




_velocity数据库交互术:简化JDBC代码的模板方法

1. Velocity数据库交互的基础理解
1.1 数据库交互概念与重要性
在开发Web应用程序时,数据库交互是至关重要的一环。它负责数据的持久化存储和检索,是业务逻辑和用户界面之间的桥梁。理解数据库交互不仅有助于开发高效的应用程序,还可以在实现高性能系统方面扮演关键角色。
1.2 Velocity引擎简介
Velocity是一个Java模板引擎,最初用于Web开发中的页面渲染。它提供了一种简单的方式来引用Java代码中的数据和逻辑,这些数据和逻辑被封装在模板中。通过模板引擎,开发者可以将应用程序的数据和业务逻辑与用户界面分离。
1.3 数据库交互的必要性
数据库交互允许应用程序执行各种操作,包括查询数据、插入新记录、更新现有记录以及删除记录。Velocity与数据库的交互可以利用其模板功能,通过预先定义好的模板来生成动态的SQL语句,从而实现上述操作。这种机制不仅提高了开发效率,还可以使代码更易于管理和维护。
在接下来的章节中,我们将深入探讨如何将Velocity与JDBC集成,从而实现数据库的交互操作。我们会从配置开始,逐步深入到SQL模板的设计,以及实践中的应用。通过这种由浅入深的方式,读者将能够掌握Velocity数据库交互的全部知识点。
2. Velocity与JDBC的集成基础
2.1 Velocity与JDBC介绍
2.1.1 JDBC的定义和作用
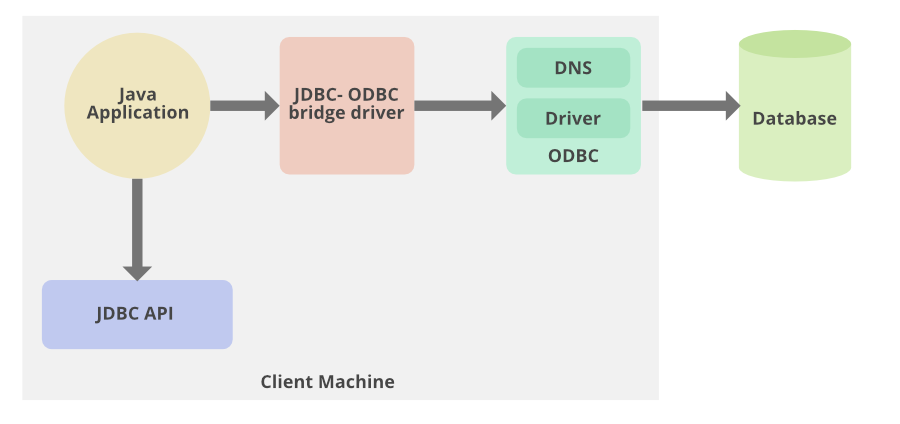
JDBC(Java Database Connectivity)是一种允许Java程序执行SQL语句的API。它定义了Java与数据库进行交互的标准方法,并提供了一系列接口和类,用于访问不同类型数据库管理系统(DBMS)。JDBC通过驱动程序管理器连接到不同的数据库,通过具体的驱动程序与数据库服务器进行通信。
JDBC的核心组件包括:
- JDBC驱动:将Java应用与特定数据库关联起来。驱动程序按照功能不同可以分为四类:JDBC-ODBC桥驱动、本地API部分用Java实现的驱动、JDBC网络纯Java驱动以及本地协议纯Java驱动。
- 连接(Connection):代表与特定数据库的通信会话,通过它可以执行SQL语句并返回结果。
- 语句(Statement):用于执行SQL语句。常用的Statement有PreparedStatement和CallableStatement两种。
- 结果集(ResultSet):包含了从数据库中查询出的行集合。
2.1.2 Velocity模板引擎的基本概念
Velocity是一个基于Java的模板引擎,它允许用户将程序逻辑与展示逻辑分离,从而实现MVC(Model-View-Controller)模式的Web应用。Velocity模板通常用来生成HTML、XML或纯文本。它能够将Java代码的逻辑嵌入模板文件中,然后通过Velocity引擎来解析这些模板,生成最终的输出文件。
Velocity的主要特点包括:
- 文本生成:适合生成任何形式的基于文本的输出。
- 模板语言:提供了一种简单的模板语言,允许用户在模板中嵌入Java代码。
- 数据访问:可以很容易地从对象数据源中访问数据。
- 性能高:由于其设计简单,Velocity引擎的执行效率很高。
2.2 配置Velocity引擎与JDBC连接
2.2.1 Velocity配置文件解析
Velocity的配置主要是通过一个名为velocity.properties的文件来完成。该文件定义了引擎的各种属性,包括模板加载路径、缓存配置、编码设置等。以下是一个典型的velocity.properties配置文件的内容:
- #.velocity.properties配置示例
- input.encoding=UTF-8
- output.encoding=UTF-8
- resource.loader=class
- class.resource.loader.class=org.apache.velocity.runtime.resource.loader.ClasspathResourceLoader
在这个配置文件中,我们设置了输入输出的编码格式为UTF-8,并指定了资源加载器为类路径加载器(ClasspathResourceLoader),这意味着Velocity将从类路径中加载模板资源。
2.2.2 JDBC数据源的配置
配置JDBC数据源涉及到在Java应用中设置数据库连接的相关属性,例如URL、用户名、密码以及驱动类等。通常,这些信息会被放在应用的配置文件中,比如database.properties:
- # database.properties配置示例
- jdbc.driver=com.mysql.cj.jdbc.Driver
- jdbc.url=jdbc:mysql://localhost:3306/mydatabase?useSSL=false&serverTimezone=UTC
- jdbc.username=root
- jdbc.password=123456
然后,在Java代码中,通过读取这些配置信息来创建数据库连接。
2.2.3 数据库连接池的应用
为了提高性能和资源管理效率,通常会使用连接池来管理数据库连接。在JDBC中,常见的连接池实现有HikariCP、Apache DBCP等。下面展示如何在Spring框架中配置HikariCP连接池:
- <!-- 在Spring的applicationContext.xml中配置HikariCP -->
- <bean id="dataSource" class="com.zaxxer.hikari.HikariDataSource" destroy-method="close">
- <property name="driverClassName" value="com.mysql.cj.jdbc.Driver"/>
- <property name="jdbcUrl" value="jdbc:mysql://localhost:3306/mydatabase?useSSL=false&serverTimezone=UTC"/>
- <property name="username" value="root"/>
- <property name="password" value="123456"/>
- </bean>
2.3 Velocity中的SQL模板设计
2.3.1 SQL模板的定义和使用方法
在Velocity中设计SQL模板,可以将SQL语句放置在模板文件中,并在需要执行时动态替换SQL模板中的参数。比如,一个简单的SQL查询模板可以是这样的:
- SELECT * FROM users WHERE user_id = $velocityRuntimeTool.getURandomNumber(1, 100000)
在Java中使用Velocity模板引擎来解析上述模板,代码可能如下:
- VelocityEngine velocityEngine = new VelocityEngine();
- velocityEngine.init("velocity.properties");
- VelocityContext context = new VelocityContext();
- context.put("velocityRuntimeTool", new RuntimeTool());
- Template template = velocityEngine.getTemplate("sql_template.vm");
- StringWriter writer = new StringWriter();
- template.merge(context, writer);
2.3.2 模板中的变量和控制逻辑
模板文件允许定义变量和控制逻辑。例如,可以定义一个变量来表示用户信息,并在查询中使用该变量:
- #set($userId = $velocityRuntimeTool.getURandomNumber(1, 100000))
- SELECT * FROM users WHERE user_id = $userId
控制逻辑通常用于模板中的判断或循环。比如,根据传入的参数决定是否查询所有用户还是特定用户:
- #if($isAllUsers)
- SELECT * FROM users
- #else
- SELECT * FROM users WHERE user_id = $userId
- #end
2.3.3 预编译语句和批量处理
使用预编译语句(PreparedStatement)可以有效地防止SQL注入,并允许批量操作。在Velocity模板中,可以将预编译语句的模板设计为:
- PREPARE STATEMENT FROM 'SELECT * FROM users WHERE user_id = ?'
在Java代码中,通过PreparedStatement实现参数的绑定和执行:
- Connection conn = dataSource.getConnection();
- PreparedStatement pstmt = conn.prepareStatement("SELECT * FROM users WHERE user_id = ?");
- pstmt.setInt(1, userId);
- ResultSet rs = pstmt.executeQuery();
这样不仅保证了查询的安全性,也提高了执行效率,特别是在进行大量数据查询时。
在下一章节中,我们将通过实践应用来进一步了解Velocity在数据库交互中的具体应用,包括数据的CRUD操作、复杂查询、事务处理以及错误处理和性能优化等内容。
3. Velocity数据库交互实践应用
在掌握 Velocity 的基础应用和与 JDBC 的集成之后,接下来将进入实际应用阶段,本章节将重点围绕如何在 Velocity 中实现数据库的 CRUD(创建、读取、更新、删除)操作进行深入讨论。同时,也将探讨如何通过 Velocity 管理复杂查询和事务处理,以及在实际应用中进行错误处理和性能优化的重要性。
3.1 实现数据的CRUD操作
3.1.1 创建(Create)数据操作实例
在 Velocity 模板中实现数据的创建操作,通常需要向数据库插入新的数据行。借助 JDBC 的预编译语句,可以有效地防止 SQL 注入攻击,同时提升代码的安全性与执行效率。
下面是一个简单的创建操作实例:


 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
51单片机中断系统与寄存器关联:一步到位掌握原理与实践
傅里叶变换在GTZAN Dataset中的实践应用:音频信号处理新手指南
从零开始构建Socket服务器:理论与实战的完美结合
QCRIL扩展性分析:自定义ROM通信实现的专家级指导
【形考答案全掌握】:江苏开放大学计算机应用基础形考第二次作业答案深度剖析
【电机控制案例】两路互补PWM:揭秘在电机控制中应用的幕后技巧
权威解读:图像融合技术如何应对证据冲突的10大挑战
【安全护航】:构建坚不可摧的健康数据安全壁垒
【Linux系统定制高手】:RedHat KDE桌面环境兼容性问题快速解决之道
【非线性优化:二维装箱问题中的双刃剑】:挑战与机遇并存


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















