Python深度学习新体验:用PyTorch轻松创建张量
发布时间: 2024-12-12 03:03:12 阅读量: 11 订阅数: 19 

基于PyTorch技术的Python深度学习

# 1. 深度学习与PyTorch简介
## 1.1 深度学习的兴起
深度学习作为人工智能领域的重要分支,近年来在图像识别、语音处理、自然语言处理等多个方面取得了显著的进展。其核心在于构建多层的神经网络模型,以此来模拟人脑处理信息的机制,从大量数据中自动提取特征并进行复杂的决策。
## 1.2 PyTorch的诞生与特点
PyTorch诞生于2016年,由Facebook的人工智能研究团队开发。作为一种开源的机器学习库,PyTorch以其动态计算图和灵活的操作方式,迅速获得了广大研究人员和工程师的喜爱。其动态计算图(也称为定义即运行)允许模型在运行时进行修改,易于构建复杂的网络结构。
## 1.3 PyTorch的应用场景
PyTorch的易用性和灵活性使其在研究和工业界都有广泛的应用。从快速原型设计到大规模的深度学习项目,PyTorch都能够提供强大的支持。它不仅适用于学术研究中的算法验证,也支持产品级别的应用部署,是连接研究与实践的桥梁。
通过这一章的介绍,读者能够了解到深度学习和PyTorch的基本概念,以及PyTorch如何在当前技术发展中扮演关键角色,为接下来深入学习PyTorch打下基础。
# 2. PyTorch基础操作
## 2.1 张量的概念和创建
### 2.1.1 张量的定义与属性
张量是PyTorch中最基本的数据结构,它是一个多维数组,用于存储数值数据,并且在深度学习中用于表示输入数据、模型参数、中间数据以及输出数据。在形式上,张量可以看作是N维数组(在数学中称为张量),它与NumPy的ndarrays类似,但是张量可以在GPU上进行加速计算,这对于深度学习的高效训练至关重要。
张量的属性包括数据类型(dtype)、形状(shape)以及它们所存储在的设备(device)。数据类型指明了张量中元素的数据格式,比如32位浮点数(`torch.float32`)或64位整数(`torch.int64`)。形状是一个整数元组,表示张量的维度大小。设备指的是张量存储的位置,可以是CPU或GPU。
### 2.1.2 张量的创建方法
在PyTorch中创建张量的方法有很多种。最基本的创建方式是使用`torch.tensor()`函数,它可以将现有的数据结构转换为张量。例如:
```python
import torch
data = [[1, 2], [3, 4]]
tensor = torch.tensor(data)
```
此外,PyTorch还提供了多种函数来创建特定形状和属性的张量:
- `torch.zeros()`:创建一个全零的张量。
- `torch.ones()`:创建一个全一的张量。
- `torch.arange()`:创建一个包含均匀间隔值的张量。
- `torch.linspace()`:创建一个包含线性间隔值的张量。
- `torch.eye()`:创建一个2D单位矩阵张量。
- `torch.normal()` 和 `torch.randint()`:分别用于创建具有正态分布和均匀分布随机数的张量。
在创建张量时,我们经常需要指定形状和数据类型。例如:
```python
# 创建一个3x3的全一浮点型张量
tensor_ones = torch.ones(3, 3, dtype=torch.float32)
# 创建一个5x5的随机正态分布整型张量
tensor_rand = torch.randn(5, 5, dtype=torch.int64)
```
创建张量后,我们可以使用`.shape`属性来查看其形状,使用`.device`属性来查看其存储位置。
## 2.2 张量的基本操作
### 2.2.1 张量的数学运算
PyTorch提供了非常丰富的张量操作,用于执行各种数学运算。这些操作包括但不限于:
- 算术运算:加(`+`)、减(`-`)、乘(`*`)、除(`/`)。
- 点乘:使用`torch.dot()`进行点乘运算。
- 矩阵乘法:使用`torch.matmul()`执行矩阵乘法。
- 广播机制:允许不同形状的张量进行算术运算。
例如:
```python
# 矩阵乘法示例
tensor_a = torch.ones(2, 3)
tensor_b = torch.ones(3, 2)
product = torch.matmul(tensor_a, tensor_b)
```
### 2.2.2 张量的维度变换
维度变换是改变张量形状的操作,包括添加(增加)维度、移除(减少)维度和改变维度顺序。常见的维度变换函数有:
- `view()`:改变张量的形状而不改变其数据。
- `unsqueeze()` 和 `squeeze()`:分别为增加和减少一个维度。
- `permute()`:重新排列张量的维度。
例如:
```python
# 使用view改变形状
tensor = torch.randn(2, 3)
reshaped_tensor = tensor.view(3, 2)
# 使用unsqueeze增加维度
tensor = torch.randn(2, 3)
tensor_unsqueezed = tensor.unsqueeze(0) # 增加一个维度变为 [1, 2, 3]
# 使用squeeze减少维度
tensor = torch.randn(1, 2, 1)
tensor_squeezed = tensor.squeeze() # 减少两个维度变为 [2]
```
### 2.2.3 张量的索引与切片
张量的索引和切片类似于Python中的列表和NumPy数组。通过指定索引或切片范围,我们可以获取或修改张量的子集。
```python
# 索引张量示例
tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])
row = tensor[1] # 获取第二行数据
# 切片张量示例
slice = tensor[:, 1] # 获取所有行的第二列
```
## 2.3 自动微分与梯度计算
### 2.3.1 计算图和自动微分机制
自动微分是深度学习中实现梯度下降的关键技术。PyTorch使用动态计算图,即定义即运行(define-by-run)的策略。这意味着计算图是根据代码的执行动态构建的。`torch.autograd`模块是PyTorch自动微分的核心,它跟踪对张量执行的所有操作,并构建用于计算梯度的计算图。
每个张量都有一个`.grad_fn`属性,它指向创建张量的`Function`,即这个张量是如何从其他张量计算而来的。当调用`.backward()`时,PyTorch将自动沿着计算图反向传播,并计算所有梯度。
### 2.3.2 损失函数与梯度下降
在深度学习中,损失函数衡量了模型预测值与真实值之间的差异。PyTorch提供了许多内置的损失函数,比如均方误差(MSE)、交叉熵损失(CrossEntropyLoss)等。模型训练过程通常涉及损失函数的计算和梯度下降优化。
梯度下降算法通过更新模型参数,以减少损失函数的值。在PyTorch中,参数的更新是通过`.backward()`方法和`.step()`方法联合实现的。`.backward()`方法用于计算损失函数相对于参数的梯度,`.step()`方法则用于更新参数值。
```python
# 一个简单的梯度下降示例
# 假设我们有一个简单的模型参数 w
w = torch.tensor(1.0, requires_grad=True)
# 定义学习率
learning_rate = 0.01
# 定义损失函数(这里只是一个示例)
def compute_loss(x, y):
return (w * x - y) ** 2
# 假设我们有一些数据点和对应的标签
data = torch.tensor([1.0, 2.0, 3.0])
targets = torch.tensor([3.0, 4.0, 5.0])
# 进行梯度下降优化
for _ in range(100):
loss = compute_loss(data, targets)
loss.backward() # 计算梯度
with torch.no_grad(): # 更新过程不记录梯度
w -= learning_rate * w.grad # 更新参数
w.grad.zero_() # 清除梯度
```
通过上述过程,PyTorch可以自动地完成从数据加载、模型定义到训练和优化的全过程。在后续的章节中,我们将进一步探索如何使用PyTorch构建复杂的深度学习模型,并讨论如何实现高效的数据处理、模型训练、保存与加载模型等高级技巧。
# 3. 构建深度学习模型
深度学习是当今AI领域的核心力量之一,它通过构建复杂的人工神经网络模型来模拟人脑的工作方式,以处理和分析数据。在第二章中,我们介绍了PyTorch的基本操作,为构建深度学习模型打下了坚实的基础。本章将深入探讨如何使用PyTorch构建和训练这些模型,同时介绍模型的保存和加载机制,以确保模型可以从一个阶段迁移到另一个阶段。
## 3.1 神经网络基本组件
深度学习模型通常由多个简单的单元——神经元组成。这些神经元通过不同层次的网络结构进行连接,构成了复杂的人工神经网络。
### 3.1.1 线性层和激活函数
神经网络的核心在于线性层和非线性激活函数。线性层执行加权求和操作,而激活函数为神经网络引入了非线性因素,这是模型能否学习复杂模式的关键。
在PyTorch中,线性层通常通过`torch.nn.Linear(in_features, out_features)`来定义,其中`in_features`是输入特征的数量,`out_features`是输出特征的数量。线性层可以被看作是在输入向量上应用一个线性变换。
激活函数如ReLU、Sigmoid和Tanh等,可以通过`torch.nn.ReLU()`等模块直接调用。例如:
```python
import torch.nn as nn
# 定义一个线性层,输入特征为1024,输出特征为512
linear_layer = nn.Linear(1024, 512)
# 应用ReLU激活函数
activation_function = nn.ReLU()
```
### 3.1.2 数据加载与预处理
深度学习模型的训练需要大量数据,因此数据加载和预处理是构建模型不可或缺的步骤。在PyTorch中,`torch.utils.data.Dataset`和`torch.utils.data.DataLoader`类是处理数据的关键组件。
使用自定义的`Dataset`类需要实现`__init__`, `__len__`, 和 `__getitem__` 方法,以便加载和处理数据。`DataLoader`类则用于迭代数据集并提供多线程加载。
```python
from torch.utils.data import Dataset, DataLoader
# 定义一个自定义数据集类
class CustomDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
# 实例化数据集
my_data = CustomDataset(my_data_points)
# 创建一个数据加载器
data_loader = DataLoader(my_data, batch_size=32, shuffle=True)
```
## 3.2 模型的搭建与训练
在数据准备就绪之后,我们可以开始搭建和训练模型了。
### 3.2.1 使用Sequential定义模型
使用`torch.nn.Sequential`类可以非常方便地按顺序堆叠多个模块来构建一个神经网络模型。这种方式的代码简洁,易于理解和维护。
```python
model = nn.Sequential(
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
```
### 3.2.2 模型训练与评估
训练深度学习模型涉及定义一个损失函数和一个优化器。损失函数用于评估模型预测值与实际值之间的差异,而优化器则用于调整模型参数以最小化损失函数。
PyTorch提供了许多内置的损失函数和优化器,如`nn.CrossEntropyLoss`和`torch.optim.SGD`。模型训练通常包含在循环中进行多个epoch的迭代,在每个epoch中,数据会通过网络进行前向传播、损失计算、反向传播和参数更新。
```python
# 定义损失函数和优化器
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练循环
for epoch in range(num_epochs):
running_loss = 0.0
for inputs, labels in data_loader:
# 前向传播
predictions = model(inputs)
# 计算损失
loss = loss_function(predictions, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch+1}, Loss: {running_loss/len(data_loader)}')
```
## 3.3 模型的保存与加载
一旦模型训练完成,我们通常希望将其保存下来,以便将来可以重新加载模型并进行预测或进一步的训练。
### 3.3.1 模型状态字典的保存与加载
PyTorch允许我们保存模型的“

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 PyTorch 中张量的创建、操作和处理。从初学者指南到高级技巧,您将了解如何构建和操作张量、执行形状变换、进行索引和切片、合并和分割数据、执行矩阵乘法、转换数据类型、应用聚合函数、在 PyTorch 和 NumPy 之间转换张量,以及优化张量操作以获得最佳性能。本专栏旨在帮助您掌握 PyTorch 中张量的基础知识,并提升您的数据处理技能,从而为深度学习和科学计算应用奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ROST软件数据可视化技巧:让你的分析结果更加直观动人
:max_bytes(150000):strip_icc()/ScreenShot2019-10-28at1.25.36PM-ab811841a30d4ee5abb2ff63fd001a3b.jpg)
参考资源链接:[ROST内容挖掘系统V6用户手册:功能详解与操作指南](https://wenku.csdn.net/doc/5c20fd2fpo?spm=1055.2635.3001.10343)
RTCM 3.3协议深度剖析:如何构建秒级精准定位系统

参考资源链接:[RTCM 3.3协议详解:全球卫星导航系统差分服务最新标准](https://wenku.csdn.net/doc/7mrszjnfag?spm=1055.2635.3001.10343)
# 1. RTCM 3.3协议简介及其在精准定位中的作用
RTCM (Radio Technical Co
提升航空数据传输效率:AFDX网络数据流管理技巧
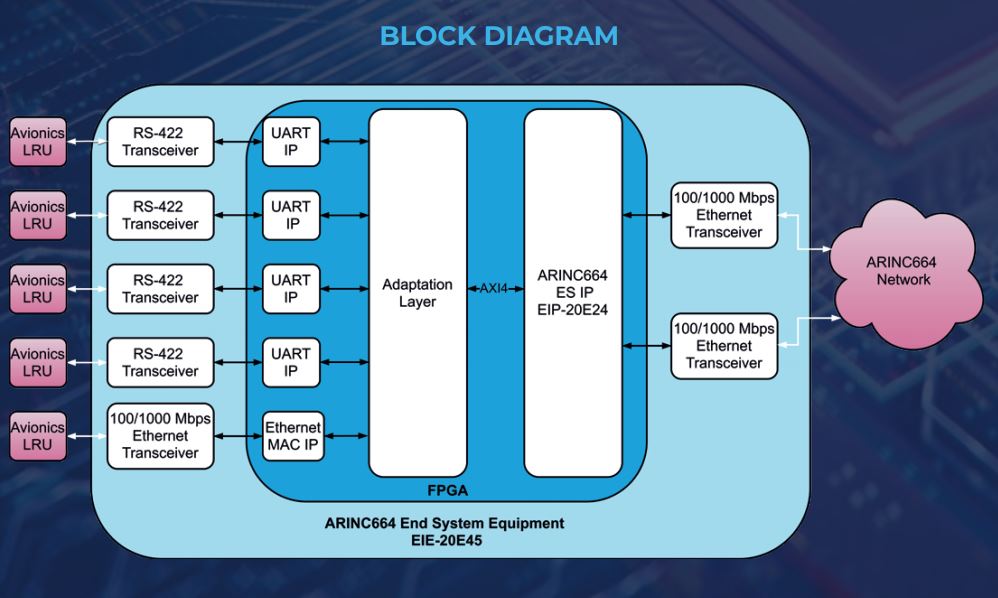
参考资源链接:[AFDX协议/ARINC664中文详解:飞机数据网络](https://wenku.csdn.net/doc/66azonqm6a?spm=1055.2635.3001.10343)
# 1. AFDX网络技术概述
## 1.1 AFDX网络技术的起源与应用背景
AFDX (Avionics Full-Duplex Switched Ethernet) 网络技术,是专为航空电子通信设计
软件开发者必读:与MIPI CSI-2对话的驱动开发策略
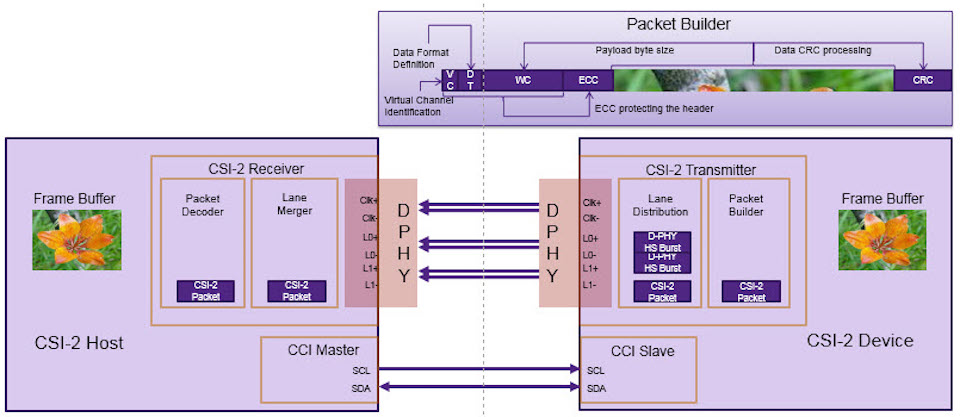
参考资源链接:[mipi-CSI-2-标准规格书.pdf](https://wenku.csdn.net/doc/64701608d12cbe7ec3f6856a?spm=1055.2635.3001.10343)
# 1. MIPI CSI-2协议概述
在当今数字化和移动化的世界里,移动设备图像性能的提升是用户体验的关键部分。为
【PCIe接口新革命】:5.40a版本数据手册揭秘,加速硬件兼容性分析与系统集成
参考资源链接:[2019 Synopsys PCIe Endpoint Databook v5.40a:设计指南与版权须知](https://wenku.csdn.net/doc/3rfmuard3w?spm=1055.2635.3001.10343)
# 1. PCIe接口技术概述
PCIe( Peripheral Component Interconnect Express)是一种高速串行计算机扩展总线标准,被广泛应用于计算机内部连接高速组件。它以点对点连接的方式,能够提供比传统PCI(Peripheral Component Interconnect)总线更高的数据传输率。PCIe的进
ZMODEM协议的高级特性:流控制与错误校正机制的精妙之处

参考资源链接:[ZMODEM传输协议深度解析](https://wenku.csdn.net/doc/647162cdd12cbe7ec3ff9be7?spm=1055.2635.3001.10343)
# 1. ZMODEM协议简介
## 1.1 什么是ZMODEM协议
ZMODEM是一种在串行通信中广泛使用的文件传输协议,它支持二进制数据传输,并可以对数据进行分块处理,确保文件完整无误地传输到目标系统。与早期的XMODEM和YMODEM协
IS903优盘通信协议揭秘:USB通信流程的全面解读

参考资源链接:[银灿IS903优盘完整的原理图](https://wenku.csdn.net/doc/6412b558be7fbd1778d42d25?spm=1055.2635.3001.10343)
# 1. USB通信协议概述
USB(通用串行总线)通信协议自从1996年首次推出以来,已经成为个人计算机和其他电子设备中最普遍的接口技术之一。该章节将概述USB通信协议的基础知识,为后续章节深入探讨USB的硬件结构、信号传输和通信流程等主题打
【功能拓展】创维E900 4K机顶盒应用管理:轻松安装与管理指南
参考资源链接:[创维E900 4K机顶盒快速配置指南](https://wenku.csdn.net/doc/645ee5ad543f844488898b04?spm=1055.2635.3001.10343)
# 1. 创维E900 4K机顶盒概述
在本章中,我们将揭开创维E900 4K机顶盒的神秘面纱,带领读者了解这一强大的多媒体设备的基本信息。我们将从其设计理念讲起,探索它如何为家庭娱乐带来高清画质和智能功能。本章节将为读者提供一个全面的概览,包括硬件配置、操作系统以及它在市场中的定位,为后续章节中关于设置、应用使用和维护等更深入的讨论打下坚实的基础。
创维E900 4K机顶盒采用先
【cx_Oracle数据库管理】:全面覆盖连接、事务、性能与安全性

参考资源链接:[cx_Oracle使用手册](https://wenku.csdn.net/doc/6476de87543f84448808af0d?spm=1055.2635.3001.10343)
# 1. cx_Oracle数据库基础介绍
cx_Oracle 是一个
【深度学习的交通预测力量】:构建上海轨道交通2030的智能预测模型

参考资源链接:[上海轨道交通规划图2030版-高清](https://wenku.csdn.net/doc/647ff0fc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )