Scrapy爬虫中的网络请求调度机制解析
发布时间: 2024-04-15 18:46:53 阅读量: 80 订阅数: 45 

解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫全套教学资料

# 1. Scrapy爬虫基础知识
网络爬虫作为一种自动化的数据获取工具,在各行各业都有着广泛的应用。通过定义好的规则,网络爬虫可以自动访问网页,提取感兴趣的信息。
### 1.1 什么是网络爬虫
#### 1.1.1 网络爬虫的定义
网络爬虫是一种程序或者脚本,可以自动地浏览互联网,并且按照一定规则抓取网页内容的工具。
#### 1.1.2 网络爬虫的应用领域
网络爬虫被广泛用于搜索引擎、数据挖掘、价格监控、舆情分析等领域,帮助人们快速获取互联网上的大量信息。Scrapy作为一个高效的Python爬虫框架,在实现网络爬虫的过程中使用广泛。
# 2. Scrapy爬虫的工作原理
### 2.1 调度器(Scheduler)的作用
网络爬虫中的调度器(Scheduler)扮演着至关重要的角色,它负责协调和管理整个爬虫的数据流程,确保每个请求都被适时发送和处理。
#### 2.1.1 调度器的工作流程
调度器的工作流程通常包括以下几个步骤:首先,将初始的请求添加到调度队列中;然后,通过算法选择下一个要处理的请求;接着,将该请求发送给下载器进行页面抓取;最后,处理完毕后返回爬取到的页面数据。
```python
# 示例代码:调度器的简单实现
class Scheduler:
def __init__(self):
self.queue = Queue()
def add_request(self, request):
self.queue.put(request)
def get_next_request(self):
return self.queue.get()
```
#### 2.1.2 调度器的数据结构
调度器主要依靠队列(Queue)这种数据结构来存储待处理的请求,保证请求的先后顺序和唯一性。
### 2.2 下载器(Downloader)的功能
下载器(Downloader)负责下载调度器分发的请求,并负责处理所有网络相关的操作,如发送请求、接收响应、处理重定向等工作。
#### 2.2.1 下载器的工作流程
下载器的工作流程包括接收调度器传递的请求、下载网页内容、处理响应并返回数据,确保页面的高效下载和数据的准确提取。
```python
# 示例代码:下载器的简单实现
class Downloader:
def download(self, request):
response = requests.get(request.url)
return response.content
```
#### 2.2.2 下载器的请求处理
下载器处理请求时需要注意处理各种类型的请求,如GET、POST请求,同时要处理异常情况,确保爬虫的稳定性和高效性。
### 2.3 引擎(Engine)的角色
引擎(Engine)是Scrapy爬虫的核心部分,负责协调调度器、下载器、爬虫模块之间的数据流转,是整个爬虫流程的主导者。
#### 2.3.1 引擎的工作流程
引擎的工作流程主要包括启动爬虫、管理各个组件之间的通信、处理各个组件返回的数据结果等步骤,确保整个爬虫系统的协调运行。
```python
# 示例代码:引擎的简单实现
class Engine:
def start(self):
scheduler = Scheduler()
downloader = Downloader()
while True:
request = scheduler.get_next_request()
if not request:
break
response = downloader.download(request)
# 处理response
```
#### 2.3.2 引擎的任务分配
引擎负责将请求分发给调度器和下载器,并根据爬虫模块返回的数据结果进行相应的处理和调度,保证任务的有序执行和高效完成。
# 3.1 请求的生成和处理
在Scrapy爬虫中,请求的生成是爬虫的第一步,也是至关重要的一步。通过创建请求,Scrapy可以向指定的URL发起网络请求并获取相应的数据。
#### 3.1.1 请求的创建方式
Scrapy中可以使用两种方式生成请求:一种是通过爬虫类的`start_requests`方法手动创建请求,另一种是通过`scrapy.Request`对象自动创建请求。下面以手动创建请求为例:
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
def start_requests(self):
urls = ['http://example.com/page1', 'http://example.com/page2']
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
```
#### 3.1.2 请求的处理流程
当Scrapy发送请求后,响应会被传递到指定的回调函数进行处理。在上面的示例中,`parse`方法用于处理请求的响应数据。可以在`parse`方法中解析HTML或者提取数据进行后续处理。
### 3.2 请求的优先级控制
对于爬虫来说,请求的优先级控制可以帮助我们更灵活地处理不同页面的数据,提高爬虫效率和抓取速度。
#### 3.2.1 请求的优先级定义
Scrapy框架中通过`priority`参数来定义请求的优先级,数值越高的请求优先级越高。默认情况下,所有请求的优先级都是0。
#### 3.2.2 请求优先级的调整方式
我们可以通过在`scrapy.Request`中设置`priority`参数来调整请求的优先级。下面是一个示例:
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
def start_requests(self):
urls = ['http://example.com/page1', 'http://example.com/page2']
for index, url in enumerate(urls):
yield scrapy.Request(url=url, callback=self.parse, priority=index)
```
### 3.3 请求的过滤与去重
在爬虫的数据抓取过程中,往往会遇到重复的URL或者已经抓取过的数据,需要进行过滤与去重处理,以避免重复获取相同的数据。
#### 3.3.1 请求去重的重要性
请求去重可以有效减少爬虫的资源消耗和数据处理量,避免重复抓取相同的页面,提高爬虫的效率。
#### 3.3.2 请求过滤的实现方式
Scrapy提供了基于`scrapy.dupefilters.DupeFilter`的去重功能,通过配置`DUPEFILTER_CLASS`参数可以指定使用的去重类。常用的去重类包括`scrapy.dupefilters.RFPDupeFilter`和`scrapy.dupefilters.BaseDupeFilter`。通过这些去重类,我们可以很方便地实现请求的去重功能。
# 4.1 数据pipeline的配置与使用
数据pipeline在Scrapy中扮演着非常关键的角色,它负责处理爬虫从网页中提取的数据,进行后续的处理、存储或展示。通过配置和使用数据pipeline,我们可以对爬取到的数据进行多种处理操作。
1. **pipeline的作用**
数据pipeline主要用于处理从Spider爬取到的数据,可以进行数据清洗、去重、验证、存储等操作。它是Scrapy中的数据处理和存储机制。
2. **pipeline的配置方法**
在Scrapy项目中,我们可以通过配置`settings.py`文件来启用和配置数据pipeline。在`ITEM_PIPELINES`中配置需要启用的pipeline类,并设置优先级来指定数据处理的顺序。
```python
ITEM_PIPELINES = {
'myProject.pipelines.MyPipeline1': 300,
'myProject.pipelines.MyPipeline2': 800,
}
```
### 4.2 数据存储到数据库
将爬取到的数据存储到数据库是爬虫过程中常见的需求,Scrapy提供了方便的接口来实现数据存储到各种类型的数据库中。
1. **存储到MySQL的方法**
使用Scrapy框架自带的MySQL数据库插件`MySQLPipeline`可以方便地将数据存储到MySQL数据库中。
```python
import pymysql
class MySQLPipeline:
def open_spider(self, spider):
self.conn = pymysql.connect(host='localhost', user='root', password='password', database='mydatabase')
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
# 处理item数据并存储到MySQL数据库中
self.cursor.execute('INSERT INTO table_name (column1, column2) VALUES (%s, %s)', (item['data1'], item['data2']))
self.conn.commit()
return item
def close_spider(self, spider):
self.conn.close()
```
2. **存储到MongoDB的方式**
如果需要将数据存储到MongoDB数据库中,可以使用`pymongo`库来实现。
```python
import pymongo
class MongoDBPipeline:
def open_spider(self, spider):
self.client = pymongo.MongoClient('mongodb://localhost:27017/')
self.db = self.client['mydatabase']
def process_item(self, item, spider):
# 处理item数据并存储到MongoDB数据库中
self.db['collection'].insert_one(dict(item))
return item
def close_spider(self, spider):
self.client.close()
### 4.3 数据处理与分析
数据处理与分析是数据爬取工作的重要环节,通过对爬取到的数据进行清洗、去重、分析和可视化处理,能够更好地理解数据和发现其中的价值。
1. **数据清洗与去重**
在数据处理过程中,常常会遇到数据中存在脏数据、重复数据等情况,需要进行清洗和去重操作以确保数据的质量和准确性。
2. **数据分析与可视化**
通过数据分析和可视化可以从多个维度深入挖掘数据的潜在价值,发现数据之间的关联性和规律性,为后续的决策和应用提供支持。
# 5. Scrapy爬虫性能优化技巧
在开发和部署Scrapy爬虫时,优化爬虫性能是至关重要的。本章将介绍一些提高Scrapy爬虫性能的技巧,包括优化目标与策略以及优化实施步骤。
1. **优化目标与策略**
- *提高爬取速度*:减少爬虫请求的响应时间,提高数据爬取效率。
- *降低资源消耗*:优化Scrapy爬虫在运行过程中的资源占用,减少带宽和CPU的消耗。
- *提升稳定性*:减少爬虫因频繁被封禁或IP被限制导致的中断,增加爬虫运行的稳定性。
- *改善代码质量*:优化爬虫代码结构、逻辑,提高代码的可读性和可维护性。
2. **优化实施步骤**
- *使用合适的User-Agent*:在Scrapy爬虫中设置合适的User-Agent,模拟真实请求,避免被网站识别为爬虫而限制访问。
- *合理设置并行请求*:通过调整并发请求数量和下载延迟,可以有效控制爬虫对目标网站的访问频率,避免对网站造成过大压力。
- *优化数据处理和存储*:合理使用数据pipeline,尽量减少内存占用,避免数据处理阻塞爬虫的运行。
- *IP代理池的使用*:通过集成IP代理池,实现爬虫请求的IP轮换,避免单一IP频繁请求被封禁的情况。
- *定时任务和增量更新*:设置定时任务定期运行爬虫,或者通过增量更新的方式,避免重复爬取已经获取的数据。
3. **性能优化代码示例**
```python
# 例:使用IP代理池
class ProxyMiddleware(object):
def process_request(self, request, spider):
request.meta['proxy'] = 'http://your_proxy_ip:port'
# 例:优化数据存储
class CustomPipeline(object):
def process_item(self, item, spider):
# 自定义数据处理逻辑
return item
```
4. **性能优化流程图**
```mermaid
graph LR;
A[开始] --> B(设置User-Agent和并发请求数量)
B --> C{需要优化数据处理和存储?}
C -->|是| D(优化数据pipeline)
C -->|否| E(继续下一步)
D --> E
E --> F(集成IP代理池)
F --> G(定时任务和增量更新)
G --> H[结束]
```
通过以上优化目标、策略和实施步骤,可以帮助你更好地优化Scrapy爬虫的性能,提高爬取效率和稳定性,为数据采集和处理提供更好的支持。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在帮助开发者深入了解和优化 Scrapy 爬虫框架。它从基础知识入手,介绍了 Scrapy 的架构和工作原理,并指导读者搭建和配置 Scrapy 项目。专栏还深入探讨了 Scrapy 的并发性能优化、反爬策略处理、网络请求调度机制和中间件自定义功能。此外,它还介绍了 Scrapy 中的去重和增量爬取技术,帮助开发者构建高效、可靠的爬虫。通过学习本专栏,读者将掌握 Scrapy 爬虫的全面知识,并能够解决常见的故障排除问题,从而提高爬虫的性能和效率。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【IST8310传感器数据表分析】:关键特性全面解读
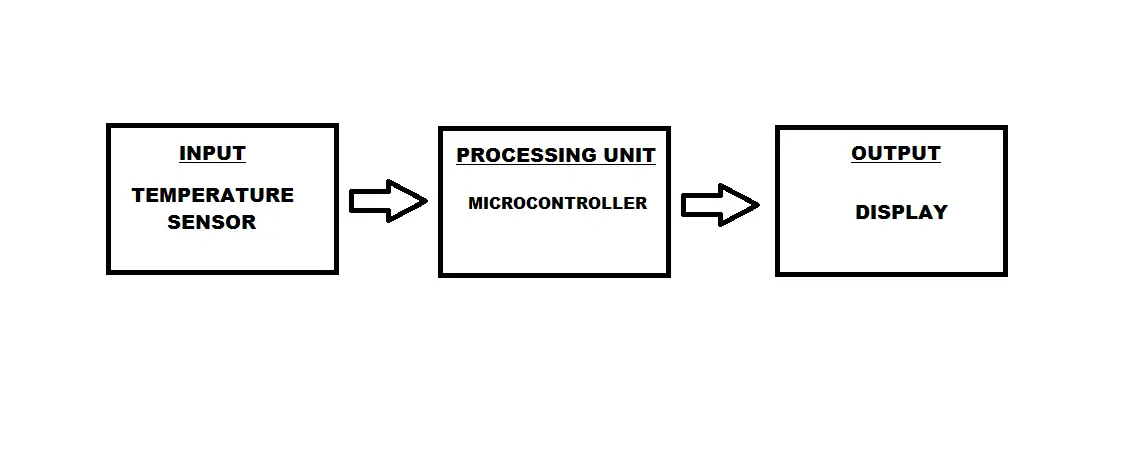
# 摘要
IST8310传感器作为一种先进的测量设备,以其高精度和可靠性在多个行业中得到广泛应用。本文从IST8310传感器的简介开始,详细介绍了其应用场景、数据采集与传输的理论与实践,以及数据处理与分析的方法。特别强调了传感器在环境监测、工业自动化和物联网等特定行业中的应用,并探讨了传感器在这些领域的实际表现和优势。最后,本文展望了IST8310传感器的未来发展趋势,包
【6SigmaET专家指南】:深入解析R13_PCB文件导入细节,避免常见错误

# 摘要
本文详细介绍了6SigmaET软件及其在PCB文件处理方面的应用,重点解析了R13版本PCB文件的结构、数据类型、编码规则以及导入流程。通过对R13_PCB文件的物理结构和数据块的分析,阐述了文件头部信息和数据类型的具体内容,并提出了有效的错误检测和处理方法。同时,本文也探讨了导入R13_PCB文件的具体操作流程,包括前期准备、导入操作注意事项及结果确认,并对常见错
LM-370A耗材管理:降低运营成本的策略与实践

# 摘要
本论文综述了LM-370A耗材管理的各个方面,重点在于运营成本的降低及其对整体财务表现的影响。首先,文章从理论基础出发,分析了运营成本的构成,并探讨了耗材管理在财务上的重要性。随后,实践方法章节着重讨论了如何通过优化耗材采购策略、生命周期成本分析以及实施有效的监控与控制措施来减少运营成本。此外,通过案例研究,本文展示了LM-370A耗材管理成功实践的量化分析和管理流程优化实例
【深入揭秘Linux内核】:掌握kernel offset信息的含义及其在Ubuntu中的关键作用
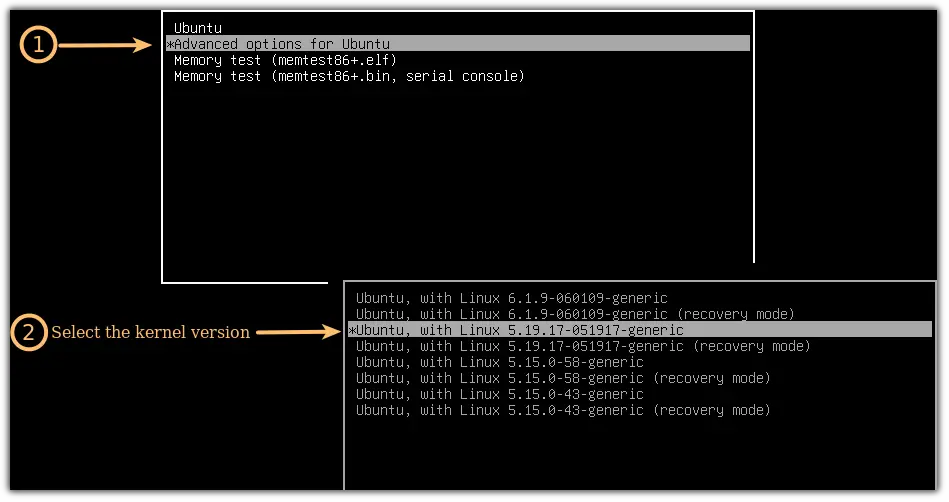
# 摘要
本文系统地介绍了Linux内核的基础知识、结构组件以及内核偏移的概念、原理与操作。通过详细解析内核的进程调度、内存管理、文件系统、网络协议栈及关键组件如VFS层和设备驱动程序,阐述了它们在Linux系统中的核心作用。同时,本文深入探讨了kernel offset在内核中的角色、对系统安全的影响以及相关的操作
VIVO-IQOO系列BL解锁全解析:ROM刷写教程及常见问题深度解读

# 摘要
本文详细探讨了VIVO-IQOO系列手机的BL解锁机制及其理论基础,阐述了解锁对ROM刷写的重要性,解锁流程的各个环节,以及所需的工具和环境配置。进一步地,文章实践了VIVO-IQOO系列手机的ROM刷写过程,包括准备工作、详细步骤和刷写后系统配置与优化。此外,还介绍了高级刷机技巧、故障排除方法以及预防刷机故障的建议。文章最后分享了社区
宠物殡葬数据分析秘籍:6个步骤通过数据挖掘揭示隐藏商机
# 摘要
随着宠物殡葬行业的兴起,数据挖掘技术在理解和优化该行业中扮演着越来越重要的角色。本文通过系统地介绍数据收集、预处理、市场分析以及数据挖掘技术的应用,揭示了宠物殡葬市场中的客户行为模式、市场细分和竞争对手情况。文章详细讨论了关联规则学习、聚类分析和预测模型构建等方法在宠物殡葬业务中的实际应用,以及如何通过数据挖掘优化服
MODBUS TCP案例深度解析:西门子系统中的通信应用
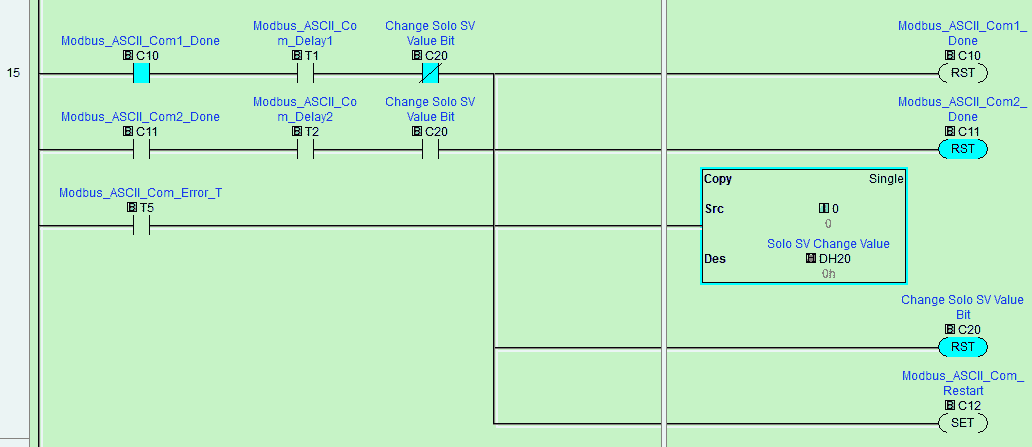
# 摘要
本文系统地介绍了MODBUS TCP通信协议的基础知识及其在西门子系统中的应用。首先,概述了MODBUS TCP协议的基本概念,随后详细探讨了其在西门子自动化系统架构中的集成细节,包括硬件接口、功能码详解以及错误处理机制。通过对客户端和服务器端编程实践的分析,本文提供了编程环境配置和数据通信同步的实操指南。文章还讨论了
文件系统故障全解析:5步恢复丢失数据的方法与技巧
# 摘要
文件系统故障是影响数据完整性和系统可用性的重要问题。本文全面概述了文件系统及其故障类型,深入探讨了硬件故障、软件故障及用户错误等常见问题,并介绍了文件系统故障的识别与诊断方法。文章还提供了一套数据丢失后的应急措施,包括使用备份还原数据的详细步骤。此外,本文提出了一套预防措施,包括建立备份策略、定期检查和维护文件系统,以及利用RAID技术降低故障风险。通过这些内容,本文旨在帮助读者更好地理
高级MSI电路设计技巧:优化你的电路设计流程

# 摘要
随着电子设备的快速发展,MSI电路设计变得越来越复杂。本文深入探讨了MSI电路设计的基础知识、理论基础、实践技巧及高级策略,并通过案例研究提供了设计流程优化的实际应用。重点涵盖了数字逻辑基础、信号完整性问题、电源管理、高级仿真技术、自动化设计工具以及可测试性设计等方面。文中不仅介绍了MSI电路设计的关键步骤和常见问题,还探讨了新兴技术对电路设计未来的影响,特别是高密度封装和绿色电路设
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )