xml.dom.minidom.Node的代码复用:模块化与函数式编程的深度应用
发布时间: 2024-10-15 19:00:56 阅读量: 2 订阅数: 3 

# 1. xml.dom.minidom.Node概述
## 1.1 xml.dom.minidom.Node简介
`xml.dom.minidom.Node` 是 Python 中 `xml.dom.minidom` 模块的一个核心类,用于表示 XML 文档的一个节点。它是 DOM API 的一部分,允许开发者以编程方式访问和修改 XML 文档的结构。`Node` 类提供了丰富的接口,用于操作节点的属性、子节点、父节点等。
## 1.2 Node 的基本属性和方法
每个 `Node` 对象都有多种属性和方法,例如 `nodeType` 属性可以告诉你当前节点的类型,如元素节点、文本节点等;`nodeName` 和 `nodeValue` 属性则分别返回节点的标签名和值。此外,`Node` 还提供了一系列方法,如 `appendChild`、`removeChild`、`replaceChild` 等,用于操作节点的子节点。
## 1.3 Node 在 XML 处理中的作用
在处理 XML 数据时,`Node` 类扮演着至关重要的角色。它不仅能够帮助我们构建和解析 XML 结构,还能通过事件监听和遍历机制,实现对 XML 文档的深度访问和修改。理解并熟练使用 `Node` 类,是进行 XML 数据处理和开发的基础。
```python
# 示例代码:创建一个 XML 文档并访问其节点
from xml.dom import minidom
# 创建一个简单的 XML 文档
xml_string = "<root><child>Example</child></root>"
dom_tree = minidom.parseString(xml_string)
# 获取根节点并遍历子节点
root_node = dom_tree.documentElement
for child in root_node.childNodes:
print(child.nodeName, child.nodeValue)
```
在上述示例中,我们创建了一个包含根节点和一个子节点的简单 XML 文档,并使用 `minidom` 模块的 `parseString` 方法将其解析为 DOM 树。随后,我们访问根节点的子节点,并打印其名称和值。这段代码展示了如何操作 XML 文档的节点。
# 2. 模块化编程基础
## 2.1 模块化的概念与重要性
### 2.1.1 什么是模块化编程
模块化编程是一种编程范式,它将程序分解成独立的、可复用的模块,每个模块实现一组相关的功能。这种编程方式有助于提高代码的可维护性、可测试性和可复用性。在模块化编程中,模块通常拥有定义良好的接口和隐藏的内部实现,这样可以在不影响其他部分的情况下对模块内部进行修改。
### 2.1.2 模块化的优势
模块化编程具有以下优势:
- **高内聚低耦合**:模块内部功能紧密相关,模块间相互独立,减少了代码间的依赖。
- **代码复用**:通用的功能可以封装在模块中,被多次复用,减少重复代码。
- **便于维护**:模块化代码结构清晰,更容易定位和修复问题。
- **团队协作**:不同的开发人员可以独立开发不同的模块,提高团队效率。
## 2.2 模块化在xml.dom.minidom.Node中的应用
### 2.2.1 模块化的实现方式
在`xml.dom.minidom.Node`中,模块化的实现方式通常涉及到将DOM操作封装成独立的函数或类,这些函数或类可以被其他部分的代码调用。例如,我们可以创建一个模块来处理节点的创建、查询和修改等操作。
```python
# 模块化示例代码
class NodeModule:
@staticmethod
def create_element(tag_name):
"""创建一个元素节点"""
return Node.createElement(tag_name)
@staticmethod
def get_child_nodes(parent_node):
"""获取子节点列表"""
return parent_node.childNodes
# 使用示例
from xml.dom.minidom import parseString
def main():
xml_content = "<root><child>Content</child></root>"
dom = parseString(xml_content)
node_module = NodeModule()
children = node_module.get_child_nodes(dom.documentElement)
for child in children:
print(child.data)
if __name__ == "__main__":
main()
```
### 2.2.2 模块化代码的优势分析
上述代码展示了如何将DOM操作封装在一个模块中,这样做有以下优势:
- **封装性**:将DOM操作封装在`NodeModule`类中,隐藏了实现细节,只暴露了必要的接口。
- **复用性**:`NodeModule`可以被任何需要操作DOM的代码复用,无需重复编写相似的代码。
- **可维护性**:如果DOM操作的实现需要改变,只需修改`NodeModule`中的相应方法,其他使用该模块的代码无需改动。
## 2.3 模块化编程的最佳实践
### 2.3.1 代码组织与模块划分
良好的代码组织和模块划分是模块化编程的关键。以下是一些最佳实践:
- **单一职责**:每个模块应有明确的职责,避免功能过于复杂。
- **接口定义**:清晰定义模块的接口,包括输入参数和返回值。
- **模块划分**:根据功能将代码划分为不同的模块,例如工具模块、业务逻辑模块等。
### 2.3.2 模块化中的依赖管理
在模块化编程中,合理管理模块间的依赖关系至关重要。以下是一些建议:
- **最小化依赖**:尽量减少模块间的依赖,使模块尽可能独立。
- **依赖抽象**:使用接口或抽象类来定义依赖,使得依赖的具体实现可以在不影响模块的情况下替换。
- **依赖注入**:通过构造函数或方法参数将依赖注入模块,增加模块的灵活性和可测试性。
```python
# 依赖注入示例代码
class NodeProcessor:
def __init__(self, node_module):
self.node_module = node_module
def process_node(self, node):
"""处理节点"""
# 假设有一个具体的处理逻辑
return self.node_module.get_child_nodes(node)
# 使用示例
node_processor = NodeProcessor(NodeModule())
root_node = NodeProcessor.process_node(node_processor, dom.documentElement)
for child in root_node:
print(child.data)
```
在本章节中,我们介绍了模块化编程的基础知识,包括模块化的概念、优势、实现方式以及最佳实践。通过具体的代码示例,我们展示了如何在`xml.dom.minidom.Node`中应用模块化编程,以及如何组织代码和管理依赖。模块化编程是提高代码质量的重要手段,它有助于构建清晰、可维护和可扩展的软件系统。
# 3. 函数式编程核心概念
## 3.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PycURL错误处理必修课:网络请求异常处理的艺术
# 1. PycURL简介与安装
## 1.1 PycURL简介
PycURL是一个用于处理URL请求的库,它是libcurl的Python封装,提供了一种高效的方式来执行多种类型的网络请求。与Python标准库中的urllib相比,PycURL在处理大量请求时具有更好的性能和灵活性。
## 1.2 安装PycURL
安装PycURL可以通过Python的包管理工具pip来完成。在命令行中输入以下命令即
Django multipartparser与其他库的集成:如Celery、Redis与Django表单的实践指南
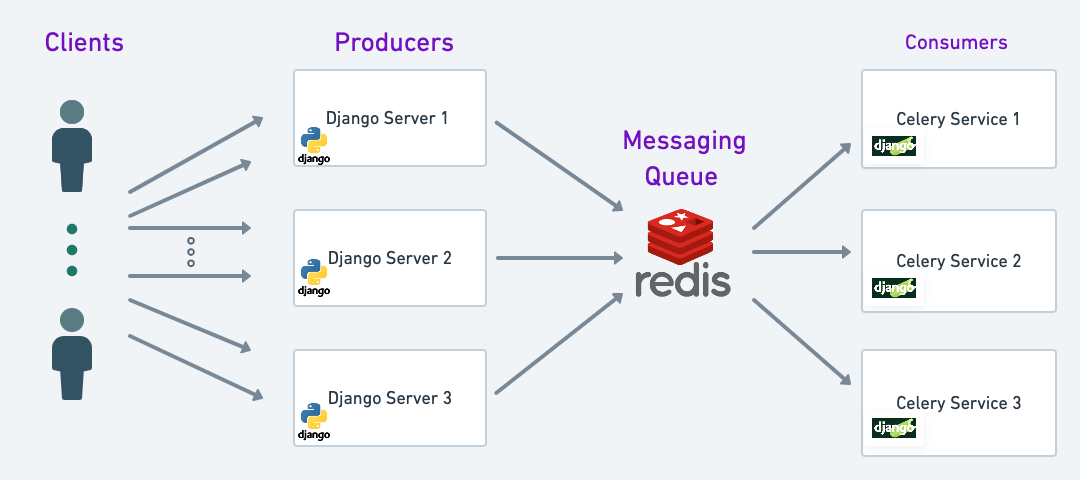
# 1. Django multipartparser简介
Django作为一个功能强大的Python Web框架,提供了一套完整的工具来处理文件上传。`multipartparser`是Django内部用于解析`multipart/form-data`请求体的模块,它为开发者提供了一种高效的方式来处理文件上传的底层细节。
## 什么是Django mult
Numpy.linalg高级应用:奇异值分解(SVD)的深度解析
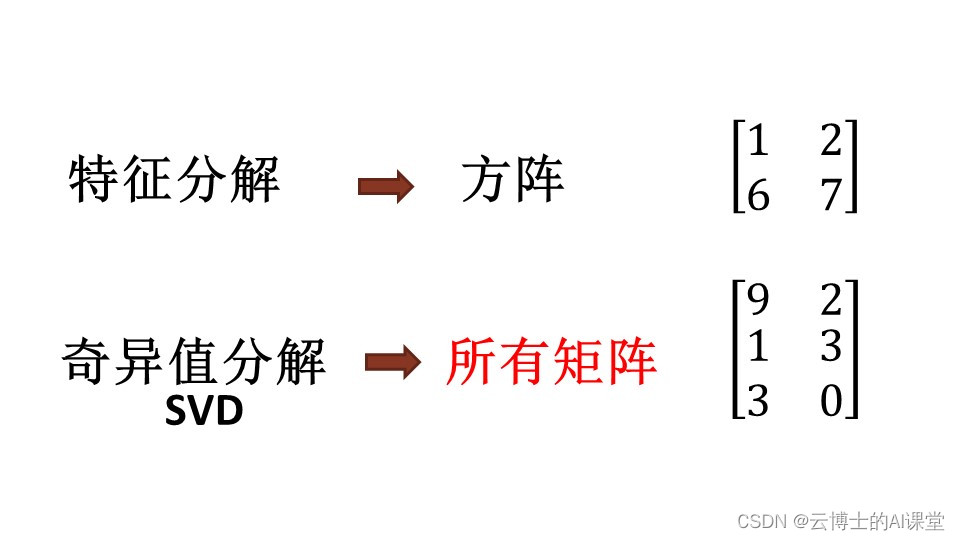
# 1. 奇异值分解(SVD)概述
## 1.1 SVD的定义与重要性
奇异值分解(SVD)是线性代数中一种强大的矩阵分解技术,它能够将任意矩阵分解为三个特定矩阵的乘积。这种分解不仅揭示了数据的内在结构,而且在数据压缩、图像处理、机器学习等领域有着广泛的应用。SVD的重要性在于它能够处理非方阵,且分解后的奇异值能够反映矩阵的特征,这对于理解数据的本质特征至关重要。
##
【敏捷开发中的Django版本管理】:如何在敏捷开发中进行有效的版本管理
# 1. 敏捷开发与Django版本管理概述
## 1.1 敏捷开发与版本控制的关系
在敏捷开发过程中,版本控制扮演着至关重要的角色。敏捷开发强调快速迭代和响应变化,这要求开发团队能够灵活地管理代码变更,确保各个迭代版本的质量和稳定性。版本控制工具提供了一个共享代码库,使得团队成员能够并行工作,同时跟踪每个成员的贡献。在Django项目中,版本控制不仅能帮助开发者管理代码
Pygments.filter模块版本升级:平滑过渡到新版本
# 1. Pygments.filter模块概述
Pygments 是一个用Python编写的通用语法高亮工具,广泛应用于源代码高亮显示。而 `Pygments.filter` 模块是其核心组件之一,它提供了一种灵活的方式来创建和应用代码过滤器,从而实现源代码的高亮显示。这个模块允许开发者自定义过滤器规则,以适应各种复杂的高亮需求。在本章中,我们将对
xml.dom.minidom.Node的数据绑定:将XML数据映射到Python对象的创新方法

# 1. XML数据绑定的概念与重要性
XML数据绑定是将XML文档中的数据与应用程序中的数据结构进行映射的过程,它是数据交换和处理中的一项关键技术。在现代软件开发中,数据绑定的重要性日益凸显,因为它简化了数据访问和管理,使得开发者可以更加专注于业务
【Django文件校验:性能监控与日志分析】:保持系统健康与性能
# 1. Django文件校验概述
## 1.1 Django文件校验的目的
在Web开发中,文件上传和下载是常见的功能,但它们也带来了安全风险。Django文件校验机制的目的是确保文件的完整性和安全性,防止恶意文件上传和篡改。
## 1.2 文件校验的基本流程
文件校验通常包括以下几个步骤:
1. **文件上传**:用户通过Web界面上传文件。
Python Zip库的文档与性能分析:提升代码可读性和性能瓶颈的解决策略

# 1. Python Zip库概述
Python的Zip库为处理ZIP格式的压缩文件提供了便利,无需借助外部工具即可在Python环境中实现文件的压缩和解压。ZIP文件格式广泛应用于文件归档、备份以及跨平台的数据交换,因其高效的压缩率和跨平台的兼容性而被广泛使用。本章将介绍Zip库的基本概念和应用,为后续章节的深入学习打下基础。
## 2. Zip库的理论基础
###
【data库的API设计】:设计易于使用的data库接口,让你的代码更友好

# 1. data库API设计概述
在当今快速发展的信息技术领域,API(应用程序编程接口)已成为不同软件系统之间交互的桥梁。本文将深入探讨`data`库API的设计,从概述到实际应用案例分析,为读者提供一个全面的视角。
## API设计的重要性
Pylons WebSockets实战:实现高效实时通信的秘诀

# 1. Pylons WebSockets基础概念
## 1.1 WebSockets简介
在Web开发领域,Pylons框架以其强大的功能和灵活性而闻名,而WebSockets技术为Web应用带来了全新的实时通信能力。WebSockets是一种网络通信协议,它提供了浏览器和服务器之间全双工的通信机制,这意味着服务器可以在任何时候向客户端发送消息,而不仅仅是响应客户端的请求。
## 1.2 WebSockets的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )