【Python读取CSV文件:10个提升效率的实用技巧】
发布时间: 2024-06-23 13:51:51 阅读量: 167 订阅数: 48 
# 1. CSV文件简介和读取基础
CSV(逗号分隔值)文件是一种广泛用于存储表格数据的文本文件格式。它以其简单性和易于解析而闻名。
### 1.1 CSV文件结构
CSV文件由一行行文本组成,每行表示一个记录。记录中的字段由分隔符(通常是逗号)分隔。第一行通常是标题行,其中包含每个字段的名称。
### 1.2 读取CSV文件
使用Python读取CSV文件有几种方法:
- 使用`csv`模块:`csv`模块提供了`reader`函数,它可以逐行迭代CSV文件。
- 使用`Pandas`库:`Pandas`库提供了`read_csv`函数,它可以将CSV文件加载到DataFrame中。
# 2. 提升CSV文件读取效率的技巧
### 2.1 优化文件读取模式
在读取CSV文件时,选择合适的读取模式可以显著提升读取效率。
#### 2.1.1 使用'r'模式进行只读操作
'r'模式是默认的读取模式,仅允许读取文件内容,不能写入或修改文件。对于只读操作,使用'r'模式可以避免不必要的写入操作,从而提高读取速度。
```python
with open('data.csv', 'r') as f:
# 读取文件内容
```
#### 2.1.2 使用'rb'模式进行二进制读取
对于包含二进制数据的CSV文件,使用'rb'模式进行二进制读取可以避免Python进行字符编码转换,从而提升读取速度。
```python
with open('data.csv', 'rb') as f:
# 读取二进制数据
```
### 2.2 利用Pandas库进行高效读取
Pandas库提供了高效的CSV文件读取函数,可以简化读取过程并提升效率。
#### 2.2.1 使用read_csv()函数
read_csv()函数是Pandas库中读取CSV文件的主要函数。它提供了多种参数,可以优化读取过程。
```python
import pandas as pd
# 读取CSV文件
df = pd.read_csv('data.csv')
```
#### 2.2.2 指定数据类型和解析器
read_csv()函数允许指定数据类型和解析器,以提高读取效率。
```python
# 指定数据类型
df = pd.read_csv('data.csv', dtype={'id': int, 'name': str})
# 指定解析器
df = pd.read_csv('data.csv', engine='c')
```
### 2.3 优化文件解析器
CSV文件解析器负责将文本数据解析为结构化的数据。优化解析器可以提高读取效率。
#### 2.3.1 使用csv.Sniffer()检测分隔符
csv.Sniffer()类可以自动检测CSV文件的分隔符,从而避免手动指定分隔符带来的错误。
```python
import csv
# 检测分隔符
sniffer = csv.Sniffer()
dialect = sniffer.sniff('data.csv')
# 使用检测到的分隔符读取文件
with open('data.csv', 'r') as f:
reader = csv.reader(f, dialect)
```
#### 2.3.2 使用csv.reader()自定义解析规则
csv.reader()函数允许自定义解析规则,以提高读取效率。
```python
# 自定义分隔符和换行符
reader = csv.reader(open('data.csv', 'r'), delimiter=',', lineterminator='\n')
# 逐行读取文件
for row in reader:
# 处理每一行数据
```
# 3. 处理CSV文件中的常见问题
### 3.1 处理缺失值和空值
CSV文件中经常会出现缺失值或空值,这会对数据分析和处理造成影响。处理缺失值和空值的方法有多种,以下介绍两种常见的方法:
#### 3.1.1 使用fillna()函数填充缺失值
fillna()函数可以用来填充缺失值,它接受一个值作为参数,用于填充所有缺失值。例如,以下代码使用fillna()函数用0填充缺失值:
```python
import pandas as pd
df = pd.read_csv('data.csv')
df.fillna(0, inplace=True)
```
**代码逻辑分析:**
* `pd.read_csv('data.csv')`:读取CSV文件并将其加载到DataFrame中。
* `df.fillna(0, inplace=True)`:使用fillna()函数用0填充DataFrame中的所有缺失值。inplace=True参数表示直接修改DataFrame,而不是返回一个新的DataFrame。
#### 3.1.2 使用dropna()函数删除空行
dropna()函数可以用来删除包含空值的整行数据。它接受一个axis参数,指定要删除的行或列。例如,以下代码使用dropna()函数删除包含任何空值的整行数据:
```python
import pandas as pd
df = pd.read_csv('data.csv')
df.dropna(inplace=True)
```
**代码逻辑分析:**
* `pd.read_csv('data.csv')`:读取CSV文件并将其加载到DataFrame中。
* `df.dropna(inplace=True)`:使用dropna()函数删除DataFrame中包含任何空值的整行数据。inplace=True参数表示直接修改DataFrame,而不是返回一个新的DataFrame。
### 3.2 处理数据类型不一致
CSV文件中还经常会出现数据类型不一致的问题,这会影响数据的处理和分析。处理数据类型不一致的方法有多种,以下介绍两种常见的方法:
#### 3.2.1 使用astype()函数转换数据类型
astype()函数可以用来转换数据类型。它接受一个dtype参数,指定要转换的目标数据类型。例如,以下代码使用astype()函数将DataFrame中的"age"列转换为整数类型:
```python
import pandas as pd
df = pd.read_csv('data.csv')
df['age'] = df['age'].astype(int)
```
**代码逻辑分析:**
* `pd.read_csv('data.csv')`:读取CSV文件并将其加载到DataFrame中。
* `df['age'] = df['age'].astype(int)`:使用astype()函数将DataFrame中的"age"列转换为整数类型。
#### 3.2.2 使用to_numeric()函数将字符串转换为数字
to_numeric()函数可以用来将字符串转换为数字。它接受一个errors参数,指定在转换失败时的处理方式。例如,以下代码使用to_numeric()函数将DataFrame中的"age"列转换为浮点类型,并忽略转换失败的错误:
```python
import pandas as pd
df = pd.read_csv('data.csv')
df['age'] = pd.to_numeric(df['age'], errors='coerce')
```
**代码逻辑分析:**
* `pd.read_csv('data.csv')`:读取CSV文件并将其加载到DataFrame中。
* `df['age'] = pd.to_numeric(df['age'], errors='coerce')`:使用to_numeric()函数将DataFrame中的"age"列转换为浮点类型,并忽略转换失败的错误。
# 4. 高级CSV文件处理技巧**
**4.1 使用正则表达式提取特定数据**
正则表达式是一种强大的工具,可用于在文本中匹配模式。我们可以使用正则表达式从CSV文件中提取特定数据。
**4.1.1 使用re.search()函数匹配模式**
`re.search()`函数可用于在字符串中搜索匹配给定正则表达式的第一个子串。语法如下:
```python
re.search(pattern, string)
```
其中:
* `pattern`:要匹配的正则表达式
* `string`:要搜索的字符串
例如,以下代码从CSV文件中提取所有包含单词“apple”的行:
```python
import csv
import re
with open('data.csv', 'r') as f:
reader = csv.reader(f)
for row in reader:
if re.search('apple', row[0]):
print(row)
```
**4.1.2 使用re.findall()函数提取所有匹配**
`re.findall()`函数可用于在字符串中查找所有匹配给定正则表达式的子串。语法如下:
```python
re.findall(pattern, string)
```
其中:
* `pattern`:要匹配的正则表达式
* `string`:要搜索的字符串
例如,以下代码从CSV文件中提取所有包含数字的行:
```python
import csv
import re
with open('data.csv', 'r') as f:
reader = csv.reader(f)
for row in reader:
numbers = re.findall('[0-9]+', row[0])
if numbers:
print(row)
```
**4.2 使用NumPy库进行数据分析**
NumPy是一个强大的库,用于处理多维数组和矩阵。我们可以使用NumPy来分析CSV文件中的数据。
**4.2.1 使用loadtxt()函数读取CSV文件**
`loadtxt()`函数可用于从CSV文件加载数据到NumPy数组。语法如下:
```python
numpy.loadtxt(fname, delimiter=',', skiprows=0)
```
其中:
* `fname`:CSV文件的文件名
* `delimiter`:分隔符(默认为逗号)
* `skiprows`:要跳过的行数(默认为0)
例如,以下代码从CSV文件中加载数据到NumPy数组:
```python
import numpy as np
data = np.loadtxt('data.csv', delimiter=',')
print(data)
```
**4.2.2 使用NumPy数组进行数据处理**
一旦数据加载到NumPy数组中,我们就可以使用NumPy函数对其进行处理。例如,以下代码计算数组中每个元素的平均值:
```python
mean = np.mean(data)
print(mean)
```
# 5.1 使用csv.writer()函数写入CSV文件
### 5.1.1 设置分隔符和换行符
在使用`csv.writer()`函数写入CSV文件时,可以指定分隔符和换行符。分隔符用于分隔不同的字段,而换行符用于分隔不同的行。
```python
import csv
# 创建一个CSV文件
with open('data.csv', 'w', newline='') as csvfile:
# 创建一个CSV写入器
csvwriter = csv.writer(csvfile, delimiter=',', lineterminator='\n')
# 写入数据
csvwriter.writerow(['Name', 'Age', 'City'])
csvwriter.writerow(['John', '30', 'New York'])
csvwriter.writerow(['Jane', '25', 'London'])
```
在上面的代码中,我们使用`delimiter`参数指定分隔符为逗号(`,`),使用`lineterminator`参数指定换行符为换行符(`\n`)。
### 5.1.2 使用writerow()和writerows()方法写入数据
使用`csv.writer()`函数写入数据时,可以使用`writerow()`方法写入一行数据,也可以使用`writerows()`方法写入多行数据。
```python
import csv
# 创建一个CSV文件
with open('data.csv', 'w', newline='') as csvfile:
# 创建一个CSV写入器
csvwriter = csv.writer(csvfile, delimiter=',', lineterminator='\n')
# 使用writerow()方法写入一行数据
csvwriter.writerow(['Name', 'Age', 'City'])
# 使用writerows()方法写入多行数据
data = [['John', '30', 'New York'], ['Jane', '25', 'London']]
csvwriter.writerows(data)
```
在上面的代码中,我们使用`writerow()`方法写入标题行,使用`writerows()`方法写入数据行。
# 6. **6.1 优化文件大小**
CSV文件的大小可能会随着数据量的增加而变得很大。为了优化文件大小,可以采用以下技巧:
### **6.1.1 使用压缩算法**
压缩算法可以显著减少CSV文件的大小。最常用的压缩算法是GZIP和BZIP2。
**示例:**
```python
import gzip
with gzip.open('data.csv.gz', 'wb') as f:
f.write(data)
```
### **6.1.2 删除不必要的数据**
CSV文件中可能包含不必要的数据,例如重复的行或空行。删除这些数据可以减小文件大小。
**示例:**
```python
import pandas as pd
df = pd.read_csv('data.csv')
df.drop_duplicates(inplace=True)
df.dropna(inplace=True)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
本专栏全面探讨了使用 Python 读取 CSV 文件的各种方法和技术。从入门指南到高级技巧,文章涵盖了提升效率、解决常见问题、处理复杂数据、优化性能和构建自定义读取器的实用技巧。此外,专栏还深入分析了 Pandas 和 NumPy 库,提供了基于场景的最佳实践,并介绍了并发、多线程、面向对象编程和测试驱动开发等高级概念。无论是初学者还是经验丰富的开发人员,本专栏都提供了宝贵的见解,帮助读者充分利用 Python 的 CSV 读取功能,高效地处理和分析数据。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
YXL480扩展性探讨:系统升级与扩展的8大策略
# 摘要
随着信息技术的快速发展,YXL480系统面临着不断增长的性能和容量需求。本文对YXL480的扩展性进行了全面概述,并详细分析了系统升级和扩展策略,包括硬件和软件的升级路径、网络架构的优化、模块化扩展方法、容量规划以及技术债务管理。通过实践案例分析,本文揭示了系统升级与扩展过程中的关键策略与决策,挑战与解决方案,并进行了综合评估与反馈。文章最后对新兴技术
【编译原理核心算法】:掌握消除文法左递归的经典算法(编译原理中的算法秘籍)

# 摘要
编译原理中的文法左递归问题一直是理论与实践中的重要课题。本文首先介绍编译原理与文法左递归的基础知识,随后深入探讨文法左递归的理论基础,包括文法的定义、分类及其对解析的影响。接着,文章详细阐述了消除直接与间接左递归的算法原理与实践应用,并
【S7-1200_S7-1500故障诊断与维护】:最佳实践与案例研究

# 摘要
本文首先对S7-1200/1500 PLC进行了概述,介绍了其基本原理和应用基础。随后,深入探讨了故障诊断的理论基础,包括故障诊断概念、目的、常见故障类型以及诊断方法和工具。文章第三章聚焦于S7-1200/1500 PLC的维护实践,讨论了日常维护流程、硬件维护技巧以及软件维护与更新的策略。第四章通过故障案例研究与分析,阐述了实际故障处理和维护
分析劳动力市场趋势的IT工具:揭秘如何保持竞争优势

# 摘要
在不断变化的经济环境中,劳动力市场的趋势分析对企业和政策制定者来说至关重要。本文探讨了IT工具在收集、分析和报告劳动力市场数据中的应用,并分析了保持竞争优势的IT策略。文章还探讨了未来IT工具的发展方向,包括人工智能与自动化、云计算与大数据技术,以及
搜索引擎核心组成详解:如何通过数据结构优化搜索算法

# 摘要
搜索引擎是信息检索的重要工具,其工作原理涉及复杂的数据结构和算法。本文从搜索引擎的基本概念出发,逐步深入探讨了数据结构基础,包括文本预处理、索引构建、搜索算法中的关键数据结构以及数据压缩技术。随后,文章分析了搜索引擎算法实践应用,讨论了查询处理、实时搜索、个性化优化等关键环节。文章还探讨了搜索引擎高级功能的实现,如自然语言处理和多媒体搜索技术,并分析了大数据环境下搜索引
Edge存储释放秘籍:缓存与历史清理策略

# 摘要
Edge存储是边缘计算中的关键组成部分,其性能优化对于提升整体系统的响应速度和效率至关重要。本文首先介绍了Edge存储的基础概念,包括缓存的作用、优势以及管理策略,探讨了如何在实践中权衡缓存大小
解决兼容性难题:Aspose.Words 15.8.0 如何与旧版本和平共处

# 摘要
Aspose.Words是.NET领域内用于处理文档的强大组件,广泛应用于软件开发中以实现文档生成、转换、编辑等功能。本文从版本兼容性问题、新版本改进、代码迁移与升级策略、实际案例分析
深入SPC世界:注塑成型质量保证与风险评估的终极指南
# 摘要
本文综合探讨了注塑成型技术中统计过程控制(SPC)的应用、风险管理以及质量保证实践。首先介绍了SPC的基础知识及其在注塑成型质量控制中的核心原理和工具。接着,文章详述了风险管理流程,包括风险识别、评估和控制策略,并强调了SPC在其中的应用
IT服务连续性管理策略:遵循ISO20000-1:2018的实用指南
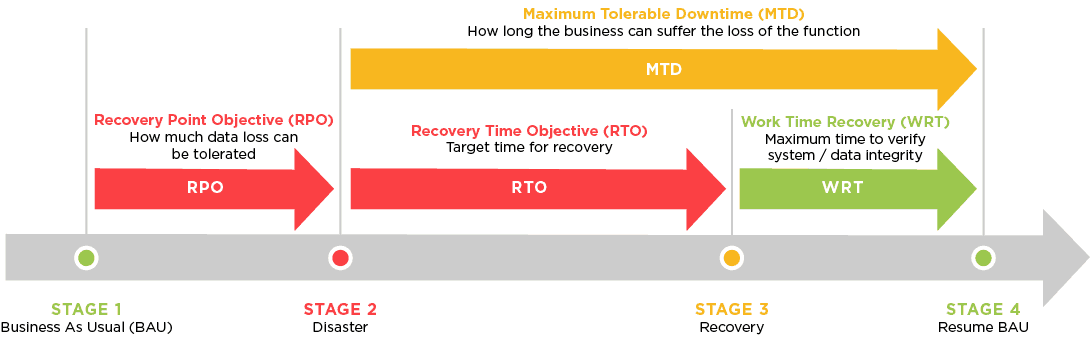
# 摘要
本文详细探讨了IT服务连续性管理,并对ISO20000-1:2018标准进行了深入解读。通过分析服务连续性管理的核心组成部分、关键概念和实施步骤,本文旨在为读者构建一个全面的管理体系。同时,文章强调了风险评估与管理
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )