揭秘Python读取CSV文件:从入门到精通


用python读取CSV数据
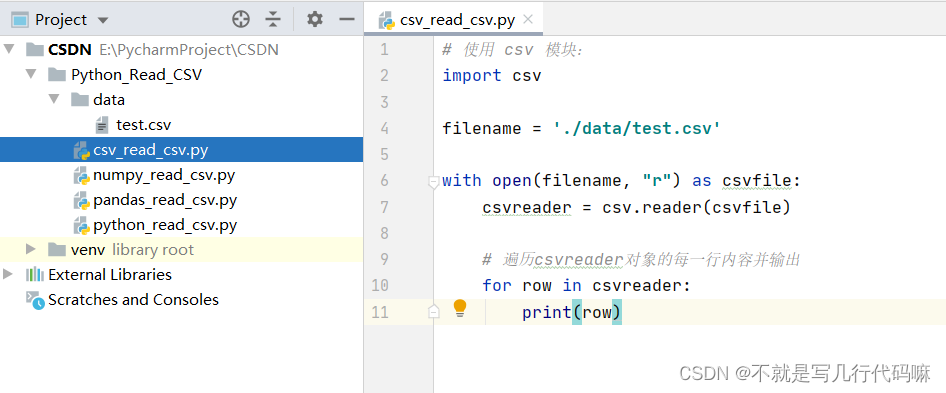
1. Python读取CSV文件基础
CSV(逗号分隔值)文件是一种广泛使用的文本文件格式,用于存储表格数据。Python提供了多种模块和方法来读取CSV文件,这使得数据分析和处理变得更加容易。
1.1 CSV模块的安装和使用
csv模块是Python标准库中用于处理CSV文件的模块。要安装它,请使用以下命令:
- pip install csv
导入csv模块后,可以使用以下代码读取CSV文件:
- import csv
- with open('data.csv', 'r') as f:
- reader = csv.reader(f)
- for row in reader:
- print(row)
1.2 pd.read_csv()方法的详细解析
Pandas库提供了pd.read_csv()方法,它提供了更高级的功能来读取CSV文件。该方法接受许多参数,包括:
filepath_or_buffer:CSV文件路径或文件对象。sep:分隔符字符(默认为逗号)。header:指定是否将第一行作为标题行(默认为True)。index_col:指定要作为索引列的列(默认为None)。
以下代码演示如何使用pd.read_csv()方法读取CSV文件:
- import pandas as pd
- df = pd.read_csv('data.csv')
- print(df.head())
2. Python CSV文件读取技巧
2.1 CSV文件读取的模块和方法
2.1.1 csv模块的安装和使用
CSV文件读取最常用的模块是csv模块,该模块提供了读取和写入CSV文件的方法。要安装csv模块,可以使用以下命令:
- pip install csv
安装完成后,可以通过以下代码导入csv模块:
- import csv
2.1.2 pd.read_csv()方法的详细解析
pd.read_csv()方法是pandas库中用于读取CSV文件的主要方法。该方法接收一个文件路径或文件对象作为参数,并返回一个DataFrame对象,其中包含CSV文件中的数据。
pd.read_csv()方法的语法如下:
- pd.read_csv(filepath_or_buffer, sep=',', header='infer', index_col=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
参数说明:
filepath_or_buffer:CSV文件路径或文件对象。sep:分隔符,默认为逗号。header:指定CSV文件是否包含标题行,默认为infer,表示自动推断。index_col:指定要作为索引的列,默认为None,表示不使用索引。dtype:指定每列的数据类型,默认为None,表示自动推断。engine:指定解析引擎,默认为None,表示使用默认引擎。converters:指定自定义转换器,默认为None,表示不使用自定义转换器。true_values:指定表示真值的字符串列表,默认为None,表示使用默认值。false_values:指定表示假值的字符串列表,默认为None,表示使用默认值。skipinitialspace:指定是否跳过每行开头的空白字符,默认为False。skiprows:指定要跳过的行号列表,默认为None,表示不跳过任何行。nrows:指定要读取的行数,默认为None,表示读取所有行。na_values:指定表示缺失值的字符串列表,默认为None,表示使用默认值。keep_default_na:指定是否保留默认的缺失值标记,默认为True。na_filter:指定是否过滤缺失值,默认为True。verbose:指定是否输出详细的解析信息,默认为False。skip_blank_lines:指定是否跳过空行,默认为True。parse_dates:指定是否将指定列解析为日期时间对象,默认为False。infer_datetime_format:指定是否自动推断日期时间格式,默认为False。keep_date_col:指定是否保留日期时间列,默认为False。date_parser:指定自定义日期时间解析器,默认为None,表示不使用自定义解析器。dayfirst:指定是否将日期格式中的第一个元素视为天,默认为False。cache_dates:指定是否缓存日期时间对象,默认为True。iterator:指定是否返回一个迭代器,默认为False。chunksize:指定每次返回的行数,默认为None,表示返回所有行。compression:指定压缩格式,默认为infer,表示自动推断。thousands:指定千位分隔符,默认为None,表示不使用千位分隔符。decimal:指定小数点分隔符,默认为.。lineterminator:指定行终止符,默认为None,表示使用默认值。quotechar:指定引用字符,默认为"。quoting:指定引用风格,默认为0,表示不引用。doublequote:指定是否将双引号视为引用字符,默认为True。escapechar:指定转义字符,默认为None,表示不使用转义字符。comment:指定注释字符,默认为None,表示不使用注释字符。encoding:指定文件编码,默认为None,表示使用默认编码。dialect:指定方言,默认为None,表示不使用方言。error_bad_lines:指定是否在遇到错误行时引发异常,默认为True。warn_bad_lines:指定是否在遇到错误行时发出警告,默认为True。delim_whitespace:指定是否将空白字符视为分隔符,默认为False。low_memory:指定是否使用低内存模式,默认为True。memory_map:指定是否将文件映射到内存,默认为False。float_precision:指定浮点数精度,默认为None,表示使用默认精度。
代码逻辑:
pd.read_csv()方法首先读取CSV文件并将其内容存储在内部缓冲区中。然后,它根据指定的参数解析缓冲区中的内容并将其转换为DataFrame对象。解析过程包括:
- 将每一行分割成列,使用指定的
sep分隔符。 - 根据指定的
header参数确定是否使用第一行作为标题行。 - 将每一列转换为指定的数据类型,使用指定的
dtype参数。 - 将指定的列设置为索引,使用指定的
index_col参数。 - 处理缺失值,使用指定的
na_values和na_filter参数。 - 处理日期时间数据,使用指定的
parse_dates和infer_datetime_format参数。
参数说明:
filepath_or_buffer:CSV文件路径或文件对象。sep:分隔符,默认为逗号。header:指定CSV文件是否包含标题行,默认为infer,表示自动推断。index_col:指定要作为索引的列,默认为None,表示不使用索引。dtype:指定每列的数据类型,默认为None,表示自动推断。engine:指定解析引擎,默认为None,表示使用默认引擎。converters:指定自定义转换器,默认为None,表示不使用自定义转换器。true_values:指定表示真值的字符串列表,默认为None,表示使用默认值。false_values:指定表示假值的字符串列表,默认为None,表示使用默认值。skipinitialspace:指定是否跳过每行开头的空白字符,默认为False。skiprows:指定要跳过的行号列表,默认为None,表示不跳过任何行。nrows:指定要读取的行数,默认为None,表示读取所有行。na_values:指定表示缺失值的字符串列表,默认为None,表示使用默认值。keep_default_na:指定是否保留默认的缺失值标记,默认为True。na_filter:指定是否过滤缺失值,默认为True。verbose:指定是否输出详细的解析信息,默认为False。skip_blank_lines:指定是否跳过空行,默认为True。parse_dates:指定是否将指定列解析为日期时间对象,默认为False。infer_datetime_format:指定是否自动推断日期时间格式,默认为False。keep_date_col:指定是否保留日期时间列,默认为False。date_parser:指定自定义日期时间解析器,默认为None,表示不使用自定义解析器。dayfirst:指定是否将日期格式中的第一个元素视为天,默认为False。cache_dates:指定是否缓存日期时间对象
3. Python CSV文件读取实践应用
3.1 CSV文件读取的Pandas操作
3.1.1 数据框的创建和操作
Pandas库是Python中用于数据处理和分析的强大工具。它提供了DataFrame数据结构,可以方便地表示和操作CSV文件中的数据。
创建数据框
- import pandas as pd
- # 从CSV文件创建数据框
- df = pd.read_csv('data.csv')
数据框操作
- 查看数据框:使用
head()和tail()方法查看数据框的前几行和后几行。 - 获取数据框信息:使用
info()方法获取数据框的摘要信息,包括数据类型、缺失值数量等。 - 选择列:使用
df['column_name']或df[['column_name1', 'column_name2']]选择特定的列。 - 添加列:使用
df['new_column_name'] = ...添加新列。 - 删除列:使用
df.drop('column_name', axis=1)删除列。 - 修改列:使用
df['column_name'].fillna(...)填充缺失值,或df['column_name'].replace(...)替换值。
3.1.2 数据过滤和排序
Pandas提供了强大的数据过滤和排序功能,可以根据条件筛选数据并按指定列排序。
数据过滤
- # 过滤特定条件的数据
- filtered_df = df[df['column_name'] > 10]
数据排序
- # 按特定列升序排序
- sorted_df = df.sort_values('column_name')
- # 按特定列降序排序
- sorted_df = df.sort_values('column_name', ascending=False)
3.2 CSV文件读取的NumPy操作
3.2.1 NumPy数组的创建和操作
NumPy库是Python中用于科学计算的库。它提供了ndarray数组数据结构,可以高效地存储和操作CSV文件中的数值数据。
创建数组
- import numpy as np
- # 从CSV文件创建数组
- arr = np.loadtxt('data.csv', delimiter=',')
数组操作
- 获取数组形状:使用
arr.shape获取数组的维度和大小。 - 选择元素:使用
arr[row_index, column_index]或arr[start_index:end_index]选择特定的元素。 - 修改元素:使用
arr[row_index, column_index] = value修改特定的元素。 - 数学运算:使用
+,-,*,/等运算符进行数学运算。 - 统计分析:使用
np.mean(),np.median(),np.std()等函数进行统计分析。
3.2.2 数据的数学运算和统计分析
NumPy提供了丰富的数学运算和统计分析函数,可以对CSV文件中的数据进行各种操作。
数学运算
- # 计算数组元素的和
- total = np.sum(arr)
- # 计算数组元素的平均值
- average = np.mean(arr)
统计分析
- # 计算数组元素的最大值
- max_value = np.max(arr)
- # 计算数组元素的标准差
- std_dev = np.std(arr)
4. Python CSV文件读取进阶应用
4.1 CSV文件读取的正则表达式
4.1.1 正则表达式的基本语法和元字符
正则表达式(Regular Expression,简称Regex)是一种强大的模式匹配语言,广泛应用于文本处理、数据挖掘等领域。其基本语法和元字符如下:
-
元字符:
.:匹配任意单个字符*:匹配前一个字符0次或多次+:匹配前一个字符1次或多次?:匹配前一个字符0次或1次^:匹配字符串的开头$:匹配字符串的结尾[]:匹配方括号内的任意单个字符[^]:匹配方括号内外的任意单个字符|:匹配多个模式中的任意一个
-
语法:
pattern:正则表达式模式re.match(pattern, string):匹配字符串开头re.search(pattern, string):匹配字符串中任意位置re.findall(pattern, string):查找所有匹配子串
4.1.2 正则表达式在CSV文件读取中的应用
正则表达式可以用于CSV文件读取中,例如:
- 提取特定列:
re.findall(r'列名', csv_data) - 过滤特定行:
re.findall(r'条件', csv_data) - 验证数据格式:
re.match(r'格式', csv_data)

4.2 CSV文件读取的数据库编程
4.2.1 数据库的连接和操作
Python可以通过第三方库(如PyMySQL、psycopg2)连接和操作数据库。连接数据库的步骤如下:
4.2.2 SQL语句的执行和结果处理
SQL语句用于操作数据库中的数据,包括查询、插入、更新和删除。执行SQL语句的步骤如下:
- # 执行查询语句
- cursor.execute('SELECT * FROM table_name')
- # 获取结果
- results = cursor.fetchall()
- # 遍历结果
- for row in results:
- print(row)
- # 执行插入语句
- cursor.execute('INSERT INTO table_name (name, age) VALUES (%s, %s)', ('John', 30))
- # 执行更新语句
- cursor.execute('UPDATE table_name SET age = %s WHERE name = %s', (31, 'John'))
- # 执行删除语句
- cursor.execute('DELETE FROM table_name WHERE name = %s', ('John'))
5. Python CSV文件读取性能优化
5.1 CSV文件读取的优化策略
5.1.1 数据预处理
- **数据类型转换:**将数据类型转换为更紧凑的数据类型,例如将浮点数转换为整数。
- **数据压缩:**使用gzip或bzip2等压缩算法压缩CSV文件,以减少文件大小。
- **数据分块:**将CSV文件分成较小的块,以便一次只加载一部分数据。
5.1.2 算法选择
- **使用Pandas的快速解析器:**Pandas提供了一个名为"fastparquet"的快速解析器,可以显著提高大型CSV文件的读取速度。
- **使用NumPy的genfromtxt()函数:**NumPy的genfromtxt()函数比Pandas的read_csv()函数更快,但它不支持所有CSV特性。
- **使用C或C++扩展:**使用C或C++扩展可以进一步提高CSV文件读取的性能。
5.2 CSV文件读取的并行处理
5.2.1 多进程和多线程的应用
- **多进程:**使用多进程将CSV文件读取任务分配给多个进程,每个进程处理文件的一部分。
- **多线程:**使用多线程将CSV文件读取任务分配给多个线程,所有线程共享同一内存空间。
5.2.2 分布式计算框架的利用
- **Apache Spark:**Apache Spark是一个分布式计算框架,可以将CSV文件读取任务分布到多个节点上。
- **Dask:**Dask是一个并行计算库,可以将CSV文件读取任务分解为较小的任务,并在多个工作节点上执行。
代码示例:
6. Python CSV文件读取案例实战
6.1 数据分析案例
6.1.1 数据清洗和预处理
在数据分析场景中,CSV文件往往包含大量杂乱无章的数据,需要进行清洗和预处理才能进行后续的分析。常见的清洗和预处理步骤包括:
- 缺失值处理: 缺失值会影响数据分析的准确性,需要根据具体情况进行处理,如删除缺失值、用平均值或中位数填充缺失值等。
- 异常值处理: 异常值是指与其他数据点明显不同的数据,可能会影响分析结果,需要进行识别和处理,如删除异常值或将其替换为更合理的值。
- 数据类型转换: CSV文件中的数据可能包含不同类型的数据,如字符串、数字、日期等,需要根据分析需求进行数据类型转换,如将字符串转换为数字、将日期转换为时间戳等。
6.1.2 数据可视化和分析
数据清洗和预处理后,可以进行数据可视化和分析。常见的数据可视化方法包括:
- 条形图: 展示不同类别或组别的数据分布情况。
- 折线图: 展示数据随时间或其他变量的变化趋势。
- 散点图: 展示两个变量之间的关系。
数据分析可以基于可视化的结果进行,如:
- 趋势分析: 识别数据随时间或其他变量的变化趋势。
- 相关性分析: 探索不同变量之间的相关关系。
- 聚类分析: 将数据点划分为不同的组别或簇。
6.2 机器学习案例
6.2.1 数据预处理和特征工程
在机器学习场景中,CSV文件中的数据需要进行预处理和特征工程才能用于模型训练。常见的数据预处理和特征工程步骤包括:
- 特征选择: 选择与目标变量相关性较强的特征,剔除无关或冗余的特征。
- 特征缩放: 将不同特征的数据值缩放至同一范围,避免特征值过大或过小对模型训练的影响。
- 数据归一化: 将数据值归一化到[0, 1]或[-1, 1]的范围内,提高模型的训练效率和稳定性。
6.2.2 模型训练和评估
数据预处理和特征工程后,可以进行模型训练和评估。常见的机器学习模型类型包括:
- 线性回归: 用于预测连续型目标变量。
- 逻辑回归: 用于预测二分类目标变量。
- 决策树: 用于分类和回归任务。
模型训练后,需要进行评估,以衡量模型的性能。常见的评估指标包括:
- 准确率: 正确预测的样本数占总样本数的比例。
- 召回率: 正确预测的正例数占实际正例数的比例。
- F1值: 准确率和召回率的加权调和平均值。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
eWebEditor在移动端的极致适配:优化用户体验的关键步骤
【菊水电源通讯手册:案例分析与经验分享】:最佳实践揭露
STC8项目案例精讲:从新手到专家的实战指南
工业通信策略:高级通信技术在STM32F103C8T6中的应用
TFS2015数据备份与恢复:3大关键步骤保障数据安全
案例研究:SAP语言包安装成功经验与企业应用分享
从v9到v10:Genesis系统升级全攻略,挑战与应对
【Android USB摄像头终极指南】:5个技巧助你成为Camera API大师
VHDL-AMS进阶指南:5个高级特性解析,专家级理解不是梦
【机器人建模必修课】:掌握D-H建模技巧,提升机器人设计效率


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )










