(MiddlewareMixin):
def process_request(self, request):
if request.path.startswith('/admin'):
print(f"Admin action logged: {request.path}")
```
上面的中间件 `AdminLogMiddleware` 在请求路径以 `/admin` 开头时,会打印一条日志信息。这只是一个简单的例子,实际上,你可以通过中间件访问请求对象,判断请求的类型,进行权限检查,以及执行其他逻辑。
将中间件添加到 `MIDDLEWARE` 列表后,每次管理员访问 Admin 站点时,中间件都会执行定义的逻辑。自定义中间件对于提升系统的安全性和性能监控是非常有用的。
## 2.3 用户体验优化实践
### 2.3.1 自定义表单和过滤器
在 Django Admin 中,自定义表单可用于增强数据的输入体验,例如添加新的表单字段、修改现有字段属性,或对表单进行验证。自定义表单通常继承自 `forms.ModelForm`,然后在 `admin.py` 中指定。
```python
from django import forms
from .forms import CustomModelForm
from .models import MyModel
from django.contrib import admin
class MyModelAdmin(admin.ModelAdmin):
form = ***
***.register(MyModel, MyModelAdmin)
```
过滤器的自定义则通常用于优化搜索功能,例如,如果一个模型中有日期字段,可以创建一个自定义的过滤器来允许用户根据日期范围进行过滤:
```python
from django.contrib.admin import SimpleListFilter
class DateRangeFilter(SimpleListFilter):
title = 'date'
parameter_name = 'date_range'
def lookups(self, request, model_admin):
return (
('today', 'Today'),
('yesterday', 'Yesterday'),
('this_week', 'This Week'),
('last_week', 'Last Week'),
)
def queryset(self, request, queryset):
if self.value() == 'today':
return queryset.filter(date.today())
if self.value() == 'yesterday':
return queryset.filter(date=yesterday())
# 其他过滤器的实现...
```
创建过滤器之后,需要在 `admin.py` 中声明使用这个过滤器。
### 2.3.2 资源优化与异步操作
为了提高用户界面的响应速度和整体性能,Django Admin 站点中的资源优化同样重要。资源优化包括压缩静态文件、使用缓存策略以及采用异步操作。
异步操作可以借助 Django 的 `Celery` 扩展包实现,通过将耗时的任务放到后台异步处理,可以显著提高响应速度。例如,在处理上传的大型文件时,可以先将文件保存到服务器,然后返回成功响应,而文件处理任务则通过 Celery 异步执行。
以下是一个简单的 Celery 异步任务例子:
```python
from celery import shared_task
@shared_task
def process_large_file(file_path):
# 这里是处理上传文件的逻辑
# ...
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Django Admin 秘籍》专栏是一份全面深入的指南,旨在帮助开发者打造高效且可定制的 Django 后台管理系统。从基础概念到高级定制化,从源码探秘到性能调优,专栏涵盖了 Django Admin 的方方面面。
专栏深入探讨了 Django Admin 的插件系统、国际化和本地化、数据安全、权限管理、API 设计、表单处理、监控和日志、第三方集成、自动化测试、自定义方法和性能调优等主题。通过对这些主题的深入分析,开发者可以掌握 Django Admin 的工作原理,并根据自己的需求进行定制和优化。
本专栏旨在为 Django 开发者提供全面的知识和实践指南,帮助他们构建健壮、可扩展且用户友好的后台管理系统,从而提升应用程序的整体质量和用户体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【单片机手势识别终极指南】:从零基础到项目实战
# 摘要
本文对单片机手势识别系统进行了全面的探讨,从基础理论到实践应用,涵盖了手势识别技术的原理、系统硬件配置、编程基础、算法实现以及系统集成与测试。重点分析了传感器技术、图像处理、机器学习模式识别在手势识别中的应用,并对单片机的选择、编程要点、硬件和软件集成技术进行了详细介绍。通过多个实战应用案例,本文展示了手势识别技术在智能家居、交互式娱乐以及工业自动化等领域的潜力与挑战,为相关领域的研究和开发提供了宝贵的参考和指导。
# 关键字
手势识
【圆周率的秘密】:7种古法到现代算法的演进和Matlab实现
# 摘要
圆周率是数学和科学领域中基础而关键的常数,历史上不断推动计算技术的发展。本文首先回顾了圆周率的历史和古代计算方法,包括阿基米德的几何逼近法、中国古代的割圆术以及古代印度和阿拉伯的算法。接着,本文探讨了现代算法,如无穷级数方法、随机算法和分数逼近法,及其在Matlab环境下的实现。文章还涵盖了Matlab环境下圆周率计算的优化与应用,包括高性能计算的实现、圆周率的视觉展示以及计算误差分析。最后,本文总结了圆周率在现代科学、工程、计算机科学以及教育中的广泛应用,展示了其跨学科的重要性。本文不仅提供了圆周率计算的历史和现代方法的综述,还强调了相关技术的实际应用和教育意义。
# 关键字
圆
RESURF技术深度解析:如何解决高压半导体器件设计的挑战
# 摘要
RESURF(Reduced Surface Field)技术作为提高高压器件性能的关键技术,在半导体物理学中具有重要的地位。本文介绍了RESURF技术的基础原理和理论基础,探讨了其物理机制、优化设计原理以及与传统高压器件设计的对比。通过对RESURF技术在高压器件设计中的应用、实践挑战、优化方向以及案例研究进行分析,本文阐述了RESURF技术在设计流程、热管理和可靠性评估中的
LDPC码基础:专家告诉你如何高效应用这一纠错技术
# 摘要
低密度奇偶校验(LDPC)码是一种高效的纠错码技术,在现代通信系统中广泛应用。本文首先介绍了LDPC码的基本原理和数学模型,然后详细探讨了LDPC码的两种主要构造方法:随机构造和结构化构造。随后,文章深入分析了LDPC码的编码和译码技术,包括其原理和具体实施方法。通过具体应用实例,评估了LDPC码在通信系统和其他领域的性能表现。最后,文章展望了LDPC码未来的发展方向和面临的挑战,强调了技术创新和应用领域拓展的重要性。
# 关键字
LDPC码;纠错原理;码字结构;编码技术;译码技术;性能分析
参考资源链接:[硬判决与软判决:LDPC码译码算法详解](https://wenku.c
【POS系统集成秘籍】:一步到位掌握收银系统与小票打印流程
# 摘要
本文综合介绍了POS系统集成的全面概述,涵盖了理论基础、实践操作及高级应用。首先,文中对POS系统的工作原理、硬件组成、软件架构进行了详细分析,进而探讨了小票打印机制和收银流程的逻辑设计。其次,作者结合具体实践,阐述了POS系统集成的环境搭建、功能实现及小票打印程序编写。在高级应用方面,文章重点讨论了客户管理、报表系统、系统安全和异常处理。最后,本文展望了未来POS系统的发展趋势,包括
【MinGW-64终极指南】:打造64位Windows开发环境的必备秘籍

# 摘要
本文详细介绍了MinGW-64及其在64位Windows操作系统中的应用。文章首先概述了MinGW-64的基本概念和它在现代软件开发中的重要作用。随后,文章指导读者完成MinGW-64的安装与配置过程,包括系统要求、环境变量设置、编译器选项配置以及包和依赖管理。第三章深入探讨了如何使用MinGW-64进行C/C++的开发工作,包括程序编写、编译、项目优化、性能分析及跨平台开发
【爱普生L3110驱动秘密】:专业技术揭秘驱动优化关键

# 摘要
本文对爱普生L3110打印机驱动进行了全面分析,涵盖了驱动概述、优化理论基础、优化实践、高级应用以及未来展望。首先介绍了驱动的基本概念和优化的重要性,接着深入探讨了驱动程序的结构和优化原则。在实践章节中,本文详细阐述了安装配置、性能调优及故障诊断的技巧。此外,还讨论了驱动的定制化开发、与操作系统的兼容性调整以及安全性的加固。最后,文章展望了驱动技术的发展趋势,社区合作的可能性以及用户体验的
DSP6416编程新手指南:C语言环境搭建与基础编程技巧

# 摘要
本文详细介绍了DSP6416平台的基础知识与C语言实践技巧,包括环境搭建、基础语法、硬件接口编程以及性能优化与调试方法。首先,本文概述了DSP6416平台特性,并指导了C语言环境的搭建流程,包括交叉编译器的选择和配置、开发环境的初始化,以及如何编写并运行第一个C语言程序。随后,深入探讨了C语言的基础知识和实践,着重于数据类型、控制结构、函数、指针以及动态内存管理。此外,
深入理解Lingo编程:@text函数的高级应用及案例解析

# 摘要
Lingo编程语言作为一种专业工具,其内置的@text函数在文本处理方面具有强大的功能和灵活性。本文首先概述了Lingo编程语言及其@text函数的基础知识,包括定义、功能、语法结构以及应用场景。接着,深入探讨了@text函数的高级特性,例如正则表达式支持、多语言国际化处理以及性能优化技巧。通过案例分析,展示了@text函数在数据分析、动态文本生成及复杂文本解析中的实际应用。此外,文章还研究了@text函数与其他编程语言的集成方法,
Keil环境搭建全攻略:一步步带你添加STC型号,无需摸索

# 摘要
本文旨在介绍Keil开发环境的搭建及STC系列芯片的应用。首先,从基础角度介绍了Keil环境的搭建,然后深入探讨了STC芯片的特性、应用以及支持的软件包。随后,详细描
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )