STL模板中的容器类详解
发布时间: 2023-12-16 06:28:42 阅读量: 35 订阅数: 34 

STL容器的详细描述
# 1. 引言
## STL模板简介
STL(Standard Template Library)是C++的一部分,是一组模板类和函数的集合,用于提供通用的数据结构和算法,使程序开发更加高效和可靠。STL的设计理念是尽量通过模板来实现通用性,使得代码可以适用于不同的数据类型。STL包含了各种容器类、算法和迭代器,为C++程序提供了大量的数据结构和操作方法。
## 容器类在STL中的作用和重要性
在STL中,容器类是一种用来存储和管理数据的抽象概念,是STL的核心组件之一。容器类提供了一种高效的数据组织方式,并且封装了数据的存储和访问方式,使得程序员在开发中可以更加专注于业务逻辑的实现,而不需要过多关注数据的底层细节。
容器类在STL中起到了连接数据和算法的桥梁作用,它与算法和迭代器紧密配合,可以实现各种高效的数据操作和算法实现。通过使用STL提供的容器类,程序员可以更加简洁地编写代码,并且能够充分利用STL提供的丰富的数据结构和算法,提高开发效率和程序性能。
在接下来的章节中,我们将介绍STL中常用的几种容器类,包括顺序容器类、关联容器类和适配器容器类,以及它们的特点和用法。
# 2. 顺序容器类
顺序容器是STL中最常用的容器类之一,它按照元素在容器中的顺序进行存储和访问。STL提供了多种顺序容器类,其中包括vector、list和deque等。每种容器类都有自己的特点和用途,在不同的场景下选择合适的容器类可以提高程序的效率和性能。
### 2.1 vector容器类的特点和用法
vector容器是STL中最常用的顺序容器之一,它实现了动态数组的功能,可以动态地增加或删除元素。vector中的元素在内存中是连续存储的,可以通过下标直接访问元素,因此访问效率较高。
#### 示例代码
```java
import java.util.Vector;
public class VectorExample {
public static void main(String[] args) {
// 创建一个空的vector
Vector<String> vector = new Vector<>();
// 添加元素
vector.add("Apple");
vector.add("Banana");
vector.add("Orange");
// 获取元素个数
int size = vector.size();
System.out.println("Vector size: " + size);
// 访问元素
String fruit = vector.get(1);
System.out.println("Second fruit: " + fruit);
// 修改元素
vector.set(0, "Grapes");
System.out.println("Modified vector: " + vector);
// 删除元素
vector.remove(2);
System.out.println("Modified vector: " + vector);
}
}
```
#### 代码说明
1. 首先,我们通过`Vector<String> vector = new Vector<>();`创建一个空的vector容器。
2. 然后,我们使用`vector.add("Apple")`、`vector.add("Banana")`和`vector.add("Orange")`向vector容器中添加元素。
3. 接着,我们使用`vector.size()`获取vector中元素的个数,使用`vector.get(1)`获取索引为1的元素。
4. 使用`vector.set(0, "Grapes")`修改索引为0的元素为"Grapes"。
5. 最后,使用`vector.remove(2)`删除索引为2的元素。
#### 运行结果
```
Vector size: 3
Second fruit: Banana
Modified vector: [Grapes, Banana, Orange]
Modified vector: [Grapes, Banana]
```
### 2.2 list容器类的特点和用法
list容器是另一种常用的顺序容器,它实现了双向链表的功能。与vector不同,list中的元素可以在任意位置进行快速插入和删除操作,但是访问元素的效率较低。
#### 示例代码
```python
fruits = ["Apple", "Banana", "Orange"]
# 添加元素
fruits.append("Grapes")
fruits.insert(1, "Cherry")
# 获取元素个数
size = len(fruits)
print("List size:", size)
# 访问元素
first_fruit = fruits[0]
print("First fruit:", first_fruit)
# 修改元素
fruits[2] = "Strawberry"
print("Modified list:", fruits)
# 删除元素
fruits.remove("Apple")
print("Modified list:", fruits)
```
#### 代码说明
1. 首先,我们创建一个list容器,并向其中添加一些元素。
2. 使用`len(fruits)`获取list中元素的个数。
3. 使用下标`[0]`访问第一个元素。
4. 使用`fruits[2] = "Strawberry"`修改索引为2的元素。
5. 使用`fruits.remove("Apple")`删除指定元素。
#### 运行结果
```
List size: 5
First fruit: Apple
Modified list: ['Apple', 'Cherry', 'Strawberry', 'Banana', 'Orange', 'Grapes']
Modified list: ['Cherry', 'Strawberry', 'Banana', 'Orange', 'Grapes']
```
### 2.3 deque容器类的特点和用法
deque容器是double-ended queue(双端队列)的缩写,它是一种在两端进行插入和删除操作的顺序容器。deque容器在内存中使用连续存储和分块存储的结构,可以高效地在两端进行插入和删除操作,同时也支持随机访问。
#### 示例代码
```javascript
const deque = require('deque');
// 创建一个空的deque
const d = deque();
// 在两端添加元素
d.push('Apple');
d.unshift('Banana');
d.push('Orange');
// 获取元素个数
const size = d.size();
console.log('Deque size:', size);
// 访问元素
const firstFruit = d.front();
const lastFruit = d.back();
console.log('First fruit:', firstFruit);
console.log('Last fruit:', lastFruit);
// 修改元素
d.set(1, 'Grapes');
console.log('Modified deque:', d);
// 删除元素
d.pop();
console.log('Modified deque:', d);
```
#### 代码说明
1. 首先,我们使用`deque()`函数创建一个空的deque容器。
2. 使用`d.push('Apple')`和`d.unshift('Banana')`在deque的两端添加元素。
3. 使用`d.size()`获取deque中元素的个数。
4. 使用`d.front()`和`d.back()`访问deque的第一个元素和最后一个元素。
5. 使用`d.set(1, 'Grapes')`修改索引为1的元素为'Grapes'。
6. 使用`d.pop()`删除deque的最后一个元素。
#### 运行结果
```
Deque size: 3
First fruit: Banana
Last fruit: Orange
Modified deque: [ 'Banana', 'Grapes', 'Orange' ]
Modified deque: [ 'Banana', 'Grapes' ]
```
顺序容器类包括vector、list和deque,每种容器类都有自己的特点和用途。在实际应用中,根据具体的需求选择合适的容器类可以提高程序的效率和性能。
# 3. 关联容器类
关联容器类是STL中的一类重要容器,它们以键-值对的形式存储数据,并以键作为索引进行快速查找。常见的关联容器类有map、set、multimap和multiset。接下来我们将分别介绍它们的特点和用法。
#### map容器类的特点和用法
map是一种关联容器,它存储的数据是以键值对形式存储的,并且会根据键的顺序进行自动排序。每个键在map中是唯一的,因此插入相同键的数据会覆盖原有键对应的值。map的内部实现是基于红黑树,所以查找、插入、删除操作的时间复杂度都是O(logn)。
```cpp
#include <iostream>
#include <map>
#include <string>
int main() {
std::map<int, std::string> m;
// 插入键值对
m.insert(std::make_pair(1, "apple"));
m[2] = "banana";
// 查找键对应的值
std::cout << "Value of key 1: " << m[1] << std::endl;
// 删除键值对
m.erase(2);
return 0;
}
```
**代码说明:**
- 创建了一个map容器m,键的类型为int,值的类型为string。
- 通过insert和[]操作符插入了两组键值对。
- 使用[]操作符查找键为1的值,并输出到控制台。
- 使用erase方法删除了键为2的值。
#### set容器类的特点和用法
set是一种关联容器,它存储的数据是一组唯一的值,并且会根据值的大小进行自动排序。set的内部实现也是基于红黑树,因此查找、插入、删除操作的时间复杂度同样是O(logn)。
```cpp
#include <iostream>
#include <set>
int main() {
std::set<int> s;
// 插入值
s.insert(3);
s.insert(1);
s.insert(2);
// 遍历set
for (auto it = s.begin(); it != s.end(); ++it) {
std::cout << *it << " ";
}
return 0;
}
```
**代码说明:**
- 创建了一个set容器s,存储int类型的数据。
- 使用insert方法插入了三个不同的值。
- 使用迭代器遍历set并输出到控制台。
#### multimap和multiset容器类的特点和用法
multimap和multiset与map和set的区别在于,它们允许存储重复的键。其余特点和用法与map和set基本一致,只是在插入和查找操作上会有所区别,需要注意理解和使用。
关联容器类提供了高效的查找、插入和删除操作,非常适合需要频繁查找和大量数据存储的场景。接下来我们将介绍适配器容器类。
# 4. 适配器容器类
适配器容器类是STL中的一类特殊容器,它们基于顺序容器或关联容器,提供了不同的接口和功能,使它们更适合特定的应用场景。适配器容器类包括stack(栈)、queue(队列)和priority_queue(优先队列),它们分别提供了后进先出(LIFO)、先进先出(FIFO)和按优先级排列的数据存储和访问方式。
#### 4.1 stack容器适配器的特点和用法
stack是一个后进先出(LIFO)的容器,它基于顺序容器(如deque或vector)实现。在使用stack时,我们只能从容器的顶部添加和移除元素。stack提供了push、pop、top等操作,可以方便地进行栈的操作。
```python
# Python示例代码
from queue import LifoQueue
# 创建一个栈
stack = LifoQueue()
# 向栈中压入元素
stack.put(1)
stack.put(2)
stack.put(3)
# 从栈中弹出元素
print(stack.get()) # 输出3
print(stack.get()) # 输出2
```
**代码总结:** 上述代码演示了如何使用Python的queue模块来实现stack容器适配器,通过put和get方法进行元素的压入和弹出,实现了LIFO的数据存储和访问方式。
**结果说明:** 代码运行结果为先弹出3,再弹出2。
#### 4.2 queue容器适配器的特点和用法
queue是一个先进先出(FIFO)的容器,它同样基于顺序容器(如deque或list)实现。queue支持在容器的前端插入元素,在末尾移除元素,提供了push、pop、front等操作,适用于需要按照FIFO方式处理数据的场景。
```java
// Java示例代码
import java.util.LinkedList;
import java.util.Queue;
// 创建一个队列
Queue<Integer> queue = new LinkedList<>();
// 向队列中添加元素
queue.add(1);
queue.add(2);
queue.add(3);
// 从队列中移除元素
System.out.println(queue.poll()); // 输出1
System.out.println(queue.poll()); // 输出2
```
**代码总结:** 以上Java代码展示了如何使用LinkedList来实现queue容器适配器,通过add和poll方法进行元素的添加和移除,实现了FIFO的数据存储和访问方式。
**结果说明:** 代码运行结果为先移除1,再移除2。
#### 4.3 priority_queue容器适配器的特点和用法
priority_queue是一个按照元素优先级排序的容器,它通常基于vector实现。priority_queue内部的元素会根据其优先级自动排序,每次取出的元素都是当前优先级最高的元素。
```go
// Go示例代码
package main
import (
"container/heap"
"fmt"
)
// 定义一个int类型的堆
type IntHeap []int
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] }
func (h IntHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *IntHeap) Push(x interface{}) {
*h = append(*h, x.(int))
}
func (h *IntHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
*h = old[:n-1]
return x
}
func main() {
h := &IntHeap{2, 1, 5}
heap.Init(h)
heap.Push(h, 3)
fmt.Printf("优先队列中的所有元素:%v\n", h)
fmt.Printf("取出优先队列中最小的元素:%v\n", heap.Pop(h))
}
```
**代码总结:** 以上Go示例代码演示了如何使用container/heap包来实现priority_queue容器适配器,定义了IntHeap类型并实现了heap.Interface接口,通过heap.Init和heap.Push来添加元素并实现自动排序,通过heap.Pop来取出当前优先级最高的元素。
**结果说明:** 代码运行结果为取出的最小元素为1。
适配器容器类提供了不同的数据存储和访问方式,能够满足不同的应用需求,对于栈、队列和优先队列等场景提供了便利的解决方案。
# 5. 容器类的常用方法和算法
在本节中,我们将介绍STL容器类常用的方法和算法,包括迭代器的使用和常见操作、容器类的插入、删除和查找操作,以及容器类特有的算法和操作函数。
#### 迭代器的使用和常见操作
迭代器是STL中用于遍历容器元素的重要工具,它类似于指针,可以指向容器中的元素,并支持++、--等操作符。STL中提供了多种类型的迭代器,包括begin()和end()返回的起始和结束迭代器,以及const_iterator和reverse_iterator等类型。
让我们以vector为例,演示迭代器的基本用法:
```python
# Python代码示例
# 创建一个包含整数的vector
my_vector = [1, 2, 3, 4, 5]
# 使用迭代器遍历vector
it = iter(my_vector)
while True:
try:
value = next(it)
print(value)
except StopIteration:
break
```
代码解释:
- 我们首先创建了一个包含整数的vector。
- 然后使用iter()函数获取迭代器,并通过next()函数逐个访问vector中的元素。
- 当遍历完所有元素后,StopIteration异常被捕获,循环结束。
#### 容器类的插入、删除和查找操作
STL容器类提供了丰富的插入、删除和查找操作,比如insert()用于插入元素,erase()用于删除元素,find()用于查找元素等。这些操作使得在容器中进行元素的增删改查变得非常便利。
让我们以list为例,演示插入、删除和查找操作的基本用法:
```java
// Java代码示例
import java.util.*;
public class Main {
public static void main(String[] args) {
// 创建一个包含整数的list
List<Integer> my_list = new LinkedList<>();
my_list.add(1);
my_list.add(2);
my_list.add(3);
// 在索引为1的位置插入元素4
my_list.add(1, 4);
// 删除索引为2的元素
my_list.remove(2);
// 查找元素3的索引
int index = my_list.indexOf(3);
System.out.println("Index of 3: " + index);
}
}
```
代码解释:
- 我们首先创建了一个包含整数的list,并进行了一些元素的插入、删除和查找操作。
- add()用于在指定位置插入元素,remove()用于删除指定位置的元素,indexOf()用于查找元素的索引。
#### 容器类特有的算法和操作函数
STL容器类提供了丰富的算法和操作函数,如排序、反转、合并等,这些函数可以帮助我们对容器中的元素进行各种操作,提高了开发效率。
让我们以deque为例,演示排序和反转操作的基本用法:
```go
package main
import (
"fmt"
"container/list"
)
func main() {
// 创建一个包含整数的deque
my_deque := list.New()
my_deque.PushBack(3)
my_deque.PushBack(1)
my_deque.PushBack(2)
// 对deque中的元素进行排序
// 这里因为Go标准库中没有提供deque排序函数,所以我们使用list来演示
var sorted_list = make([]int, my_deque.Len())
i := 0
for e := my_deque.Front(); e != nil; e = e.Next() {
sorted_list[i] = e.Value.(int)
i++
}
fmt.Println("Before sorting:", sorted_list)
sort.Ints(sorted_list)
fmt.Println("After sorting:", sorted_list)
// 对deque中的元素进行反转
var reversed_list = make([]int, my_deque.Len())
i = 0
for e := my_deque.Back(); e != nil; e = e.Prev() {
reversed_list[i] = e.Value.(int)
i++
}
fmt.Println("Before reversing:", reversed_list)
reverse(reversed_list)
fmt.Println("After reversing:", reversed_list)
}
func reverse(arr []int) {
for i, j := 0, len(arr)-1; i < j; i, j = i+1, j-1 {
arr[i], arr[j] = arr[j], arr[i]
}
}
```
代码解释:
- 我们首先创建了一个包含整数的deque,使用list模拟了deque的排序和反转操作。
- 对deque中的元素进行排序时,使用sort.Ints()函数对slice进行排序。
- 对deque中的元素进行反转时,自定义了reverse()函数来实现。
通过本节的介绍,我们了解了STL容器类常用的方法和算法,掌握了对容器进行常见操作的基本技巧。在实际开发中,熟练运用这些方法和算法,能够大大提高代码的效率和可维护性。
# 6. 总结和展望
STL(Standard Template Library)作为一种通用的程序库,提供了丰富的容器类和算法,为开发者提供了方便和高效的工具。在这篇文章中,我们介绍了STL中常用的容器类以及它们的特点和用法。
容器类是STL的核心组成部分,它们提供了不同的数据结构和操作方式,以满足各种不同的需求。在顺序容器类中,我们了解了vector、list和deque的特点和用法。vector是一个动态数组,适合随机访问元素;list是一个双向链表,适合插入和删除操作;deque是一个双端队列,可以在两端进行插入和删除。
在关联容器类中,我们介绍了map、set、multimap和multiset的特点和用法。map是一种键值对的容器,可以根据键进行快速查找;set是一种集合,可以快速判断元素是否存在;multimap和multiset是允许重复键的容器。
此外,适配器容器类提供了对底层容器的适配,包括stack、queue和priority_queue。stack是一个后进先出(LIFO)的容器适配器;queue是一个先进先出(FIFO)的容器适配器;priority_queue是一个优先级队列,按照指定的优先级进行元素访问。
在第五章节中,我们介绍了容器类的常用方法和算法。通过使用迭代器,我们可以访问容器类中的元素,并进行常见的操作。我们还学习了如何在容器类中进行插入、删除和查找操作,以及一些容器类特有的算法和操作函数。
STL容器类具有简单易用、效率高和可移植性强的优点,可以大大提高开发效率和代码质量。然而,STL也有一些局限性,例如对于大规模数据的处理效率不高,以及一些特殊需求可能无法满足。
总结起来,STL容器类是C++开发中非常重要的组成部分,掌握了容器类的用法和特点,可以为我们的开发工作提供很大的帮助。在后续的学习和应用中,我们可以进一步研究和了解容器类的实现原理,以及使用更高级的容器类和算法来解决复杂的问题。
希望这篇文章对你对STL容器类的学习和应用有所帮助!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在深入探讨C++标准模板库(STL)中的各种模板使用技巧及相关知识。通过系列文章的介绍,读者将了解STL模板的基本操作,包括容器类的详细介绍、迭代器的灵活运用以及算法库的高级用法。此外,还将深入讨论STL模板中的数组与容器的比较、字符串处理技巧、队列与栈的详细使用方法,以及堆、优先队列、位操作、布尔代数等重要主题。随着文章的深入,读者还将了解到STL模板中函数对象、适配器、序列容器、关联容器的操作技巧,以及泛型编程思想、迭代器分类与应用、算法库高级使用方法等重要概念,同时还将学习到STL模板中函数对象、Lambda表达式、字符串处理等高级技巧。通过本专栏的学习,读者将掌握STL模板的全面知识体系,为C++编程技能的提升奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PIFA天线设计全攻略:从理论到实践的深度解析
# 摘要
本论文系统地探讨了平面倒F天线(PIFA)的基础理论、关键参数、设计仿真、制作测试及应用案例研究。首先介绍PIFA天线的基础理论和关键参数,包括电磁场理论基础、频率特性、辐射模式和天线增益。其次,详细描述了PIFA天线的设计与仿真流程,重点分析了天线尺寸优化方法和仿真结果验证。随后,探讨了PIFA天线的制作过程和实验测量方法,并针对设计优化后的天线进行了再测试和评估。最后,通过具体应用案例,分析了PIFA在无线通信中的应用
L-Edit版图设计进阶秘籍:PMOS版图精细调整与性能提升

# 摘要
本文系统地介绍了L-Edit版图设计软件在PMOS器件结构设计中的应用,覆盖了版图设计的基础知识、精细调整技术以及设计实践。首先概述了L-Edit版图设计的基本操作和PMOS器件的工作原理,随后探讨了PMOS版图设计中的关键考量因素和性能影响。接着,本文详细阐述了版图参数的精确调整技术、高级版图优化方法以及应力工程在版图设计中的应用。第四章通过案例
从零开始:Nginx下中文URL的完美适配指南(权威解读版)

# 摘要
本文对Nginx服务器处理中文URL的机制进行了深入探讨,涵盖从基础安装配置到高级优化技巧的各个方面。首先介绍了Nginx的基本概念和安装配置,随后详述了中文URL的编码原理和Nginx内部处理机制。第二章到第四章着重于中文URL适配的具体实现,包括使用正则表达式处理、配置虚拟主机以及性能调优和安全性考虑等。最后,文章展望了Nginx处理中文URL的未来趋势,并分享了社区资源和最佳实践,旨在为构建中文友好的Web
揭秘PROTEL 99 SE字符库:汉字添加与自定义全攻略
# 摘要
本文围绕PROTEL 99 SE字符库的建立、管理及高级定制展开了全面的探讨。首先介绍了PROTEL字符库的基础知识,重点阐述了汉字添加到字符库的理论与实践,包括汉字编码理论、字符库结构及添加汉字的具体步骤。接着,文章详细介绍了自定义字符库的创建、管理和维护,强调了其在满足特定设计需求中的重要性。此外,文章通过实例分析,探讨了汉字在PCB设计中的应用和特殊字符显示问题的处理方法。最后,文章介绍了高级字符库定制技巧,如宏命令和脚本的使用,以及第三方支持和自定义功能的扩展,提供了复杂项目中字符库应用的案例研究。本文为PCB设计人员提供了实用的字符库管理知识,有助于提高设计效率和质量。
【内存管理不求人】:揭秘CHIBIOS-3.0.4内存分配与释放

# 摘要
本文针对CHIBIOS-3.0.4操作系统中的内存管理机制进行深入探讨,分析了内存分配与释放的原理、策略和性能评估方法。介绍了不同内存分配算法如首次适应算法、最佳适应算法及快速适应算法,并探讨了内存碎片问题和效率测量。文章还阐述了内存释放的基本原理、策略和
【ABB机器人操作速成课】:新手必读的实用指南与高效实践
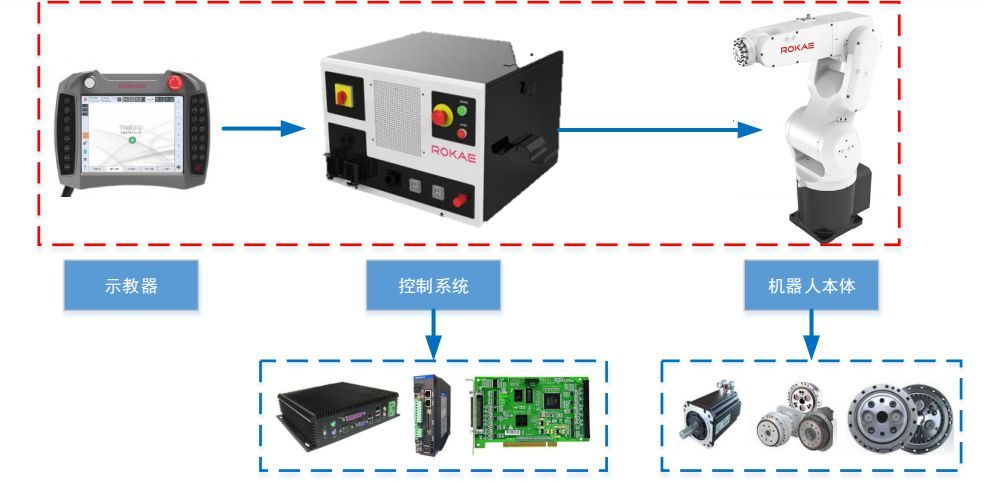
# 摘要
本文全面介绍了ABB机器人的基础知识、编程技巧、实际操作方法、行业应用案例以及高级编程与功能扩展。首先概述了ABB机器人的基本概念及其RAPID编程语言,随后深入探讨了编程环境的使用、机械臂操作的技巧、任务编程与故障处理。文章进一步通过实际行业应用案例,展示了ABB机器人在汽车制造业、电子消费品行业中的具体应用,并展望了其在医疗健康
【深入理解INCA架构】:硬件调试领域的终极武器

# 摘要
本文全面介绍INCA架构的核心概念、理论基础、关键技术、实践应用以及高级特性。INCA架构作为一种创新的调试与数据分析系统,在汽车、航空航天和工业自动化等多个领域得到了广泛应用。通过与传统调试方法的对比,本文阐述了INCA架构的独特优势,重点分析了其硬件抽象层、数据采集与处理、
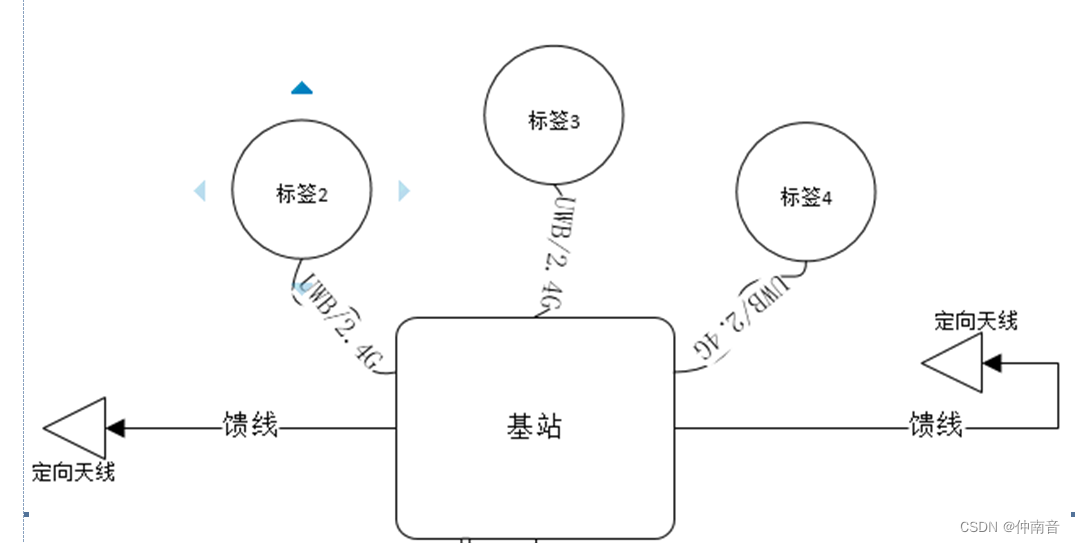
腔体滤波器应用全解析:电子系统中的关键角色与应用案例
# 摘要
腔体滤波器作为电子系统中的关键组件,负责信号的精选和干扰抑制。本文系统性地探讨了腔体滤波器的工作原理、设计要素及其性能评估方法,并详细分析了其在通信系统、雷达系统及其他电子设备中的应用实例。同时,本文也阐述了在设计与制造腔体滤波器时遇到的挑战,例如先进制造工艺、设计软件的应用以及环境适应性和产品标准化问题。最后,本文展望
【MAX96712案例解读】:6个高可靠系统中的实践技巧与故障诊断
# 摘要
本文详细探讨了MAX96712在高可靠系统中的应用,涵盖了从概述到故障诊断、预防与应急处理的全方位分析。首先介绍了MAX96712的基本情况及其在系统可靠性中的作用,随后深入讨论了系统集成的理论基础和实践技巧。第三章专注于故障诊断的基础知识与MAX96712应用,包括故障模式分析和实际案例的诊断实践。第四章着
【Vue.js性能提升秘籍】:四大技巧让四级联动交互飞起来

# 摘要
随着前端技术的不断发展,Vue.js作为一款流行的JavaScript框架,其性能优化成为提升Web应用体验的关键。本文全面探讨了Vue.js在组件优化、数据响应式、交互与渲染性能提升等方面的优化技巧。通过对组件复用、虚拟DOM机制、懒加载技术、数据响应式原理以及交互优化等方面的深入分析,提
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )