大数据技术概览:从Hadoop到Spark的性能优化之旅
发布时间: 2024-12-27 14:26:49 阅读量: 4 订阅数: 6 

大数据课程设计:基于Hadoop和Spark的中文手写数字实时识别系统源代码+实验报告.zip
# 摘要
大数据技术不断演进,为数据处理与分析带来了革命性的变化。本文首先回顾了大数据技术的核心概念及其演进路径,重点介绍了Hadoop生态系统架构及性能优化的方法。通过对Hadoop核心组件、性能优化理论和实践进行详细分析,本文探讨了如何通过配置和参数调优来提升Hadoop集群的性能。接着,本文深入分析了从Hadoop到Spark的技术迁越,包括两者架构的对比、Spark的优化技术和性能调优实践。在此基础上,进一步探讨了Spark生态系统中性能优化的多种技术,如并行度调整、数据序列化、SQL查询优化及实时计算优化。最后,本文展望了大数据处理的未来趋势,包括新兴技术的概览以及性能优化策略的未来发展方向,特别是机器学习与数据湖技术在大数据中的应用。
# 关键字
大数据技术;Hadoop架构;性能优化;Spark生态;实时计算;数据湖技术
参考资源链接:[XKT-510规格书英文](https://wenku.csdn.net/doc/6412b6f5be7fbd1778d4894f?spm=1055.2635.3001.10343)
# 1. 大数据技术的演进与核心概念
随着信息技术的飞速发展,大数据已成为IT领域中不可或缺的一部分。其背后的技术演进是一个长期且持续的过程,涉及数据存储、处理、分析等多个层面的技术革新。为了深入理解大数据技术,我们首先要掌握其核心概念,包括数据的生命周期、数据生态系统,以及在大数据背景下诞生的新型数据处理框架与算法。
## 1.1 大数据时代的挑战与机遇
大数据带来了前所未有的挑战:数据量巨大、速度快、类型多样,这三者的结合给传统的数据处理方法带来了巨大压力。然而,挑战与机遇并存,对这些挑战的应对催生了新的技术、新的岗位以及新的商业机会。这包括但不限于云计算、物联网(IoT)、人工智能(AI)等技术的融合应用。
## 1.2 大数据的技术层次
大数据技术可以分为几个层次,从底层的硬件存储到上层的高级分析应用,每个层次都需要特定的技术支持。例如,在存储层次,有分布式文件系统如HDFS;在计算层次,有MapReduce和Spark等计算框架;在应用层次,有数据可视化和机器学习算法等。这些技术层次共同构建了处理大规模数据的能力。
## 1.3 大数据处理的五种范式
大数据处理模式多种多样,其中较为重要的包括:批量处理、流式处理、交互式查询、图处理和机器学习。这些范式针对不同类型的应用场景,有的适用于大规模数据的离线分析,有的适合实时数据处理,还有的则是优化了数据结构以处理复杂的关系图谱。
上述章节内容为大数据技术的演进与核心概念提供了全面的概览,并奠定了后续章节深入探讨各种大数据技术的理论基础。在接下来的章节中,我们将详细探讨Hadoop生态系统的工作原理与优化策略,进而过渡到Spark等新兴技术的探索和性能提升。
# 2. Hadoop的架构与性能优化基础
## 2.1 Hadoop核心组件分析
### 2.1.1 HDFS的数据存储机制
Hadoop Distributed File System (HDFS) 是Hadoop的一个核心组件,用于在普通硬件上存储大量数据。HDFS的设计理念是首先假设硬件故障是常态,其次优化大文件的读写操作。它采用主从(Master/Slave)架构,主要包含两类节点:NameNode(主节点)和DataNode(数据节点)。
**NameNode**:是HDFS集群的管理节点,负责管理文件系统的命名空间及客户端对文件的访问。它并不存储实际的数据,而是记录各个文件的元数据,包括文件的属性、权限、目录结构、文件块的位置信息等。同时,NameNode还负责维护数据块到DataNode的映射。
**DataNode**:是真正存储数据的节点,它们负责管理连接到节点的存储。每个文件被切分成一个或多个数据块,这些数据块在集群的DataNode上分布式存储。DataNode还负责数据的创建、删除、读写等操作。
**数据存储的可靠性**:为了保证数据的可靠性,HDFS 默认将数据块复制三份。当一个DataNode节点发生故障时,NameNode可以调度其他DataNode节点上的副本继续提供服务。
```java
// Java代码示例:使用HDFS API列出HDFS根目录下的文件和目录
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
RemoteIterator<LocatedFileStatus> iterator = fs.listFiles(new Path("/"), true);
while (iterator.hasNext()) {
LocatedFileStatus fileStatus = iterator.next();
String name = fileStatus.getPath().getName();
if (fileStatus.isDirectory()) {
System.out.println("Directory: " + name);
} else {
System.out.println("File: " + name);
}
}
```
以上代码展示了如何使用HDFS API列出根目录下的文件和目录。其中,`FileSystem.get(conf)`用于获取HDFS的文件系统实例,`listFiles`方法用于列出文件和目录信息。
### 2.1.2 MapReduce的计算模型
MapReduce是一种编程模型,用于处理和生成大数据集的算法模型。它由Google提出,Hadoop MapReduce是其开源实现。该模型非常适合在大量廉价硬件设备上运行,能够处理PB级别的数据。
MapReduce作业分为两个阶段:Map阶段和Reduce阶段。
**Map阶段**:这个阶段主要负责并行处理输入数据,它将输入的数据切分成独立的块,然后通过Map函数对每个块进行处理。每个Map任务输出的结果是键值对(key-value pairs),这些键值对会被传送到Reduce阶段。
**Reduce阶段**:在Reduce阶段,所有Map任务的输出结果被合并处理。这个过程涉及到对数据进行排序(基于键值对中的key),然后把相同key的value进行合并。
```python
# Python代码示例:使用Hadoop Streaming实现MapReduce任务
# Map阶段
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
key, value = line.split("\t")
print(f"{key}\t{value}")
# Reduce阶段
#!/usr/bin/env python
from operator import itemgetter
import sys
current_key = None
current_value = []
for line in sys.stdin:
line = line.strip()
key, value = line.split("\t", 1)
if current_key == key:
current_value.append(value)
else:
if current_key:
print(f"{current_key}\t{','.join(current_value)}")
current_key = key
current_value = [value]
if current_key == key:
print(f"{current_key}\t{','.join(current_value)}")
```
上述Python脚本展示了MapReduce的基本流程。Map阶段脚本将输入数据分割成键值对并输出,而Reduce阶段脚本则负责对具有相同键的值进行汇总。
## 2.2 Hadoop性能优化理论
### 2.2.1 资源管理与调度优化
在Hadoop中,资源管理主要由YARN(Yet Another Resource Negotiator)负责。YARN的目标是将资源管理和作业调度/监控分离开来,以实现更好的资源利用率和系统可扩展性。
**资源管理器**(ResourceManager)是YARN中的主要组件,负责管理整个系统的计算资源。它为每个运行的ApplicationMaster分配Container,其中包含计算资源(如CPU和内存)。
**节点管理器**(NodeManager)运行在每个节点上,负责监控容器的资源使用情况并汇报给ResourceManager。它还负责启动和停止应用程序的Container。
**应用程序主控器**(ApplicationMaster)负责协调运行在YARN上的应用,与ResourceManager协商资源,并与NodeManager协作启动或停止Container。
资源调度优化通常涉及对YARN的调度器进行调整,以满足不同作业的资源需求。例如,FIFO调度器按提交顺序运行作业,而Capacity调度器允许多个作业并行运行,通过队列进行管理。
```xml
<!-- yarn-site.xml 配置示例 -->
<configuration>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default, high-priority</value>
</property>
<!-- 其他配置项 -->
</configuration>
```
以上配置文件定义了YARN使用的调度器为CapacityScheduler,并设置了两个队列,一个用于默认任务,另一个用于高优先级任务。
### 2.2.2 数据本地化与网络通信
数据本地化是指将计算尽可能地移动到存储数据的地方进行,以此来减少数据在网络中的传输,提高作业的运行效率。Hadoop通过将Map任务优先调度到含有其输入数据块的节点上执行,实现了数据本地化。
网络通信优化通常关注减少跨网络的数据传输,这可以通过以下方式实现:
- **合理设置副本数量**:增加副本数量能够提高数据的可用性,但同时会增加网络带宽的消耗。因此,设置合适的副本数量是优化的关键。
- **压缩数据**:在不改变数据大小的情况下,压缩数据可以减少网络传输的数据量。Hadoop支持多种压缩算法,如Gzip、Snappy等。
- **优化MapReduce任务**:合理设计MapReduce的逻辑,如通过Combiner减少Map到Reduce的数据传输量。
```sh
# Hadoop配置示例:设置数据块副本数
fs.replication=<num>
```
上述命令展示了如何通过命令行设置HDFS文件系统的数据块副本数。
## 2.3 Hadoop集群配置与性能调优实践
### 2.3.1 硬件资源分配与监控
Hadoop集群的硬件资源分配对于整体性能至关重要。通常包括对CPU、内存、磁盘和网络进行合理分配。
**CPU**:CPU资源应当根据集群上运行的作业类型来分配。对于CPU密集型作业,应当分配更多的CPU核心。
**内存**:内存主要用于NameNode的元数据管理和YARN中运行任务的内存需求。合理设置JVM堆大小,避免过多的垃圾回收开销。
**磁盘**:磁盘I/O性能直接影响到HDFS的读写性能。使用SSD代替传统的HDD磁盘可以显著提高性能,尤其是对于随机读写密集型任务。
**网络**:网络带宽对集群性能有显著影响,特别是对于跨网络的数据传输。应当选择高带宽的网络设备并优化网络拓扑结构。
监控工具如Ganglia、Nagios和Ambari可以用来监控集群的性能指标,如CPU利用率、内存消耗、磁盘I/O以及网络流量等。
### 2.3.2 Hadoop参数调优技巧
Hadoop参数调优是提升集群性能的关键步骤。调优的目标是使系统资源得到最佳利用,并减少不必要的资源消耗。
以下是一些通用的参数调优技巧:
- **调整缓冲区大小**:HDFS的读写缓冲区大小影响数据传输速率,可以调大以提高吞吐量。
- **优化垃圾回收**:合理配置JVM的垃圾回收参数,以减少GC对性能的影响。
- **IO调度器**:Hadoop 2.x版本以后,支持在DataNode上使用Linux的IO调度器,例如`deadline`调度器。
- **启用并行GC**:并行垃圾回收器通常适合于多核CPU服务器,能提升处理能力。
```sh
# Hadoop参数调优示例:调整HDFS的读写缓冲区大小
fs.local.block.size=4096m
```
以上命令演示了如何调整HDFS的读写缓冲区大小,以便于处理更大的数据块。
Hadoop集群调优是一个持续的过程,需要根据实际工作负载和应用特性,不断监控和调整参数,以达到最优的性能表现。
# 3. 从Hadoop到Spark的技术迁越
## 3.1 Hadoop与Spark的对比分析
### 3.1.1 处理模式与应用场景差异
在大数据处理领域,Hadoop和Spark是两个经常被拿来对比的框架。Hadoop主要基于磁盘的MapReduce模型进行数据处理,适合批处理场景,对大规模离线数据的处理表现出色。对于需要重复访问数据的任务,Hadoop的磁盘I/O操作频繁,这导致了它的处理速度受限。
相比之下,Spark采用了内存计算的模式,对数据处理速度有显著的提升。通过将数据加载到内存中进行处理,Spark能够以接近实时的速度提供查询结果。这种快速的数据处理能力使得Spark特别适合于需要快速迭代的算法,如机器学习和实时数据流处理等场景。
### 3.1.2 系统架构与性能特点
Hadoop系统架构中的核心组件包括HDFS和MapReduce。HDFS作为分布式文件存储系统,能够提供高吞吐量的数据访问。MapReduce编程模型允许开发者通过简单的函数式编程模式定义任务,但这种模型的运行效率在某些情况下并不能完全满足高并发、低延迟处理的要求。
而Spark则通过弹性分布式数据集(RDD)的概念,提供了更为灵活的处理模式。RDD支持容错的并行数据操作,可以保持数据在内存中进行多次计算,这样极大地减少了I/O操作。此外,Spark还引入了Spark SQL和DataFrame来支持结构化数据处理,提供了一个优化的数据处理和查询引擎。
### 3.1.3 技术优缺点
Hadoop由于其稳定性、可扩展性和成本效益,在企业中得到了广泛的应用,尤其是对于历史数据的批处理分析。但是,其数据处理速度慢,延迟高,不适合实时或准实时的场景。
Spark则在性能上有显著优势,特别是对于需要迭代计算和内存处理的任务。它能够更快地完成复杂的数据分析任务,并且具有很好的容错机制。然而,Spark对内存和CPU资源的消耗相对较高,这可能会导致在某些资源有限的环境中出现性能瓶颈。
## 3.2 Spark基础架构与运行原理
### 3.2.1 RDD的引入与作用
弹性分布式数据集(RDD)是Spark的核心抽象,它允许用户在容错的并行数据处理中进行迭代。RDD是不可变的分布式对象集合,它能够并行操作,且在出现故障时能自动恢复。
RDD的引入解决了Hadoop MapReduce模型的两个主要缺点:一是需要重复读写磁盘,降低了处理速度;二是复杂的计算任务需要多个MapReduce作业串行执行,导致效率低下。
### 3.2.2 Spark SQL与DataFrame的优化
Spark SQL是Apache Spark用来处理结构化数据的模块。它允许用户运行SQL查询,同时支持Hive表、Parquet文件和其他数据源。DataFrame是Spark SQL的一个核心概念,它是以RDD为基础的分布式数据集合,提供了更优化的执行计划和更快的执行速度。
DataFrame API为结构化数据操作提供了高度优化的执行策略,比如 Catalyst查询优化器和Tungsten执行引擎。它通过一系列的查询优化规则来提高查询性能,比如谓词下推、列式存储和向量化执行等。
## 3.3 Spark性能优化实践
### 3.3.1 内存管理与垃圾回收调优
Spark的性能在很大程度上依赖于高效的内存使用。为了确保内存资源的最优分配,Spark提供了多种内存管理选项。通过调整`spark.executor.memory`和`spark.memory.fraction`等参数,可以控制用于执行任务的内存总量和用于缓存数据的比例。
此外,垃圾回收(GC)调优对于Spark应用来说也至关重要。不恰当的GC设置会导致严重的性能问题,尤其是在处理大规模数据时。例如,合理配置`spark.executor.extraJavaOptions`参数,可以指定垃圾回收器的类型和相关配置,以减少垃圾回收的开销。
### 3.3.2 Spark作业调度机制
Spark使用了一个基于事件的调度器,它维护了一个作业队列,通过DAG调度器将作业转换为一系列的阶段。每个阶段包含多个任务,任务被提交到任务调度器进行调度执行。
在优化Spark作业时,合理配置`spark.default.parallelism`和`spark.sql.shuffle.partitions`参数非常关键。它们控制了不同作业阶段的并发度和shuffle阶段的分区数。如果这些参数配置不当,可能会导致资源浪费或任务执行过慢。
```bash
# 示例代码块:展示如何通过设置参数来优化Spark作业的内存使用和执行性能
spark-submit \
--class com.example.MySparkApp \
--master yarn \
--executor-memory 8g \
--executor-cores 4 \
--num-executors 10 \
my-spark-app.jar
```
在上述示例中,指定了执行器的内存大小为8GB,核心数为4个,并启动了10个执行器。这些参数的设置对于优化内存使用和并行度是非常重要的。
根据上述内容,本章深入探讨了从Hadoop迁移到Spark的技术演进过程,以及如何在实践中对Spark进行性能优化。通过理解这两者的对比和Spark的架构原理,开发者可以更好地利用Spark在大数据处理中的优势,优化应用程序的性能。
# 4. Spark生态系统中的性能优化
## 4.1 Spark Core优化技术
### 4.1.1 并行度与任务划分
Apache Spark 中的并行度指的是在执行作业时,任务可以被分割成多少个独立的子任务来并行运行。适当的并行度能够充分利用集群资源,提高数据处理的吞吐量和效率。Spark Core 提供了一系列的参数和方法来控制并行度,如 `spark.default.parallelism` 和 `rdd.partitions()`。
在 Spark 应用中,确保数据被均匀地分配到各个分区是至关重要的。分区数过多会导致任务调度开销,而分区数太少可能会造成内存压力过大和处理能力不足。以下是调整并行度的一些策略:
- 根据集群资源和数据量动态调整`spark.default.parallelism`,推荐值为集群核心数的2-3倍。
- 使用 `rdd.coalesce()` 或 `rdd.repartition()` 来调整分区数,前者适用于减少分区数,后者用于增加分区数。
- 当执行宽依赖操作(如 shuffle)时,Spark 会自动创建新的分区来匹配父 RDD 的分区数。
代码示例:
```scala
val inputRDD = sc.textFile("hdfs://path/to/input", minPartitions = 100)
val result = inputRDD.map(...)
```
逻辑分析和参数说明:
在上述代码中,`sc.textFile` 的第二个参数指定了初始的分区数为100,这通常是基于集群资源和输入数据大小来估计的。在进行 map 操作之前,我们可以预估该操作大概需要多少并行度。
### 4.1.2 数据序列化与持久化策略
Spark 提供了多种序列化库来减少内存占用,并且允许用户通过持久化 API 将数据缓存到内存中,以便重复使用。选择合适的序列化库和持久化级别能够显著提升性能。
- 默认使用 Java 序列化,但性能较差。可以考虑使用 Kryo 序列化,它提供了更高的序列化速度和更好的压缩性能。
- 持久化级别决定了数据在内存中的存储形式,从存储到磁盘到仅存储到内存都有涵盖。合理的级别选择能够保证计算性能和内存使用的平衡。
代码示例:
```scala
import org.apache.spark.serializer.KryoSerializer
val conf = new SparkConf()
.set("spark.serializer", classOf[KryoSerializer].getName)
.registerKryoClasses(Array(classOf[MyClass]))
val sc = new SparkContext(conf)
```
逻辑分析和参数说明:
在上述代码中,我们通过 `SparkConf` 设置了序列化器为 Kryo,并注册了需要序列化的自定义类。这种设置可以减少序列化开销,提高性能。
## 4.2 Spark SQL的深度优化
### 4.2.1 Catalyst优化器与查询执行
Spark SQL 采用 Catalyst 作为查询优化器,其内部包括解析器、逻辑计划生成器、逻辑计划优化器、物理计划生成器和代码生成器几个主要组成部分。Catalyst 应用一系列的规则来转换和优化查询计划。
- 逻辑计划优化阶段,Catalyst 会进行谓词下推、选择性列投影、连接策略重写等优化。
- 物理计划生成器会根据逻辑计划生成多个可选的物理执行方案,然后通过成本模型选择最佳方案。
- 代码生成器可以将最终的执行计划转换为优化的 Java 字节码,减少运行时开销。
代码示例:
```scala
val people = spark.read.json("hdfs://path/to/people.json")
val sqlDF = people.select("name", "age")
sqlDF.write.save("hdfs://path/to/output")
```
逻辑分析和参数说明:
在这个例子中,我们读取一个 JSON 文件并创建一个 DataFrame,然后选择特定的列进行查询。Spark SQL 的 Catalyst 优化器将自动处理查询优化的各个步骤。
### 4.2.2 DataFrame API的高级调优
DataFrame API 通过 Catalyst 优化器提供了高级的查询优化能力。用户可以利用 DataFrame API 提供的方法来进行进一步的查询优化。
- 使用 `explain` 方法可以帮助用户理解查询的执行计划。
- 使用 `hint` 方法可以为 Catalyst 优化器提供额外的优化提示。
- 利用 `DataFrame` 的 `repartition`、`coalesce` 等方法来优化数据的分布。
表格示例:
| DataFrame Method | Description | Use Case |
|------------------|----------------------------------------|--------------------------------|
| repartition | Rebalances the number of partitions | Widely varying partition sizes |
| coalesce | Merges partitions, fewer partitions | Reducing the number of partitions |
| cache | Persist the DataFrame in memory | Repeated use of the DataFrame |
| persist | Different levels of persistence | Balancing computation and memory|
逻辑分析和参数说明:
在调优 DataFrame 时,可以通过上述方法控制数据的分区数量和存储方式。例如,当发现数据倾斜导致某些任务运行过慢时,可以通过 `repartition` 方法来重新分配数据,以达到负载均衡。
## 4.3 Spark Streaming与实时计算优化
### 4.3.1 实时数据处理架构
Spark Streaming 是 Spark 生态系统中的实时数据处理模块,它提供了微批处理的编程模型来处理流数据。Spark Streaming 的架构设计允许开发者以批处理的方式编写实时数据处理应用。
- 输入数据源通过 DStream(Discretized Stream)接口接入 Spark Streaming。
- DStream 逻辑上表示一系列连续的 RDDs,它们代表数据流的不同批次。
- Spark Streaming 作业的调度周期由 `batchDuration` 参数控制,默认为 1 秒。
代码示例:
```scala
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
```
逻辑分析和参数说明:
在这个实时计算的示例中,我们创建了一个 Spark Streaming 上下文,并设置每秒处理一批数据。从一个 TCP socket 读取文本数据流,并进行词频统计。
### 4.3.2 微批处理与滑动窗口优化
微批处理是一种流处理的优化策略,其中每个微批都是一次完整的批处理计算。滑动窗口是微批处理中的一个重要概念,它允许用户基于时间窗口对流数据进行聚合分析。
- 滑动窗口能够对一段时间内的数据进行聚合操作,如计算过去5分钟内的平均值。
- 微批处理通过调整 `batchDuration` 来影响窗口大小和滑动间隔。
- 滑动窗口的聚合操作通常涉及到 `updateStateByKey` 或 `window` 函数。
代码示例:
```scala
val windowedWordCounts = wordCounts.window(Seconds(30), Seconds(10))
```
逻辑分析和参数说明:
在这个代码中,我们定义了一个30秒的窗口,并且每10秒滑动一次。这意味着我们每隔10秒计算一次过去30秒内单词出现的次数。
mermaid格式流程图示例:
```mermaid
graph LR
A[Input Data Source] -->|Streamed Data| B[DStream]
B -->|Micro-batch| C[Spark Engine]
C -->|Compute| D[RDDs]
D -->|Aggregation| E[Windowed Results]
E --> F[Output]
```
逻辑分析和参数说明:
上述流程图描述了 Spark Streaming 处理流数据到最终结果的过程。DStream 代表了一个连续的数据流,它被拆分成一系列的微批,每个微批都转换为一个 RDD 进行计算。窗口聚合计算发生在这些微批处理后,最终输出聚合结果。
# 5. 大数据处理的未来趋势与展望
大数据技术的演进正推动着信息时代的变革,引领行业走向更加智能化、自动化的未来。本章将探讨新兴的大数据技术,并展望性能优化策略的发展趋势,为IT行业专业人士提供前瞻性的洞见。
## 5.1 新兴大数据技术概览
在大数据处理领域,新兴技术的出现不仅提高了数据处理能力,而且改变了我们处理数据的方式。两个最引人注目的技术是Flink和Kubernetes。
### 5.1.1 Flink与实时处理能力
Apache Flink是一个开源流处理框架,其特点在于提供低延迟、高吞吐量的数据处理。Flink的设计重点在于快速准确的实时数据处理能力。
```mermaid
graph LR
A[实时数据源] -->|流处理| B(Flink作业)
B -->|实时计算结果| C[输出结果]
C --> D[进一步处理或展示]
```
Flink通过状态管理、事件时间和窗口操作提供了强大的实时处理能力。Flink的状态后端可以配置为内存或RocksDB,保证了状态的持久性和一致性。而事件时间处理允许开发者处理无序事件,保证了数据处理的准确性。
### 5.1.2 Kubernetes在大数据中的应用
Kubernetes,最初由Google设计,已成为容器编排的事实标准。在大数据领域,Kubernetes可以提高集群的利用率和资源的灵活性,尤其是在Hadoop和Spark这样的分布式计算系统中。
```mermaid
graph LR
A[容器化应用程序] --> B(Kubernetes集群)
B -->|调度和管理| C[高效资源利用]
C --> D[快速部署和扩展]
D --> E[高可用性和容错性]
```
Kubernetes使得大数据作业可以动态地在物理或虚拟机集群上运行,提高了资源使用率和系统的整体弹性。通过容器化大数据应用,Kubernetes可以实现快速部署和扩展,为大数据工作负载提供高度的可移植性和敏捷性。
## 5.2 性能优化策略的未来方向
随着大数据技术的发展,性能优化策略也在不断演进。我们预计,机器学习和数据湖技术将成为性能优化的重要方向。
### 5.2.1 机器学习与大数据优化结合
机器学习是一种强大的工具,可以用于优化大数据处理流程。通过建立预测模型,机器学习可以帮助我们理解数据分布和处理瓶颈,从而自动调整系统参数,实现性能优化。
### 5.2.2 数据湖技术与生态整合
数据湖技术提供了一个统一的存储解决方案,用于存储各种格式的数据,包括原始数据、半结构化数据和结构化数据。通过生态整合,数据湖可以更好地与分析工具和机器学习模型结合,为性能优化提供更全面的数据支持。
在数据湖中,我们可以利用数据湖架构的灵活性,结合数据治理策略,优化数据的存储和处理过程。例如,数据湖可以存储Hadoop处理后的数据,然后利用Spark SQL进行深入分析,或者与机器学习模型结合,提升数据价值和系统性能。
通过本章节的介绍,我们可以看到大数据技术的未来发展方向,以及如何通过新兴技术和策略进一步提升大数据处理的效率和价值。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了软件开发各个领域的专业知识,涵盖从架构设计到性能优化再到敏捷开发的广泛主题。通过深入浅出的文章,专栏旨在帮助开发人员提升技能,提高软件质量。从微服务拆分到 Scrum 框架,从大数据技术到机器学习,再到移动应用性能优化和消息队列技术,专栏涵盖了当今软件开发中至关重要的概念和技术。此外,专栏还探讨了软件架构设计模式、RESTful API 构建、数据库事务和并发控制以及 SEO 技术,为开发人员提供全面的知识和见解,以构建高性能、可扩展和用户友好的软件应用程序。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
WZl客户端补丁编辑器全流程剖析:如何从源码到成品
# 摘要
本文主要探讨了WZl客户端补丁编辑器的设计与实现,包括源码分析与理解、用户界面设计、功能模块开发、异常处理与优化以及测试与部署。首先,对编辑器的源码结构和核心技术原理进行了详细解析,阐述了补丁生成算法、压缩和解压缩机制。其次,本文详细介绍了编辑器的设计和实现过程,包括界面布局、功能模块划分以及文件读写和补丁逻辑处理的实现。同时,也对异常处理和性能优化提出了相应的策略和措施。此外,本文还对编辑器的
信息系统项目时间管理:制定与跟踪项目进度的黄金法则

# 摘要
项目时间管理是确保项目按时完成的关键环节,涉及工作分解结构(WBS)的构建、项目进度估算、关键路径法(CPM)的应用等核心技术。本文全面探讨了项目时间管理的概念、重要性、进度计划的制定和跟踪控制策略,并且分析了多项目环境中的时间管理挑战、风险评估以及时间管理的创新方法。通过案例研究,本文总结了时间管理的最佳实践与技巧,旨在为项目管理者提供实用的工具和策略,以提高项目执行效率
R420读写器GPIO脚本自动化:简化复杂操作的终极脚本编写手册

# 摘要
本文主要探讨了R420读写器与GPIO脚本的综合应用。第一章介绍了R420读写器的基本概念和GPIO脚本的应用概述。第二章详细阐述了GPIO脚本的基础知识、自动化原理以及读写器的工作机制和信号控制原理。第三章通过实践操作,说明了如何编写基本和复杂操作的GPIO脚本,并探讨了R420读写器与外部设备的交互。第四章则聚焦于自动化脚本的优化与高级应用开发,包括性能优化策略、远程控制和网络功能集成,以及整合R420
EIA-481-D实战案例:电路板设计中的新标准应用与效率提升

# 摘要
EIA-481-D标准作为电路板设计领域的一项新标准,对传统设计方法提出了挑战,同时也为行业发展带来了新机遇。本文首先概述了EIA-481-D标准的产生背景及其核心要素,揭示了新标准对优化设计流程和跨部门协作的重要性。随后,探讨了该标准在电路板设计中的实际应用,包括准备工作、标准化流程的执行以及后续的测试与评估。文章重点分析了EIA-481-D标准带来
利用Xilinx SDK进行Microblaze程序调试:3小时速成课
# 摘要
本文详细介绍了Microblaze处理器与Xilinx SDK的使用方法,涵盖了环境搭建、程序编写、编译、调试以及实战演练的全过程。首先,概述了Microblaze处理器的特点和Xilinx SDK环境的搭建,包括软件安装、系统要求、项目创建与配置。随后,深入探讨了在Microblaze平台上编写汇编和C语言程序的技巧,以及程序的编译流程和链接脚本的编写。接着,文章重点讲述了使用Xilinx
LIN 2.1与LIN 2.0全面对比:升级的最佳理由

# 摘要
随着车载网络技术的迅速发展,LIN(Local Interconnect Network)技术作为一项重要的低成本车辆通信标准,已经实现了从2.0到2.1的演进。本文旨在全面概述LIN 2.1技术的关键改进,包括性能优化、诊断能力提升及安全性增强等方面。文章深入探讨了LIN 2.1在汽车通信中的实际
【数据同步技术挑战攻略】:工厂管理系统中的应用与应对

# 摘要
数据同步技术是确保信息系统中数据准确性和一致性的重要手段。本文首先概述了数据同步技术及其理论基础,包括数据一致性的定义和同步机制类型。接着,本文探讨了数据同步技术的
【Adobe Illustrator高级技巧曝光】:20年经验设计专家分享的秘密武器库
# 摘要
本文全面探讨了Adobe Illustrator在图形设计领域的应用,涵盖了从基础操作到高效工作流程优化的各个方面。首先介绍了Illustrator的基本功能和高级图形设计技巧,包括路径、锚点、图层、蒙版以及颜色和渐变的处理。其次,强调了工作流程的优化,包括自定义工作区、智能对象与符号管理,以及输出和预览设置的高效化。接着深入讨
TRACE32高级中断调试:快速解决中断响应难题
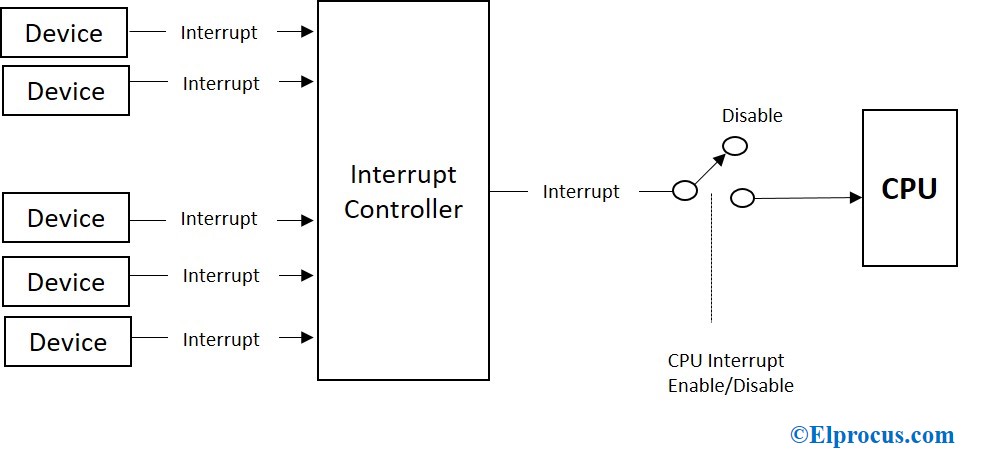
# 摘要
中断机制是现代嵌入式系统设计中的关键组成部分,直接影响到系统的响应时间和性能。本文从中断机制的基础知识出发,介绍了TRACE32工具在高级中断调试中的功能与优势,并探讨了其在实际应用中的实践技巧。通过对中断系统工作原理的理论分析,以及 TRACE32 在测量、分析和优化中断响应时间方面的技术应用,本文旨在提高开发者对中断调试的理解和操作能力。同时,通过分析常见中断问题案例,本文展示了 TRACE32 在实际项目
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )