Hadoop NameNode全面解析:掌握其作用与优势的5个技巧
发布时间: 2024-10-30 06:01:26 阅读量: 72 订阅数: 45 

hadoop NameNode 源码解析
# 1. Hadoop NameNode概述
Hadoop NameNode 是 Apache Hadoop 分布式存储系统的核心组件,它负责管理文件系统命名空间以及控制外部客户端对文件的访问。作为 Hadoop 分布式文件系统(HDFS)中的主节点,NameNode 是一个关键的服务,它记录了 HDFS 上所有文件的元数据信息,例如文件名、权限、文件属性、文件块信息等。NameNode 的存在使得 HDFS 能够轻松处理大量数据,并在多个计算节点之间进行高效的数据分布与处理。在本章节中,我们将简要概述 NameNode 的基本概念和它在 Hadoop 生态系统中的重要地位,为后续章节深入探讨其工作原理、优化策略及应用场景打下基础。
# 2. Hadoop NameNode的工作原理
在第一章中,我们已经对Hadoop NameNode进行了一个概览性的介绍,而现在我们将深入探讨NameNode的核心工作原理,包括其架构、关键角色、职责以及故障转移机制。通过本章节的学习,读者将能够理解NameNode是如何在Hadoop分布式文件系统(HDFS)中扮演核心角色,以及它是如何处理数据存储和管理的。
## 2.1 Hadoop分布式文件系统的架构
Hadoop分布式文件系统(HDFS)是Hadoop生态系统中的重要组成部分,它为存储大规模数据集提供了高容错性的解决方案。HDFS的架构可以分为NameNode和DataNode两大部分。
### 2.1.1 HDFS的基本组成
HDFS采用主/从(Master/Slave)架构模式,NameNode作为Master节点,DataNode作为Slave节点。
- **NameNode**:管理文件系统的命名空间,记录文件中各个块所在的位置信息。它是HDFS的大脑,负责维护文件系统树及整个文件系统的元数据。用户和其他客户端通过与NameNode交互来获取文件系统的元数据信息。
- **DataNode**:实际存储数据的节点,负责处理文件系统客户端的读写请求,并在本地文件系统上管理数据块(block)。DataNode通常运行在普通的机器上,负责具体的存储工作,以及与实际数据交互。
### 2.1.2 NameNode与DataNode的关系
NameNode和DataNode之间通过心跳和块报告机制来维持状态信息。
- **心跳信号**:DataNode周期性地向NameNode发送心跳信号,告知NameNode自己仍然处于正常工作状态。如果NameNode长时间未收到某个DataNode的心跳信号,则会认为该节点已经宕机或不可达。
- **块报告**:DataNode会定期向NameNode发送存储的数据块信息,这样NameNode就可以验证每个数据块的完整性和副本数量是否符合要求。
## 2.2 NameNode的关键角色与职责
NameNode在HDFS中扮演着至关重要的角色,它负责元数据的管理以及维护系统的高可用性。
### 2.2.1 元数据管理
元数据是关于数据的数据,即描述数据内容和位置等信息的数据。NameNode存储了所有文件系统的元数据,包括:
- 文件和目录信息
- 每个文件的权限和属性
- 文件内容被分割成数据块的列表,以及每个数据块所在的DataNode信息
### 2.2.2 高可用性设计
为了保证系统的高可用性,Hadoop采用了多种设计,如热备和故障转移等。
- **热备份**:Hadoop通过配置Secondary NameNode或者Standby NameNode来实现热备份,以减少故障时的数据丢失和系统停机时间。
- **故障转移**:当主NameNode发生故障时,Secondary NameNode或Standby NameNode可以迅速接管,以保持服务的连续性。
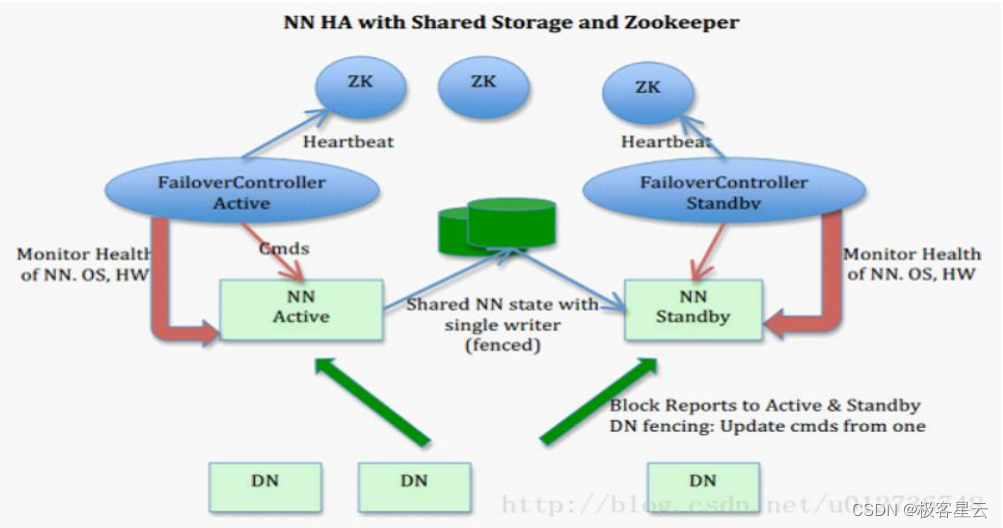
## 2.3 NameNode的故障转移机制
由于NameNode的重要性,其故障转移机制是保证HDFS高可用性的核心。
### 2.3.1 节点故障检测
故障转移开始于故障检测阶段。HDFS通过以下机制来检测NameNode是否故障:
- 心跳监控:DataNode和Secondary NameNode周期性地向主NameNode发送心跳信号。如果在预期时间内,NameNode没有接收到这些心跳,它将记录并监控这些节点的状态。
- 自动故障检测:ZooKeeper等外部系统也可以配置来监控NameNode的健康状况,当检测到主NameNode无法服务时,触发故障转移流程。
### 2.3.2 状态恢复与一致性保证
故障转移的目标是确保状态快速恢复并保证数据一致性。
- **状态恢复**:Standby NameNode会从主NameNode和DataNode同步元数据和数据块信息,以备不时之需。
- **一致性保证**:通过维护编辑日志(EditLog)和文件系统镜像(FsImage),HDFS确保元数据的一致性和恢复能力。
通过分析心跳机制、故障检测策略、以及状态恢复流程,我们能够理解NameNode是如何保证其高可用性以及数据的一致性的。在本章节的后半部分,我们将继续深入探讨NameNode的性能优化技巧和解决常见问题的策略。
为了提供清晰的章节间关联,下面的章节内容将在不同的深度层次上继续深入探讨Hadoop NameNode的架构细节、优化方法和故障处理策略。通过这样的安排,我们将逐步构建出对Hadoop NameNode的全面理解,并将这些知识应用到实践之中。
# 3. Hadoop NameNode的优势与挑战
## 3.1 NameNode的性能优化技巧
Hadoop NameNode作为整个Hadoop集群的核心,它的性能直接影响整个系统的运行效率。优化NameNode的性能,可以提升集群的处理能力,满足大规模数据存储和处理的需求。
### 3.1.1 内存使用与优化
NameNode的内存使用是一个关键性能指标,内存的大小直接关系到它可以管理的数据节点(DataNode)数量,以及能够处理的文件数量。由于所有的文件系统元数据都存储在内存中,因此当集群规模扩大时,对内存的需求也随之增加。优化NameNode的内存使用包括以下几个方面:
1. **优化JVM参数设置**:调整JVM的堆内存大小以及垃圾回收策略可以改善NameNode的性能。例如,增加堆内存(-Xmx和-Xms参数)可以提供更多的内存给NameNode,从而提高处理能力。
2. **使用压缩命名空间**:Hadoop允许启用一个选项,该选项压缩存储在内存中的文件路径,这可以大大减少内存使用。
```xml
<!-- 在hdfs-site.xml中配置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>***</value>
<description>指定NameNode元数据存储路径</description>
</property>
```
3. **使用NameNode联邦架构**:为了支持更大的集群规模,Hadoop引入了NameNode联邦,通过增加NameNode的数量来分散内存负担。
### 3.1.2 垃圾回收和资源限制
Hadoop NameNode的JVM垃圾回收是影响性能的关键因素。垃圾回收过程会导致NameNode的响应时间暂时性增加,严重时可能导致性能波动。
1. **选择合适的垃圾回收算法**:对于NameNode来说,使用G1垃圾回收器通常是一个不错的选择,因为它能在保持较短暂停的同时,有效管理大内存堆。
2. **优化JVM参数**:通过调整JVM参数来控制垃圾回收的行为,如增加新生代内存比例,减少Full GC的频率。
```sh
# 示例JVM参数调整
-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=35
```
3. **资源限制设置**:通过设置操作系统级别的资源限制来保证NameNode的稳定运行。例如,使用`ulimit`来限制打开的文件数量。
## 3.2 NameNode的扩展性与限制
NameNode的设计和实现方式决定了它的扩展性和潜在的系统瓶颈。了解这些限制对于部署大规模的Hadoop集群至关重要。
### 3.2.1 扩展策略与实践
随着数据量的增长,集群的扩展是不可避免的需求。为了应对这种扩展性需求,可以采用以下策略:
1. **增加DataNode数量**:在硬件条件允许的情况下,可以增加DataNode的数量以提供更多的存储空间和计算能力。
2. **升级NameNode硬件**:提高NameNode的硬件配置,特别是增加更多的CPU和内存资源,可以提升元数据处理能力。
3. **采用NameNode联邦**:通过配置多个NameNode,将元数据空间进行切分,可以提升集群的扩展性。
### 3.2.2 系统瓶颈与性能极限
每个Hadoop集群都有其性能极限,这些极限通常是由硬件资源、网络带宽、存储I/O等限制因素决定的。以下是两个可能成为瓶颈的因素:
1. **网络带宽**:Hadoop集群中的数据传输依赖于网络带宽,当数据量极大时,网络带宽可能会成为瓶颈。
2. **存储I/O**:DataNode的磁盘I/O性能直接影响数据读写速度。在高并发和大数据量环境下,I/O可能会成为系统性能的瓶颈。
## 3.3 NameNode常见问题的解决方法
在使用Hadoop NameNode时,可能会遇到各种问题。了解这些问题的来源和解决方案对于确保集群稳定运行非常重要。
### 3.3.1 常见错误分析
错误分析是解决问题的关键步骤。常见的问题及分析方法如下:
1. **JournalNode同步问题**:在High Availability配置中,JournalNode集群同步问题会导致NameNode无法正常切换。通过检查JournalNode的日志文件,可以找到同步失败的原因。
2. **内存溢出**:如果NameNode的内存配置不足,很容易发生内存溢出错误。使用堆转储文件进行分析,可以找出内存溢出的原因。
### 3.3.2 解决方案与预防措施
为了应对常见的问题,可以采取以下预防措施和解决方案:
1. **监控系统状态**:使用Hadoop自带的Web界面或第三方监控工具,持续监控集群的状态,及时发现并解决潜在问题。
2. **配置检查与备份**:定期进行配置文件检查,并对关键数据进行备份,如FsImage和EditLog文件,可以有效防止数据丢失。
由于篇幅限制,这里展示了第三章的部分内容。根据章节要求,每个章节都必须有更详细的子章节内容,代码块、表格、列表以及至少一种流程图。而本文内容展示了如何针对Hadoop NameNode性能优化和常见问题的解决方法进行详细阐述,同时也展示了如何使用配置项进行性能调整。在实际文章中,还需要补充更多实践操作的细节、配置项的详细说明、故障排查的详细步骤以及优化措施的验证过程等内容。
# 4. Hadoop NameNode的高级配置
## 4.1 高级NameNode配置项解析
### 4.1.1 配置项的作用与调优
Hadoop NameNode 的配置项丰富而详尽,合理地调整配置项可以显著提升系统的性能与稳定性。在这部分,我们将深入探讨一些关键的配置项及其优化方法。
首先是 `dfs.namenode.handler.count`,这是控制 NameNode 处理 RPC 请求的线程数。默认值为 10,但在处理大量并发小文件的场景下,可以适当增加这个值来提升并发性能。一般建议设置为集群中小文件数量的两倍。
接下来是 `dfs.replication`,它定义了 HDFS 数据块的副本数。在稳定性要求较高的环境中,可以适当增加这个值以提高数据的冗余性和可靠性。例如,在生产环境中,将其设置为 3 或更高以应对节点故障。
我们还可以优化 `dfs.namenode.name.dir` 和 `dfs.datanode.data.dir`,分别指定 NameNode 元数据和 DataNode 数据块的存储位置。通过将这些配置指向高性能的存储设备,例如 SSD,可以加快读写速度。
还有 `dfs.namenode.checkpoint.dir`,它决定了检查点文件存储的位置。合理的配置可以确保 NameNode 故障时快速恢复,提高系统的容错能力。
代码块示例:
```properties
# RPC 请求处理器的数量
dfs.namenode.handler.count=30
# 数据块的副本数
dfs.replication=3
# NameNode 元数据的存储路径
dfs.namenode.name.dir=/data/hadoop/name
# DataNode 数据块的存储路径
dfs.datanode.data.dir=/data/hadoop/data
# 检查点目录
dfs.namenode.checkpoint.dir=/data/hadoop/dfs/nn/dfscheckpoints
```
每个配置项的调整都需要根据实际的集群规模、硬件条件、数据访问模式来定制。因此,对 Hadoop 的高级配置,监控系统的运行情况,理解参数的含义是至关重要的。
### 4.1.2 自动故障转移配置
NameNode 的高可用性是任何 Hadoop 集群设计的核心部分。自动故障转移(Automatic Failover)可以确保在 NameNode 发生故障时,集群可以快速恢复服务。Hadoop 提供了基于 ZooKeeper 的自动故障转移配置选项。
配置自动故障转移主要涉及 `dfs.ha.fencing.methods`,它定义了一系列防止脑裂(split-brain)的机制。`sshfence` 是其中一种常用方法,它通过 SSH 命令远程关机或断开服务,来隔离故障的 NameNode。其他方法包括使用外部的 shell 脚本或者使用光纤通道等硬件隔离机制。
要启用自动故障转移,还需要设置 `dfs.ha.automatic-failover.enabled` 为 true,并配置集群的 NameNode 服务和故障转移控制器,如 ZKFailoverController (ZKFC)。ZKFC 会监控 NameNode 的健康状态,并在必要时进行故障转移操作。
代码块示例:
```properties
# 故障转移方法配置
dfs.ha.fencing.methods=sshfence(/path/to/fence/script)
# 启用自动故障转移
dfs.ha.automatic-failover.enabled=true
# 配置 NameNode 服务
dfs.ha.namenodes.nn1=zkfc1, zkfc2
# 故障转移控制器的配置
# 此处省略了 ZooKeeper 连接字符串和故障转移控制器的具体配置
```
配置自动故障转移是一个复杂的过程,需要对 Hadoop 集群的架构有深入理解,并且对自动化运维工具有一定的了解。正确的配置可以大大提高系统的可用性和维护性。
## 4.2 NameNode的监控与日志分析
### 4.2.1 监控工具与性能指标
监控是维护 Hadoop NameNode 稳定运行的重要手段。Hadoop 自带的 JMX (Java Management Extensions) 提供了丰富的监控指标,而像 Ganglia、Nagios 等第三方监控工具也可以与 Hadoop 集成使用。
监控指标主要包括 NameNode 的 CPU、内存、文件系统利用率、RPC 调用次数和延迟、块(Block)的数量和大小分布,以及数据节点的健康状况等。通过收集这些指标,运维人员可以实时了解 NameNode 的健康状态,并及时发现性能瓶颈或潜在的故障点。
使用 Java 命令行工具 jstat,可以查看 NameNode 的内存使用情况:
```bash
jstat -gcutil <pid> <interval> <count>
```
其中 `<pid>` 是 NameNode 进程的 ID,`<interval>` 是两次采样的间隔时间(单位为毫秒),`<count>` 是采样的次数。
除了使用命令行工具,还可以使用 Hadoop 提供的 Web 界面进行监控。例如,访问 NameNode 的 Web UI 界面,可以查看其详细的状态和统计信息,如活动的 RPC 调用和块的操作等。
### 4.2.2 日志文件的解读与分析
Hadoop NameNode 的日志文件记录了集群操作的详细信息,对于诊断问题和性能调优至关重要。日志文件位于配置的 `dfs.namenode.name.dir` 目录下,并以 `hadoop-hadoop-namenode-*.log` 的格式命名。
解读 NameNode 的日志文件,可以使用日志管理工具,如 Elasticsearch、Logstash 和 Kibana (ELK) 堆栈,或者使用 Hadoop 提供的 `hdfs --daemon logviewer` 命令。
在日志中,重要的信息包括启动和关闭事件、文件系统操作(如创建、删除、打开文件)、数据块的复制和恢复状态、以及各种错误和异常。这些信息有助于识别系统故障的根本原因,并监控性能趋势。
```bash
hdfs --daemon logviewer <namenode_id>
```
其中 `<namenode_id>` 是 NameNode 的标识符。
## 4.3 NameNode的备份与数据安全
### 4.3.1 数据备份策略
数据备份是保证 Hadoop NameNode 数据安全的重要组成部分。有效的备份策略不仅可以防止数据丢失,还可以在灾难发生时快速恢复。
NameNode 的元数据备份通常分为两个步骤:首先,定期将元数据备份到远程或本地的磁盘上;其次,将备份的元数据转存到更安全的存储设备上,比如 Amazon S3、云存储服务或者磁带。
对于自动备份,可以使用 Hadoop 提供的 `dfsadmin -saveNamespace` 命令定期保存 NameNode 的命名空间状态。此外,Hadoop 还支持使用 `dfsadmin -fetchImage` 命令获取整个文件系统的状态,这可以帮助管理员更快速地恢复集群状态。
代码块示例:
```bash
# 命令用于保存 NameNode 的命名空间状态
hdfs dfsadmin -saveNamespace
# 命令用于获取整个文件系统的状态
hdfs dfsadmin -fetchImage
```
除了使用命令行工具,还可以通过编写脚本或使用像 Apache Oozie 这样的工作流管理系统来自动化备份过程。
### 4.3.2 灾难恢复流程
灾难恢复是针对大规模故障或数据丢失事件而设计的恢复计划。灾难恢复计划应该包括以下步骤:
1. **预先规划**:确定备份的策略和频率、数据恢复点目标(RPO)和恢复时间目标(RTO),并准备必要的硬件和软件资源。
2. **故障检测**:设置监控告警,以便在发生故障时及时通知运维人员。
3. **初步评估**:发生故障后,首先要评估故障的严重性,确定是否需要执行灾难恢复流程。
4. **数据恢复**:使用最近的备份数据,恢复 NameNode 的状态。如果集群配置了自动故障转移,恢复过程会更加快速和简单。
5. **系统测试**:在恢复 NameNode 后,需要运行系统测试来验证数据的完整性和系统功能。
6. **业务连续性**:确保业务能够无缝切换回恢复后的系统,并监控系统直到完全稳定。
```mermaid
graph LR
A[检测到故障] --> B[故障评估]
B --> |需要恢复| C[启动灾难恢复计划]
B --> |不需要恢复| D[监控系统稳定性]
C --> E[数据恢复]
E --> F[系统测试]
F --> G[业务连续性]
G --> H[监控系统稳定性]
```
灾难恢复流程的效率直接决定了企业应对故障的能力和损失的大小。良好的备份和恢复策略可以最大限度地减少故障对企业的影响。
# 5. Hadoop NameNode的实践应用
## 5.1 构建高可用性Hadoop集群
### 5.1.1 硬件环境搭建
构建一个高可用性(High Availability,HA)的Hadoop集群是一个复杂的过程,涉及到硬件的选择与配置。为了支持大规模数据处理和保证服务的持续可用性,我们需要设计一个既高效又稳定的硬件环境。关键组件包括:
- **服务器**: 应选择性能稳定、扩展性强的服务器,通常以刀片服务器为主。服务器的CPU应具备强大的计算能力,建议使用多核心处理器。内存的大小要能够满足Hadoop运行时的大量内存需求。
- **存储**: 数据存储设备需要具有高吞吐量和容错能力。推荐使用高速的固态硬盘(SSD)作为NameNode的存储介质,因为它可以极大提升读写速度和提高故障恢复效率。对于DataNode,可以使用大容量的机械硬盘以降低成本。
- **网络**: 集群内部应该拥有高带宽、低延迟的网络连接,以保证数据在节点间的迅速传输。
搭建硬件环境时,还需考虑机房的供电系统、散热系统和安全系统等因素,以保证整个系统的稳定运行。
### 5.1.2 集群配置与部署
配置Hadoop集群需要经过以下步骤:
1. **安装操作系统**: 首先在所有服务器上安装Linux操作系统,推荐使用稳定版本的CentOS或Ubuntu。
2. **安装JDK**: Hadoop需要Java环境运行,因此必须安装Java开发工具包(JDK)。
3. **下载并解压Hadoop**: 从Apache Hadoop官网下载适合的Hadoop版本,解压到服务器的相应目录。
4. **配置Hadoop环境**: 设置环境变量`JAVA_HOME`,并配置Hadoop的`conf/hadoop-env.sh`文件。接着编辑`conf/core-site.xml`、`conf/hdfs-site.xml`和`conf/yarn-site.xml`等核心配置文件,设置好集群的命名空间、副本策略、资源管理器等关键参数。
5. **格式化HDFS文件系统**: 使用`hdfs namenode -format`命令格式化NameNode,为集群的初始启动做准备。
6. **启动集群**: 通过`start-dfs.sh`和`start-yarn.sh`脚本分别启动分布式文件系统和资源管理器。
在搭建集群的过程中,监控各节点间的通信状态和资源使用情况是非常重要的,这能帮助我们及时发现和解决问题。
## 5.2 NameNode的实际应用场景
### 5.2.1 大数据分析处理
NameNode在大数据分析处理中扮演着重要角色。Hadoop集群能有效地存储和处理PB级别的数据。例如,在日志分析、视频监控、电子商务推荐系统等领域,可以通过MapReduce或Spark等编程模型,利用Hadoop集群进行分布式计算。NameNode管理的数据块定位信息对于MapReduce任务的调度至关重要,它决定了数据在计算过程中的传输路径和处理效率。
### 5.2.2 数据仓库与数据挖掘
在数据仓库和数据挖掘的应用中,Hadoop NameNode能够整合来自不同源的海量数据,并为后续的数据分析和挖掘提供基础。NameNode使用户能够访问存储在HDFS中的数据,而无需担心数据的具体物理位置。数据仓库如Amazon Redshift或Google BigQuery等通过Hadoop进行数据的预处理,为数据分析提供了一个高效的环境。
## 5.3 NameNode在云环境中的部署
### 5.3.1 云服务模式简介
在云环境中部署Hadoop NameNode,可以采用不同的服务模式:
- **基础设施即服务(IaaS)**: 如Amazon EC2,提供虚拟化计算资源。用户可以在此基础上自行搭建和管理Hadoop集群。
- **平台即服务(PaaS)**: 如Google App Engine,提供一个部署应用的平台,可能已经内置了Hadoop支持。
- **软件即服务(SaaS)**: 提供应用程序和数据,用户不需要关心底层Hadoop集群的部署和管理。
### 5.3.2 云环境中NameNode的特殊考虑
在云环境中,NameNode的部署需要考虑以下特殊因素:
- **弹性和可伸缩性**: 云环境提供的资源可以根据需求动态调整,NameNode应该能够适应资源的动态变化。
- **高可用性**: 云服务提供商通常会有多个数据中心来保证服务的连续性。NameNode可以部署在这些数据中心,以实现高可用性。
- **数据安全和备份**: 在云环境中,数据的安全和备份是一个重要考量。需要有策略来保证数据的加密传输和存储,以及定期备份。
在云环境中部署NameNode时,需要遵循云服务的特定指南,并利用云服务的优势来提升集群的可用性和性能。
# 6. Hadoop NameNode的性能调优策略
在现代的大数据处理场景中,一个高效、稳定、可扩展的Hadoop NameNode是至关重要的。性能调优不仅能够提升NameNode的处理能力,还可以通过资源管理避免潜在的系统瓶颈。本章将深入探讨如何通过具体操作来优化NameNode的性能。
## 6.1 NameNode内存与存储的优化
在Hadoop集群中,NameNode的内存和存储性能直接关系到整个系统的运行效率。首先,我们需要了解如何调整NameNode的JVM堆大小,因为它对于NameNode的性能有着决定性的影响。
```***
***.preferIPv4Stack=true -Xmx4g -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:MaxTenuringThreshold=42 -XX:SurvivorRatio=32
```
上述代码展示了JVM的一些常用参数设置,其中`-Xmx4g`是用来设置堆的最大容量为4GB。调整这个参数时需要注意,过大的堆可能会导致长时间的垃圾回收停顿,而过小的堆则不能满足NameNode的需求。
接下来是存储优化,NameNode存储的是HDFS的元数据信息。在磁盘选择上,应优先考虑SSD,因为SSD具有低延迟和高吞吐量的特点,可以显著提高NameNode的响应速度。
## 6.2 垃圾回收(GC)优化
Java的垃圾回收机制是自动内存管理的一个重要组成部分,但如果不加以控制,GC造成的停顿可能会影响NameNode的性能。我们可以采用并行垃圾回收器来减少停顿时间。
```java
-XX:+UseParallelGC -XX:ParallelGCThreads=12 -XX:+UseParallelOldGC
```
在这里,我们指定了使用并行垃圾回收器,并设置了12个GC线程来并行处理垃圾回收。
## 6.3 配置文件参数调优
Hadoop的配置文件中有很多参数可以用来优化NameNode的性能。例如:
```xml
<property>
<name>dfs.namenode.handler.count</name>
<value>20</value>
</property>
```
此配置项`dfs.namenode.handler.count`指定了处理RPC请求的Handler数量,调优这个参数可以增强NameNode处理并发请求的能力。
## 6.4 网络层面的优化
除了内存和存储之外,网络配置也是性能调优不可忽视的一部分。通过调整TCP/IP堆栈参数,可以进一步优化网络性能。
```shell
sysctl -w net.ipv4.tcp_tw_recycle=1
sysctl -w net.ipv4.tcp_tw_reuse=1
```
以上命令会启用TCP的快速回收机制,减少TIME_WAIT状态的持续时间,提升网络层面的性能。
## 6.5 NameNode扩展性的优化
随着数据量的不断增长,NameNode的扩展性显得尤为重要。Hadoop 2.x引入了NameNode联邦和高可用性(HA)特性,可以通过增加额外的NameNode来提高系统的扩展性。
配置NameNode联邦时,需要关注以下参数:
```xml
<property>
<name>dfs.namenode.federation.nameservices</name>
<value>mycluster</value>
</property>
```
通过这种方式,我们可以在集群中部署多个NameNode来提升系统的可用性和扩展性。
## 6.6 实例:配置高可用性Hadoop集群
为了展示性能调优的全过程,以下是一个高可用性Hadoop集群配置的示例。本示例包含多个步骤,从环境检查到集群部署,再到性能调优。
```shell
# 检查主机名
hostname
# 设置主机名映射
echo "**.**.*.* nn1" >> /etc/hosts
echo "**.**.*.* nn2" >> /etc/hosts
# 在NameNode节点上创建HDFS目录
hdfs dfs -mkdir /hdfs
# 配置SSH无密码访问
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
```
在实际操作中,还需要配置hdfs-site.xml、core-site.xml等Hadoop配置文件,并在两个NameNode上执行格式化操作,以及启动所有相关服务。这只是一个简化的配置过程,每一步都需要根据实际情况进行调整。
## 结语
通过对Hadoop NameNode的性能调优策略的探索,我们了解了从内存到存储,从网络到扩展性等多个方面的优化方法。通过本章的内容,希望能帮助IT从业者们更好地管理和优化Hadoop NameNode,提高大数据处理效率。在未来的章节中,我们还将深入探讨更多关于Hadoop NameNode的高级配置与最佳实践。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面解析了 Hadoop NameNode,这是 Hadoop 生态系统中的核心组件。通过一系列深入的文章,该专栏揭示了 NameNode 的作用、优势、元数据管理、故障转移机制、监控和维护策略,以及横向扩展和通信机制。此外,该专栏还提供了 NameNode 配置、数据访问路径、日志分析、与 ZooKeeper 的协同工作、性能优化、高并发处理、内存限制和容错机制方面的最佳实践和技巧。通过深入了解 NameNode,读者可以掌握其在 Hadoop 集群中至关重要的作用,并优化其性能和可靠性,以满足大数据时代的挑战。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyroSiM中文版模拟效率革命:8个实用技巧助你提升精确度与效率
# 摘要
PyroSiM是一款强大的模拟软件,广泛应用于多个领域以解决复杂问题。本文从PyroSiM中文版的基础入门讲起,逐渐深入至模拟理论、技巧、实践应用以及高级技巧与进阶应用。通过对模拟理论与效率提升、模拟模型精确度分析以及实践案例的探讨,本文旨在为用户提供一套完整的PyroSiM使用指南。文章还关注了提高模拟效率的实践操作,包括优化技巧和模拟工作流的集成。高级
QT框架下的网络编程:从基础到高级,技术提升必读
# 摘要
QT框架下的网络编程技术为开发者提供了强大的网络通信能力,使得在网络应用开发过程中,可以灵活地实现各种网络协议和数据交换功能。本文介绍了QT网络编程的基础知识,包括QTcpSocket和QUdpSocket类的基本使用,以及QNetworkAccessManager在不同场景下的网络访问管理。进一步地,本文探讨了QT网络编程中的信号与槽
优化信号处理流程:【高效傅里叶变换实现】的算法与代码实践

# 摘要
傅里叶变换是现代信号处理中的基础理论,其高效的实现——快速傅里叶变换(FFT)算法,极大地推动了数字信号处理技术的发展。本文首先介绍了傅里叶变换的基础理论和离散傅里叶变换(DFT)的基本概念及其计算复杂度。随后,详细阐述了FFT算法的发展历程,特别是Coo
MTK-ATA核心算法深度揭秘:全面解析ATA协议运作机制

# 摘要
本文深入探讨了MTK-ATA核心算法的理论基础、实践应用、高级特性以及问题诊断与解决方法。首先,本文介绍了ATA协议和MTK芯片架构之间的关系,并解析了ATA协议的核心概念,包括其命令集和数据传输机制。其次,文章阐述了MTK-ATA算法的工作原理、实现框架、调试与优化以及扩展与改进措施。此外,本文还分析了MTK-ATA算法在多
【MIPI摄像头与显示优化】:掌握CSI与DSI技术应用的关键
# 摘要
本文全面介绍了MIPI摄像头与显示技术,从基本概念到实际应用进行了详细阐述。首先,文章概览了MIPI摄像头与显示技术的基础知识,并对比分析了CSI与DSI标准的架构、技术要求及适用场景。接着,文章探讨了MIPI摄像头接口的配置、控制、图像处理与压缩技术,并提供了高级应用案例。对于MIPI显示接口部分,文章聚焦于配置、性能调优、视频输出与图形加速技术以及应用案例。第五章对性能测试工具与
揭秘PCtoLCD2002:如何利用其独特算法优化LCD显示性能

# 摘要
PCtoLCD2002作为一种高性能显示优化工具,在现代显示技术中占据重要地位。本文首先概述了PCtoLCD2002的基本概念及其显示性能的重要性,随后深入解析了其核心算法,包括理论基础、数据处理机制及性能分析。通过对算法的全面解析,探讨了算法如何在不同的显示设备上实现性能优化,并通过实验与案例研究展示了算法优化的实际效果。文章最后探讨了PCtoLCD2002算法的进阶应用和面临
DSP系统设计实战:TI 28X系列在嵌入式系统中的应用(系统优化全攻略)
# 摘要
TI 28X系列DSP系统作为一种高性能数字信号处理平台,广泛应用于音频、图像和通信等领域。本文旨在提供TI 28X系列DSP的系统概述、核心架构和性能分析,探讨软件开发基础、优化技术和实战应用案例。通过深入解析DSP系统的设计特点、性能指标、软件开发环境以及优化策略,本文旨在指导工程师有效地利用DSP系统的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )