xml.dom.minidom.Node高级应用:属性和文本节点的管理秘籍
发布时间: 2024-10-15 18:04:36 阅读量: 3 订阅数: 3 

# 1. xml.dom.minidom.Node概述
在本文中,我们将深入探讨 `xml.dom.minidom.Node`,它是 Python 中处理 XML 数据的一个重要对象。`Node` 对象代表了 XML 文档中的一个基本单元,可以是元素、文本、注释等。在 `xml.dom.minidom` 中,`Node` 提供了一套丰富的方法来访问和操作 XML 文档的结构和内容。
为了更好地理解 `Node` 的功能,我们将从基础概念出发,逐步深入了解其操作方法,包括节点的创建、插入、删除和替换,以及属性和文本节点的管理。最后,我们将通过实例解析,展示 `Node` 在 HTML 和 XML 文档中的具体应用。
请跟随本文的节奏,让我们一起探索 `xml.dom.minidom.Node` 的强大功能和应用潜力。
# 2. xml.dom.minidom.Node的基础操作
## 2.1 Node的基本概念和类型
在XML文档中,Node是一个基本的构建块,它可以代表一个元素、属性、文本内容或者是文档本身。在`xml.dom.minidom`模块中,Node对象提供了多种方法来操作这些基本元素。Node类型包括元素节点(ELEMENT_NODE)、属性节点(ATTRIBUTE_NODE)、文本节点(TEXT_NODE)、文档节点(DOCUMENT_NODE)等。
### 2.1.1 Node类型
Node对象在`xml.dom.minidom`中具有不同的类型,每种类型对应XML文档中的不同结构:
- ELEMENT_NODE:代表一个元素节点,如`<tag>content</tag>`中的`<tag>`和`</tag>`。
- ATTRIBUTE_NODE:代表一个属性节点,如`<tag attribute="value">`中的`attribute="value"`。
- TEXT_NODE:代表文本内容节点,如`<tag>content</tag>`中的`content`。
- DOCUMENT_NODE:代表整个文档,是所有节点的根节点。
### 2.1.2 Node对象的属性
Node对象提供了多个属性来获取节点的信息:
- `nodeType`:返回节点类型,如1代表ELEMENT_NODE。
- `nodeName`:返回节点的名称,对于元素节点,是标签名;对于属性节点,是属性名;对于文本节点,是"#text"。
- `nodeValue`:返回节点的值,对于文本节点,是文本内容;对于属性节点,是属性值。
- `attributes`:返回节点的属性列表。
## 2.2 Node的创建和插入
创建和插入Node是操作XML文档的基础。我们可以使用`minidom`提供的方法来创建新的节点,并将其插入到文档中。
### 2.2.1 创建新Node
在minidom中,我们可以使用`createElement`, `createTextNode`, `createAttribute`等方法来创建不同类型的节点:
```python
from xml.dom.minidom import Document
# 创建一个新的文档实例
doc = Document()
# 创建一个元素节点
element = doc.createElement("example")
# 创建一个文本节点
text = doc.createTextNode("Hello, World!")
# 创建一个属性节点
attribute = doc.createAttribute("attributeName")
attribute.value = "attributeValue"
```
### 2.2.2 插入Node
创建Node后,我们需要将其插入到文档中。可以使用`appendChild`, `insertBefore`, `replaceChild`等方法:
```python
# 将文本节点作为元素节点的子节点插入
element.appendChild(text)
# 将属性节点添加到元素节点
element.setAttributeNode(attribute)
# 将元素节点添加到文档的根节点
doc.documentElement.appendChild(element)
```
## 2.3 Node的删除和替换
在XML文档操作中,有时需要删除或者替换现有的Node。`xml.dom.minidom`提供了相应的方法来实现这些操作。
### 2.3.1 删除Node
要删除一个Node,可以使用`removeChild`方法:
```python
# 假设有一个已存在的节点node_to_remove
# 从其父节点中删除它
parent_node.removeChild(node_to_remove)
```
### 2.3.2 替换Node
要替换一个Node,可以使用`replaceChild`方法:
```python
# 创建一个新节点new_node
new_node = doc.createTextNode("New text content")
# 替换已存在的节点
parent_node.replaceChild(new_node, old_node)
```
## 2.4 Node操作的实践应用
下面我们通过一个实际的例子来展示Node的创建、插入、删除和替换操作:
```python
from xml.dom.minidom import Document
# 创建文档
doc = Document()
# 创建元素节点
parent_element = doc.createElement("parent")
doc.documentElement.appendChild(parent_element)
# 创建子元素节点
child_element = doc.createElement("child")
parent_element.appendChild(child_element)
# 创建文本节点
text_node = doc.createTextNode("Hello, Minidom!")
child_element.appendChild(text_node)
# 删除节点
# 假设我们要删除文本节点
parent_element.removeChild(text_node)
# 替换节点
# 假设我们要替换子元素节点为一个新的文本节点
new_text_node = doc.createTextNode("Replaced content!")
parent_element.replaceChild(new_text_node, child_element)
```
在本章节中,我们详细介绍了`xml.dom.minidom.Node`的基础操作,包括Node的基本概念和类型、创建和插入Node、删除和替换Node。通过具体的代码示例和逻辑分析,我们展示了如何在Python中使用minidom模块来操作XML文档中的节点。
通过本章节的介绍,你可以掌握如何在`xml.dom.minidom`中进行Node的基础操作,为进一步深入理解和应用XML文档操作打下坚实的基础。
# 3. xml.dom.minidom.Node的属性管理
#### 3.1 Node的属性获取和设置
在使用xml.dom.minidom进行XML或者HTML文档的解析时,我们经常会遇到需要获取和设置元素属性的情况。Node对象的属性主要通过NamedNodeMap接口进行管理,我们可以使用`attributes`属性来访问一个节点的所有属性。
**代码示例:**
```python
from xml.dom import minidom
# 解析XML文档
dom = minidom.parseString('<root attr="value"><child /></root>')
root = dom.documentElement
# 获取属性
attr = root.attributes.getNamedItem('attr')
print(f"获取到的属性值为: {attr.value}")
# 设置属性
root.attributes.setNamedItem(minidom.Attr('newattr', 'newvalue'))
print(f"设置新属性后的root节点: {root.toxml()}")
```
**参数说明:**
- `getNamedItem(name)`:通过属性名获取对应的属性节点。
- `setNamedItem(attr)`:设置一个属性节点。
**逻辑分析:**
在上述代码中,我们首先解析了一个XML字符串并获取了根节点。然后,我们使用`getNamedItem`方法通过属性名`'attr'`获取了一个属性节点,并打印了其值。接着,我们创建了一个新的属性节点`newattr`并使用`setNamedItem`方法将其设置到了根节点上。
#### 3.2 常见的属性操作方法
在xml.dom.minidom中,除了基本的获取和设置属性的方法外,还有一些常用的操作属性的方法,例如删除属性、遍历属性等。
**代码示例:**
```python
from xml.dom import minidom
# 解析XML文档
dom = minidom.parseString('<root attr="value"><child /></root>')
root = dom.documentElement
# 删除属性
root.attributes.removeNamedItem('attr')
# 遍历属性
for attr in root.attributes.values():
print(f"属性名: {attr.nodeName}, 属性值: {attr.value}")
print(f"删除属性后的root节点: {root.toxml()}")
```
**参数说明:**
- `removeNamedItem(name)`:通过属性名删除一个属性节点。
- `values()`:返回属性节点的迭代器。
**逻辑分析:**
在上述代码中,我们首先删除了根节点的一个属性。然后,我们遍历了根节点的所有属性,并打印了它们的名字和值。最后,我们打印了删除属性后的根节点的XML表示。
#### 3.3 属性操作的实践应用
属性操作在实际应用中非常广泛,比如在处理配置文件、用户信息等场景中,我们经常需要根据条件修改XML或HTML文档中的属性值。
**实践案例:**
假设我们有一个用户配置文件,我们需要根据用户的权限等级动态地添加或修改属性。
**代码示例:**
```python
from xml.dom import minidom
# 假设这是用户配置文件
users_config = '''<?xml version="1.0"?>
<users>
<user level="basic">
<name>John Doe</name>
</user>
<user level="advanced">
<name>Jane Smith</name>
</user>
</users>'''
# 解析XML文档
dom = minidom.parseString(users_config)
users = dom.documentElement
# 假设我们要给所有基本等级用户添加一个新的属性
for user in users.getElementsByTagName('user'):
if user.attributes.getNamedItem('level').value == 'basic':
new_attr = minidom.Attr('discount', '10')
user.attributes.setNamedItem(new_attr)
print(dom.toxml())
```
**逻辑分析:**
在这个实践案例中,我们首先解析了一个XML字符串,该字符串表示用户配置文件。然后,我们遍历了所有的`<user>`节点,检查了它们的`level`属性。如果用户的等级是`'basic'`,我们创建了一个新的属性`discount`并将其添加到了该用户节点上。最后,我们打印了修改后的XML文档。
**总结:**
通过本章节的介绍,我们可以看到xml.dom.minidom中Node的属性管理是非常灵活的。我们可以获取、设置、删除和遍历属性,这些操作在处理XML或HTML文档时非常有用。在实际应用中,这些属性操作可以帮助我们根据不同的需求动态地修改文档内容。
# 4. xml.dom.minidom.Node的文本节点管理
## 4.1 文本节点的创建和插入
在处理XML或HTML文档时,文本节点是最基本的组成部分之一。文本节点通常包含实际的文本数据,它们可以作为元素的子节点存在。在`xml.dom.minidom`模块中,文本节点可以通过`createTextNode`方法创建,并通过`appendChild`方法插入到DOM树中。以下是一个创建和插入文本节点的示例代码:
```python
from xml.dom import minidom
# 创建一个DOM文档
dom = minidom.Document()
# 创建一个元素节点
element = dom.createElement("example")
# 创建一个文本节点
text = dom.createTextNode("Hello, XML!")
# 将文本节点插入到元素节点中
element.appendChild(text)
# 将元素节点插入到DOM文档中
dom.appendChild(element)
# 将DOM文档转换为字符串并打印出来
print(***rettyxml())
```
在上述代码中,我们首先创建了一个DOM文档实例,然后创建了一个名为"example"的元素节点。接着,我们创建了一个文本节点,并将其作为子节点插入到元素节点中。最后,我们将元素节点插入到DOM文档中,并将其转换为格式化的XML字符串进行打印。
### 逻辑分析
1. **创建DOM文档**:`minidom.Document()`用于创建一个新的DOM文档对象。
2. **创建元素节点**:`createElement`方法用于创建一个新的元素节点。
3. **创建文本节点**:`createTextNode`方法用于创建一个新的文本节点。
4. **插入文本节点**:通过`appendChild`方法将文本节点添加到元素节点中。
5. **插入元素节点**:将元素节点插入到DOM文档的根节点下。
6. **输出XML**:`toprettyxml`方法用于将DOM文档转换为格式化的XML字符串。
### 参数说明
- `minidom.Document()`:创建一个新的DOM文档实例。
- `createElement(tag)`:创建一个具有指定标签名的元素节点。
- `createTextNode(data)`:创建一个包含指定数据的文本节点。
- `appendChild(node)`:将一个节点添加到另一个节点的子节点列表的末尾。
## 4.2 文本节点的删除和替换
文本节点在XML/HTML文档中可能会因为各种原因需要被删除或替换。在`xml.dom.minidom`中,文本节点的删除可以通过`removeChild`方法实现,而文本节点的替换可以通过先删除原有文本节点,然后创建新文本节点并插入到相应位置来完成。以下是一个文本节点删除和替换的示例代码:
```python
from xml.dom import minidom
# 假设我们已经有一个包含文本节点的DOM文档
dom = minidom.parseString("<root><example>Hello, XML!</example></root>")
# 获取根节点
root = dom.documentElement
# 获取元素节点
element = root.firstChild
# 获取文本节点
text = element.firstChild
# 删除文本节点
element.removeChild(text)
# 创建新的文本节点
new_text = dom.createTextNode("Hello, New World!")
# 将新的文本节点插入到元素节点中
element.appendChild(new_text)
# 将DOM文档转换为字符串并打印出来
print(***rettyxml())
```
在上述代码中,我们首先解析了一个包含文本节点的XML字符串,并获取了根节点和元素节点。然后,我们获取了元素节点中的文本节点,并使用`removeChild`方法将其删除。接着,我们创建了一个新的文本节点,并将其插入到元素节点中。最后,我们将DOM文档转换为格式化的XML字符串进行打印。
### 逻辑分析
1. **解析XML**:`minidom.parseString`方法用于解析XML字符串并创建DOM文档。
2. **获取根节点**:`documentElement`属性用于获取DOM文档的根节点。
3. **获取元素节点**:通过访问子节点列表来获取目标元素节点。
4. **获取文本节点**:通过访问元素节点的子节点列表来获取文本节点。
5. **删除文本节点**:使用`removeChild`方法删除文本节点。
6. **创建新的文本节点**:使用`createTextNode`方法创建新的文本节点。
7. **插入新的文本节点**:使用`appendChild`方法将新的文本节点插入到元素节点中。
8. **输出XML**:`toprettyxml`方法用于将DOM文档转换为格式化的XML字符串。
## 4.3 文本节点操作的实践应用
文本节点的操作在实际应用中非常常见,尤其是在处理包含大量文本数据的XML文档时。例如,你可能需要对文档中的特定文本进行搜索、修改或删除。在这一节中,我们将通过一个具体的例子来展示文本节点操作的实际应用场景。
### 实践应用案例
假设我们有一个XML文档,记录了一系列的产品信息,包括产品名称和描述。我们的任务是将所有描述中的"old"替换为"new"。
#### 步骤一:加载XML文档
首先,我们需要加载XML文档。这里我们可以使用`minidom.parse`方法来加载一个XML字符串或文件。
```python
from xml.dom import minidom
# 加载XML文档
dom = minidom.parseString("<products><product><name>Product1</name><description>Old description</description></product></products>")
```
#### 步骤二:遍历文本节点
接下来,我们需要遍历所有描述节点,并对每个节点的内容进行处理。
```python
# 获取所有产品节点
products = dom.getElementsByTagName("product")
# 遍历每个产品节点
for product in products:
# 获取描述节点
description = product.getElementsByTagName("description")[0]
# 获取描述节点的文本内容
text_content = description.firstChild.nodeValue
# 替换文本内容
new_text_content = text_content.replace("old", "new")
# 创建新的文本节点
new_description = dom.createTextNode(new_text_content)
# 替换原来的描述节点
description.replaceChild(new_description, description.firstChild)
```
#### 步骤三:输出修改后的XML
最后,我们将修改后的DOM文档转换为字符串并打印出来。
```python
# 输出修改后的XML
print(***rettyxml())
```
### 代码逻辑分析
1. **加载XML文档**:使用`minidom.parseString`方法加载XML字符串。
2. **遍历产品节点**:通过`getElementsByTagName`方法获取所有产品节点。
3. **获取描述节点**:在每个产品节点中获取描述节点。
4. **获取文本内容**:获取描述节点的文本内容。
5. **替换文本内容**:使用字符串的`replace`方法替换文本中的"old"为"new"。
6. **创建新的文本节点**:使用`createTextNode`方法创建新的文本节点。
7. **替换原节点**:使用`replaceChild`方法将原来的文本节点替换为新的文本节点。
8. **输出XML**:使用`toprettyxml`方法将DOM文档转换为格式化的XML字符串。
### 实践应用总结
通过上述示例,我们展示了如何使用`xml.dom.minidom`模块中的文本节点操作方法来实现对XML文档中特定文本内容的搜索和替换。这种文本处理技术在数据清洗、信息提取等场景中非常有用,能够帮助开发者高效地管理和操作大量的文本数据。
# 5. xml.dom.minidom.Node的高级应用
在本章节中,我们将深入探讨xml.dom.minidom.Node的高级应用,包括节点的遍历和搜索、复制和克隆以及事件处理。这些高级特性为DOM操作提供了更为复杂和强大的功能,使得开发者能够更加灵活和高效地处理XML和HTML文档。
## 5.1 Node的遍历和搜索
遍历DOM树是处理XML和HTML文档的基础操作之一。xml.dom.minidom提供了多种方法来遍历节点,包括使用`childNodes`属性和`parentNode`属性,以及利用XPath表达式进行高级搜索。
### 5.1.1 使用childNodes属性
`childNodes`属性返回当前节点的所有子节点的列表,这包括元素节点、文本节点以及注释节点等。通过循环访问这些子节点,我们可以遍历整个DOM树。
### 5.1.2 使用parentNode属性
`parentNode`属性可以获取任何节点的父节点,这对于向上遍历DOM树非常有用。通过递归地访问`parentNode`,我们可以遍历到DOM树的根节点。
### 5.1.3 XPath表达式的使用
XPath是一种在XML文档中查找信息的语言,它允许开发者使用路径表达式来选择XML文档中的节点或节点集。在xml.dom.minidom中,`evaluate()`方法可以用来执行XPath表达式。
#### 代码示例
以下代码展示了如何使用XPath表达式来查找文档中所有的`<div>`元素:
```python
from xml.dom import minidom
# 加载XML文档
dom_tree = minidom.parseString('<html><body><div id="a"><span>Text 1</span></div><div id="b"><span>Text 2</span></div></body></html>')
# 使用XPath表达式查找所有的<div>元素
div_elements = dom_tree.getElementsByTagName('div')
for div in div_elements:
print(div.toxml())
```
### 5.1.4 遍历和搜索实践应用
#### 实践步骤
1. 创建一个XML或HTML文档的DOM树。
2. 使用`childNodes`遍历DOM树。
3. 使用`parentNode`向上遍历到根节点。
4. 使用`evaluate()`方法执行XPath表达式。
#### 实践示例
假设我们有以下XML文档:
```xml
<library>
<book category="fiction">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
</book>
<book category="learning">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
</book>
</library>
```
我们想要遍历这个文档,并打印出所有的`<title>`元素。
```python
from xml.dom import minidom
# 加载XML文档
dom_tree = minidom.parseString("""
<library>
<book category="fiction">
<title lang="en">Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
</book>
<book category="learning">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
</book>
</library>
""")
# 使用XPath表达式查找所有的<title>元素
titles = dom_tree.getElementsByTagName('title')
for title in titles:
print(title.toxml())
```
## 5.2 Node的复制和克隆
节点的复制和克隆是DOM操作中常用的功能,它允许开发者创建节点的副本。xml.dom.minidom提供了`cloneNode()`方法来克隆一个节点,包括其所有属性和子节点。
### 5.2.1 cloneNode()方法
`cloneNode()`方法用于克隆一个节点。它接受一个布尔参数,当参数为`True`时,克隆包括子节点在内的完整节点;当参数为`False`时,只克隆节点本身,不包括其子节点。
### 5.2.2 克隆节点的实践应用
#### 实践步骤
1. 选择要克隆的节点。
2. 调用`cloneNode()`方法进行克隆。
#### 实践示例
假设我们有以下XML文档:
```xml
<library>
<book category="fiction">
<title>Harry Potter</title>
</book>
</library>
```
我们想要克隆`<library>`节点。
```python
from xml.dom import minidom
# 加载XML文档
dom_tree = minidom.parseString("""
<library>
<book category="fiction">
<title>Harry Potter</title>
</book>
</library>
""")
# 克隆<library>节点
cloned_library = dom_tree.documentElement.cloneNode(True)
# 打印克隆后的XML
print(cloned_library.toxml())
```
## 5.3 Node的事件处理
DOM事件处理允许开发者在节点上绑定事件处理器,以响应不同的事件,如点击、鼠标悬停等。在xml.dom.minidom中,我们可以使用`registerHandler()`方法来注册事件处理器。
### 5.3.1 registerHandler()方法
`registerHandler()`方法用于注册事件处理器。它需要两个参数:事件类型和事件处理器函数。
### 5.3.2 事件处理的实践应用
#### 实践步骤
1. 创建一个事件处理器函数。
2. 使用`registerHandler()`注册事件处理器。
#### 实践示例
假设我们有以下HTML文档:
```html
<!DOCTYPE html>
<html>
<head>
<title>DOM Event Example</title>
</head>
<body>
<button id="myButton">Click me!</button>
</body>
</html>
```
我们想要在点击按钮时打印出一条消息。
```python
from xml.dom import minidom
# 加载HTML文档
dom_tree = minidom.parseString("""
<!DOCTYPE html>
<html>
<head>
<title>DOM Event Example</title>
</head>
<body>
<button id="myButton">Click me!</button>
</body>
</html>
""")
# 定义事件处理器函数
def print_message(event):
print("Button clicked!")
# 获取按钮元素
button = dom_tree.getElementsByTagName('button')[0]
# 注册点击事件处理器
dom_tree.registerHandler('click', print_message)
# 打印DOM树
print(dom_tree.toxml())
```
请注意,上述代码示例仅供参考,实际使用时需要根据具体的应用场景和需求进行调整和优化。
# 6. xml.dom.minidom.Node的实例解析
## 6.1 Node在HTML文档中的应用实例
在本节中,我们将通过具体的实例来解析`xml.dom.minidom.Node`在HTML文档中的应用。我们将从简单的HTML结构开始,逐步展示如何使用`Node`来操作HTML元素。
### 示例1:获取HTML文档的根节点
```python
from xml.dom import minidom
# 解析HTML字符串
html_str = "<html><head><title>示例页面</title></head><body><h1>欢迎来到我的网站</h1></body></html>"
dom_tree = minidom.parseString(html_str)
# 获取根节点
root = dom_tree.documentElement
print(root)
```
在这个示例中,我们首先使用`minidom.parseString`方法解析了一个简单的HTML字符串,并获取了DOM树的根节点`html`。
### 示例2:遍历HTML文档的子节点
```python
# 遍历根节点的所有子节点
children = root.childNodes
for child in children:
print(child.nodeName)
```
在这个示例中,我们遍历了根节点`html`的所有子节点,打印出了每个子节点的节点名称。
### 示例3:修改HTML文档中的内容
```python
# 查找<title>节点并修改内容
titles = root.getElementsByTagName('title')
if titles:
titles[0].firstChild.data = '新页面标题'
# 输出修改后的HTML字符串
print(dom_tree.toxml())
```
在这个示例中,我们查找了所有`<title>`节点,并修改了第一个`<title>`节点的内容。然后,我们使用`toxml()`方法输出了修改后的HTML字符串。
### 示例4:删除HTML文档中的节点
```python
# 删除<body>节点中的<h1>节点
h1 = root.getElementsByTagName('h1')[0]
parent = h1.parentNode
if parent:
parent.removeChild(h1)
# 输出删除后的HTML字符串
print(dom_tree.toxml())
```
在这个示例中,我们首先获取了`<h1>`节点,然后找到了它的父节点`<body>`,并使用`removeChild`方法删除了`<h1>`节点。最后,我们输出了删除后的HTML字符串。
## 6.2 Node在XML文档中的应用实例
在本节中,我们将通过一个XML文档的例子来展示`Node`的应用。
### 示例1:解析XML文档的根节点
```python
from xml.dom import minidom
# 解析XML字符串
xml_str = "<library><book><title>学习XML</title><author>张三</author></book></library>"
dom_tree = minidom.parseString(xml_str)
# 获取根节点
root = dom_tree.documentElement
print(root)
```
在这个示例中,我们解析了一个包含书籍信息的XML字符串,并获取了根节点`library`。
### 示例2:添加新的XML节点
```python
# 创建新的<book>节点
new_book = dom_tree.createElement('book')
# 创建新的<author>节点并设置文本
author = dom_tree.createElement('author')
author_text = dom_tree.createTextNode('李四')
author.appendChild(author_text)
# 将<author>节点添加到<book>节点
new_book.appendChild(author)
# 将<book>节点添加到根节点
root.appendChild(new_book)
# 输出修改后的XML字符串
print(dom_tree.toxml())
```
在这个示例中,我们创建了一个新的`<book>`节点,并为其添加了一个`<author>`子节点。然后,我们将其添加到根节点`library`下。
### 示例3:修改XML文档中的节点属性
```python
# 查找所有的<book>节点
books = root.getElementsByTagName('book')
for book in books:
# 为每个<book>节点添加一个属性
book.setAttribute('category', '技术')
# 输出修改后的XML字符串
print(dom_tree.toxml())
```
在这个示例中,我们查找了所有的`<book>`节点,并为每个节点添加了一个名为`category`的属性。
## 6.3 Node在复杂XML文档中的应用实例
在本节中,我们将通过一个更复杂的XML文档实例来深入探讨`Node`的应用。
### 示例1:复杂的XML文档结构
```xml
<library>
<book>
<title>学习XML</title>
<author>张三</author>
<published>2021</published>
</book>
<book>
<title>深入Python</title>
<author>李四</author>
<published>2020</published>
</book>
</library>
```
在这个示例中,我们有一个包含多本书籍信息的XML文档。
### 示例2:解析并修改复杂XML文档
```python
from xml.dom import minidom
# 解析XML字符串
xml_str = """<library>
<book>
<title>学习XML</title>
<author>张三</author>
<published>2021</published>
</book>
<book>
<title>深入Python</title>
<author>李四</author>
<published>2020</published>
</book>
</library>"""
dom_tree = minidom.parseString(xml_str)
# 获取根节点
root = dom_tree.documentElement
# 修改第一本书的出版年份
published_year = root.getElementsByTagName('published')[0]
published_year.firstChild.data = '2022'
# 输出修改后的XML字符串
print(dom_tree.toxml())
```
在这个示例中,我们首先解析了上述XML文档,并获取了根节点`library`。然后,我们找到了第一个`<book>`节点中的`<published>`节点,并修改了它的内容。
### 示例3:删除复杂XML文档中的节点
```python
# 删除第二本书
second_book = root.getElementsByTagName('book')[1]
root.removeChild(second_book)
# 输出修改后的XML字符串
print(dom_tree.toxml())
```
在这个示例中,我们删除了XML文档中的第二本书。我们首先获取了第二个`<book>`节点,并使用`removeChild`方法将其从根节点`library`中删除。
通过上述三个小节的实例,我们可以看到`xml.dom.minidom.Node`在处理HTML和XML文档时的强大功能。无论是获取、添加、修改还是删除节点,`Node`都提供了一系列丰富的方法来满足我们的需求。在实际应用中,这些操作可以极大地提升我们处理文档的效率和灵活性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Werkzeug.exceptions库的异常链:深入理解异常链的用法和好处
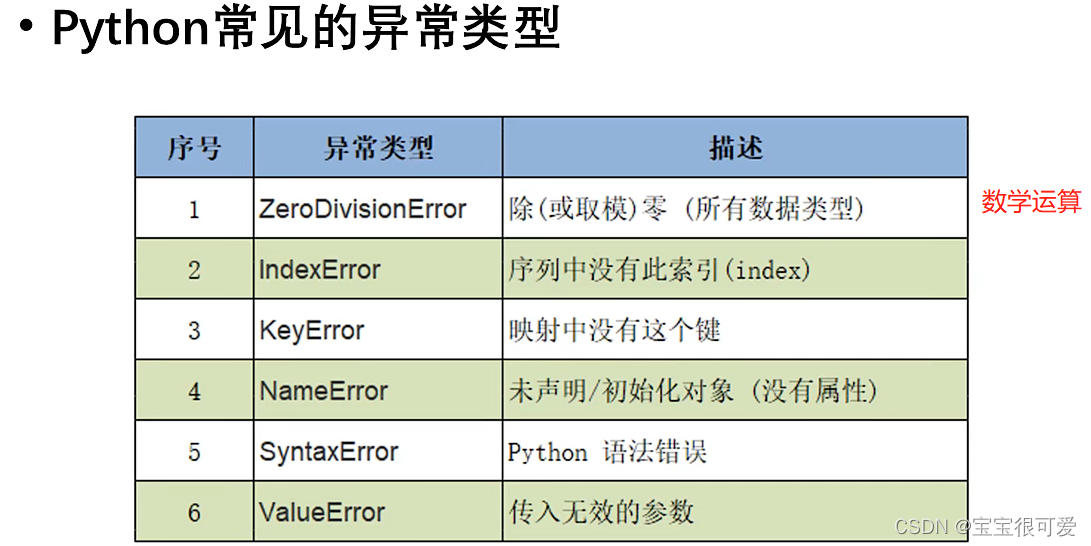
# 1. Werkzeug.exceptions库概述
Werkzeug.exceptions库是Python编程语言中Flask框架的一个重要组成部分,它提供了一系列预定义的异常类,这些异常类在Web应用开发中扮演着重要的角色。通过定义不同类型的HTTP异常,Werkzeug允许开发者以一种标准化的方式来表达错误,并且能够与Web服务器进行有效交互。
## 1.1 Werkz
Pylons WebSockets实战:实现高效实时通信的秘诀

# 1. Pylons WebSockets基础概念
## 1.1 WebSockets简介
在Web开发领域,Pylons框架以其强大的功能和灵活性而闻名,而WebSockets技术为Web应用带来了全新的实时通信能力。WebSockets是一种网络通信协议,它提供了浏览器和服务器之间全双工的通信机制,这意味着服务器可以在任何时候向客户端发送消息,而不仅仅是响应客户端的请求。
## 1.2 WebSockets的
Pygments社区资源利用:解决Pygments.filter难题
# 1. Pygments概述与基本使用
## 1.1 Pygments简介
Pygments是一个Python编写的通用语法高亮工具,它可以处理多种编程语言的源代码。它将代码转换为带有颜色和格式的文本,使得阅读和理解更加容易。Pygments不仅提供了命令行工具,还通过API的形式支持集成到其他应用中。
## 1.2 安装Pygments
PycURL与REST API构建:构建和调用RESTful服务的实践指南

# 1. PycURL简介与安装
## PycURL简介
PycURL是一款强大的Python库,它是libcurl的Python接口,允许开发者通过Python代码发送网络请求。与标准的urllib库相比,PycURL在性能上有着显著的优势
Django multipartparser的缓存策略:提高响应速度与减少资源消耗的6大方法

# 1. Django multipartparser简介
## Django multipartparser的概念
Django作为一个强大的Python Web框架,为开发者提供了一系列工具来处理表单数据。其中,`multipa
Numpy.linalg在优化问题中的应用:线性和非线性规划问题的求解
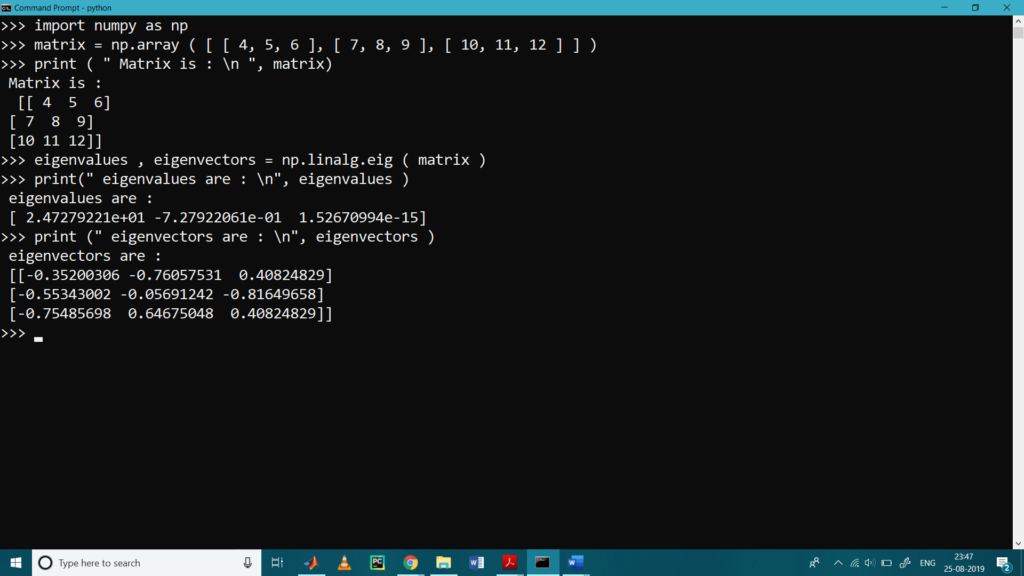
# 1. Numpy.linalg库简介
## 1.1 Numpy库概述
Numpy是一个强大的Python库,专门用于进行大规模数值计算,尤其是在科学计算领域。它提供了高性能的多维数组对象以及用于处理这些数组的工具。
## 1.2 Numpy.linalg模块介绍
Numpy.linalg模块是Numpy库中专门用于线性代数计算的模块,包含了大量的线性代数运算函数
Twisted.web.client与asyncio的集成:探索异步编程的新纪元

# 1. Twisted.web.client与asyncio的基本概念
## 1.1 Twisted.web.client简介
Twisted.web.client是一个强大的网络客户端库,它是Twisted框架的一部分,提供了构建异步HTTP客户端的能力。Twisted是一个事件驱动的网络编程框架,它允许开发者编写非阻塞的网络
【敏捷开发中的Django版本管理】:如何在敏捷开发中进行有效的版本管理
# 1. 敏捷开发与Django版本管理概述
## 1.1 敏捷开发与版本控制的关系
在敏捷开发过程中,版本控制扮演着至关重要的角色。敏捷开发强调快速迭代和响应变化,这要求开发团队能够灵活地管理代码变更,确保各个迭代版本的质量和稳定性。版本控制工具提供了一个共享代码库,使得团队成员能够并行工作,同时跟踪每个成员的贡献。在Django项目中,版本控制不仅能帮助开发者管理代码
【Django文件校验:性能监控与日志分析】:保持系统健康与性能
# 1. Django文件校验概述
## 1.1 Django文件校验的目的
在Web开发中,文件上传和下载是常见的功能,但它们也带来了安全风险。Django文件校验机制的目的是确保文件的完整性和安全性,防止恶意文件上传和篡改。
## 1.2 文件校验的基本流程
文件校验通常包括以下几个步骤:
1. **文件上传**:用户通过Web界面上传文件。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )