C++实时渲染优化秘籍:性能提升的关键技术点
发布时间: 2024-12-10 06:31:47 阅读量: 1 订阅数: 15 

3D高斯飞溅实时辐射场渲染:一个用于3D实时辐射场渲染的项目

# 1. C++实时渲染的简介与挑战
在计算机图形学中,实时渲染是一个挑战性领域,它要求在极短的时间内(通常为毫秒级别)完成图像的渲染,以便于动态场景能够在屏幕上连续流畅地显示。C++作为一种高效的编程语言,在实时渲染领域扮演着至关重要的角色。它被广泛用于游戏开发、虚拟现实(VR)、增强现实(AR)以及高性能计算领域中,因其对系统资源的精巧控制能力和运行时性能而备受青睐。
然而,C++实时渲染同样面临着多方面的挑战。首先,渲染的实时性要求很高,任何性能瓶颈都可能导致卡顿或延迟,影响用户体验。其次,硬件的多样性和复杂性使得开发者需要精心设计代码以适应不同的平台和设备。此外,随着画面质量要求的不断提升,如何在不牺牲性能的前提下实现更高质量的渲染效果,也是C++实时渲染开发者需要解决的问题。本章将对C++实时渲染的挑战进行初步探讨,为后续章节中介绍的性能优化、高级技术应用和实践案例分析等内容打下基础。
# 2. C++实时渲染性能优化基础
### 2.1 渲染管线和性能瓶颈
#### 2.1.1 了解现代渲染管线
现代渲染管线是实时渲染的核心,它包含了从应用阶段到最终屏幕像素呈现的多个步骤。理解这些步骤有助于我们确定性能瓶颈,从而进行针对性的优化。
- 应用阶段:处理用户输入,更新游戏逻辑状态。
- 几何阶段:包括顶点着色器、曲面细分着色器、几何着色器等,进行顶点数据的处理和几何形态的生成。
- 光栅化阶段:将几何数据转换为屏幕像素的过程,包含光栅化、边界测试、深度测试等。
- 像素处理阶段:像素着色器处理光栅化后的每个像素,进行纹理映射、光照计算等。
- 输出合并阶段:将像素处理后的颜色和深度信息混合,输出最终图像。
渲染管线的不同阶段对性能有不同的影响,实时渲染优化的一个重要方面是减少不必要的计算和提升瓶颈阶段的效率。
#### 2.1.2 识别性能瓶颈的方法
识别性能瓶颈是性能优化的前提。以下是一些常用的方法:
- 性能分析工具:使用如NVIDIA的Nsight或者AMD的Radeon Performance Analyzer等专业工具进行实时分析。
- 框架内置分析器:一些游戏引擎,例如Unreal或Unity,提供了内置的渲染性能分析工具。
- 模拟帧率限制:通过软件模拟不同帧率下的渲染表现,以此来判断性能瓶颈。
- 逐阶段分析:分别测量渲染管线各个阶段所消耗的时间,识别出最耗时的部分。
### 2.2 资源管理和数据结构优化
#### 2.2.1 高效的资源管理技术
在实时渲染中,资源管理是保证游戏流畅运行的关键。以下是一些提高资源管理效率的技术:
- 预加载和缓存:提前加载常用资源,并对重要资源进行缓存处理,避免运行时频繁的磁盘I/O操作。
- 动态资源加载:依据当前场景需求动态地加载和卸载资源,利用虚拟内存技术减少物理内存占用。
- 资源池化:对重复使用的资源,如粒子、网格等,采用预分配内存池的方式来管理,避免频繁的内存分配和回收。
#### 2.2.2 优化数据结构以提升性能
数据结构的选择直接影响渲染性能。为了提升性能,可以采取以下策略:
- 使用稀疏数组来存储具有大量零元素的矩阵。
- 利用BSP树、KD树等空间分割技术来优化场景的组织。
- 运用平衡二叉树(如红黑树)来管理场景中的动态对象,加快查询和排序速度。
### 2.3 多线程和并发渲染技术
#### 2.3.1 多线程渲染的原理和优势
多线程渲染技术可以充分利用现代多核CPU的计算能力。其原理主要依赖于任务的拆分和并行执行。主要优势包括:
- 分离渲染任务:将计算密集型和I/O密集型任务分别在不同线程中执行。
- 降低单线程负载:通过多线程分担渲染任务,减少单线程的计算压力。
- 提高资源利用率:并行执行多个任务,提高CPU资源的利用率。
#### 2.3.2 并发编程在渲染中的应用
在实际应用中,C++提供了多种并发编程的工具,如std::thread、std::async以及库支持如Intel TBB等。以std::async为例,它允许我们以异步的方式启动任务,同时可以使用future来获取任务完成后的结果。
```cpp
#include <future>
#include <iostream>
int compute(int x) {
// 模拟长时间计算
return x * x;
}
int main() {
std::future<int> result = std::async(compute, 42);
std::cout << "计算正在进行,结果将在完成后输出..." << std::endl;
// 做其他事情...
int r = result.get(); // 等待任务完成并获取结果
std::cout << "计算结果: " << r << std::endl;
return 0;
}
```
在渲染中,可以利用并发编程技术来处理场景的更新、物理计算、AI决策等后台任务,从而提升渲染效率。
通过深入理解渲染管线,实施资源管理的策略,以及运用多线程和并发编程技术,可以有效地提升C++实时渲染的性能。在下一章节中,我们将深入探讨实时渲染的高级技术应用。
# 3. C++实时渲染高级技术应用
## 3.1 图形API与硬件加速
### 3.1.1 掌握DirectX和OpenGL
DirectX 和 OpenGL 是 C++ 实时渲染中不可或缺的图形 API。它们是连接应用程序与硬件加速功能的桥梁。DirectX 主要由微软开发,专为 Windows 平台设计,而 OpenGL 作为开放式标准,被广泛应用于多种操作系统。掌握这两个 API 是提升渲染效率和质量的基础。
DirectX 12 和 OpenGL 4.x 等最新版本都引入了对底层硬件更直接的控制,这允许开发者利用硬件的全部潜能进行高效渲染。这包括了对多核心处理器的更好支持,对异步计算的加强,以及更细致的图形资源管理。
实现 Direct3D 12 或 OpenGL 4.x 通常需要深入理解 GPU 架构和底层渲染管线。开发者需手动管理显存和资源上传,这可以显著减少 CPU 到 GPU 的瓶颈,使得渲染效率大大提升。
### 3.1.2 硬件加速的原理和实践
硬件加速原理主要是利用 GPU 的并行处理能力进行图形渲染。在 C++ 中,这通常涉及到创建一个渲染上下文(在 DirectX 中是 ID3D12Device,在 OpenGL 中是 GL context),并通过这个上下文提交渲染命令。
GPU 架构通常包含了多个顶点着色器,像素着色器,几何着色器,以及其他各种单元,它们能够同时处理成百上千个渲染指令。硬件加速的实践包括但不限于:减少渲染状态变更,批处理渲染调用,使用计算着色器进行通用计算等。
下面是一个简单的 OpenGL 代码示例,展示了如何初始化一个渲染上下文并设置基本的渲染状态:
```cpp
// 初始化 OpenGL 渲染上下文
SDL_Window* window = SDL_CreateWindow(
"OpenGL Window",
SDL_WINDOWPOS_UNDEFINED,
SDL_WINDOWPOS_UNDEFINED,
800,
600,
SDL_WINDOW_OPENGL
);
SDL_GL_SetAttribute(SDL_GL_CONTEXT_MAJOR_VERSION, 4);
SDL_GL_SetAttribute(SDL_GL_CONTEXT_MINOR_VERSION, 5);
SDL_GL_SetAttribute(SDL_GL_CONTEXT_PROFILE_MASK, SDL_GL_CONTEXT_PROFILE_CORE);
SDL_GLContext glContext = SDL_GL_CreateContext(window);
// 设置视口大小
glViewport(0, 0, 800, 600);
// 开启深度测试
glEnable(GL_DEPTH_TEST);
// 主循环
bool running = true;
while (running) {
// 渲染逻辑...
SDL_GL_SwapWindow(window);
}
// 清理
SDL_GL_DeleteContext(glContext);
SDL_DestroyWindow(window);
```
在这段代码中,首先创建了一个窗口并设置 OpenGL 上下文,指定使用 OpenGL 4.5 核心模式配置。然后设置视口,并开启深度测试,这是大部分实时渲染应用的基础设置。之后进入主循环,渲染画面并交换缓冲区。
## 3.2 着色器优化与GPU计算
### 3.2.1 着色器性能分析和优化
着色器是运行在 GPU 上的小程序,用于控制渲染管线中特定阶段的输出,包括顶点着色器、片元着色器和几何着色器等。高效、优化的着色器代码直接影响渲染性能。因此,性能分析和优化着色器代码是高级技术应用中的关键一环。
分析着色器性能通常包括:识别过度复杂的数学运算,减少纹理采样,优化算法以减少指令数量,以及合理利用寄存器和局部存储。
优化着色器的策略之一是减少动态分支(即 if-else 语句),因为它们会降低 GPU 的并行性能。另外,使用条件编译和预处理器宏可以提前确定分支,减少运行时的分支。
### 3.2.2 GPU计算的优势和策略
现代 GPU 不再仅仅局限于图形渲染,它们还能够执行通用计算任务,这一特性被称为通用 GPU(GPGPU)计算。CUDA 和 OpenCL 是执行 GPGPU 计算的两个流行框架,它们允许开发者使用 C++ 编写可以在 GPU 上执行的代码。
GPU 计算的优势在于其高度的并行性,对于那些可以分解为多个独立子任务的问题,比如物理模拟、图像处理和数据挖掘等,GPU 计算可以提供比传统 CPU 更高的性能。
实现 GPU 计算的策略包括:使用线程工作组来优化内存访问模式,避免全局内存的访问瓶颈,并确保足够的计算负载来隐藏内存访问延迟。
这里是一个简单的 CUDA 代码片段,用于实现向量加法:
```cpp
// CUDA 简单向量加法示例
__global__ void addVectors(int n, float *a, float *b, float *c) {
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < n) {
c[index] = a[index] + b[index];
}
}
int main() {
int vectorSize = 256;
int size = vectorSize * sizeof(float);
float *a, *b, *c;
// 分配和初始化主机内存
a = (float *)malloc(size);
b = (float *)malloc(size);
c = (float *)malloc(size);
// 分配设备内存
float *d_a, *d_b, *d_c;
cudaMalloc(&d_a, size);
cudaMalloc(&d_b, size);
cudaMalloc(&d_c, size);
// 将向量复制到设备内存
cudaMemcpy(d_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size, cudaMemcpyHostToDevice);
// 调用 kernel 函数
int threadsPerBlock = 256;
int blocksPerGrid = (vectorSize + threadsPerBlock - 1) / threadsPerBlock;
addVectors<<<blocksPerGrid, threadsPerBlock>>>(vectorSize, d_a, d_b, d_c);
// 将结果复制回主机内存
cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost);
// 清理资源
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
free(a); free(b); free(c);
return 0;
}
```
在这个例子中,`addVectors` 是一个 CUDA 内核函数,它并行地执行每个线程的向量加法。通过指定合适的网格和块大小,可以充分利用 GPU 的并行计算能力。
## 3.3 实时全局光照和阴影技术
### 3.3.1 全局光照模型的介绍
全局光照(Global Illumination, GI)是实时渲染中模拟光线如何在场景中传播并相互作用以产生真实感图像的过程。与简单的直接光照不同,全局光照考虑了光线的反射、折射、散射等复杂现象。
实时全局光照模型尝试在保持性能的前提下近似真实世界中的光照效果,如辐射度方法、路径追踪、光子映射、屏幕空间反射等。这些算法的实时版本,比如屏幕空间全局光照(SSGI)、预计算的辐射传递(如 Lightmaps),和近似算法(如 Cascaded Shadow Maps)被广泛应用于现代游戏和模拟中。
### 3.3.2 高效实现全局光照和阴影
为了实现高效全局光照,渲染引擎通常结合多种技术。例如,使用延迟渲染(Deferred Shading)或延迟光照(Deferred Lighting)方法,这些方法将场景几何体的属性(如位置、法线、颜色)与光照计算分离,从而允许多个光源在不增加几何体复杂度的情况下产生影响。
实时阴影技术中,阴影贴图(Shadow Maps)是最常用的方案之一。阴影贴图通过渲染光源视角下的深度信息来确定哪些区域在光源的视野内是可见的。这个技术的挑战在于处理不同距离上的阴影精度问题和处理边缘锯齿。
下面是一个简单的阴影贴图生成的伪代码:
```cpp
// 1. 渲染场景从光源视角,产生深度贴图(Shadow Map)
glBindFramebuffer(GL_FRAMEBUFFER, depthFBO);
glViewport(0, 0, shadowWidth, shadowHeight);
glClear(GL_DEPTH_BUFFER_BIT);
// 渲染场景从光源视角的代码...
// 2. 使用深度贴图来渲染带有阴影的场景
glBindFramebuffer(GL_FRAMEBUFFER, 0);
glViewport(0, 0, screenWidth, screenHeight);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
// 渲染主场景,并使用深度贴图来计算阴影...
```
在这段伪代码中,首先从光源的视角渲染场景,生成深度贴图,然后在渲染主场景时,使用这个深度贴图来确定哪些部分应该在阴影中。
## 表格
在讨论实时渲染技术时,理解和比较不同硬件加速方法的性能至关重要。下表展示了主流图形 API 和它们的核心特性:
| 特性/图形 API | DirectX 12 | OpenGL 4.x |
|----------------|------------|------------|
| 平台支持 | Windows | 跨平台 |
| 核心特性 | 更低级别的硬件控制 | 更高的硬件抽象层次 |
| 适用性 | 游戏开发 | 多种应用领域 |
| 性能优势 | 提升多核心效率 | 灵活性和通用性 |
| 着色器模型 | 着色器模型 5 | GLSL |
通过上表我们可以看出,DirectX 12 适合于对性能有极高要求的游戏开发,而 OpenGL 提供了更大的平台通用性和灵活性。
## Mermaid 流程图
下面是一个简化的实时全局光照计算流程图:
```mermaid
graph LR
A[场景渲染] --> B[生成深度贴图]
B --> C[渲染主场景]
C --> D[使用深度贴图计算阴影]
D --> E[输出最终图像]
```
这个流程图简单地描述了从深度贴图生成到最终带有阴影效果的场景渲染过程。
## 代码块
在实时渲染中,开发者需要对使用的各种硬件资源进行精细的控制。以下是一个简化的 GPU 硬件资源使用示例,演示了如何使用 C++ 进行 GPU 资源分配和管理:
```cpp
// GPU资源分配
unsigned int texture;
glGenTextures(1, &texture);
glBindTexture(GL_TEXTURE_2D, texture);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, data);
glGenerateMipmap(GL_TEXTURE_2D);
```
在这个代码段中,使用 `glGenTextures` 创建一个新的纹理对象,`glBindTexture` 绑定到当前上下文中,`glTexImage2D` 生成纹理数据,最后 `glGenerateMipmap` 创建所有必要的多级渐远纹理。
通过上述内容,我们可以看到,高级技术应用的深度和广度。C++ 实时渲染不仅要求深入理解硬件加速的原理,还需要在实践中掌握各种技术细节,从而在游戏和图形应用中创造出既高效又高质量的视觉效果。
# 4. C++实时渲染实践案例分析
## 4.1 游戏引擎渲染优化实例
### 游戏引擎的渲染架构优化
为了实现更流畅的游戏体验,游戏引擎必须经过精心设计和不断优化以适应当前硬件的性能要求。首先,我们应当了解游戏引擎的渲染架构,这是实现优化的基础。游戏引擎的渲染架构主要包括渲染管线的管理、资源的调度、场景的组织、光照和阴影的计算等。
在优化方面,我们可以通过多种手段来提升渲染性能。例如,减少渲染管线的复杂度,将渲染任务分解为更小的单元以提高并行度;使用多线程技术来执行非渲染相关的计算任务,如物理模拟、声音处理等;通过资源管理器高效地加载和卸载资源,避免内存和GPU显存的浪费;以及利用空间分割技术如四叉树或八叉树来减少场景中渲染对象的数量。
### 实际案例中的性能提升策略
在实际的游戏开发过程中,性能优化的策略需要根据具体的情况来制定。例如,在某个第一人称射击游戏中,开发者可能会优先优化角色和武器模型的渲染,因为玩家的注意力通常集中在这些元素上。使用LOD(Level of Detail)技术,可以动态地根据玩家视角与对象的距离更换不同细节级别的模型,这样既节省了渲染资源又保证了视觉效果。
另一个常见的优化策略是使用延迟渲染(Deferred Rendering)技术,将场景中的光照计算推迟到屏幕空间进行,这可以处理大量光源对场景的影响而不显著增加性能负担。此外,通过合理安排渲染调用顺序,可以最小化状态变换的开销,以及通过绘制批次(Draw Batching)来减少渲染调用的次数。
### 代码块示例与逻辑分析
```cpp
// 简单的LOD管理器示例
class LodManager {
private:
float currentDistance;
Model *modelHigh;
Model *modelMedium;
Model *modelLow;
public:
LodManager(Model* high, Model* medium, Model* low) : modelHigh(high), modelMedium(medium), modelLow(low) {}
void SetDistance(float distance) {
currentDistance = distance;
if (currentDistance > HIGH_THRESHOLD) {
// 使用低多边形模型
Render(modelLow);
} else if (currentDistance > MEDIUM_THRESHOLD) {
// 使用中等多边形模型
Render(modelMedium);
} else {
// 使用高多边形模型
Render(modelHigh);
}
}
void Render(Model* model) {
// 这里包含渲染模型的代码
}
};
```
在这个代码示例中,我们创建了一个`LodManager`类来管理不同LOD级别的模型。通过`SetDistance`函数,我们根据观察者的距离来选择并渲染适当的模型。`Render`函数是一个占位函数,实际中应包含具体的渲染逻辑。
### 表格展示优化策略
下面是一个表格,列出了一些常见的渲染优化策略以及它们的应用场景:
| 优化策略 | 应用场景 | 优点 | 注意事项 |
| --- | --- | --- | --- |
| LOD技术 | 场景中距离观察者远的对象 | 减少渲染负载,提升性能 | 注意LOD切换时的视觉跳跃问题 |
| 延迟渲染 | 大量光源的场景 | 动态处理多光源,性能开销低 | 对显存有一定要求,不适用于大量几何体 |
| 批处理绘制 | 需要减少渲染调用次数的场景 | 减少API调用次数,提高效率 | 资源合并时需小心避免过度消耗内存 |
### 4.2 VR/AR渲染优化技术
#### VR/AR渲染的特殊要求
虚拟现实(VR)和增强现实(AR)技术的渲染需求与传统游戏或应用有较大的不同。VR/AR要求极高的帧率和稳定的图像输出以避免用户体验到晕动病。此外,VR/AR应用需要考虑3D环境的重建、头部跟踪以及交互,这些都对渲染性能提出了更高的要求。
#### 优化技术在VR/AR中的应用
为了满足这些要求,开发者们通常会采用一些专门的优化技术。例如,在VR中,使用单遍渲染(Single Pass Rendering)技术可以将双眼图像渲染到同一帧缓冲区中,减少了一半的渲染调用。在AR中,通过预加载和缓存3D资源,可以减少实时加载资源带来的延迟,确保实时性。利用时间扭曲(Time Warping)技术可以对已经渲染完成的帧进行微小调整,以弥补头部移动带来的视觉误差。
### 4.3 跨平台渲染优化策略
#### 跨平台渲染的技术挑战
跨平台渲染面临的最大挑战在于不同平台和设备在硬件性能上的巨大差异。这意味着开发者需要为每个平台制定特定的渲染优化策略。例如,移动设备的GPU性能与PC或游戏机平台相比通常较弱,因此需要更加精细地控制渲染负载和优化资源使用。
#### 跨平台优化策略和案例
为了实现跨平台优化,可以采用一些通用的技术策略。例如,使用动态分辨率技术来根据设备的性能动态调整渲染分辨率。开发者还可以针对不同平台提供不同的图形质量选项,让玩家根据自己的设备选择合适的画质。此外,通过分析性能瓶颈,决定是优化算法复杂度还是使用更高级的硬件特性来提升性能。
为了展示这些策略的实施,我们可以通过一个案例来分析具体的实现。在这个案例中,开发者为一款跨平台的游戏确定了不同的渲染优化方法,如在低端移动设备上关闭某些特效,在高端设备上启用更复杂的光照模型等。通过这种方式,开发者能够在保证游戏性能的同时,让游戏在不同设备上都拥有较为出色的视觉体验。
# 5. 未来C++实时渲染技术展望
## 5.1 实时渲染技术的发展趋势
实时渲染技术随着计算机图形学的不断进步而演变,其发展趋势不仅受到硬件性能提升的影响,还紧密依赖于软件算法和渲染技术的创新。其中一个显著的趋势就是实时光线追踪技术的兴起。
### 5.1.1 新兴技术如光线追踪对实时渲染的影响
光线追踪(Ray Tracing)在传统的离线渲染中广为人知,它能够产生非常真实的渲染效果,包括复杂的光影效果、反射、折射以及全局光照。然而,它对计算资源的需求非常高,通常不被用于实时应用。随着GPU技术的发展,如NVIDIA的RTX系列显卡,实时光线追踪开始成为可能。
光线追踪的优势在于其能够模拟光线在现实世界中的物理行为,从而在渲染过程中产生极其逼真的图像。在C++实时渲染中,通过集成光线追踪API(如DirectX Raytracing,DXR),开发者能够在保持高帧率的同时,为应用添加光线追踪效果,比如电影级别的阴影、反射和散射效果。
```cpp
// 示例代码:在C++中初始化和使用DirectX Raytracing (DXR)
#include <d3d12.h>
#include <d3d12Raytracing.h>
// 创建并初始化DXR资源
void CreateDXRResources(ID3D12Device* pDevice) {
// 这里省略了具体DXR初始化代码
}
// 在渲染循环中调用光线追踪
void RenderWithRayTracing(ID3D12GraphicsCommandList* pCommandList, ... ) {
// 这里省略了具体的光线追踪渲染代码
}
```
### 5.1.2 未来渲染技术的创新点
除了光线追踪,未来实时渲染技术还有许多其他创新点,其中包括:
- **微多边形技术**:通过增加几何细节来提高图像质量,同时使用LOD(细节级别)技术减少资源消耗。
- **视差贴图和位移贴图**:使用贴图技术动态地改变几何体的表面,增强视觉真实感。
- **改进的阴影算法**:如使用VSM(Variance Shadow Maps)来提高阴影的质量与性能。
- **自适应抗锯齿技术**:提升边缘抗锯齿的效率,如TAA(Temporal Anti-Aliasing)等。
## 5.2 深度学习与实时渲染的融合
深度学习,作为一种人工智能算法,已经开始影响实时渲染领域,尤其是在图像生成、超分辨率和视频渲染方面。
### 5.2.1 深度学习在渲染优化中的应用
深度学习模型可以通过分析大量的渲染数据来学习如何优化图像质量,并且可以用于生成逼真的纹理、实时环境遮挡以及光线追踪优化。例如,深度学习超分辨率算法可以将低分辨率图像转换成高分辨率图像,而这个过程可以通过GPU加速进行实时应用。
```cpp
// 示例代码:使用深度学习模型进行图像超分辨率
#include <opencv2/opencv.hpp>
#include <torch/script.h> // One-stop header.
int main() {
// 加载深度学习模型
torch::jit::script::Module module;
try {
module = torch::jit::load("super_resolution_model.pt");
}
catch (const c10::Error& e) {
std::cerr << "模型加载失败\n";
return -1;
}
// 创建图像
cv::Mat image = cv::imread("low_resolution_image.jpg", cv::IMREAD_COLOR);
// 使用深度学习模型处理图像并进行超分辨率处理
// 这里省略了具体的图像处理和超分辨率代码
}
```
### 5.2.2 实现智能渲染的可能路径
智能渲染技术的核心在于使用AI来模拟或者增强渲染过程。比如,智能去噪技术可以实时从渲染的图像中移除噪声,而不必依赖于传统的多帧采样技术。此外,AI还可以用于优化渲染管线,例如智能资源管理、动态调度渲染任务等。
智能渲染的实现路径可能包括以下几个方面:
- **深度学习去噪**:训练深度学习模型以识别和去除图像中的噪点。
- **AI驱动的渲染路径决策**:根据实时场景分析结果动态调整渲染技术。
- **智能图像处理**:利用AI优化图像的最终呈现,例如色调映射、色彩校正等。
总之,实时渲染技术正处于快速发展阶段,其未来不仅包括传统技术的提升,还融合了人工智能的先进算法,为开发者提供了无限的可能性。随着技术的不断进步,未来的实时渲染将更加逼真、高效和智能化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 C++ 在实时渲染技术中的应用,涵盖了广泛的主题,包括:
* 结合 OpenGL 实现高效的 2D 渲染
* 资源管理策略以优化内存使用
* 构建粒子系统以创建动态世界
* 多线程渲染技术以提高效率
* 探索 Vulkan API 以利用下一代图形功能
* 延迟渲染与光栅化的比较和最佳实践
* 高质量抗锯齿技术,包括 MSAA 和 SSAA
* 渲染引擎架构设计以构建可扩展系统
* 视觉效果渲染以实现逼真的视觉体验
* 材质和纹理管理策略以优化渲染性能
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Docker基础入门】:掌握Docker技术,开启云原生之旅

# 摘要
Docker作为一种流行的容器化技术,在软件开发和部署领域中扮演着重要角色。本文从Docker技术的基础知识讲起,逐步深入到安装、配置、镜像制作与管理、容器实践应用以及企业级应用与实践。通过系统性地介绍Docker环境的搭建、命令行操作、网络与存储配置、镜像的构建优化、镜像仓库的维护,以及容器化应用的部署和监控,本文旨在为读者提供全面的Docker使
版图软件Laker个性化设置:打造高效能工作环境的6个策略

# 摘要
版图软件Laker作为电子设计自动化(EDA)领域的重要工具,其个性化设置对于提高设计效率和用户体验至关重要。本文首先概述了Laker个性化设置的基本概念和界面优化方法,包括用户界面的个性化调整、工具栏和面板的布局优化以及视图和显示选项的定制。接着,文章深入探讨了自动化与宏命令的高级应用,强调了创建、编
LabSpec 5性能监控与调优全攻略:确保测试稳定性
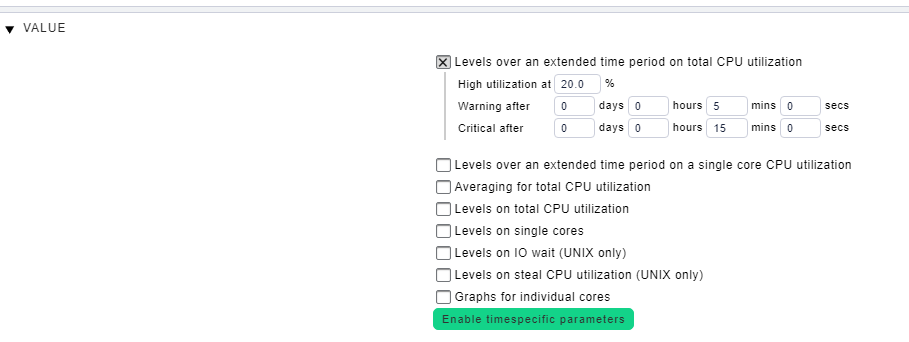
# 摘要
本文旨在详细介绍LabSpec 5平台在性能监控与调优方面的应用与实践。首先,概述了性能监控的基础理论,包括监控的目标、重要性以及关键性能指标。随后,探讨了LabSpec 5平台上的监控工具,并比较了内置工具与第三方工具。在性能调优策略方面,本文分析了系统资源、网络性能及应用程序的优化方法。进一步地,介绍了LabSpec
如何制定IPD评审计划:5个步骤实现有效的DCP应用

# 摘要
本文深入探讨了集成产品开发(IPD)评审计划的制定与执行。首先概述了IPD评审计划的基本理论和框架,分析了其目标和作用,以及评审流程。接着,本文详细介绍了制定IPD评审计划的五个关键步骤,强调了项目准备、评审时间表、评审内容和标准的确立、资源和工具的准备以及执行和持续改进的重要性。通过实践案例分析,探讨了IPD评审计划的成功应用、面临的挑战、应对策略以及经验教训。最后,本文评
【Python高效数据导入秘籍】:提升电子表格数据处理的7个实用技巧

# 摘要
Python数据导入是数据分析和处理的首要步骤,其重要性不言而喻。本文系统地阐述了Python中基础数据导入技术的使用,包括内置库的简单应用和pandas库等高级技术。同时,针对数据导入的性能优化进行了深入探讨,提出了一系列优化策略,并详细介绍了Dask和PyTables等工具在处理大数据导入中的应用。本文还深入探讨了数据预处理与清洗的有效方法,确保数据质量,并给出了特定格式数据导入的高级技巧。最后,文章展望了数据导入自动化和集成的
Matlab助力工业机器人精度提升:10大仿真技巧与案例分析
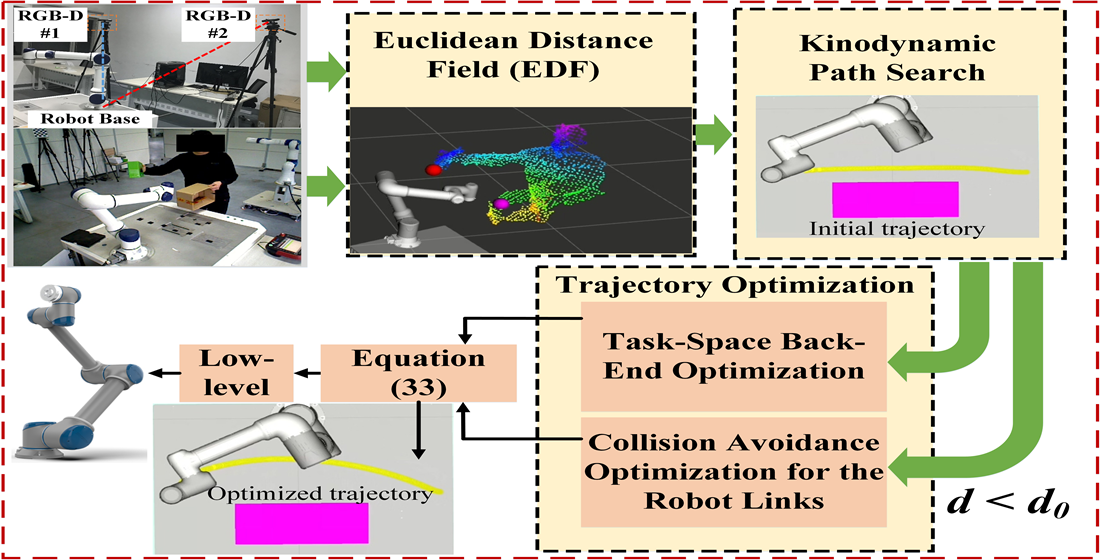
# 摘要
本文综述了Matlab在工业机器人领域的应用,从基础仿真环境搭建至机器人建模、精度提升技巧,以及实际案例分析与实操技巧。详细介绍了Matlab软件的安装配置、仿真环境与工具箱,阐述了机器人运动学、动力学仿真、路径规划与轨迹优化的基本理论和方法。通过实际应用案例,探讨了Matlab在提高机器人系
【PowerArtist从入门到精通】:10个实用技巧快速提升代码质量

# 摘要
本文全面介绍了PowerArtist工具的安装、使用及其在提升代码质量方面的应用。首先概述了代码质量的定义、重要性以及静态分析与动态分析的区别。随后,深入探讨了通过PowerArtist进行代码质量检测的技巧,包括代码复杂度分析、编码规范检查和冗余代码检测。接着,本文进一步阐述了使用PowerArtist进行代码质量改进的策略,如代码重构、
BusMaster硬件兼容秘籍:保障系统最佳状态的技巧
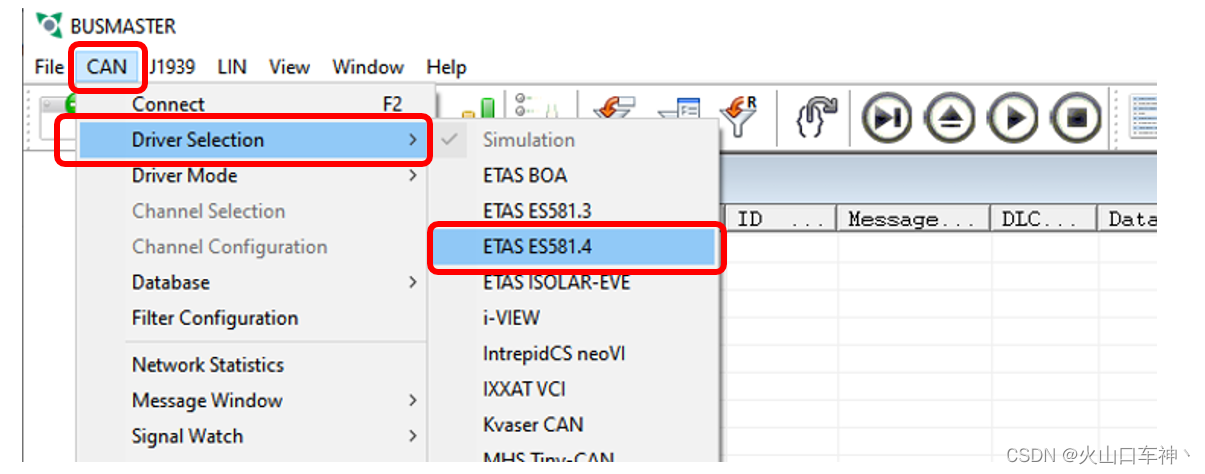
# 摘要
随着电子技术的快速发展,BusMaster硬件在系统集成中的兼容性问题逐渐凸显。本文系统地概述了BusMaster硬件兼容性的重要性,分析了硬件规范与标准,并介绍了兼容性测试的实践方法。通过深入探讨BusMaster驱动的安装与配置、硬件升级与维护以及解决兼容性问题的技巧,本文为工程师提供了实用的指导和案例分析。此外,本文还探讨了高级兼容性策略,包括预防措施和跨平台解决方案,并展望了BusMaster在未来面临的技术
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )