模板错误处理与异常管理:确保Velocity模板稳定性的策略
发布时间: 2024-09-29 16:05:49 阅读量: 102 订阅数: 52 

Velocity模板引擎 v2.2.0.zip

# 1. Velocity模板引擎基础
## Velocity简介
Velocity是一个用于Web应用的模板引擎,它允许使用模板语言与Java代码分离,从而提高了开发效率和维护性。Velocity通过一种基于Java的模板语言(VTL)来生成源代码或HTML。这种分离不仅使得网页设计人员能够编写页面模板,而且也让开发者专注于后端逻辑,两者之间通过模板语言通信。
## 核心概念
在深入Velocity之前,理解几个核心概念是非常重要的。模板是包含静态文本和动态内容占位符的文件。上下文(Context)是一个键值对集合,它被用来存储数据,这些数据可以在模板中被引用和操作。最后,模板引擎是处理模板与上下文结合,并生成最终输出的组件。
## 环境搭建与基本用法
为了开始使用Velocity,首先需要在项目中添加依赖。对于Maven项目,可以在pom.xml中添加如下依赖:
```xml
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
</dependency>
```
一个典型的Velocity模板使用示例可能如下:
```java
VelocityEngine engine = new VelocityEngine();
engine.init();
VelocityContext context = new VelocityContext();
context.put("name", "World");
Template template = engine.getTemplate("hello_world.vm");
Writer writer = new StringWriter();
template.merge(context, writer);
System.out.println(writer.toString());
```
在这个例子中,我们初始化了`VelocityEngine`,创建了`VelocityContext`来存储数据,然后加载并执行了一个名为`hello_world.vm`的模板文件。
这一章对Velocity模板引擎进行了基础的介绍,涵盖了它的核心组件和使用场景。下一章我们将深入探讨模板错误处理机制。
# 2. 模板错误处理机制
## 2.1 错误分类与识别
### 2.1.1 语法错误的识别和诊断
在使用Velocity模板引擎进行Web开发时,语法错误是初学者常常遇到的问题。Velocity模板引擎有一套自己的语法规则,不遵循这些规则就会产生语法错误。例如,模板中的变量引用、方法调用、控制结构等都有严格的格式要求。
识别语法错误通常涉及两个步骤:错误的检测和错误的诊断。错误检测通常发生在模板加载阶段,而错误诊断则需要根据Velocity引擎提供的错误信息来确定问题所在。Velocity通过异常的形式报告语法错误,并给出错误发生的行号和简短的描述。
```java
try {
VelocityEngine engine = new VelocityEngine();
engine.init(props);
Template template = engine.getTemplate("template.vm");
VelocityContext context = new VelocityContext();
// ... 填充上下文变量
StringWriter writer = new StringWriter();
template.merge(context, writer);
} catch (ResourceNotFoundException e) {
// 模板未找到处理
e.printStackTrace();
} catch (ParseErrorException e) {
// 语法错误处理
System.err.println("语法错误在模板的第 " + e.getLineNumber() + " 行");
e.printStackTrace();
} catch (Exception e) {
// 其他类型的错误处理
e.printStackTrace();
}
```
在上述代码中,异常`ParseErrorException`是当模板引擎在解析模板时发现语法错误抛出的。通过捕获此异常,并调用`getLineNumber()`方法,开发者可以得知错误发生的具体位置。这样的诊断机制允许开发人员迅速定位问题,并对模板文件进行修改。
### 2.1.2 运行时错误的追踪和日志记录
运行时错误通常发生在模板执行阶段,这可能是由于模板逻辑错误或数据问题导致的。为了有效地追踪和记录运行时错误,Velocity提供了日志记录功能,通过配置日志系统(如Log4j),开发人员可以详细记录模板执行过程中的各种信息和错误。
```properties
log4j.rootLogger=DEBUG, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
```
在上述配置文件中,我们配置了Log4j来记录日志。在开发过程中,将日志级别设置为DEBUG可以帮助开发者捕获更多的细节信息。Velocity的异常和日志记录通常与Log4j紧密集成,可以在模板执行过程中产生详细的错误信息和调试信息。
## 2.2 错误处理策略
### 2.2.1 静默错误处理与反馈机制
在生产环境中,为了不暴露系统内部错误,开发者可能倾向于采用静默错误处理策略。这种策略的目的是确保即使发生错误,也不会影响最终用户的体验。在Velocity中,可以捕获异常,并不向用户展示异常详情,而是返回一个友好的错误信息。
```java
try {
// 模板加载和渲染代码
} catch (VelocityException e) {
// 返回一个友好的错误消息给用户
return "抱歉,由于我们的服务器错误,页面无法显示,请稍后再试。";
}
```
在这种处理方式中,即使发生错误,用户也只会看到一个普通的错误提示,而不是一堆开发者级别的错误信息。这种处理策略虽然可以提升用户体验,但也应该记录详细的错误日志,以便后续的分析和修复。
### 2.2.2 错误恢复和备选方案设计
在生产环境中,模板引擎错误的发生是难以避免的。为此,设计一个有效的错误恢复机制和备选方案是至关重要的。例如,当一个模板无法正常渲染时,可以回退到一个默认的模板,确保用户界面的连贯性和可用性。
```java
try {
// 尝试加载和渲染主模板
} catch (Exception e) {
// 尝试加载备选的错误模板
Template errorTemplate = engine.getTemplate("error.vm");
StringWriter writer = new StringWriter();
errorTemplate.merge(new VelocityContext(), writer);
return writer.toString();
}
```
在这个示例中,如果主模板出现任何异常,我们不再直接抛出异常,而是捕获异常,并尝试加载一个名为`error.vm`的备用模板。这种方法可以确保即使主模板出现问题,用户也能够看到一个错误页面,而不是一个空白页面或者不完整的页面。
## 2.3 测试与验证
### 2.3.* 单元测试和集成测试的编写
为了保证模板的质量和减少错误的发生,编写单元测试和集成测试是必不可少的。在Velocity中,单元测试可以用来检测特定模板的功能,而集成测试则可以验证模板与应用程序其他部分的整合。
```java
public class VelocityT
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“Velocity 介绍与使用”深入探讨了 Velocity 模板引擎,从基础语法到高级技巧,提供了全面的实践指南。通过 Spring Boot 案例分析和最佳实践,它展示了 Velocity 在 Java Web 开发中的应用,并通过性能提升秘籍优化了页面渲染效率。专栏还比较了 Velocity 和 FreeMarker,并提供了自定义函数、数据库交互和安全实践的实战技巧。此外,它涵盖了 Velocity 在国际化、调试、大数据和微服务架构中的应用,以及在 RESTful API 和前端框架中的集成方法。通过自定义指令开发和缓存机制,专栏强调了 Velocity 在业务逻辑和模板分离以及提升应用性能方面的优势。最后,它提供了模板错误处理和异常管理策略,确保 Velocity 模板的稳定性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
微机接口技术深度解析:串并行通信原理与实战应用
# 摘要
微机接口技术是计算机系统中不可或缺的部分,涵盖了从基础通信理论到实际应用的广泛内容。本文旨在提供微机接口技术的全面概述,并着重分析串行和并行通信的基本原理与应用,包括它们的工作机制、标准协议及接口技术。通过实例介绍微机接口编程的基础知识、项目实践以及在实际应用中的问题解决方法。本文还探讨了接口技术的新兴趋势、安全性和兼容
【进位链技术大剖析】:16位加法器进位处理的全面解析
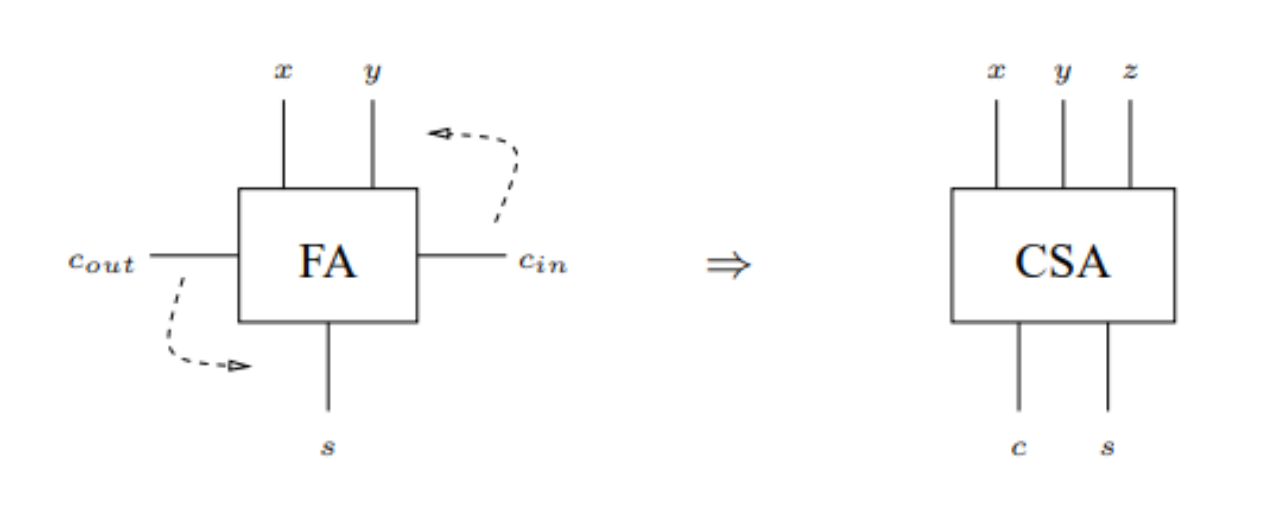
# 摘要
进位链技术是数字电路设计中的基础,尤其在加法器设计中具有重要的作用。本文从进位链技术的基础知识和重要性入手,深入探讨了二进制加法的基本规则以及16位数据表示和加法的实现。文章详细分析了16位加法器的工作原理,包括全加器和半加器的结构,进位链的设计及其对性能的影响,并介绍了进位链优化技术。通过实践案例,本文展示了进位链技术在故障诊断与维护中的应用,并探讨了其在多位加法器设计以及多处理器系统中的高级应用。最后,文章展望了进位链技术的未来,
【均匀线阵方向图秘籍】:20个参数调整最佳实践指南
# 摘要
均匀线阵方向图是无线通信和雷达系统中的核心技术之一,其设计和优化对系统的性能至关重要。本文系统性地介绍了均匀线阵方向图的基础知识,理论基础,实践技巧以及优化工具与方法。通过理论与实际案例的结合,分析了线阵的基本概念、方向图特性、理论参数及其影响因素,并提出了方向图参数调整的多种实践技巧。同时,本文探讨了仿真软件和实验测量在方向图优化中的应用,并介绍了最新的优化算法工具。最后,展望了均匀线阵方向图技术的发展趋势,包括新型材料和技术的应用、智能化自适应方向图的研究,以及面临的技术挑战与潜在解决方案。
# 关键字
均匀线阵;方向图特性;参数调整;仿真软件;优化算法;技术挑战
参考资源链
ISA88.01批量控制:制药行业的实施案例与成功经验

# 摘要
ISA88.01标准为批量控制系统提供了框架和指导原则,尤其是在制药行业中,其应用能够显著提升生产效率和产品质量控制。本文详细解析了ISA88.01标准的概念及其在制药工艺中的重要
实现MVC标准化:肌电信号处理的5大关键步骤与必备工具

# 摘要
本文探讨了MVC标准化在肌电信号处理中的关键作用,涵盖了从基础理论到实践应用的多个方面。首先,文章介绍了
【FPGA性能暴涨秘籍】:数据传输优化的实用技巧
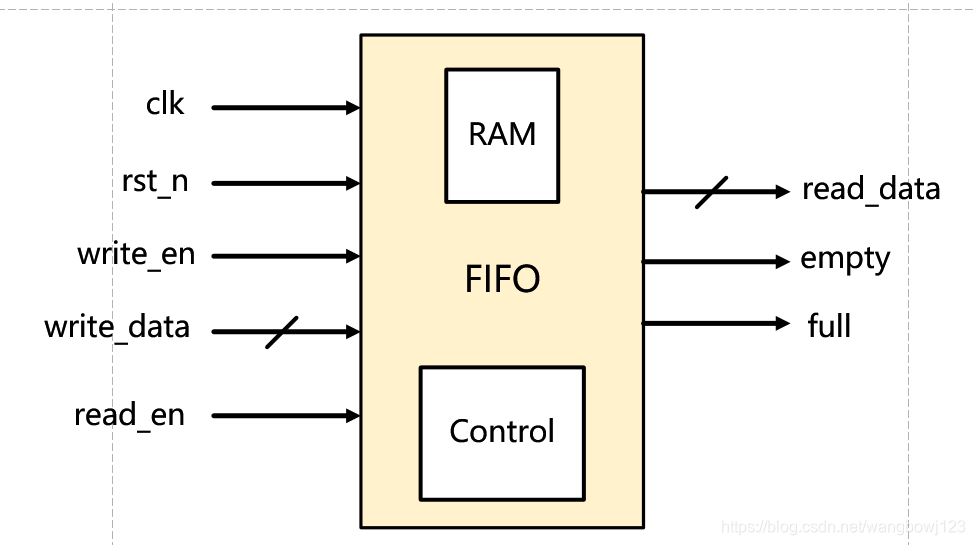
# 摘要
本文全面介绍了FPGA在数据传输领域的应用和优化技巧。首先,对FPGA和数据传输的基本概念进行了介绍,然后深入探讨了FPGA内部数据流的理论基础,包
PCI Express 5.0性能深度揭秘:关键指标解读与实战数据分析

# 摘要
PCI Express(PCIe)技术作为计算机总线标准,不断演进以满足高速数据传输的需求。本文首先概述PCIe技术,随后深入探讨PCI Express 5.0的关键技术指标,如信号传输速度、编码机制、带宽和吞吐量的理论极限以及兼容性问题。通过实战数据分析,评估PCI Express
CMW100 WLAN指令手册深度解析:基础使用指南揭秘
# 摘要
CMW100 WLAN指令是业界广泛使用的无线网络测试和分析工具,为研究者和工程师提供了强大的网络诊断和性能评估能力。本文旨在详细介绍CMW100 WLAN指令的基础理论、操作指南以及在不同领域的应用实例。首先,文章从工作原理和系统架构两个层面探讨了CMW100 WLAN指令的基本理论,并解释了相关网络协议。随后,提供了详细的操作指南,包括配置、调试、优化及故障排除方法。接着,本文探讨了CMW100 WLAN指令在网络安全、网络优化和物联网等领域的实际应用。最后,对CMW100 WLAN指令的进阶应用和未来技术趋势进行了展望,探讨了自动化测试和大数据分析中的潜在应用。本文为读者提供了
三菱FX3U PLC与HMI交互:打造直觉操作界面的秘籍

# 摘要
本论文详细介绍了三菱FX3U PLC与HMI的基本概念、工作原理及高级功能,并深入探讨了HMI操作界面的设计原则和高级交互功能。通过对三菱FX3U PLC的编程基础与高级功能的分析,本文提供了一系列软件集成、硬件配置和系统测试的实践案例,以及相应的故障排除方法。此外,本文还分享了在不同行业应用中的案例研究,并对可能出现的常见问题提出了具体的解决策略。最后,展望了新兴技术对PLC和HMI
【透明度问题不再难】:揭秘Canvas转Base64时透明度保持的关键技术

# 摘要
本文旨在全面介绍Canvas转Base64编码技术,从基础概念到实际应用,再到优化策略和未来趋势。首先,我们探讨了Canvas的基本概念、应用场景及其重要性,紧接着解析了Base64编码原理,并重点讨论了透明度在Canvas转Base64过程中的关键作用。实践方法章节通过标准流程和技术细节的讲解,提供了透明度保持的有效编码技巧和案例分析。高级技术部分则着重于性能优化、浏览器兼容性问题以及Ca
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )