STM32 SPI性能提升:揭秘吞吐率翻倍的秘密武器
发布时间: 2024-12-28 08:42:42 阅读量: 7 订阅数: 11 

基于springboot的酒店管理系统源码(java毕业设计完整源码+LW).zip
# 摘要
本论文深入探讨了基于STM32微控制器的SPI通信技术,从基础性能概述到实际应用场景中的性能提升策略进行了详细分析。首先,介绍了SPI通信的基础知识和硬件架构,并解析了其性能的关键影响因素。随后,探讨了在软件层面上,通过调整协议栈和操作系统集成来进一步优化SPI性能的方法。最后,通过案例研究展示了硬件升级方案和软件优化实例,并分析了提升SPI吞吐率的实践技巧。本研究为开发者提供了一套完整的SPI通信性能提升方案,对于提高工业控制、数据采集等领域的通信效率具有重要的参考价值。
# 关键字
SPI通信;性能优化;STM32;硬件架构;软件协议栈;实时操作系统(RTOS)
参考资源链接:[STM32 SPI总线通信详解:主从模式与协议分析](https://wenku.csdn.net/doc/70amsibqyw?spm=1055.2635.3001.10343)
# 1. SPI通信基础与性能概述
## 1.1 SPI通信基本概念
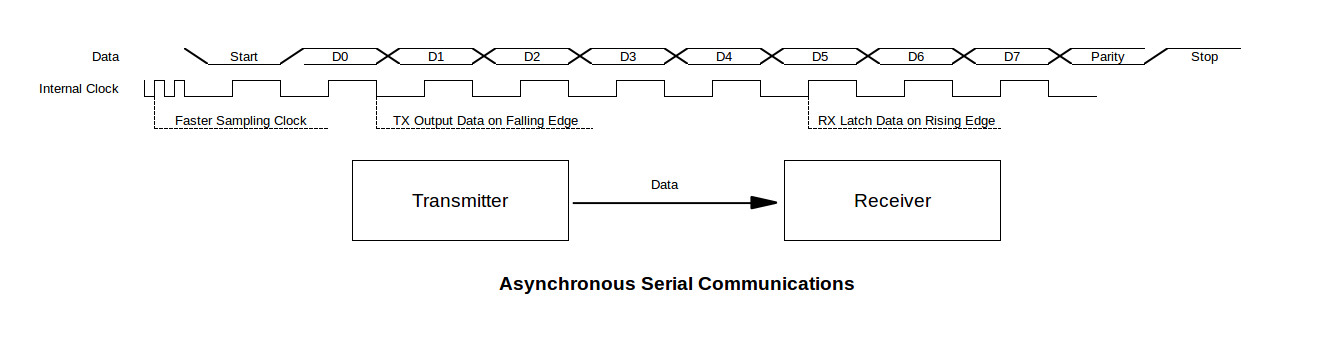
SPI(Serial Peripheral Interface)是一种常用的串行通信协议,广泛应用于微控制器和各种外围设备之间的通信。它支持全双工、同步数据传输,通常包含四个信号线:主设备的MISO(Master In Slave Out),MOSI(Master Out Slave In),SCK(Serial Clock)和SS(Slave Select)。SPI通信协议的一个显著特点是其灵活性高,可以支持单向或双向的数据传输,并且数据的位宽、传输速率和工作模式(模式0到模式3)可以根据具体需求进行调整。
## 1.2 SPI性能评估指标
SPI通信性能的评估往往通过多个指标来考量,主要包括吞吐率(Throughput)、延迟(Latency)、CPU占用率和功耗。吞吐率是指单位时间内传输的数据量,是评估性能的关键指标之一,直接关系到系统的数据传输效率。延迟是指从数据准备好发送到数据完全发送完成所需要的时间,它影响了系统的响应速度。CPU占用率和功耗则是衡量系统资源占用和能效的指标,尤其在嵌入式系统和移动设备中至关重要。
## 1.3 SPI性能优化的方向
SPI性能优化通常可以分为硬件优化和软件优化两个方向。硬件优化主要针对物理层,如选择合适的SPI芯片,优化PCB布线以减少信号干扰,或者通过增加外部电路来提升信号质量。软件优化则可能涉及到驱动程序的编写,通信协议栈的调整,甚至操作系统级别的调度策略等。通过优化,可以使得SPI通信更加高效、可靠,并适应特定应用场景下的性能需求。
# 2. 深入理解STM32 SPI硬件架构
## 2.1 STM32 SPI硬件特性解析
### 2.1.1 SPI主要寄存器和配置选项
STM32微控制器系列中的SPI模块是一种灵活的串行通信接口,支持全双工、同步、主从模式通信。它的主要寄存器包括但不限于:控制寄存器(CR1, CR2)、状态寄存器(SR)、数据寄存器(DR)以及通信参数配置寄存器(例如,Baud Rate Register, CRC Polynomial Register等)。
```c
// SPI主要寄存器配置示例
void SPI_Configuration(void) {
// 使能SPI时钟
RCC_APB2PeriphClockCmd(RCC_APB2Periph_SPI1, ENABLE);
// 设置SPI为主模式,8位数据传输,使能硬件NSS管理
SPI_InitTypeDef SPI_InitStructure;
SPI_InitStructure.SPI_Direction = SPI_Direction_2Lines_FullDuplex;
SPI_InitStructure.SPI_Mode = SPI_Mode_Master;
SPI_InitStructure.SPI_DataSize = SPI_DataSize_8b;
SPI_InitStructure.SPI_CPOL = SPI_CPOL_Low;
SPI_InitStructure.SPI_CPHA = SPI_CPHA_1Edge;
SPI_InitStructure.SPI_NSS = SPI_NSS_Soft;
SPI_InitStructure.SPI_BaudRatePrescaler = SPI_BaudRatePrescaler_8; // 预分频值
SPI_InitStructure.SPI_FirstBit = SPI_FirstBit_MSB;
SPI_InitStructure.SPI_CRCPolynomial = 7;
SPI_Init(SPI1, &SPI_InitStructure);
// 使能SPI
SPI_Cmd(SPI1, ENABLE);
}
```
通过配置上述寄存器,可以设置SPI的传输速率、时钟极性和相位,以及数据格式等参数。这些配置对通信的效率和可靠性至关重要。
### 2.1.2 DMA在SPI通信中的作用
直接内存访问(DMA)是一种允许外围设备直接读写系统内存的技术,而无需CPU介入。在SPI通信中,通过DMA可以实现数据的自动传输,从而减轻CPU的负担,实现高速数据传输。
```c
// DMA配置示例以进行SPI数据传输
void DMA_Configuration(void) {
// 使能DMA时钟
RCC_AHBPeriphClockCmd(RCC_AHBPeriph_DMA1, ENABLE);
// 配置DMA传输方向、传输大小、外设地址、内存地址等参数
DMA_InitTypeDef DMA_InitStructure;
DMA_DeInit(DMA1_Channel5); // 假设使用DMA1的通道5与SPI1关联
DMA_InitStructure.DMA_PeripheralBaseAddr = (uint32_t)&(SPI1->DR); // SPI数据寄存器地址
DMA_InitStructure.DMA_MemoryBaseAddr = (uint32_t)pBuffer; // 数据缓冲区地址
DMA_InitStructure.DMA_DIR = DMA_DIR_PeripheralDST; // 内存到外设
DMA_InitStructure.DMA_BufferSize = bufferSize; // 传输大小
DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable;
DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable;
DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_Byte;
DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_Byte;
DMA_InitStructure.DMA_Mode = DMA_Mode_Normal;
DMA_InitStructure.DMA_Priority = DMA_Priority_High;
DMA_InitStructure.DMA_M2M = DMA_M2M_Disable;
DMA_Init(DMA1_Channel5, &DMA_InitStructure);
// 使能DMA通道
DMA_Cmd(DMA1_Channel5, ENABLE);
}
```
在SPI与DMA结合使用时,可以达到更高的吞吐量和更低的CPU负载。这是因为在DMA模式下,数据传输可以自动进行,而不需要CPU周期性地进行检查和管理。
## 2.2 影响SPI性能的关键因素
### 2.2.1 时钟速率与时钟极性和相位设置
SPI通信的性能受时钟速率的影响很大,一般情况下,速率越高,通信越快。然而,时钟极性和相位的设置对于通信的正确性至关重要,必须与SPI从设备相匹配。
```mermaid
graph LR;
A[SPI初始化] -->|设置SPI参数| B[CR1寄存器配置];
B -->|时钟速率| C[BR];
C -->|时钟极性| D[CPOL];
D -->|时钟相位| E[CPHA];
E -->|选择主从模式| F[MODE];
```
### 2.2.2 数据缓冲和批量传输机制
在处理大量数据时,合理使用数据缓冲区可以提高数据传输的效率。STM32的SPI模块支持多种数据缓冲和批量传输机制,合理配置这些功能,可以避免数据在传输中的延迟。
```c
// 设置SPI的FIFO或缓冲机制
void SPI_BuffConfig(void) {
// 启用FIFO
SPI_I2S_FIFOModeConfig(SPI1, SPI_I2S_FIFOMode_Enable);
// 设置FIFO接收阈值
SPI_I2S_FIFOThresholdConfig(SPI1, SPI_I2S_FIFOTreshold_HalfFull);
// 清除FIFO接收溢出标志
SPI_I2S_FIFOClearFlag(SPI1, SPI_I2S_FIFOClearFlag_RXOVR);
}
```
### 2.2.3 中断与DMA传输效率对比
在实时性要求较高的应用场景中,中断通常比轮询方式更加高效。而在高吞吐量的应用中,DMA传输的效率显著优于中断方式,因为DMA几乎不占用CPU资源。
```c
// 中断方式配置SPI接收
void SPI_InterruptConfig(void) {
// 使能SPI的中断
SPI_I2S_ITConfig(SPI1, SPI_I2S_IT_RXNE, ENABLE);
// 注册中断处理函数
NVIC_EnableIRQ(SPI1_IRQn);
}
// DMA方式配置SPI接收
void SPI_DMAConfig(void) {
// 配置DMA传输方向、传输大小、外设地址、内存地址等参数
// 使能DMA通道
// 使能SPI的DMA请求
SPI_I2S_DMACmd(SPI1, SPI_I2S_DMAReq_Rx, ENABLE);
}
```
## 2.3 性能优化的理论基础
### 2.3.1 性能评估标准
在进行SPI通信性能优化之前,需要明确性能评估的标准。常用的性能指标包括传输速率、CPU占用率、响应时间、错误率等。
### 2.3.2 实时性能分析工具
性能分析工具可以实时监控系统性能,分析瓶颈所在,并提供改进方向。在STM32中,可以使用如ST-LINK Utility、STM32CubeIDE等工具进行性能分析。
```markdown
| 性能指标 | 描述 | 评价方法 |
| --- | --- | --- |
| 传输速率 | 每秒传输的数据量 | 使用示波器或性能分析工具测量 |
| CPU占用率 | CPU处理任务所消耗的比率 | 在调试模式下使用调试器进行采样 |
| 响应时间 | 从请求到响应的时间 | 通过时序图记录和分析 |
| 错误率 | 数据传输中的错误发生频率 | 通过校验和或CRC校验进行检测 |
```
通过这些工具和指标,开发者可以量化SPI通信的性能表现,并根据实际需求调整配置以达到最优状态。
# 3. 提升SPI吞吐率的实践技巧
## 3.1 高效数据传输策略
在数据密集型应用中,数据传输的效率直接影响整体性能。对于SPI通信来说,提高吞吐率意味着减少数据传输过程中的延迟和中断次数。以下是一些实践技巧,用于提升SPI的吞吐率。
### 3.1.1 使用DMA进行缓冲区管理
**直接内存访问(DMA)** 是一种在不使用CPU的情况下,直接读写内存的技术。在SPI通信中,通过DMA可以实现高效的数据缓冲区管理。
**实践步骤:**
1. 配置SPI为主设备,并确保其具有DMA请求能力。
2. 配置DMA控制器,选择合适的通道用于SPI的TX(发送)和RX(接收)操作。
3. 在代码中初始化DMA通道,设置源地址(数据存储缓冲区地址)、目标地址(SPI数据寄存器地址)以及传输的字节数。
4. 启动DMA传输,并在传输完成时配置相应的中断服务例程(ISR)以处理传输完成后的事件。
**代码示例:**
```c
// 伪代码展示DMA初始化过程
void DMA_Init() {
// 初始化SPI DMA传输通道
DMA_Cmd(DMA_Channel_SPI_TX, ENABLE); // 启用SPI发送通道
DMA_Cmd(DMA_Channel_SPI_RX, ENABLE); // 启用SPI接收通道
// 配置DMA传输参数
DMA_SetTransferMode(DMA_Channel_SPI_TX, DMA_Transfer_MemoryToPeripheral);
DMA_SetTransferMode(DMA_Channel_SPI_RX, DMA_Transfer_PeripheralToMemory);
// 设置传输方向和数据大小
DMA_SetPeripheralIncMode(DMA_Channel_SPI_TX, DMA_PeripheralInc_Disable);
DMA_SetPeripheralIncMode(DMA_Channel_SPI_RX, DMA_PeripheralInc_Disable);
// 配置源和目标地址,传输字节数等
// ...
}
void SPI_Config() {
// SPI初始化代码
// ...
}
int main() {
// 系统初始化
DMA_Init();
SPI_Config();
// 开始DMA传输
// ...
while(1) {
// 主循环代码
}
}
```
### 3.1.2 缓冲区大小与传输次数的优化
在使用DMA进行数据传输时,合理选择缓冲区大小和传输次数对于提升吞吐率至关重要。过大或过小的缓冲区都会影响性能。
**缓冲区大小:**
缓冲区的大小应该根据应用程序的需求和DMA传输单元(DMA burst size)来设定。一个较大的缓冲区可以减少DMA传输次数,但会增加每次中断处理的开销。选择一个合适的缓冲区大小,可以在减少中断次数和降低中断处理开销之间取得平衡。
**传输次数:**
传输次数的优化需要考虑总数据量和缓冲区大小。若数据总量远大于缓冲区大小,可能需要多次传输。然而,频繁的传输可能会引入额外的延迟。优化此策略通常需要对应用进行分析,以确定最优的缓冲区大小和传输次数组合。
## 3.2 精细配置SPI参数
除了硬件特性之外,通过精细配置SPI参数也可以实现性能提升。
### 3.2.1 调整时钟频率和时钟极性/相位
SPI时钟频率和时钟极性(CPOL)/时钟相位(CPHA)是影响通信速率和同步的关键因素。
- **时钟频率**:更高频率的时钟可以提供更快的数据传输速率。然而,时钟频率受限于物理特性和外设支持的最高速度。
- **时钟极性(CPOL)和时钟相位(CPHA)**:这两个参数定义了数据采样和数据准备的时序。根据SPI设备的规格,合理设置CPOL和CPHA,确保数据能正确同步。
### 3.2.2 字长对齐与数据格式优化
**字长对齐** 指的是数据在内存中的存储方式,这对于DMA传输效率有显著影响。通常,将数据字长对齐到DMA传输单元的大小可以提升性能。
**数据格式优化** 可以通过设置SPI的数据帧格式来实现。例如,选择16位数据帧格式而非8位数据帧,可以减少发送和接收相同数据量所需的传输次数,从而提升效率。
## 3.3 中断管理与错误处理
在中断驱动的SPI通信中,中断管理与错误处理机制对于保持吞吐率至关重要。
### 3.3.1 优化中断服务程序
中断服务程序(ISR)应该尽可能地简短和高效。对于与SPI传输相关的中断,只有当数据传输完成或出现错误时才需要执行特定的操作。
**实践建议:**
1. 在ISR中仅处理与传输完成相关的任务,并将其他复杂操作放到后台任务中。
2. 使用事件标志或信号量来通知主程序传输已经完成,使得主程序可以异步地处理这些事件。
### 3.3.2 错误检测与异常处理策略
SPI通信中可能会遇到多种错误,如帧错误、校验错误或超时错误。为这些错误设计有效的检测机制,并制定相应的处理策略,能够提高系统的稳定性和吞吐率。
**错误检测** 应该在ISR中或者通过定期轮询SPI状态寄存器来完成。对于检测到的错误,可以采取以下策略:
- **重试机制**:如果错误可能是暂时的(如短暂的通信干扰),可以尝试重传数据。
- **错误恢复**:如果错误持续发生,可能需要执行更复杂的恢复程序,例如重新初始化SPI硬件或重新连接外围设备。
- **日志记录**:记录错误信息可以帮助后续分析通信故障原因,优化系统设计。
通过这些策略,可以确保SPI通信在遇到错误时能够尽可能地维持高吞吐率,同时保证数据传输的正确性和可靠性。
# 4. 软件层面对SPI性能的优化
## 4.1 软件协议栈的调整
### 4.1.1 软件协议栈对性能的影响
软件协议栈是现代通信中不可或缺的一部分,它为应用程序提供了访问硬件的接口,并实现了各种网络通信协议。在SPI通信中,软件协议栈处理数据,控制通信流程,并管理错误处理等。然而,软件协议栈的开销可能会成为性能瓶颈,尤其是在对实时性和吞吐量要求极高的应用中。对于STM32这样的微控制器而言,优化软件协议栈意味着减少CPU周期的消耗,提高数据处理效率,并确保在多任务环境中保持响应性和稳定性。
### 4.1.2 协议栈优化方法和案例
协议栈优化通常包括以下几个方面:
- **代码精简**:去除不必要的协议功能模块,仅保留应用所需的最小协议集。
- **数据流优化**:实现更有效的数据缓冲和排队策略,减少内存拷贝次数。
- **中断管理**:优化中断处理逻辑,确保及时响应数据传输事件,同时最小化中断服务例程的执行时间。
- **多线程优化**:合理分配任务优先级,避免线程阻塞和资源竞争问题。
举一个优化案例,可以考虑以下优化步骤:
1. **分析现有的协议栈**:使用性能分析工具确定开销最大的函数。
2. **评估和去除多余功能**:检查是否有必要实现完整的协议栈,或者可以采用简化版本。
3. **实现数据流缓冲策略**:通过预分配固定大小的缓冲池来减少动态内存分配。
4. **优化中断服务例程**:调整中断优先级和合并中断服务例程中的相关任务。
5. **多线程调整**:使用实时操作系统(RTOS)提供的同步机制,例如信号量和互斥锁,来优化线程间通信。
下面是一个简单的代码示例,展示了如何在使用FreeRTOS操作系统的情况下优化中断服务例程:
```c
void SPI_IRQHandler(void) {
// 使用互斥量防止数据访问冲突
if (xSemaphoreTake(xSPI_Mutex, portMAX_DELAY) == pdTRUE) {
// 中断服务逻辑
// ...
// 释放互斥量,允许其他任务访问数据
xSemaphoreGive(xSPI_Mutex);
}
}
```
在这个示例中,使用互斥量来确保在中断服务例程中的数据处理是线程安全的,从而避免潜在的竞态条件。这种做法提高了通信的可靠性,但同时,过多的同步机制也可能会增加响应时间。
## 4.2 操作系统的集成优化
### 4.2.1 实时操作系统(RTOS)的选择和配置
在需要高度实时性的系统中,实时操作系统(RTOS)提供了一种有效的管理多任务和资源的方式。选择合适的RTOS,并对其进行正确的配置,是提升系统性能的关键步骤。在SPI通信中,RTOS能够确保关键任务获得足够的处理时间,并且可以按照优先级调度任务执行,从而优化整体性能。
选择RTOS时,需要考虑如下因素:
- **调度策略**:优先级或时间片轮转调度。
- **内存使用**:对嵌入式系统来说,RTOS的内存占用是非常重要的。
- **内核功能**:是否支持所需的功能,如互斥量、信号量、消息队列等。
- **开发工具和社区支持**:成熟的开发工具链和活跃的社区可以加速开发进程。
一旦选定了RTOS,下一步就是进行配置,具体包括设置任务优先级、堆栈大小、调度策略等。合理配置可以最小化任务切换的开销,确保高优先级任务能够及时得到执行。
### 4.2.2 多任务环境下SPI通信的调度策略
在多任务环境下,为了有效地管理SPI通信,需要制定合适的调度策略。这包括:
- **任务优先级分配**:核心通信任务应该具有高优先级,以确保它们能够在需要时获得处理时间。
- **任务同步**:使用信号量或互斥量来同步对共享资源(如SPI总线)的访问,以防止资源冲突。
- **中断优先级配置**:确保SPI中断优先级高于或等同于其他普通任务优先级,但不能过高以免影响系统的整体稳定性。
- **中断驱动与轮询驱动的平衡**:在对实时性要求极高的场景中使用中断驱动方式,而在对功耗有特别要求的场景中考虑轮询驱动方式。
下面是一个简化的示例,展示了如何在RTOS环境下使用信号量来同步SPI通信任务:
```c
void SPI_SendTask(void* pvParameters) {
while(1) {
// 等待信号量
if(xSemaphoreTake(xSPI_Semaphore, portMAX_DELAY) == pdTRUE) {
// 执行SPI发送操作
// ...
// 释放信号量,允许其他任务请求SPI
xSemaphoreGive(xSPI_Semaphore);
}
}
}
```
## 4.3 高级数据处理技术
### 4.3.1 数据压缩与预处理
在许多应用场景中,为了提高SPI的吞吐量,对数据进行压缩或预处理是一种有效的方法。数据压缩可以减少需要传输的数据量,而预处理可以提高数据的处理效率。
- **数据压缩技术**:选择合适的数据压缩算法能够显著减少数据传输时间,但也会增加处理器的负担。应选择与应用场景相匹配的压缩算法。
- **预处理技术**:如数据分块处理和缓冲,减少每次处理的数据量,提高单次处理效率。
### 4.3.2 后台数据处理机制的设计与实现
在许多高性能应用中,数据处理任务可以在后台运行,这样可以减轻主任务的负担,提高系统的整体响应性。设计后台数据处理机制时,应考虑以下方面:
- **任务的独立性**:后台任务应尽量独立,避免与主任务产生过多依赖。
- **资源管理**:后台任务不应该占用过多资源,尤其是在内存和处理器时间上。
- **通信机制**:后台任务和主任务之间需要有效的通信机制,例如使用队列来传递数据。
下面是一个后台数据处理任务的示例:
```c
void BackgroundDataProcessingTask(void* pvParameters) {
while(1) {
// 等待任务队列中的数据
if(xQueueReceive(xDataProcessingQueue, &data, portMAX_DELAY) == pdTRUE) {
// 对数据进行处理
// ...
}
}
}
```
通过采用以上所述的技术和策略,可以有效提升软件层面对SPI性能的优化,为实现高效、可靠的通信提供支持。
# 5. 案例研究:STM32 SPI性能提升实战
在前面的章节中,我们已经深入探讨了STM32 SPI通信的基础知识、硬件架构特性、性能优化的理论基础和软件层面的优化策略。为了将这些理论知识和优化技巧应用到实际项目中,本章将通过案例研究的形式,详细分析在典型应用场景中STM32 SPI性能提升的实战操作和硬件升级方案,以及软件优化与调优的实例。
## 5.1 典型应用场景分析
在不同的应用场景中,STM32的SPI性能需求和优化手段可能存在差异。我们将重点分析工业控制和高速数据采集这两个典型应用场景。
### 5.1.1 工业控制中的SPI应用
在工业控制系统中,数据通常需要在多个传感器、执行器和控制器之间实时传输。这就要求SPI通信具有极高的稳定性和实时性。例如,一个典型的温度控制系统可能需要通过SPI接口读取温度传感器数据,并将控制信号发送至风扇执行器。
在这样的应用场景中,性能提升的关键在于提高SPI通信的稳定性和实时性,降低通信延迟。具体操作包括:
- 精确配置SPI的时钟速率,确保系统其他部分不会因SPI通信而产生瓶颈。
- 采用DMA传输,减少CPU负担,提高数据传输效率。
- 对SPI通信过程进行详细的实时性能分析,确定是否存在性能瓶颈并进行相应优化。
### 5.1.2 高速数据采集系统的SPI配置
高速数据采集系统要求SPI接口能够以极快的速度接收来自模拟-数字转换器(ADC)的数据。一个典型的高速数据采集系统可能需要每秒数百万次的采样率。
为了满足这类应用的需求,性能提升的措施包括:
- 使用高速SPI外围设备,比如具有高速数据吞吐率的ADC。
- 优化SPI时钟设置,以确保与ADC采样率的同步。
- 采用高级数据处理技术,比如数据压缩,减轻后续数据处理模块的压力。
## 5.2 硬件升级方案探讨
硬件的性能直接影响通信效率,适当的硬件升级可以在不改变软件架构的前提下显著提升性能。
### 5.2.1 SPI接口硬件升级案例
硬件升级的案例包括:
- 将SPI接口从标准模式升级为高速模式,通过选择支持更高频率的SPI芯片来实现。
- 在硬件层面增加过滤电路,减少信号干扰,提升通信稳定性。
### 5.2.2 高速SPI外围设备的选型建议
在选择高速外围设备时,建议考虑:
- 设备的最大时钟速率和数据吞吐率是否满足系统需求。
- 设备的兼容性和对STM32系列的驱动支持。
- 设备的功耗和封装尺寸,特别是对于空间受限的嵌入式系统。
## 5.3 软件优化与调优实例
软件优化与调优不仅可以提升系统的性能,还可以在一定程度上缓解硬件的不足。
### 5.3.1 优化前后性能对比
优化前的系统可能因为CPU占用率高、通信延迟大等问题,导致数据传输效率低下。优化措施可能包括:
- 重写SPI通信协议栈,减少不必要的开销。
- 使用任务优先级和中断管理策略,确保关键任务能够获得及时处理。
通过这些优化措施,可以显著提升系统的吞吐率和实时性。
### 5.3.2 调优过程中遇到的问题与解决方案
在软件调优过程中,可能会遇到如下问题:
- 中断服务程序(ISR)执行时间过长,影响系统的响应速度。
- 数据缓冲区管理不当,导致缓冲区溢出或数据丢失。
针对这些问题,解决方案包括:
- 优化ISR代码,缩短其执行时间。
- 设计智能的缓冲区管理策略,比如动态调整缓冲区大小。
通过具体的案例分析和优化实例,我们能够看到在实际应用中如何将理论知识与实践相结合,从而有效提升STM32 SPI通信的性能。这些实践经验对于解决实际开发中的问题具有指导意义,并可为其他类似项目提供参考。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
STM32-SPI总线通信协议专栏深入探讨了STM32微控制器与SPI设备之间的通信。它提供了一系列全面指南,涵盖从入门到高级技巧的各个方面。专栏深入研究了SPI通信的初始化、数据传输、性能优化、中断和DMA的使用、故障排除、实际应用、多主通信、安全措施、物联网优化、编程技术、调试技巧、时钟管理、片选信号管理、故障预防、高速应用、协议解析、电源管理以及信号干扰与抗干扰。通过深入浅出的讲解和丰富的案例分析,本专栏旨在帮助读者掌握STM32-SPI通信的方方面面,提升他们的嵌入式系统开发能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【动态时间线掌握】:FullCalendar官网API,交互式时间管理新境界
# 摘要
本文详细介绍了FullCalendar官网API的概述、基本使用与配置、高级主题定制、事件源与动态数据处理、国际化与本地化实践以及项目案例与最佳实践。通过对初始化方法、事件与资源管理、交互功能等方面的深入探讨,提供了一系列实用的配置选项和自定义技巧。文章进一步分析了如何通过REST API集成和CRUD操作实现动态数据处理,展示了事件动态渲染、冲突检测和解决的策略。同时,探讨了FullCalendar的多语言支
汇川机器人编程手册:故障诊断与维护 - 快速修复问题的专家指南
# 摘要
汇川机器人作为自动化技术领域的关键设备,其编程、故障诊断、维护以及性能优化对于保证生产效率和安全性至关重要。本文首先概述了汇川机器人编程的基础知识及故障诊断的必要性,随后深入探讨了软件和硬件故障诊断的理论与技巧,包括日志分析、故障模拟、问题定位、代码修复等方法。接着,文章着重介绍了系统集成与性能优化的策略,以及如何通过监测和分析来识别性能瓶颈。最后,本文提出了故障诊断与维护的最佳实践,包括案例库建设、标准化操作流程的制定以及预见性维护的策略,旨在通过共享知识和技术进步来提高故障响应速度与维护效率。本研究对机器人技术维护人员具有重要的参考价值,有助于提升机器人的整体运维管理水平。
#
【TDC-GP22问题诊断全攻略】:揭秘手册未涉及的问题解决之道
# 摘要
本文全面介绍了TDC-GP22问题诊断的基础理论与实践技巧,重点探讨了其工作原理、故障诊断的理论基础以及高级诊断技术的应用。通过对TDC-GP22硬件架构和软件逻辑流程的分析,结合故障分析方法论和常见故障模式的研究,本文为故障诊断提供了理论支持。实践技巧章节强调了实时监控、日志分析、故障模拟及排除步骤、维修与维护策略等关键操作的重要性。此外,本文还涉及了自定义诊断脚本编写、故障案例分析以及远程诊断与技术支持的高级应用,最终展望了TDC-GP22诊断技术的未来发展趋势和持续改进的重要性,特别指出了教育与培训在提高操作人员技能和制定标准操作流程(SOP)方面的作用。
# 关键字
TDC
STM32内存优化:HAL库内存管理与性能提升策略
# 摘要
随着嵌入式系统技术的发展,STM32作为高性能微控制器在许多应用领域中得到了广泛应用。本文首先介绍了STM32内存管理的基础知识,然后深入探讨了HAL库中的内存分配与释放机制,包括动态内存分配策略和内存泄漏的检测与预防。接着,文中分析了内存性能分析工具的使用方法以及内存使用优化案例。在第四章中,讨论了内存优化技术在STM32项目中的实际应用,以及在多任务环境下的内存管理策略。最后一
【UML组件图】:模块化构建专家,医院管理系统升级必备

# 摘要
本文系统地介绍了UML组件图的理论基础及其在医院管理系统的应用实践。首先概述了组件图的定义、目的和组成元素,强调了其在软件工程中的作用和与类图的区别。接着,深入分析了医院管理系统的模块化需求,详细探讨了组件图的设计、实现以及优化与重构。案例研究部分
【ANSA算法实战】:5大策略与技巧提升网络性能及案例分析

# 摘要
ANSA算法是一种先进的网络性能调节算法,其工作原理包括流量预测模型和速率调整机制。本文详细介绍了ANSA算法的理论基础,包括其关键参数对网络性能的影响以及优化方法,并与传统算法进行了比较分析。文章进一步探讨了ANSA算法的实战技巧,涵盖了配置、部署、性能监控与调优,以及故障诊断处理。为提升性能,本文提出了路由优化、流量调度和缓存机制优化策略,并通过案例研究验
打造冠军团队:电赛团队协作与项目管理指南(专家经验分享)

# 摘要
电子设计竞赛(电赛)是检验电子工程领域学生团队协作和项目管理能力的重要平台。本文重点讨论了电赛团队协作与项目管理的重要性,分析了团队的组织架构设计原则和角色分配,以及项目的规划、执行、控制和总结各个阶段的有效管理流程。同时,探讨了沟通与协作技巧,创新思维在解决方案设计中的应用,并通过对成功和失败案例的分析,总结了实战经验与教训。本文旨在为电赛参与者提供系统化的团队协
FBX与OpenGL完美融合:集成到渲染流程的实战技巧

# 摘要
FBX与OpenGL是3D图形开发中广泛使用的文件格式和渲染API。本文首先概述了FBX与OpenGL的基础知识,随后深入探讨了FBX数据结构及其在OpenGL中的应用,包括FBX数据的解析、动画和材质的处理等。接着,文章着重介绍了在OpenGL中实现高效FBX渲染的多种策略,如渲染性能优化和动画平滑处理等。最后,本文通过实战案例分析,展示了如何构建
增强学习精要:打造自主决策智能体,3大策略与方法
# 摘要
增强学习作为一种机器学习方法,在智能控制、机器人技术、游戏和推荐系统等多个领域具有广泛应用。本文首先介绍了增强学习的概念与基础,然后深入探讨了策略设计的重要性,包括奖励函数的优化、探索与利用的平衡以及策略评估与改进的方法。此外,本文还详细阐述了几种主要的增强学习算法,如Q学习、策略梯度和深度增强学习框架,并对它们的应用实例进行了具体分析。最后,文章还涉及了增强学习的高级主题,包括模型预测控制、多智能体系统的设计以及在不确定性
【BPMN魔法】:在MagicDraw中实现业务流程建模

# 摘要
业务流程模型和符号(BPMN)是一种广泛使用的标准化建模语言,用于描述、分析、设计、优化和文档化企业中的业务流程。本文首先概述了BPMN的历史和崛起,以及其在企业中的基础理论与元素。接着深入讨论了在MagicDraw软件中如何实践操作BPMN,包括界面操作、业务流程图的创建、定制与优化。进一步探讨了进阶的BPMN建模技巧,包括子流程、泳道、异常处理、以及模型的验证与仿真。通过案例分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )