大数据中的Velocity应用:提升数据报告效率的秘诀
发布时间: 2024-09-29 15:40:40 阅读量: 179 订阅数: 48 
# 1. 大数据与Velocity简介
在当今信息时代,大数据的重要性不言而喻,它已成为各行业发展的新动力。Velocity作为一个高效的模板引擎,为处理大数据提供了有力工具,尤其在生成数据报告方面表现卓越。随着数据量的急剧增长,传统的数据处理方法已难以满足实时性和高效性的需求,这就要求我们寻找新的解决方案。Velocity的引入,正好填补了这一市场缺口,它通过简单的模板语言和强大的数据处理能力,实现了数据的快速处理和高质量报告的生成。本章将从大数据的背景出发,简要介绍Velocity引擎的基本概念和在大数据领域的应用前景,为读者提供一个全面的初步认识。
# 2. Velocity引擎的工作原理
## 2.1 Velocity模板引擎基础
### 2.1.1 模板语言的概念和作用
模板语言是一种用于分离应用程序逻辑和展示层的编程语言。它允许开发者通过定义特定的标记和结构来创建动态内容,这些内容会根据数据的不同而变化。在Web开发中,模板语言广泛用于生成HTML页面,使得前端展示可以轻松地与后端数据进行动态绑定。
模板语言提供了一种更直观、更简洁的方式来处理数据展示的逻辑,与传统的编程语言相比,它通常更加专注于数据和展示逻辑的整合。通过模板语言,开发者可以专注于应用逻辑的实现,而设计师可以更容易地理解和修改页面布局和样式,从而提高开发效率并减少错误。
例如,Velocity模板语言允许你通过简单的标记和属性来展示数据对象,而不需要将数据处理逻辑嵌入HTML代码中。这种分离使得代码更加清晰,也便于团队协作和维护。
### 2.1.2 Velocity的基本语法
Velocity模板引擎遵循着简单、直观的语法,它包括变量引用、控制结构(如if-else条件判断和循环结构)、以及一些特殊符号等。
- **变量引用**:在模板中,变量通常被标记为`$变量名`。Velocity会将这些变量替换为相应的值。
```velocity
Hello, $name!
```
- **控制结构**:Velocity使用特殊的指令来实现控制结构,比如`#if`、`#foreach`、`#macro`等。
```velocity
#if($user.isActive)
<p>Welcome back, $user.name!</p>
#end
```
- **特殊符号**:Velocity使用符号`#`来指示模板指令,这些符号对于模板的解析和执行至关重要。
```velocity
#set($greeting = "Hello")
#set($subject = "World")
$greeting, $subject!
```
理解并熟练运用这些基本语法是掌握Velocity模板引擎的基础。更高级的用法涉及到宏的定义、工具箱的使用等,这些都是在后续章节中将会详细介绍的内容。
## 2.2 Velocity的工作机制
### 2.2.1 模板的加载和编译过程
Velocity引擎的工作流程可以分为几个关键步骤,从加载模板开始,然后对模板进行编译,最终执行模板并输出最终结果。
- **模板的加载**:通常,Velocity模板存放在文件系统或资源包中。在初始化时,模板引擎会加载指定路径下的模板文件。
```java
VelocityEngine engine = new VelocityEngine();
engine.setProperty(RuntimeConstants.RESOURCE_LOADER, "class");
engine.setProperty("class.resource.loader.class", "org.apache.velocity.runtime.resource.loader.ClasspathResourceLoader");
engine.init();
Template template = engine.getTemplate("templates/helloworld.vm");
```
- **模板的编译**:加载模板后,Velocity会编译模板,创建一个可以被立即执行的模板对象。编译过程涉及到解析模板中的指令、宏、引用等元素。
- **模板的执行和输出**:在执行阶段,Velocity会结合提供的上下文数据(Context)来渲染模板,输出最终结果。
### 2.2.2 上下文(Context)与变量的使用
在模板引擎中,上下文(Context)是用于存储变量和其值的环境。Velocity使用`VelocityEngine`来初始化一个`VelocityContext`对象,该对象负责处理模板中的变量引用。
- **上下文的创建和初始化**:
```java
VelocityContext context = new VelocityContext();
context.put("name", "Velocity");
```
- **变量的引用和使用**:
```velocity
Hello, $name!
```
- **变量的作用域**:在模板中定义的变量可以有全局作用域,也可以是在特定的`#set`指令下定义的局部变量。Velocity上下文管理着这些变量的作用域。
### 2.2.3 模板的渲染流程
模板的渲染是将模板与数据上下文结合生成最终输出的过程。这一过程中,Velocity遍历模板中的每一部分,对于遇到的每一个变量或指令,它根据上下文来解析和替换。
- **遍历模板**:Velocity引擎会逐行或逐块地遍历模板,识别出数据绑定、控制结构等。
- **替换变量**:对于模板中引用的变量,Velocity会查找上下文中对应的值进行替换。
- **执行指令**:遇到模板中的指令(如`#if`、`#foreach`等),Velocity会根据条件判断或循环逻辑来处理。
- **输出结果**:所有替换和执行完成后,Velocity将生成的字符串输出到指定的流或文件中。
## 2.3 Velocity与大数据的结合
### 2.3.1 在大数据环境下部署Velocity
将Velocity与大数据技术相结合,主要利用其快速、高效的数据渲染能力。部署Velocity时需要考虑其性能和扩展性。
- **集成方式**:在大数据环境下,可能需要通过服务框架(如Apache Thrift或gRPC)来集成Velocity,使其能够处理大规模的数据请求。
- **性能优化**:为了适应大数据环境,Velocity需要进行适当的性能优化,比如使用线程池、缓存技术等。
### 2.3.2 Velocity在数据报告中的优势分析
Velocity在数据报告生成方面具有一定的优势,这使得它非常适合用于大数据环境中的报告系统开发。
- **模板化报告生成**:Velocity允许使用模板技术来生成报告,这降低了重复编写报告逻辑的需要,提高了开发效率。
- **动态数据绑定**:Velocity可以将动态数据与模板绑定,使得报告可以实时反映数据的变化。
- **跨平台能力**:Velocity的报告可以用于多种展示平台,包括Web页面、PDF文档、电子邮件等。
通过这些优势分析,我们可以看到Velocity在处理大数据报告生成任务时的潜力。在接下来的章节中,我们将探讨如何使用Velocity进行数据报告的实践操作。
# 3. Velocity实践:数据报告生成技术
## 3.1 Velocity数据报告模板设计
### 3.1.1 设计报告结构和布局
当使用Velocity进行数据报告的生成时,首先需要设计一个清晰的报告结构和布局。这一步骤对于最终报告的可读性和专业度至关重要。设计报告结构通常包括以下几个方面:
1. **报告的页面布局**:需要规划好报告中各个部分的位置,例如标题、页眉、页脚、数据表、图表等。
2. **导航和目录**:对于长篇报告,合理的导航和目录结构可以极大地提高用户体验。
3. **样式和格式**:设计统一且专业的视觉样式,包括字体、颜色、边距等。
在Velocity中,模板设计通常会涉及到HTML、CSS和JavaScript,而Velocity的变量和宏可以动态生成数据和逻辑控制,使模板具有更高的灵活性。
### 3.1.2 报告内容的数据绑定和逻辑处理
数据绑定是将后台数据动态地与模板中的占位符进行绑定的过程。在Velocity中,数据绑定主要通过变量来实现。例如:
```html
<h1>$title</h1>
<table>
<tr>
<td>员工姓名</td>
<td>$employeeName</td>
</tr>
<!-- 其他数据绑定 -->
</table>
```
在上述代码中,`$title` 和 `$employeeName` 是从Velocity上下文中获取的变量。Velocity模板引擎在渲染时会将这些变量替换为实际的数据。
逻辑处理则涉及到条件判断、循环遍历等,比如:
```html
#if($sales > $targetSales)
<p>销售目标达成!</p>
#elseif($sales > $halfTargetSales)
<p>销售目标完成过半!</p>
#end
```
在Velcoity模板中,使用`#if`、`#elseif`和`#end`进行条件判断,控制输出的动态内容。
## 3.2 Velocity高级特性应用
### 3.2.1 使用宏和指令增强报告功能
宏是Velocity中用于封装重复使用的代码片段的功能,可以极大地简化模板编写,并增强模板的功能性。例如:
```html
#macro(getSalesChart $salesData)
<!-- 宏体:根据销售数据生成图表 -->
#end
```
在模板中可以多次调用这个宏来生成不同的图表。
而Velocity的指令则可以扩展模板引擎本身的功能。指令通常以`#`开头,后接指令名称和参数。例如,可以创建一个自定义指令来处理特定数据格式。
### 3.2.2 嵌入脚本和条件逻辑的实现
Velocity支持在模板中嵌入简单的脚本代码,这为模板的动态生成提供了强大的支持。例如,可以使用Velocimacro来定义和执行脚本逻辑:
```v
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“Velocity 介绍与使用”深入探讨了 Velocity 模板引擎,从基础语法到高级技巧,提供了全面的实践指南。通过 Spring Boot 案例分析和最佳实践,它展示了 Velocity 在 Java Web 开发中的应用,并通过性能提升秘籍优化了页面渲染效率。专栏还比较了 Velocity 和 FreeMarker,并提供了自定义函数、数据库交互和安全实践的实战技巧。此外,它涵盖了 Velocity 在国际化、调试、大数据和微服务架构中的应用,以及在 RESTful API 和前端框架中的集成方法。通过自定义指令开发和缓存机制,专栏强调了 Velocity 在业务逻辑和模板分离以及提升应用性能方面的优势。最后,它提供了模板错误处理和异常管理策略,确保 Velocity 模板的稳定性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB模块库翻译性能优化:关键点与策略分析

# 1. MATLAB模块库性能优化概述
MATLAB作为强大的数学计算和仿真软件,广泛应用于工程计算、数据分析、算法开发等领域。然而,随着应用程序规模的不断增长,性能问题开始逐渐凸显。模块库的性能优化,不仅关乎代码的运行效率,也直接影响到用户的工作效率和软件的市场竞争力。本章旨在简要介绍MATLAB模块库性能优化的重要性,以及后续章节将深入探讨的优化方法和策略。
## 1.1 MATLAB模块库性能优化的重要性
随着应用需求的
MATLAB遗传算法在天线设计优化中的应用:提升性能的创新方法

# 1. 遗传算法的基础理论
遗传算法是计算数学中用来解决优化和搜索问题的算法,其思想来源于生物进化论和遗传学。它们被设计成模拟自然选择和遗传机制,这类算法在处理复杂的搜索空间和优化问题中表现出色。
## 1.1 遗传算法的起源与发展
遗传算法(Genetic Algorithms,GA)最早由美国学者John Holland在20世
【MATLAB应用诊断与修复】:快速定位问题,轻松解决问题的终极工具
# 1. MATLAB的基本概念和使用环境
MATLAB,作为数学计算与仿真领域的一种高级语言,为用户提供了一个集数据分析、算法开发、绘图和数值计算等功能于一体的开发平台。本章将介绍MATLAB的基本概念、使用环境及其在工程应用中的地位。
## 1.1 MATLAB的起源与发展
MATLAB,全称为“Matrix Laboratory”,由美国MathWorks公司于1984年首次推出。它是一种面向科学和工程计算的高性能语言,支持矩阵运算、数据可视化、算法设计、用户界面构建等多方面任务。
## 1.2 MATLAB的安装与配置
安装MATLAB通常包括下载安装包、安装必要的工具箱以及环境
算法优化:MATLAB高级编程在热晕相位屏仿真中的应用(专家指南)

# 1. 热晕相位屏仿真基础与MATLAB入门
热晕相位屏仿真作为一种重要的光波前误差模拟方法,在光学设计与分析中发挥着关键作用。本章将介绍热晕相位屏仿真的基础概念,并引导读者入门MATLAB,为后续章节的深入学习打下坚实的基础。
## 1.1 热晕效应概述
热晕效应是指在高功率激光系统中,由于温度变化导致的介质折射率分
【异步任务处理方案】:手机端众筹网站后台任务高效管理
# 1. 异步任务处理概念与重要性
在当今的软件开发中,异步任务处理已经成为一项关键的技术实践,它不仅影响着应用的性能和可扩展性,还直接关联到用户体验的优化。理解异步任务处理的基本概念和它的重要性,对于开发者来说是必不可少的。
## 1.1 异步任务处理的基本概念
异步任务处理是指在不阻塞主线程的情况下执行任务的能力。这意味着,当一个长时间运行的操作发生时,系统不会暂停响应用户输入,而是让程序在后台处理这些任务
【数据不平衡环境下的应用】:CNN-BiLSTM的策略与技巧

# 1. 数据不平衡问题概述
数据不平衡是数据科学和机器学习中一个常见的问题,尤其是在分类任务中。不平衡数据集意味着不同类别在数据集中所占比例相差悬殊,这导致模型在预测时倾向于多数类,从而忽略了少数类的特征,进而降低了模型的泛化能力。
## 1.1 数据不平衡的影响
当一个类别的样本数量远多于其他类别时,分类器可能会偏向于识别多数类,而对少数类的识别
MATLAB噪声过滤技术:条形码识别的清晰之道

# 1. MATLAB噪声过滤技术概述
在现代计算机视觉与图像处理领域中,噪声过滤是基础且至关重要的一个环节。图像噪声可能来源于多种因素,如传感器缺陷、传输干扰、或环境光照不均等,这些都可能对图像质量产生负面影响。MATLAB,作为一种广泛使用的数值计算和可视化平台,提供了丰富的工具箱和函数来处理这些噪声问题。在本章中,我们将概述MATLAB中噪声过滤技术的重要性,以及它在数字图像处理中
人工智能中的递归应用:Java搜索算法的探索之旅
# 1. 递归在搜索算法中的理论基础
在计算机科学中,递归是一种强大的编程技巧,它允许函数调用自身以解决更小的子问题,直到达到一个基本条件(也称为终止条件)。这一概念在搜索算法中尤为关键,因为它能够通过简化问题的复杂度来提供清晰的解决方案。
递归通常与分而治之策略相结合,这种策略将复杂问题分解成若干个简单的子问题,然后递归地解决每个子问题。例如,在二分查找算法中,问题空间被反复平分为两个子区间,直到找到目标值或子区间为空。
理解递归的理论基础需要深入掌握其原理与调用栈的运作机制。调用栈是程序用来追踪函数调用序列的一种数据结构,它记录了每次函数调用的返回地址。递归函数的每次调用都会在栈中创
Git协作宝典:代码版本控制在团队中的高效应用
# 1. Git版本控制基础
## Git的基本概念与安装配置
Git是目前最流行的版本控制系统,它的核心思想是记录快照而非差异变化。在理解如何使用Git之前,我们需要熟悉一些基本概念,如仓库(repository)、提交(commit)、分支(branch)和合并(merge)。Git可以通过安装包或者通过包管理器进行安装,例如在Ubuntu系统上可以使用`sudo apt-get install git`
调度问题的遗传算法解法:策略优化与成功案例研究
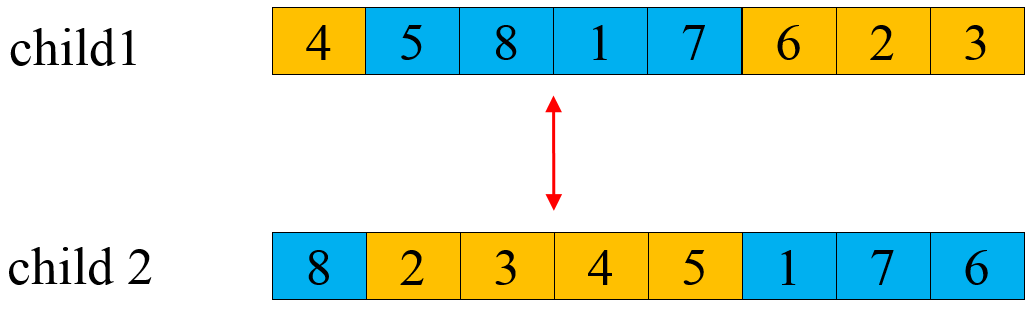
# 1. 遗传算法的基本原理和遗传机制
遗传算法(Genetic Algorithm, GA)是一种启发式搜索算法,受到生物进化论的启发,通过模拟自然选择和遗传学机制,用于解决优化问题。遗传算法的求解过程是对种群中个体进行选择、交叉、变异等操作,最终生成适应度高的新个体。本章节将介绍遗传算法的核心组件和基本操作,带领读者理解GA的工作原理和遗传机制。
## 1.1 遗传算法核心组件
遗传算法主要由以下几个核心组件
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )