深入理解Vue.js的响应式原理与生命周期
发布时间: 2024-01-21 05:56:22 阅读量: 28 订阅数: 31 
#
## 第一章:Vue.js简介与响应式原理概述
### 1.1 Vue.js框架简介
Vue.js是一款流行的前端JavaScript框架,它采用了MVVM(Model-View-ViewModel)的设计模式,能够轻松构建交互式的用户界面。Vue.js具有简洁、高效、灵活的特点,因此备受开发者的喜爱。
### 1.2 什么是响应式原理
响应式原理是Vue.js框架的核心概念之一,它可以使数据的变化自动反映在UI界面上。当数据发生变化时,Vue.js会自动更新相关的DOM元素,从而实现了数据和视图的同步。这种机制使得开发者能够专注于数据的处理,而无需手动操作DOM。
### 1.3 Vue.js的数据双向绑定机制
Vue.js的数据双向绑定机制是实现响应式原理的关键。在Vue.js中,将数据与DOM元素进行绑定后,任何对数据的修改都会立即反映在对应的DOM元素上,同时,用户对DOM元素的操作也会同步更新数据。
通过使用Vue.js提供的`v-model`指令,我们可以轻松实现输入框数据到数据模型的双向绑定,例如:
```html
<div id="app">
<input v-model="message" type="text">
<p>{{ message }}</p>
</div>
<script>
var app = new Vue({
el: '#app',
data: {
message: 'Hello, Vue.js!'
}
});
</script>
```
在上面的代码中,`v-model`指令将`input`输入框的值与Vue实例中的`message`属性进行了双向绑定。当用户在输入框中输入内容时,`message`属性的值会自动更新;当`message`属性的值发生改变时,`p`标签中的文本也会同步更新。
这种数据双向绑定的机制让开发者能够更加高效地处理数据与UI之间的交互,提升了开发效率。
总结:本章介绍了Vue.js框架的概述,包括其简介、响应式原理和数据双向绑定机制。下一章将深入探讨Vue实例与数据驱动原理。
# 2. Vue实例与数据驱动原理
### 2.1 Vue实例的创建与生命周期
在Vue.js中,通过创建一个Vue实例来启动应用程序。Vue实例是Vue.js的核心部分,它负责管理整个应用的数据、模板和生命周期。
#### 创建Vue实例
可以通过以下步骤来创建一个Vue实例:
1. 引入Vue.js库:
```html
<script src="https://cdn.jsdelivr.net/npm/vue"></script>
```
2. 实例化一个Vue对象:
```javascript
const app = new Vue({
// 选项
});
```
#### Vue实例的生命周期
Vue实例的生命周期可以分为以下几个阶段:
1. beforeCreate:实例刚被创建,数据观测和事件系统都未初始化。
2. created:实例已经完成了数据观测,属性和方法已经被初始化,但是DOM还未被挂载。
3. beforeMount:在挂载开始之前被调用,相关的render函数首次被调用。
4. mounted:实例已经挂载到DOM上,此时可以进行DOM操作。
5. beforeUpdate:响应式数据发生改变,虚拟DOM重新渲染之前被调用。
6. updated:虚拟DOM重新渲染并应用到实际DOM后被调用。
7. beforeDestroy:实例销毁之前调用。
8. destroyed:实例销毁后调用,清理相关的监听器和子组件。
#### 示例代码
下面是一个简单示例的代码,展示了Vue实例的创建和生命周期钩子函数的使用:
```javascript
// 创建Vue实例
const app = new Vue({
el: '#app',
data: {
message: 'Hello, Vue!'
},
beforeCreate() {
console.log('beforeCreate');
},
created() {
console.log('created');
},
beforeMount() {
console.log('beforeMount');
},
mounted() {
console.log('mounted');
},
beforeUpdate() {
console.log('beforeUpdate');
},
updated() {
console.log('updated');
},
beforeDestroy() {
console.log('beforeDestroy');
},
destroyed() {
console.log('destroyed');
}
});
```
在上述代码中,我们通过new Vue()创建了一个Vue实例,并传入了一些选项,包括el:表示将Vue实例挂载到页面中的DOM元素的选择器;data:表示Vue实例的数据。
在控制台中运行上述代码,可以看到生命周期钩子函数的执行顺序,以及相关的输出结果。
### 2.2 数据驱动视图的原理
Vue.js的核心思想是数据驱动视图,即通过对数据进行操作和更新,自动更新对应的视图。这个过程是如何实现的呢?
Vue.js通过使用响应式的数据绑定机制来实现数据驱动视图,具体原理如下:
1. 在Vue实例初始化时,对data选项中的属性进行劫持,将其转化为getter和setter。
2. 当我们访问或修改这些属性时,触发getter和setter,从而实现对属性的监听。
3. 当属性发生变化时,通过触发依赖追踪机制,通知相关的Watcher进行更新。
4. Watcher接收到变化通知后,触发更新函数,根据新的数据生成新的虚拟DOM,并通过DOM Diff算法比较新旧虚拟DOM的差异。
5. 根据差异生成最终的变更补丁(Patch),然后将补丁应用到实际的DOM上,更新视图。
### 2.3 响应式数据的绑定与更新
Vue.js提供了一些指令和方法来实现数据的响应式绑定和更新,包括v-bind、v-model等。具体用法如下:
- v-bind指令:用于绑定属性,将Vue实例中的数据和DOM元素的属性进行绑定。例如:
```html
<div v-bind:class="className"></div>
```
上述代码中,`v-bind:class`将Vue实例中的`className`属性与该div元素的class属性进行绑定,当`className`发生变化时,class属性也会相应地更新。
- v-model指令:用于实现表单元素的双向绑定,将表单元素的值和Vue实例中的数据进行绑定。例如:
```html
<input v-model="message" />
```
上述代码中,`v-model="message"`将该input元素的值与Vue实例中的`message`数据进行绑定,当用户输入新的值时,`message`数据也会相应地更新。
以上是Vue实例与数据驱动原理的介绍,通过对Vue实例的生命周期和数据驱动视图原理的理解,可以更好地使用Vue.js开发Web应用。在下一章节中,我们将介绍侦听器与计算属性的用法和原理。
# 3.
## 第三章:侦听器与计算属性
### 3.1 侦听器的工作原理
Vue.js提供了一种侦听数据变化的机制,即侦听器(watcher)。侦听器可以监测指定的数据,当数据发生变化时,侦听器会自动执行相应的回调函数。
```javascript
// 创建一个Vue实例
var app = new Vue({
data: {
message: 'Hello, Vue.js!'
},
watch: {
message: function(newMessage, oldMessage) {
console.log('数据发生变化:' + oldMessage + ' => ' + newMessage);
}
}
});
// 修改数据
app.message = 'Hello, world!';
```
上面代码中,我们在Vue实例的`data`选项中定义了一个`message`属性,并在`watch`属性中定义了一个侦听器。当`message`属性发生变化时,侦听器会自动执行回调函数,并输出数据的变化信息。
### 3.2 计算属性与依赖追踪
除了使用侦听器,Vue.js还提供了计算属性(computed property)的方式来实现对数据变化的侦听。计算属性是基于响应式依赖进行缓存的,只有相关的依赖发生变化时,计算属性才会重新计算。
```javascript
// 创建一个Vue实例
var app = new Vue({
data: {
firstName: 'John',
lastName: 'Doe'
},
computed: {
fullName: function() {
return this.firstName + ' ' + this.lastName;
}
}
});
// 获取计算属性的值
console.log(app.fullName); // 输出:John Doe
// 修改相关的依赖
app.firstName = 'Jane';
app.lastName = 'Smith';
// 再次获取计算属性的值
console.log(app.fullName); // 输出:Jane Smith
```
上面的代码中,我们在Vue实例中定义了`firstName`和`lastName`两个属性,并在`computed`选项中定义了一个计算属性`fullName`。`fullName`属性是根据`firstName`和`lastName`的值来计算的,当`firstName`或`lastName`发生变化时,`fullName`会自动重新计算,我们可以通过`app.fullName`来获取最新的计算结果。
### 3.3 何时使用侦听器和计算属性
在开发中,根据具体的需求,我们可以选择使用侦听器或计算属性来处理数据变化。一般来说:
- 当需要在数据变化时执行异步操作或复杂逻辑时,可使用侦听器;
- 当需要对数据进行复杂的处理或运算,并且希望结果被缓存起来,只有依赖发生变化时才重新计算时,可使用计算属性。
根据实际情况选择合适的方式可以减少代码的复杂度并提高性能。
在本章中,我们介绍了Vue.js中的侦听器和计算属性,以及它们的工作原理和使用场景。侦听器和计算属性提供了一种便捷的方式来监听数据变化,并执行相应的操作。在下一章中,我们将深入探讨Vue.js的生命周期钩子函数,更好地理解Vue.js的生命周期管理机制。
# 4. Vue生命周期详解
Vue生命周期是Vue实例从创建、更新到销毁的整个过程,通过一系列的钩子函数(生命周期钩子函数)可以让我们在特定阶段添加自定义逻辑。Vue生命周期包括三个阶段:创建阶段、更新阶段和销毁阶段。以下是Vue生命周期各个阶段的详细介绍:
#### 4.1 Vue实例的创建阶段
在Vue实例的创建阶段,包括了从实例初始化到模板编译的整个过程。在这个阶段,Vue实例会经历以下生命周期钩子函数:
- **beforeCreate**:在实例初始化之后,数据观测 (data observer) 和事件配置之前被调用。
- **created**:实例已经创建完成之后被调用。在这一步,实例已完成数据观测,属性和方法的运算,watch/event事件回调。然而,挂载阶段还没开始,$el 属性目前不可见。
- **beforeMount**:在挂载开始之前被调用:相关的 render 函数首次被调用。
#### 4.2 Vue实例的更新阶段
Vue实例的更新阶段是在数据发生变化,导致视图需要更新时触发的阶段。在这个阶段,Vue实例会经历以下生命周期钩子函数:
- **beforeUpdate**:数据更新时调用,发生在虚拟 DOM 重新渲染和打补丁之前。
- **updated**:由虚拟 DOM 重新渲染和打补丁之后调用。调用时,组件 DOM 已更新,所以你现在可以执行依赖于 DOM 的操作。
#### 4.3 Vue实例的销毁阶段
在Vue实例被销毁时,会触发销毁阶段的生命周期钩子函数,主要用于善后处理以及清理工作。
- **beforeDestroy**:在实例销毁之前调用。在这一步,实例仍然完全可用。
- **destroyed**:在实例销毁之后调用。该钩子函数用于处理一些清理工作和解绑定。
以上是Vue生命周期各个阶段的详细内容,在实际项目开发中,充分理解Vue生命周期对于合理处理数据和资源具有重要意义。
# 5. 响应式原理与性能优化
在Vue.js中,响应式原理是其核心机制之一。通过响应式原理,Vue.js能够将数据和视图进行高效的绑定,并在数据发生变化时自动更新视图。然而,在实际开发中,大规模的数据更新可能会导致性能问题,因此我们需要深入了解响应式原理,并掌握一些性能优化的策略。
#### 5.1 虚拟DOM与DOM Diff算法
Vue.js使用虚拟DOM(Virtual DOM)来提高渲染性能。在数据发生变化时,Vue会先将变化的部分转换成虚拟DOM,然后与之前的虚拟DOM进行对比,找出差异并最小化影响的部分,最后只对实际发生变化的部分进行DOM操作,从而减少了DOM操作的次数,提升了渲染效率。
DOM Diff算法是虚拟DOM的核心算法之一,它通过高效的方式对比新旧虚拟DOM的差异,找出需要更新的部分。Vue.js内部使用了一些优化手段,比如采用了双端比较的策略,以及对特殊情况进行了特殊处理,来进一步提高DOM Diff的效率。
#### 5.2 响应式数据的性能优化策略
在实际开发中,我们需要注意一些响应式数据的性能优化策略,比如避免频繁触发setter函数、合理使用计算属性、合理使用v-if和v-for等指令、合理使用key属性来优化DOM的复用等。这些优化策略可以有效减少不必要的DOM操作,提升渲染性能。
#### 5.3 避免不必要的更新与渲染
最后,在开发过程中,我们还需要注意避免不必要的更新与渲染。比如通过合理使用shouldComponentUpdate或者React.memo(在React中)、shouldUpdateComponent(在Vue.js中)来避免不必要的组件更新,以及通过合理的事件节流、函数防抖来减少不必要的数据更新等方式,来优化应用的性能。
在本章中,我们将通过实际的代码示例和性能优化手段,深入理解Vue.js中的响应式原理与性能优化策略,帮助开发者更好地利用Vue.js进行前端开发,并构建高性能的Web应用。
希望这个章节内容符合你的要求,如果有其他需要,也可以随时向我提问。
# 6. 深入理解Vue.js的生命周期钩子函数
Vue.js提供了一系列的生命周期钩子函数,可以让开发者在组件的不同阶段执行相应的操作。在本章节中,我们将深入探讨Vue.js的生命周期钩子函数。
### 6.1 生命周期钩子函数的分类与执行顺序
Vue.js的生命周期钩子函数可以分为8个阶段,按照执行顺序从上到下分别是:
1. beforeCreate:在实例初始化之后,数据观测(data observer)和event/watcher事件配置之前调用。
2. created:在实例创建完成后调用,此时实例已经完成数据观测,但是尚未挂载到DOM上。
3. beforeMount:在实例挂载之前调用,相关的render函数首次被调用。
4. mounted:在实例挂载到DOM上后调用,此时组件已经被渲染出来。
5. beforeUpdate:在响应式数据更新之前调用,DOM还没有被重新渲染。
6. updated:在响应式数据更新并且DOM重新渲染完成之后调用。
7. activated:用于keep-alive组件,组件被激活时调用。
8. deactivated:用于keep-alive组件,组件被停用时调用。
### 6.2 生命周期钩子函数的应用场景
不同的生命周期钩子函数适用于不同的场景,根据需要选择合适的钩子函数来执行相应的操作。下面列举了一些常见的应用场景:
- beforeCreate:可以在此阶段进行一些初始化的工作,例如全局事件的注册。
- created:可以在此阶段进行一些异步请求或者其他的初始化操作。
- beforeMount:可以在此阶段修改渲染内容或者执行一些其他操作。
- mounted:可以在此阶段进行DOM操作或者与第三方库进行交互。
- beforeUpdate:可以在此阶段做一些在数据更新前需要处理的操作。
- updated:可以在此阶段进行DOM操作、调用第三方库的更新方法等。
- activated:可以在此阶段执行一些组件被激活时需要的操作。
- deactivated:可以在此阶段执行一些组件被停用时需要的操作。
### 6.3 自定义生命周期钩子函数的实现
除了内置的生命周期钩子函数,Vue.js还允许开发者在组件中自定义钩子函数来满足特定的需求。自定义钩子函数可以在组件的任意阶段执行相应的操作,增强了组件的灵活性。
下面是一个自定义钩子函数的示例:
```javascript
Vue.component('my-component', {
created: function () {
this.customHook();
},
methods: {
customHook: function () {
console.log('Custom hook is called');
}
}
})
```
以上示例中,在组件的`created`阶段,我们调用了自定义的钩子函数`customHook`来输出一条自定义的日志信息。
总结:
本章节我们深入理解了Vue.js的生命周期钩子函数,包括其分类和执行顺序,以及应用场景和自定义钩子函数的实现。通过合理地利用生命周期钩子函数,可以更好地控制和管理组件的生命周期,提升应用程序的性能和用户体验。
希望本章节的内容能够帮助你更好地理解Vue.js的生命周期钩子函数。如果有任何疑问或需要进一步的帮助,请随时与我联系。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏旨在通过实战案例精讲,帮助读者深入学习并掌握基于JS/React/VueJS/NodeJS框架的开发技能。从JavaScript基础知识入门到高级技巧与性能优化,以及React、Vue.js和Node.js各个方面的实践经验,涵盖了组件开发、响应式开发、服务器端开发、异步编程、事件驱动、函数式编程、模块化开发、打包工具、路由管理、组件通信、状态管理、网络编程、安全防护等多个关键主题。读者将深入理解这些技术的原理和应用,掌握错误处理与调试技巧,学习数据库操作与 ORM 框架实战,了解组件化开发与 UI 库实践,以及 Web 安全与防护策略。通过专栏的学习,读者可以系统地提升在前端和服务器端开发中的技能水平。
专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【保险行业extRemes案例】:极端值理论的商业应用,解读行业运用案例
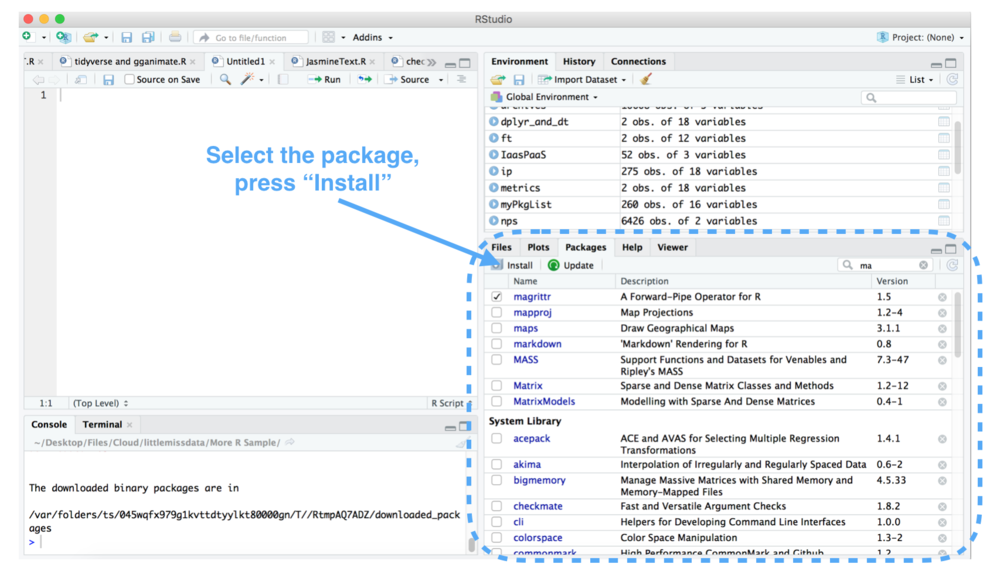
# 1. 极端值理论概述
极端值理论是统计学的一个重要分支,专注于分析和预测在数据集中出现的极端情况,如自然灾害、金融市场崩溃或保险索赔中的异常高额索赔。这一理论有助于企业和机构理解和量化极端事件带来的风险,并设计出更有效的应对策略。
## 1.1 极端值理论的定义与重要性
极端值理论提供了一组统计工具,
R语言数据分析高级教程:从新手到aov的深入应用指南
# 1. R语言基础知识回顾
## 1.1 R语言简介
R语言是一种开源编程语言和软件环境,特别为统计计算和图形表示而设计。自1997年由Ross Ihaka和Robert Gentleman开发以来,R已经成为数据科学领域广受欢迎的工具。它支持各种统计技术,包括线性与非线性建模、经典统计测试、时间序列分析、分类、聚类等,并且提供了强大的图形能力。
## 1.2 安装与配置R环境
要开始使用R语言,首先需要在计算机上安装R环境。用户可以访问官方网站
【R语言统计推断】:ismev包在假设检验中的高级应用技巧

# 1. R语言与统计推断基础
## 1.1 R语言简介
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。由于其强大的数据处理能力、灵活的图形系统以及开源性质,R语言被广泛应用于学术研究、数据分析和机器学习等领域。
## 1.2 统计推断基础
统计推断是统计学中根据样本数据推断总体特征的过程。它包括参数估计和假设检验两大主要分支。参数估计涉及对总体参数(如均值、方差等)的点估计或区间估计。而
R语言prop.test应用全解析:从数据处理到统计推断的终极指南

# 1. R语言与统计推断简介
统计推断作为数据分析的核心部分,是帮助我们从数据样本中提取信息,并对总体进行合理假设与结论的数学过程。R语言,作为一个专门用于统计分析、图形表示以及报告生成的编程语言,已经成为了数据科学家的常用工具之一。本章将为读者们简要介绍统计推断的基本概念,并概述其在R语言中的应用。我们将探索如何利用R语言强大的统计功能库进行实验设计、数据分析和推断验证。通过对数据的
【R语言编程实践手册】:evir包解决实际问题的有效策略

# 1. R语言与evir包概述
在现代数据分析领域,R语言作为一种高级统计和图形编程语言,广泛应用于各类数据挖掘和科学计算场景中。本章节旨在为读者提供R语言及其生态中一个专门用于极端值分析的包——evir——的基础知识。我们从R语言的简介开始,逐步深入到evir包的核心功能,并展望它在统计分析中的重要地位和应用潜力。
首先,我们将探讨R语言作为一种开源工具的优势,以及它如何在金融
R语言lme包深度教学:嵌套数据的混合效应模型分析(深入浅出)

# 1. 混合效应模型的基本概念与应用场景
混合效应模型,也被称为多层模型或多水平模型,在统计学和数据分析领域有着重要的应用价值。它们特别适用于处理层级数据或非独立观测数据集,这些数据集中的观测值往往存在一定的层次结构或群组效应。简单来说,混合效应模型允许模型参数在不同的群组或时间点上发生变化,从而能够更准确地描述数据的内在复杂性。
## 1.1 混合效应模型的
【R语言t.test实战演练】:从数据导入到结果解读,全步骤解析

# 1. R语言t.test基础介绍
统计学是数据分析的核心部分,而t检验是其重要组成部分,广泛应用于科学研究和工业质量控制中。在R语言中,t检验不仅易用而且功能强大,可以帮助我们判断两组数据是否存在显著差异,或者某组数据是否显著不同于预设值。本章将为你介绍R语言中t.test函数的基本概念和用法,以便你能快速上手并理解其在实际工作中的应用价值。
## 1.1 R语言t.test函数概述
R语言t.test函数是一个
【R语言图表大师】:princomp包在数据可视化中的神奇应用
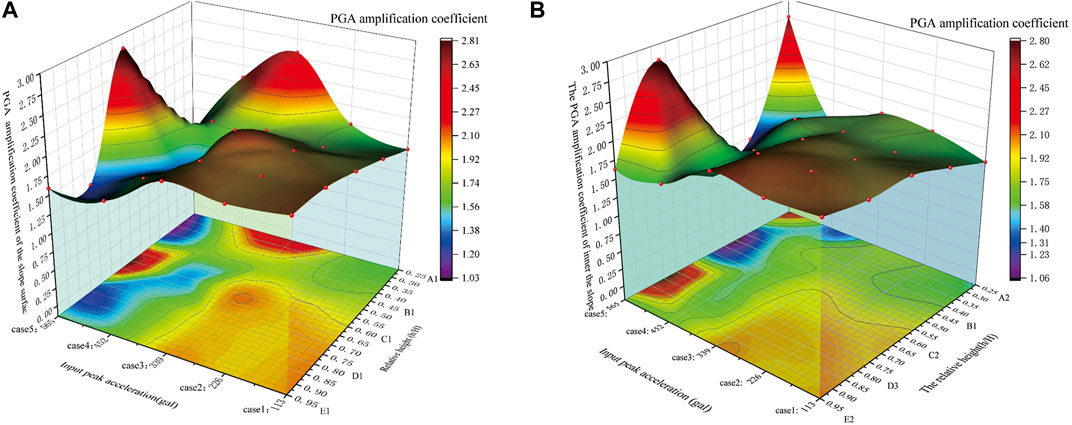
# 1. R语言与数据可视化
随着数据量的不断增长,数据可视化已成为将复杂信息转换为直观视觉表现的关键工具,而R语言作为数据分析领域中的一把利剑,其在数据可视化方面的表现更是引人注目。本章将首先介绍R语言的基本概念,随后着重探讨其在数据可视化方面的强大功能。
R语言是一种专门用于统计分析和图形表示的编程语言,它不仅
【数据清洗艺术】:R语言density函数在数据清洗中的神奇功效

# 1. 数据清洗的必要性与R语言概述
## 数据清洗的必要性
在数据分析和挖掘的过程中,数据清洗是一个不可或缺的环节。原始数据往往包含错误、重复、缺失值等问题,这些问题如果不加以处理,将严重影响分析结果的准确性和可靠性。数据清洗正是为了纠正这些问题,提高数据质量,从而为后续的数据分析和模型构建打下坚实的基础。
## R语言概述
R语言是一种用于统计分析
R语言数据包个性化定制:满足复杂数据分析需求的秘诀

# 1. R语言简介及其在数据分析中的作用
## 1.1 R语言的历史和特点
R语言诞生于1993年,由新西兰奥克兰大学的Ross Ihaka和Robert Gentleman开发,其灵感来自S语言,是一种用于统计分析、图形表示和报告的编程语言和软件环境。R语言的特点是开源、功能强大、灵活多变,它支持各种类型的数据结
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )