【C++多线程编程速成课】:7天掌握std::thread,开启并行编程大门
发布时间: 2024-10-20 10:04:09 阅读量: 20 订阅数: 27 

# 1. C++多线程编程基础
## 简介
多线程编程是现代软件开发中不可或缺的一部分,特别是对于需要并发处理和高响应性的应用程序。C++提供了强大的多线程支持,特别是在C++11标准中引入的一系列库,使多线程编程变得更加容易和高效。本章将介绍C++多线程编程的基础知识,为读者后续深入理解和应用打下坚实基础。
## 基本概念
在C++中,线程代表了一个单独的执行路径。多线程程序可以同时执行多个线程,以提高程序的性能和响应速度。理解线程的基本概念是掌握多线程编程的第一步。这些概念包括线程的创建、同步、互斥、以及如何在C++中管理和使用线程。
## 开始编程
为了在C++中使用多线程,我们需要包含 `<thread>` 头文件。以下是一个简单的例子,展示了如何创建和启动一个线程:
```cpp
#include <iostream>
#include <thread>
void printHello() {
std::cout << "Hello from the thread!" << std::endl;
}
int main() {
std::thread t(printHello); // 创建并启动线程
t.join(); // 等待线程结束
return 0;
}
```
在此代码中,我们定义了一个 `printHello` 函数,它将在新线程中执行。在 `main` 函数中,我们创建了一个 `std::thread` 对象 `t` 并调用了 `printHello` 函数。`t.join()` 语句确保主线程等待新线程完成它的任务后再继续执行。这是多线程编程中最基本的操作之一,它奠定了更复杂多线程应用的基础。
# 2. std::thread的使用和管理
C++11 引入了 `<thread>` 库,提供了对多线程的直接支持,这使得在C++中进行多线程编程变得更为简单和方便。`std::thread` 类是这一系列操作的核心,它负责线程的创建、启动、同步以及结束。本章节将详细介绍 `std::thread` 的使用方法,探讨线程同步与互斥的机制,并且介绍线程的高级特性,包括线程局部存储和线程的分离与取消。
## 2.1 创建和启动线程
### 2.1.1 std::thread的基本用法
`std::thread` 类为创建和管理线程提供了一个简洁的接口。基本的用法包括创建一个线程实例,将其与一个要执行的函数关联起来,并启动它。
```cpp
#include <thread>
void thread_function() {
// 这里是线程要执行的代码
}
int main() {
// 创建一个线程对象
std::thread t(thread_function);
// 线程会在这里开始执行
t.join(); // 等待线程执行完成
return 0;
}
```
在这个例子中,`t` 是一个 `std::thread` 对象,它在创建的时候关联了一个函数 `thread_function`。调用 `t.join()` 就是告诉主函数等待这个线程执行结束。
### 2.1.2 线程的构造和启动
创建和启动线程时,除了直接关联一个函数外,还可以传递参数给线程函数,并且创建多个线程。
```cpp
void thread_function(int arg) {
// 使用参数arg执行操作
}
int main() {
int num = 42;
std::thread t1(thread_function, num); // 向线程函数传递参数
// 创建并启动第二个线程
std::thread t2(thread_function, num);
t1.join();
t2.join();
return 0;
}
```
在上面的例子中,两个线程 `t1` 和 `t2` 都被创建了,并且它们都会调用 `thread_function` 函数,并传递 `num` 作为参数。
## 2.2 线程的同步与互斥
### 2.2.1 互斥锁std::mutex
在多线程环境中,多个线程可能会访问和修改共享资源,这可能会导致数据竞争和不一致的问题。`std::mutex` 类提供了一种机制来防止多个线程同时访问共享资源。
```cpp
#include <mutex>
std::mutex mtx;
void shared_resource_function() {
mtx.lock(); // 尝试锁定互斥锁
// 临界区开始,执行需要同步的代码
// ...
mtx.unlock(); // 解锁
}
int main() {
std::thread t(shared_resource_function);
t.join();
return 0;
}
```
在这个例子中,`shared_resource_function` 函数使用了 `std::mutex` 保护一个临界区。当一个线程进入临界区时,它会锁定互斥锁;当退出临界区时,它会解锁。
### 2.2.2 条件变量std::condition_variable
条件变量允许线程阻塞等待某个条件成立。一个线程可以调用 `wait` 方法等待,直到另一个线程通知这个条件变量。
```cpp
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cv;
bool ready = false;
void print_id(int id) {
std::unique_lock<std::mutex> lk(mtx);
while (!ready) {
cv.wait(lk); // 等待条件变量通知
}
std::cout << "Thread " << id << '\n';
}
void go() {
std::unique_lock<std::mutex> lk(mtx);
ready = true;
cv.notify_all(); // 通知所有等待的线程
}
int main() {
std::thread threads[10];
for (int i = 0; i < 10; ++i)
threads[i] = std::thread(print_id, i);
std::cout << "10 threads ready to race...\n";
go(); // 启动线程
for (auto& th : threads) th.join();
return 0;
}
```
在本例中,`go` 函数修改 `ready` 标志,并通知所有等待的线程,`print_id` 函数则等待 `ready` 为真后才继续执行。
## 2.3 线程的高级特性
### 2.3.1 线程局部存储(TLS)
线程局部存储(Thread Local Storage, TLS)允许定义一个全局变量,但每个线程都有它自己的实例。
```cpp
#include <thread>
#include <iostream>
__thread int t_id; // TLS变量
void print_id() {
std::cout << "Thread ID: " << t_id << '\n';
}
void thread_function() {
t_id = 1;
print_id();
}
int main() {
std::thread t1(thread_function);
t_id = 2;
print_id();
t1.join();
return 0;
}
```
在上面的代码中,`t_id` 是一个 TLS 变量,每个线程中 `t_id` 的值是独立的。在 `main` 函数和 `thread_function` 中对 `t_id` 的赋值操作,不会互相影响。
### 2.3.2 线程的分离和取消
线程的分离(detach)意味着线程的结束不需要其他线程来处理。而取消线程意味着终止线程的执行。
```cpp
#include <thread>
void thread_function() {
// 模拟长时间运行的线程任务
}
int main() {
std::thread t(thread_function);
// 如果不需要同步等待线程结束,则可以分离线程
// t.detach();
// 如果确定需要取消线程,需要更复杂的设计来确保安全地中断线程执行
// 这通常不是推荐的做法,因为它可能导致资源泄漏
return 0;
}
```
在上面的例子中,如果不再需要等待线程 `t` 结束,可以调用 `t.detach()` 将其分离。而线程的取消通常需要额外的设计,因为C++标准库中并没有提供直接取消线程的机制。
[接下来的章节将会探讨 C++11 中的其他多线程组件,包括原子操作和原子类型、线程池的实现与应用,以及并发算法与并行算法。]
# 3. C++11中的其他多线程组件
随着C++11标准的引入,C++的多线程编程能力得到了极大的加强。在这一章中,我们将深入探讨C++11新增的一些多线程组件,包括原子操作、原子类型、线程池的实现与应用以及并发算法与并行算法。这些组件为开发者提供了更多工具来设计和实现高效、安全的多线程应用程序。
## 3.1 原子操作和原子类型
### 3.1.1 std::atomic的使用
在多线程环境中,原子操作是一种无需其他线程干预的操作,保证了执行的原子性,即在执行过程中不会被线程调度机制打断。C++11提供了`std::atomic`模板类来支持原子操作,它是一个通用的工具,可以用来封装各种类型的数据,确保在多线程环境中对这些数据的读写是安全的。
```cpp
#include <atomic>
#include <thread>
std::atomic<int> atomicCounter(0);
void incrementCounter() {
for (int i = 0; i < 1000; ++i) {
atomicCounter.fetch_add(1, std::memory_order_relaxed);
}
}
int main() {
std::thread t1(incrementCounter);
std::thread t2(incrementCounter);
t1.join();
t2.join();
std::cout << "Counter value is: " << atomicCounter << std::endl;
return 0;
}
```
在上面的示例中,我们定义了一个`std::atomic<int>`类型的变量`atomicCounter`,并在两个线程中对其进行增加操作。由于使用了`std::atomic`,我们无需额外的同步机制,就可以保证计数器的准确性。
### 3.1.2 内存顺序和原子操作
C++11不仅定义了原子类型,还提供了多种内存顺序选项,这些选项用于控制原子操作的执行顺序。`std::memory_order`枚举定义了这些选项,包括`memory_order_relaxed`、`memory_order_consume`、`memory_order_acquire`、`memory_order_release`、`memory_order_acq_rel`和`memory_order_seq_cst`等。开发者可以根据具体场景选择合适的内存顺序,以优化程序性能。
```cpp
std::atomic<int> flag(0);
std::atomic<int> data(0);
void write() {
data.store(42, std::memory_order_release);
flag.store(1, std::memory_order_release);
}
void read() {
while (flag.load(std::memory_order_acquire) == 0);
std::cout << data.load(std::memory_order_acquire) << std::endl;
}
int main() {
std::thread producer(write);
std::thread consumer(read);
producer.join();
consumer.join();
return 0;
}
```
在这个例子中,`write`函数首先存储一个值到`data`变量,然后设置`flag`为1。`read`函数将等待`flag`变为1,然后读取`data`的值。这里使用了`memory_order_release`和`memory_order_acquire`内存顺序,以确保在`data`写入之前,相关的内存操作都已完成。
## 3.2 线程池的实现与应用
### 3.2.1 std::thread的线程池模式
线程池是一种管理线程执行资源的技术,它预先创建一定数量的线程,并将这些线程放入一个池中,之后将任务提交给线程池来执行。这样可以避免频繁创建和销毁线程的开销,并且可以更有效地管理线程资源。
```cpp
#include <thread>
#include <vector>
#include <queue>
#include <condition_variable>
#include <mutex>
class ThreadPool {
public:
ThreadPool(size_t);
template<class F, class... Args>
auto enqueue(F&& f, Args&&... args)
-> std::future<typename std::result_of<F(Args...)>::type>;
~ThreadPool();
private:
// 需要实现的组件,如任务队列、线程执行函数等
};
int main() {
ThreadPool pool(4);
std::future<int> result = pool.enqueue([](int answer) { return answer; }, 42);
std::cout << result.get() << std::endl;
return 0;
}
```
上述代码展示了一个简化版的`ThreadPool`类的框架,其中包含了启动和管理线程池的基本结构。通过`enqueue`方法,我们可以将任务添加到线程池中去异步执行。
### 3.2.2 实际案例:并发任务处理
线程池在实际编程中非常有用,尤其是在需要并发执行多个任务时。考虑以下场景:我们有一个应用需要处理多个独立的计算任务,这些任务之间相互独立,没有依赖关系。使用线程池可以有效地并行执行这些任务,提高应用程序的性能。
```cpp
#include <thread>
#include <vector>
#include <numeric>
#include <iostream>
void task(int n) {
std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟计算任务耗时
std::cout << "Processing task " << n << std::endl;
}
int main() {
ThreadPool pool(4);
std::vector<std::future<void>> results;
for (int i = 0; i < 10; ++i) {
results.emplace_back(pool.enqueue(task, i));
}
for (auto&& result : results) {
result.get();
}
return 0;
}
```
在这个案例中,我们创建了一个有4个工作线程的线程池,然后提交了10个任务到这个线程池。这些任务将并发执行,而主线程将等待所有任务完成。
## 3.3 并发算法与并行算法
### 3.3.1 std::async的并行任务启动
`std::async`是C++11提供的一个用于启动并行任务的工具,它是非同步执行的。使用`std::async`可以非常方便地将函数调用发送到后台线程执行,并获取一个`std::future`对象,该对象能够用来获取函数执行的结果。
```cpp
#include <future>
#include <iostream>
#include <chrono>
int compute(int sleep_time) {
std::this_thread::sleep_for(std::chrono::seconds(sleep_time));
return sleep_time * sleep_time;
}
int main() {
auto result1 = std::async(std::launch::async, compute, 2);
auto result2 = std::async(std::launch::async, compute, 3);
std::cout << "Result1: " << result1.get() << std::endl;
std::cout << "Result2: " << result2.get() << std::endl;
return 0;
}
```
在这个例子中,我们同时启动了两个异步任务,分别计算两个不同参数的平方值。`std::async`会根据处理器的数量和负载情况,合理地调度这两个任务到不同的线程中执行。
### 3.3.2 实际案例:并行排序和搜索
`std::async`的应用不仅限于简单的函数调用,还可以用于并行执行更复杂的任务,例如并行排序和搜索。这在处理大数据集时尤其有用,可以显著减少算法的时间复杂度。
```cpp
#include <future>
#include <vector>
#include <algorithm>
std::vector<int> asyncSort(std::vector<int> data) {
std::sort(data.begin(), data.end());
return data;
}
int main() {
std::vector<int> data = {4, 2, 8, 6, 1, 7, 3, 5};
auto asyncResult = std::async(std::launch::async, asyncSort, std::move(data));
// 执行其他任务
std::vector<int> sortedData = asyncResult.get();
for (int i : sortedData) {
std::cout << i << " ";
}
return 0;
}
```
在这个例子中,我们创建了一个异步任务来对一个整数向量进行排序。由于`std::sort`是一个可以在多线程环境中使用的算法,`std::async`可以有效地将这个任务分配到不同的核心上,并行执行。
在实际应用中,可以将数据集分割成多个部分,然后并行地对每个部分进行排序,最后再将结果合并。这样的并行处理技术可以大幅提升排序算法的执行效率。
在本章节中,我们介绍了原子操作、线程池以及并发算法等C++11中增加的多线程组件。通过理解这些组件的用法与应用场景,可以更加深入地掌握多线程编程的技术和提高程序性能的策略。在下一章节,我们将进入实践案例与性能调优,通过实际的编程案例来进一步探讨多线程编程的高级应用和性能优化技巧。
# 4. 实践案例与性能调优
在前三章中,我们了解了C++多线程编程的基本概念、C++11中引入的线程组件以及如何使用这些组件进行基本的多线程编程。到了这一章节,我们将深入探讨多线程编程在实际问题中的应用,同时涉及调试和测试多线程程序的策略,并分享性能优化的技巧。
## 4.1 多线程编程在实际问题中的应用
多线程编程的应用广泛,尤其在需要高性能计算和快速响应的服务上。我们将通过两个具体案例:网络服务的多线程处理和并行计算在科学仿真中的应用,来探讨多线程编程的实际运用。
### 4.1.1 网络服务的多线程处理
在网络服务中,尤其是服务器端编程,处理大量的并发连接是性能瓶颈的常见来源。通过多线程技术,可以有效地提升服务器的并发处理能力。以一个简单的HTTP服务器为例:
```cpp
#include <thread>
#include <iostream>
#include <vector>
#include <mutex>
#include <functional>
std::mutex m;
void handle_client(std::string client_data) {
std::lock_guard<std::mutex> lock(m);
std::cout << "Handling client with data: " << client_data << std::endl;
// 模拟处理请求,例如解析HTTP请求、读写数据等。
// ...
}
int main() {
std::vector<std::thread> threads;
for (int i = 0; i < 100; ++i) {
// 模拟接收到的客户端数据。
std::string client_data = "Client Data " + std::to_string(i);
threads.emplace_back(std::thread(handle_client, client_data));
}
for (auto& t : threads) {
if (t.joinable()) {
t.join();
}
}
return 0;
}
```
这段代码演示了一个简单的多线程HTTP服务器处理多个客户端请求的情况。我们使用`std::thread`创建线程来模拟处理每个客户端。注意`std::lock_guard`用于保护可能被多个线程同时访问的共享资源(在这里是标准输出)。
接下来,我们将了解在并行计算和科学仿真中如何利用多线程。
### 4.1.2 并行计算与科学仿真
在并行计算领域,多线程编程是实现高性能模拟和数据处理的核心技术。在科学仿真中,大量的数据运算和模型迭代可以并行化,从而缩短计算时间。
例如,在物理模拟中,根据不同的模型计算和渲染,可以分配到不同的线程中并行执行:
```cpp
#include <thread>
#include <vector>
#include <atomic>
std::atomic<int> model_index = 0;
void process_model(int id) {
// 模拟处理模型的函数
while (model_index < 100) {
// 确保安全读取共享数据
int current_index = model_index.fetch_add(1);
if (current_index < 100) {
// 模型处理逻辑
// ...
} else {
break;
}
}
}
int main() {
std::vector<std::thread> threads;
for (int i = 0; i < 4; ++i) {
threads.emplace_back(std::thread(process_model, i));
}
for (auto& t : threads) {
if (t.joinable()) {
t.join();
}
}
return 0;
}
```
在这个例子中,我们使用`std::atomic`来保证对共享变量`model_index`的线程安全访问,并将模型处理分配给多个线程。这是一个简化的并行数据处理模式。
## 4.2 多线程程序的调试和测试
调试和测试是确保多线程程序正确性和性能的关键步骤。本节将探讨一些工具和方法,并讨论测试策略。
### 4.2.1 调试工具和方法
多线程程序的调试是复杂而困难的,因为它涉及到并发的不确定性和线程竞争条件。一些常用的调试工具包括:
- **GDB**: GNU Debugger 支持多线程调试。
- **Valgrind**: 可以检测线程间的竞争条件,例如使用Helgrind工具。
- **Visual Studio**: 提供强大的多线程调试功能。
使用这些工具时,关注死锁、数据竞争和内存泄漏是常见的调试方法。例如,使用GDB调试多线程程序时:
```sh
gdb ./my_multithreaded_program
(gdb) set print thread-events on
(gdb) break main
(gdb) run
(gdb) thread apply all bt
```
上面的GDB命令帮助我们查看所有线程的回溯信息,便于识别问题所在。
### 4.2.2 测试多线程代码的策略
多线程代码测试策略包括:
- **单线程测试**: 首先保证单线程逻辑正确。
- **线程安全测试**: 检查共享资源的访问是否正确同步。
- **压力测试**: 模拟高负载条件,测试程序的响应能力和资源使用情况。
- **性能测试**: 通过测试找出性能瓶颈,并进行优化。
下表展示了单线程与多线程环境下不同测试策略的特点:
| 测试类型 | 单线程环境 | 多线程环境 |
| --- | --- | --- |
| **单元测试** | 独立测试每个函数 | 需要考虑线程间交互 |
| **集成测试** | 测试模块间的接口 | 测试线程协作和同步 |
| **系统测试** | 测试整个系统的功能 | 测试整体性能和并发能力 |
## 4.3 性能优化技巧
性能优化是多线程编程中的一个重要话题。本节将介绍如何识别性能瓶颈和应用并发设计模式。
### 4.3.1 识别瓶颈
性能瓶颈可能是由于线程竞争、资源争用、负载不均衡或者锁的滥用导致的。我们可以使用性能分析工具,如`perf`或`Intel VTune`,来识别这些问题。下面是一个简单的识别线程瓶颈的例子:
```cpp
#include <iostream>
#include <thread>
#include <chrono>
void critical_section() {
// 模拟需要时间的临界区操作
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
int main() {
std::chrono::steady_clock::time_point start = std::chrono::steady_clock::now();
std::thread t1(critical_section);
std::thread t2(critical_section);
t1.join();
t2.join();
std::chrono::steady_clock::time_point end = std::chrono::steady_clock::now();
std::chrono::duration<double, std::milli> elapsed = end - start;
std::cout << "Total time taken by two threads: " << elapsed.count() << "ms" << std::endl;
return 0;
}
```
通过计时,我们可以分析这段代码执行的时间,以识别是否存在临界区造成的性能瓶颈。
### 4.3.2 并发模式与设计
在多线程编程中,选择正确的并发模式和设计至关重要。常见的模式包括:
- **生产者-消费者模式**: 线程安全地进行生产与消费。
- **读写锁模式**: 在读多写少的场景中提升性能。
例如,下面的代码使用了生产者-消费者模式:
```cpp
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>
std::queue<int> queue;
std::mutex queue_mutex;
std::condition_variable cond_var;
void producer() {
int count = 0;
while (count < 10) {
std::unique_lock<std::mutex> lock(queue_mutex);
queue.push(count++);
cond_var.notify_one();
}
}
void consumer() {
int data = 0;
while (data < 10) {
std::unique_lock<std::mutex> lock(queue_mutex);
cond_var.wait(lock, []{ return !queue.empty(); });
data = queue.front();
queue.pop();
std::cout << "Consumed: " << data << std::endl;
}
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
```
在这个例子中,生产者线程向队列中添加数据,消费者线程从中取出数据消费。这里使用了`std::condition_variable`来等待队列非空,避免了无用的循环检查。
通过本章的介绍,我们探讨了多线程编程在实际问题中的应用、调试与测试策略以及性能优化的方法。理解这些概念和技巧对于开发高效、健壮的多线程程序至关重要。
# 5. C++多线程编程进阶
## 5.1 锁的精细化管理
### 5.1.1 std::lock_guard和std::unique_lock
C++11引入了新的锁管理工具来提供更灵活的线程同步机制,相较于传统的`std::mutex`,`std::lock_guard`和`std::unique_lock`提供了RAII(Resource Acquisition Is Initialization)风格的锁管理,使得代码更加安全和简洁。
- **std::lock_guard** 是一个RAII包装器,用于在构造函数中自动获取锁,并在析构函数中释放锁。这样可以确保即使在异常抛出的情况下,锁也能被正确释放。
```cpp
#include <mutex>
std::mutex my_mutex;
{
std::lock_guard<std::mutex> lock(my_mutex);
// 执行临界区代码
}
// lock_guard离开作用域,锁自动释放
```
- **std::unique_lock** 提供了比`std::lock_guard`更多的灵活性,它不仅可以延迟锁的获取,还可以在需要时转让锁的所有权。
```cpp
std::unique_lock<std::mutex> lock(my_mutex, std::defer_lock);
if (need_to_lock) {
lock.lock(); // 显式锁定
}
// 使用lock_guard
std::lock_guard<std::mutex> guard(std::move(lock));
// 或者重新获取锁
lock.lock();
```
### 5.1.2 读写锁std::shared_mutex
在很多情况下,读操作远多于写操作,为了提高性能,C++17引入了`std::shared_mutex`,也称为共享互斥锁。
```cpp
#include <shared_mutex>
std::shared_mutex rw_mutex;
// 读取操作
{
std::shared_lock<std::shared_mutex> read_lock(rw_mutex);
// 进行读取操作
}
// 写入操作
{
std::unique_lock<std::shared_mutex> write_lock(rw_mutex);
// 进行写入操作
}
```
`std::shared_mutex`允许多个线程同时读取数据,但是在写入时需要独占锁。这种锁特别适用于读多写少的场景,比如缓存系统。
## 5.2 线程安全的设计模式
### 5.2.1 生产者-消费者问题
生产者-消费者问题是多线程编程中的经典问题,其核心在于如何高效地在生产者和消费者之间共享数据,同时避免竞争条件和死锁。
- **队列的使用**:可以使用线程安全的队列(如`std::queue`配合`std::mutex`和`std::condition_variable`)来处理生产者和消费者之间的同步问题。
```cpp
#include <queue>
#include <mutex>
#include <condition_variable>
#include <thread>
std::queue<int> my_queue;
std::mutex my_mutex;
std::condition_variable my_cond_var;
void producer() {
while (true) {
std::this_thread::sleep_for(std::chrono::milliseconds(100));
int value = produce_value();
{
std::lock_guard<std::mutex> lock(my_mutex);
my_queue.push(value);
}
my_cond_var.notify_one();
}
}
void consumer() {
while (true) {
std::unique_lock<std::mutex> lock(my_mutex);
my_cond_var.wait(lock, [] { return !my_queue.empty(); });
int value = my_queue.front();
my_queue.pop();
lock.unlock();
consume_value(value);
}
}
```
### 5.2.2 任务队列的设计与实现
任务队列是另一种常见的线程安全设计模式,它允许多个生产者向队列中添加任务,而多个消费者从中取出任务并执行。
```cpp
std::queue<std::function<void()>> task_queue;
std::mutex task_mutex;
std::condition_variable task_cond_var;
void worker_thread() {
while (true) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(task_mutex);
task_cond_var.wait(lock, [] { return !task_queue.empty(); });
task = std::move(task_queue.front());
task_queue.pop();
}
task(); // 执行任务
}
}
void add_task(std::function<void()> new_task) {
{
std::lock_guard<std::mutex> lock(task_mutex);
task_queue.push(std::move(new_task));
}
task_cond_var.notify_one();
}
```
## 5.3 深入理解C++内存模型
### 5.3.1 内存顺序详解
C++11引入了内存顺序的概念,用于定义多线程环境下的内存操作顺序。内存顺序是原子操作的一部分,可以控制当原子操作的读者和写者分布在不同的线程时,这些操作如何互相作用。
- **std::memory_order**: 是一个枚举类型,包含了多个内存顺序选项,如`memory_order_relaxed`, `memory_order_acquire`, `memory_order_release`, `memory_order_acq_rel`, 和 `memory_order_seq_cst`等。
```cpp
#include <atomic>
#include <thread>
std::atomic<bool> ready(false);
std::atomic<int> result(0);
void producer() {
result.store(42, std::memory_order_release);
ready.store(true, std::memory_order_release);
}
void consumer() {
while (!ready.load(std::memory_order_acquire));
int r = result.load(std::memory_order_acquire);
assert(r == 42); // 此处不会触发断言
}
```
### 5.3.2 顺序一致性与原子操作
顺序一致性是多线程编程中的一个重要概念,它确保了多个线程看到的内存操作顺序是一致的。在C++中,使用原子操作可以实现顺序一致性。
- **顺序一致性模型**: 当使用`std::memory_order_seq_cst`时,原子操作表现出顺序一致性,保证了操作的全局排序,是最严格但也是最易于理解的内存顺序保证。
```cpp
std::atomic<int> x(0), y(0);
std::atomic<bool> z(false);
void write_x() {
x.store(1, std::memory_order_seq_cst);
}
void write_y() {
y.store(1, std::memory_order_seq_cst);
}
void read_x_then_y() {
while (!x.load(std::memory_order_seq_cst));
if (y.load(std::memory_order_seq_cst)) {
++z;
}
}
void read_y_then_x() {
while (!y.load(std::memory_order_seq_cst));
if (x.load(std::memory_order_seq_cst)) {
++z;
}
}
```
通过顺序一致性的原子操作,即使在多个线程的情况下,也能保证每个操作在所有线程中的执行顺序是一致的。这对于实现复杂的同步机制非常有帮助,尽管在性能上可能比其他内存顺序选项要低。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 C++ 中强大的多线程库 std::thread,涵盖了从基本原理到高级技巧的各个方面。通过一系列深入的文章,您将了解 std::thread 的工作原理、如何利用它创建高性能多线程应用程序、优化线程池以提高并发效率、跨平台使用 std::thread 的最佳实践,以及解决常见问题的调试技术。此外,本专栏还提供了有关共享资源、线程安全、条件变量、任务管理、线程局部存储、数据竞争预防、同步机制、事件驱动架构和操作系统线程互操作性的全面指南。通过阅读本专栏,您将掌握使用 std::thread 构建高效、可扩展和健壮的多线程应用程序所需的知识和技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【聚类算法优化】:特征缩放的深度影响解析
# 1. 聚类算法的理论基础
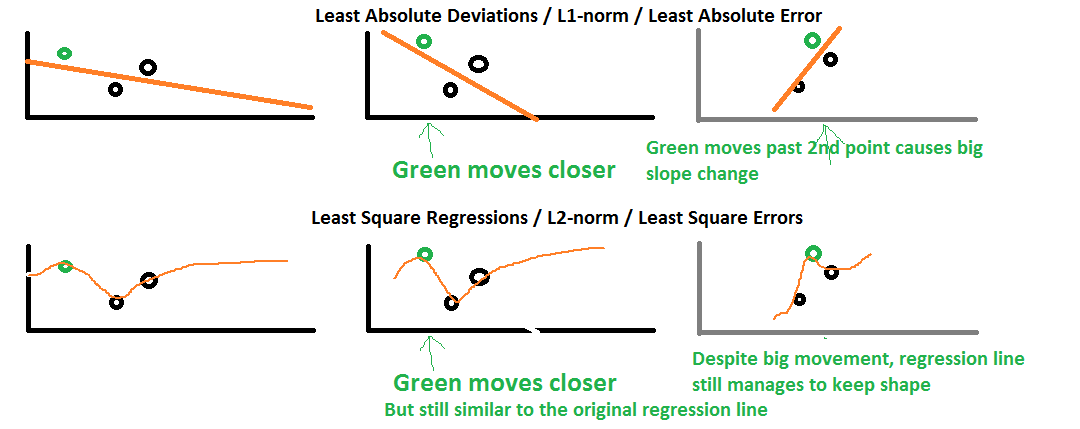
聚类算法是数据分析和机器学习中的一种基础技术,它通过将数据点分配到多个簇中,以便相同簇内的数据点相似度高,而不同簇之间的数据点相似度低。聚类是无监督学习的一个典型例子,因为在聚类任务中,数据点没有预先标注的类别标签。聚类算法的种类繁多,包括K-means、层次聚类、DBSCAN、谱聚类等。
聚类算法的性能很大程度上取决于数据的特征。特征即是数据的属性或
数据标准化:统一数据格式的重要性与实践方法
# 1. 数据标准化的概念与意义
在当前信息技术快速发展的背景下,数据标准化成为了数据管理和分析的重要基石。数据标准化是指采用统一的规则和方法,将分散的数据转换成一致的格式,确保数据的一致性和准确性,从而提高数据的可比较性和可用性。数据标准化不仅是企业内部信息集成的基础,也是推动行业数据共享、实现大数据价值的关键。
数据标准化的意义在于,它能够减少数据冗余,提升数据处理效率
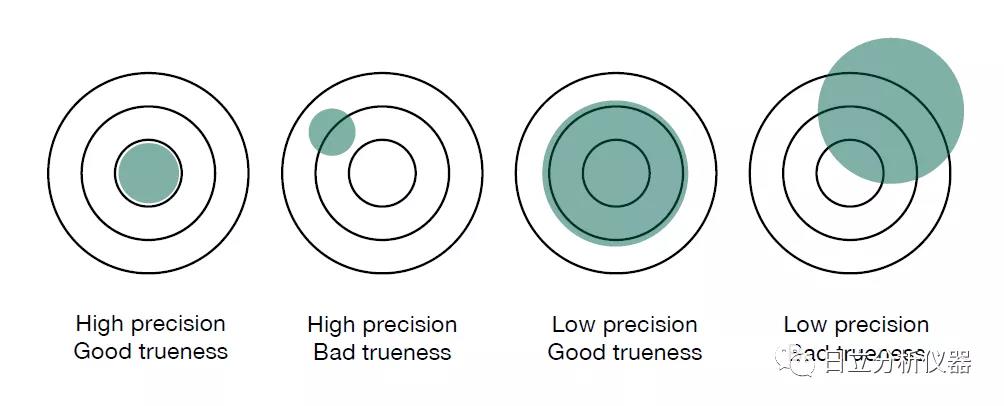
【云环境数据一致性】:数据标准化在云计算中的关键角色
# 1. 数据一致性在云计算中的重要性
在云计算环境下,数据一致性是保障业务连续性和数据准确性的重要前提。随着企业对云服务依赖程度的加深,数据分布在不同云平台和数据中心,其一致性问题变得更加复杂。数据一致性不仅影响单个云服务的性能,更
深度学习在半监督学习中的集成应用:技术深度剖析

# 1. 深度学习与半监督学习简介
在当代数据科学领域,深度学习和半监督学习是两个非常热门的研究方向。深度学习作为机器学习的一个子领域,通过模拟人脑神经网络对数据进行高级抽象和学习,已经成为处理复杂数据类型,如图像、文本和语音的关键技术。而半监督学习,作为一种特殊的机器学习方法,旨在通过少量标注数据与大量未标注数据的结合来提高学习模型
数据归一化的紧迫性:快速解决不平衡数据集的处理难题
# 1. 不平衡数据集的挑战与影响
在机器学习中,数据集不平衡是一个常见但复杂的问题,它对模型的性能和泛化能力构成了显著的挑战。当数据集中某一类别的样本数量远多于其他类别时,模型容易偏向于多数类,导致对少数类的识别效果不佳。这种偏差会降低模型在实际应用中的效能,尤其是在那些对准确性和公平性要求很高的领域,如医疗诊断、欺诈检测和安全监控等。
不平衡数据集不仅影响了模型的分类阈值和准确性评估,还会导致机
【迁移学习的跨学科应用】:不同领域结合的十大探索点

# 1. 迁移学习基础与跨学科潜力
## 1.1 迁移学习的定义和核心概念
迁移学习是一种机器学习范式,旨在将已有的知识从一个领域(源领域)迁移到另一个领域(目标任务领域)。核心在于借助源任务上获得的丰富数据和知识来促进目标任务的学习,尤其在目标任务数据稀缺时显得尤为重要。其核心概念包括源任务、目标任务、迁移策略和迁移效果评估。
## 1.2 迁移学习与传统机器学习方法的对比
与传统机器学习方法不同,迁
无监督学习在自然语言处理中的突破:词嵌入与语义分析的7大创新应用
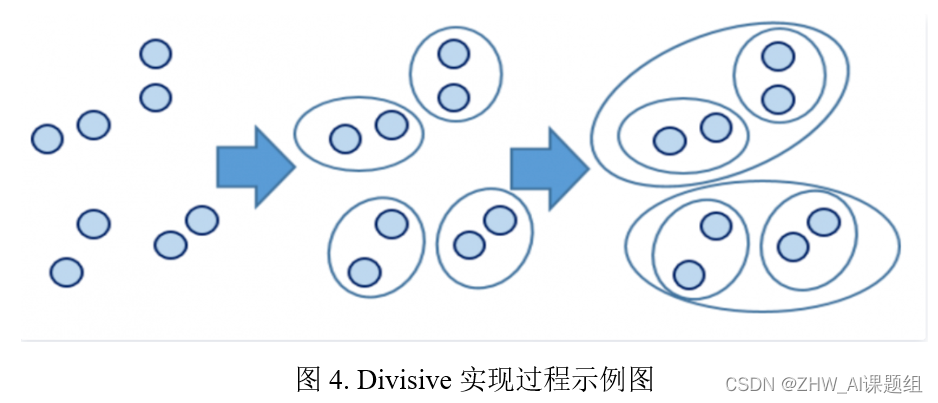
# 1. 无监督学习与自然语言处理概论
## 1.1 无监督学习在自然语言处理中的作用
无监督学习作为机器学习的一个分支,其核心在于从无标签数据中挖掘潜在的结构和模式
【数据集划分的终极指南】:掌握Train_Test Split到数据不平衡处理的20种技巧
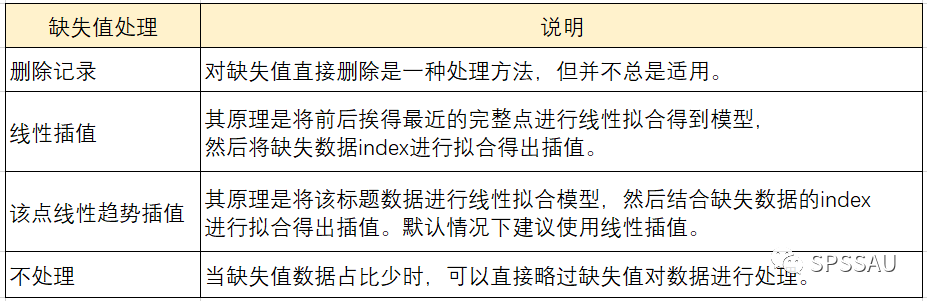
# 1. 数据集划分的基础概念与重要性
在机器学习和数据科学的世界里,数据集划分是一项不可或缺的技术。它不仅关乎模型的训练与验证,更是评估模型泛化能力的关键步骤。理解数据集划分的基础概念,以及其在数据处理流程中的重要性,对于任何致力于构建稳定和可靠模型的开发者来说,都是必不可少的。
数据集划分主要分为三个部分:训练集(Train)、验证集
数据增强实战:从理论到实践的10大案例分析

# 1. 数据增强简介与核心概念
数据增强(Data Augmentation)是机器学习和深度学习领域中,提升模型泛化能力、减少过拟合现象的一种常用技术。它通过创建数据的变形、变化或者合成版本来增加训练数据集的多样性和数量。数据增强不仅提高了模型对新样本的适应能力,还能让模型学习到更加稳定和鲁棒的特征表示。
## 数据增强的核心概念
数据增强的过程本质上是对已有数据进行某种形式的转换,而不改变其底层的分
强化学习在多智能体系统中的应用:合作与竞争的策略
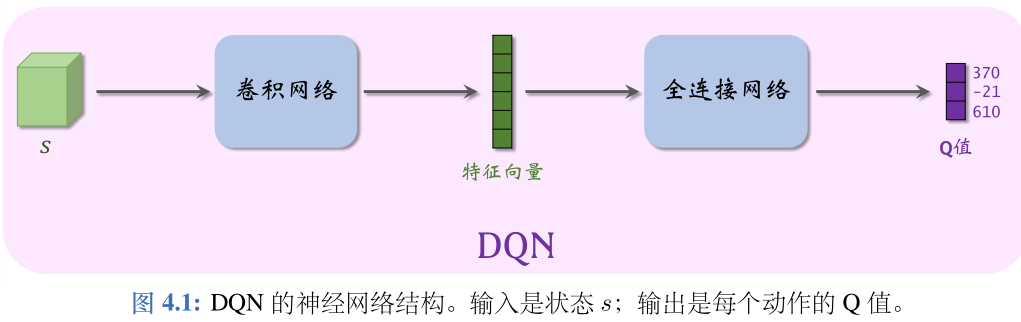
# 1. 强化学习与多智能体系统基础
在当今快速发展的信息技术行业中,强化学习与多智能体系统已经成为了研究前沿和应用热点。它们为各种复杂决策问题提供了创新的解决方案。特别是在人工智能、机器人学和游戏理论领域,这些技术被广泛应用于优化、预测和策略学习等任务。本章将为读者建立强化学习与多智能体系统的基础知识体系,为进一步探讨和实践这些技术奠定理论基础。
## 1.1 强化学习简介
强化学习是一种通过
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )