Java File类高级主题:文件过滤器与排序的7大实用技巧
发布时间: 2024-10-21 18:20:39 阅读量: 2 订阅数: 3 
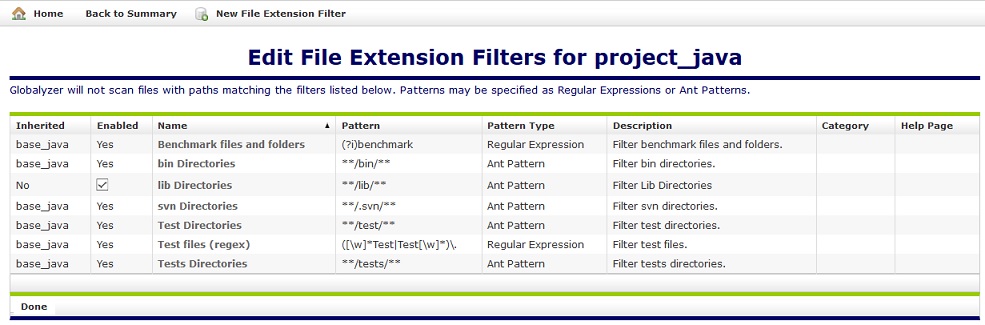
# 1. Java File类的文件过滤基础
在Java编程中,与文件系统交互是一个常见的需求,而文件过滤是文件操作的一个重要部分。`java.io.File`类作为处理文件和目录的核心类,提供了基础的文件过滤机制。本章将介绍文件过滤的基础概念,以及如何在使用`File`类进行文件操作时实现简单的文件过滤功能。
文件过滤涉及到的常见场景包括但不限于筛选出特定类型的文件(如只获取JPEG图片文件)、排除掉隐藏文件、或者基于文件的修改时间进行筛选。这些操作可以帮助开发者编写出更加高效和专业的文件管理系统。
为了实现过滤功能,开发者需要理解如何利用`File`类提供的方法,例如`list()`和`listFiles()`,这些方法都允许传入一个过滤器参数,通过这个参数可以指定过滤条件,从而得到满足特定要求的文件集合。下一章将深入探讨实现文件过滤器的具体策略。
# 2. 实现文件过滤器的策略
文件过滤是编程中经常遇到的需求,特别是在需要处理大量文件时。Java 提供了几种策略来实现文件过滤器,从而帮助开发者根据特定的规则筛选文件。本章节将详细探讨基于接口、基于Lambda表达式以及组合文件过滤器这几种策略。
## 2.1 基于接口的文件过滤器
### 2.1.1 使用FilenameFilter接口
`FilenameFilter` 是 Java 中用于文件过滤的传统接口,它要求实现 `accept` 方法来决定是否包含某个文件。以下是一个使用 `FilenameFilter` 接口的基本例子:
```java
import java.io.File;
import java.io.FilenameFilter;
public class FileListFilter {
public static void main(String[] args) {
File dir = new File("path/to/your/directory");
File[] files = dir.listFiles(new FilenameFilter() {
public boolean accept(File dir, String name) {
return name.endsWith(".txt"); // 接受所有以.txt结尾的文件
}
});
// 打印出所有符合条件的文件名
for (File *** {
System.out.println(file.getName());
}
}
}
```
### 2.1.2 实践:创建自定义文件过滤逻辑
实现自定义的文件过滤逻辑时,我们可以通过扩展 `FilenameFilter` 接口来创建自己的过滤器。例如,创建一个过滤器,不仅基于文件名后缀,而且基于文件大小或创建日期。这里是一个示例,展示了如何使用自定义的 `FilenameFilter` 实现更复杂的文件筛选:
```java
import java.io.File;
import java.io.FilenameFilter;
public class AdvancedFileFilter implements FilenameFilter {
private final String extension;
private final long sizeLimit;
public AdvancedFileFilter(String extension, long sizeLimit) {
this.extension = extension;
this.sizeLimit = sizeLimit;
}
@Override
public boolean accept(File dir, String name) {
File file = new File(dir, name);
return file.getName().endsWith(extension) && file.length() < sizeLimit;
}
public static void main(String[] args) {
File dir = new File("path/to/your/directory");
AdvancedFileFilter filter = new AdvancedFileFilter(".txt", 1024); // 文件大小限制为1KB
File[] files = dir.listFiles(filter);
for (File *** {
System.out.println(file.getName());
}
}
}
```
## 2.2 基于Lambda表达式的文件过滤器
### 2.2.1 Lambda表达式概述
从 Java 8 开始,Lambda 表达式成为了处理集合和数组时一种更简洁的写法。Lambda 表达式可以用来创建 `FilenameFilter` 的实例,使代码更简洁易读。
### 2.2.2 实践:使用Lambda表达式简化过滤器
在文件过滤中使用 Lambda 表达式可以让代码更加简洁,如下所示:
```java
import java.io.File;
public class LambdaFileFilter {
public static void main(String[] args) {
File dir = new File("path/to/your/directory");
File[] files = dir.listFiles((d, name) -> name.endsWith(".txt"));
for (File *** {
System.out.println(file.getName());
}
}
}
```
在这个例子中,我们使用了一个Lambda表达式直接创建了一个 `FilenameFilter` 实例。这种方式不仅减少了代码量,也提高了代码的可读性。
## 2.3 组合文件过滤器
### 2.3.1 逻辑组合过滤器
有时候,单个过滤条件不足以满足需求,这时可以使用逻辑组合来创建更复杂的过滤器。Java 的 `Files` 类提供了 `find` 方法来组合多个过滤条件。
### 2.3.2 实践:组合过滤器的应用场景分析
例如,我们需要找出所有是 `.txt` 文件且大小超过1KB的文件,可以使用如下的代码:
```java
import java.io.File;
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
public class CompositeFileFilter {
public static void main(String[] args) throws IOException {
Path path = Paths.get("path/to/your/directory");
Files.find(path, Integer.MAX_VALUE, (pathToCheck, attr) -> {
return attr.isRegularFile() && pathToCheck.toString().endsWith(".txt") && attr.size() > 1024;
}).forEach(System.out::println);
}
}
```
在上述代码中,`Files.find` 方法接受三个参数:起始路径、最大递归深度和一个 `BiPredicate` 接口实例。返回的 `Stream<Path>` 可以进一步处理,例如打印出满足条件的文件路径。这种方式将多个过滤条件组合,形成一个强大的过滤逻辑。
# 3. 文件排序的策略与技术
在处理文件系统中的数据时,我们常常需要按照特定的规则对文件进行排序。排序的策略与技术能够帮助我们根据文件的不同属性,如大小、名称、修改日期等,将文件以适当的顺序排列。本章节将深入探讨文件排序的基本原理,并介绍如何实现自定义排序规则以及高级排序特性的运用。
## 3.1 文件排序的基本原理
在Java中,`File`类提供了排序功能,但要理解并高效使用这些功能,我们必须了解其背后的基本原理。
### 3.1.1 File类的排序方法
Java的`File`类提供了一个名为`list()`的方法,该方法可以返回一个包含当前目录下所有文件名的字符串数组。通过传递一个`FilenameFilter`,我们可以过滤出特定类型的文件。然而,`list()`方法的排序行为依赖于底层操作系统的文件系统,因此它并不保证排序的顺序和稳定性。
为了更精确地控制文件排序,可以使用`listFiles(FileFilter)`方法,它允许我们传递一个实现了`FileFilter`接口的过滤器对象。这允许我们在获取文件列表之前就进行过滤。一旦有了文件列表,就可以使用Java的集合框架中的排序方法,如`Collections.sort()`,并传入自定义的`Comparator`来对文件进行排序。
### 3.1.2 排序依据与性能考量
在选择排序依据时,开发者需要考虑多种因素,如文件属性的访问速度和排序后的用途。文件属性包括但不限于文件大小、创建时间、最后修改时间等。
性能考量是排序实现中不可忽视的部分。如果文件数量巨大,排序操作可能会消耗大量的CPU和内存资源。为了避免这种情况,可以考虑使用外部排序算法,即将数据分批读入内存中进行排序,然后将排序后的数据写回临时文件,最终合并这些临时文件。
## 3.2 自定义排序规则
为了适应特定的业务需求,Java允许开发者通过实现`Comparator`接口来自定义排序规则。
### 3.2.1 使用Comparator接口
`Comparator`接口允许我们定义一个比较器来决定两个对象的排序顺序。例如,我们可能希望按照文件的修改日期进行排序。实现`Comparator`时,我们只需要重写`compare()`方法,该方法接受两个`File`对象作为参数,并返回一个表示它们顺序的整数值。
```java
import java.io.File;
***parator;
public class LastModifiedComparator implements Comparator<File> {
@Override
public int compare(File file1, File file2) {
long file1LastModified = file1.lastModified();
long file2LastModified = file2.lastModified();
***pare(file1LastModified, file2LastModified);
}
}
```
在上述代码中,`LastModifiedComparator`类实现了`Comparator`接口,通过比较两个文件的最后修改时间来定义排序规则。
### 3.2.2 实践:创建自定义Comparator
在实际应用中,我们可能需要对文件列表进行排序,以实现特定的业务逻辑。下面是一个使用自定义比较器对文件列表进行排序的示例:
```java
import java.io.Fi
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Go中间件跨域、鉴权与缓存:多策略保障前后端分离高效运行
# 1. Go中间件的基本概念和作用
在当今的软件开发领域,中间件作为软件开发的基础设施之一,扮演着非常重要的角色。特别是在使用Go语言进行Web服务开发时,中间件的合理运用能够显著提高代码的可维护性、安全性以及性能。本章将详细介绍Go中间件的基本概念,并探讨其在Web服务中的作用。
## 1.1 中间件的定义
中间件(Mid
【Criteria API与DTO高效转换】:构建快速数据传输的秘密

# 1. Criteria API与DTO的概念及重要性
在现代的软件开发中,特别是在Java领域,Criteria API和数据传输对象(DTO)是构建数据访问层和数据交换层的重要组件。本章将介绍它们的基本概念和在企业级应用中的重要性。
## 1.1 什么是Criteria API
Criteria API是Java持久化API(Java Persistence API, JPA
代码重构与设计模式:同步转异步的CompletableFuture实现技巧
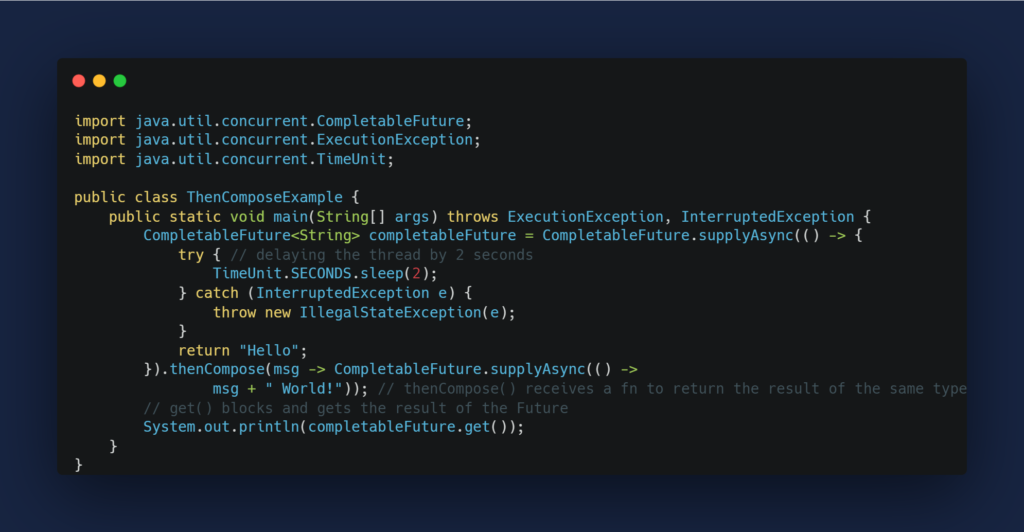
# 1. 代码重构与设计模式基础
在当今快速发展的IT行业中,软件系统的维护和扩展成为一项挑战。通过代码重构,我们可以优化现有代码的结构而不改变其外部行为,为软件的可持续发展打下坚实基础。设计模式,作为软件工程中解决特定问题的模板,为代码重构提供了理论支撑和实践指南。
## 1.1 代码重构的重要性
重构代码是软件开发生命周期中不
***模型验证进阶:数据绑定和验证控件的深度应用
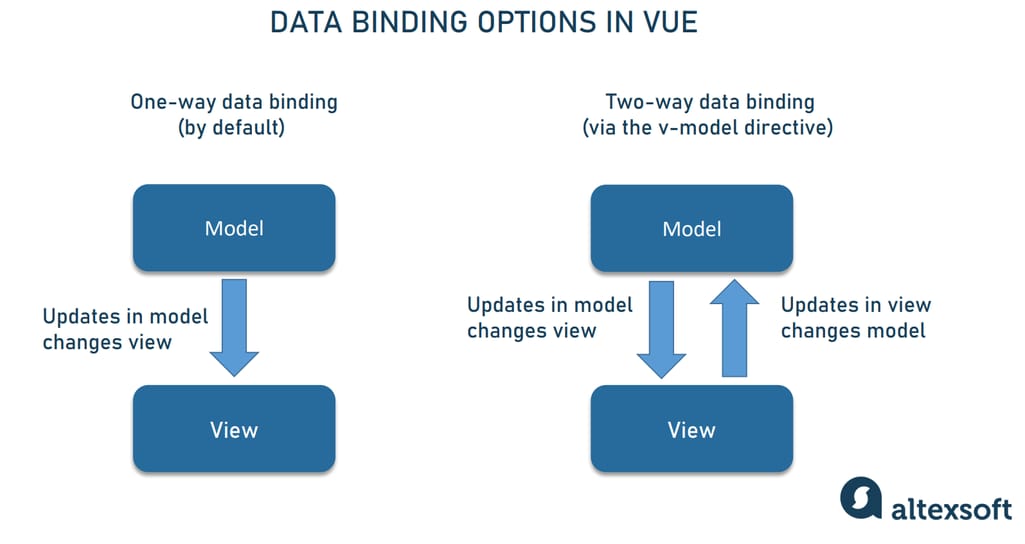
# 1. 模型验证的基本概念和重要性
在IT行业,特别是在软件开发领域,模型验证是确保应用程序可靠性的关键环节。它是指通过一系列检查确保数据符合特定规则和预期格式的过程。验证的过程不仅提高了数据的准确性和完整性,同时在预防安全性问题、提高用户体验和减轻后端处理压力方面扮演着重要角色。
## 1.1 验证的概念和目的
模型验证的核心目的在于确认用户输入或
Go语言自定义错误类型与测试:编写覆盖错误处理的单元测试
# 1. Go语言错误处理基础
在Go语言中,错误处理是构建健壮应用程序的重要部分。本章将带你了解Go语言错误处理的核心概念,以及如何在日常开发中有效地使用错误。
## 错误处理理念
Go语言鼓励显式的错误处理方式,遵循“不要恐慌”的原则。当函数无法完成其预期工作时,它会返回一个错误值。通过检查这个
C++14 std::make_unique:智能指针的更好实践与内存管理优化

# 1. C++智能指针与内存管理基础
在现代C++编程中,智能指针已经成为了管理内存的首选方式,特别是当涉及到复杂的对象生命周期管理时。智能指针可以自动释放资源,减少内存泄漏的风险。C++标准库提供了几种类型的智能指针,最著名的包括`std::unique_ptr`, `std::shared_ptr`和`std::weak_ptr`。本章将重点介绍智能指针的基本概念,以及它
【配置管理实用教程】:创建可重用配置模块的黄金法则
# 1. 配置管理的概念和重要性
在现代信息技术领域中,配置管理是保证系统稳定、高效运行的基石之一。它涉及到记录和控制IT资产,如硬件、软件组件、文档以及相关配置,确保在复杂的系统环境中,所有的变更都经过严格的审查和控制。配置管理不仅能够提高系统的可靠性,还能加快故障排查的过程,提高组织对变化的适应能力。随着企业IT基础设施的不断扩张,有效的配置管理已成为推动IT卓越运维的必要条件。接
C#日志记录经验分享:***中的挑战、经验和案例
# 1. C#日志记录的基本概念与必要性
在软件开发的世界里,日志记录是诊断和监控应用运行状况的关键组成部分。本章将带领您了解C#中的日志记录,探讨其重要性并揭示为什么开发者需要重视这一技术。
## 1.1 日志记录的基本概念
日志记录是一个记录软件运行信息的过程,目的是为了后续分析和调试。它记录了应用程序从启动到执行过程中发生的各种事件。C#中,通常会使用各种日志框架来实现这一功能,比如NLog、Log4Net和Serilog等。
## 1.2 日志记录的必要性
日志文件对于问题诊断至关重要。它们能够提供宝贵的洞察力,帮助开发者理解程序在生产环境中的表现。日志记录的必要性体现在以下
Go errors包与RESTful API:创建一致且用户友好的错误响应格式

# 1. 理解RESTful API中的错误处理
RESTful API的设计哲学强调的是简洁、一致和面向资源,这使得它在构建现代网络服务中非常流行。然而,与任何技术一样,API在日常使用中会遇到各种错误情况。正确处理这些错误不仅对于维护系统的健壮性和用户体验至关
C++17函数式编程效率提升:constexpr lambda表达式的奥秘

# 1. C++17中的constexpr函数简介
C++17对 constexpr 函数进行了进一步的强化,使其成为现代C++编程中不可忽视的一部分。constexpr 关键字用于声明那些可以被编译器计算的常量表达式。这些函数的优势在于,它们能在编译时计算出结果,从而提高程序性能,并减少运行时的计算负担。
## 1.1 constexpr
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )