【Anaconda配置专家】:揭秘高效集成外部数据源的不传之秘
发布时间: 2024-12-10 00:56:43 阅读量: 4 订阅数: 16 

anaconda:配置pip的清华镜像源

# 1. Anaconda配置专家入门
## 1.1 安装Anaconda
Anaconda 是一个开源的Python发行版本,它包含了数据分析的必要库如NumPy、Pandas等,并且通过Conda包管理器简化了包的安装和环境配置。首先从Anaconda官网下载适合您操作系统的Anaconda安装包。安装时请遵循以下步骤:
- 下载适合您系统架构的Anaconda安装程序(例如Python 3.7版本)。
- 运行安装向导,并遵循指示完成安装。
- 在安装过程中,确保勾选“Add Anaconda to my PATH environment variable”选项,以便在任何目录下都能直接使用conda命令。
安装完成后,打开命令提示符或终端,输入`conda list`确认安装成功。
## 1.2 配置基础环境
安装Anaconda后,需要配置一个适合数据分析的基础环境。可以通过以下步骤进行基础环境的配置:
- 使用命令`conda create -n base python=3.7`创建一个新的名为“base”的环境,并指定Python版本为3.7。
- 使用命令`conda activate base`激活该环境。
- 使用命令`conda install jupyter pandas numpy scipy matplotlib`安装一些常用的数据分析和可视化库。
这样,您就已经准备好了一个基础的数据分析环境。接下来,您可以开始使用Jupyter Notebook进行Python编程和数据分析。
## 1.3 运行您的第一个Notebook
Jupyter Notebook 是一个交互式的Web应用,能够让您运行代码、添加注释和可视化展示结果。要运行您的第一个Notebook,按照以下步骤操作:
- 在激活的Anaconda环境中输入`jupyter notebook`启动Jupyter服务器。
- 通过Web界面创建一个新的Notebook,通常默认为Python 3环境。
- 在Notebook中输入您的第一段代码,并使用`Shift+Enter`运行它。
通过这一步骤,您可以验证Anaconda环境配置是否成功,并开始您的数据分析之旅。
本章内容提供了安装和配置Anaconda环境的基础知识,是成为数据分析专家的第一步。在后续章节中,您将学习如何利用Anaconda进行环境管理和包管理,从而在特定领域深入应用。
# 2. Anaconda环境与包管理
## 2.1 Anaconda环境配置
### 2.1.1 理解Conda环境管理器
Conda环境管理器是Anaconda包、依赖和环境管理的工具。它可以帮助用户创建、保存、加载和切换不同的环境,而不会干扰不同项目或应用程序所需的包和版本。在多项目工作流中,Conda环境管理器变得至关重要,它确保了项目之间的隔离性,同时也避免了潜在的依赖冲突。
Conda环境通过创建具有独立文件系统的虚拟环境来工作,每个环境都有自己的Python版本和安装的包。这种隔离性允许开发者在不担心破坏系统级别安装的情况下,自由安装和测试软件包。
要开始使用Conda,首先需要安装Anaconda或Miniconda。Miniconda是Anaconda的轻量级版本,包含Conda和其依赖的包管理器。安装完成后,通过命令行界面(CLI)或Anaconda Navigator(一个图形用户界面)来管理环境。
### 2.1.2 创建和管理Conda环境
创建新的Conda环境,可以使用`conda create`命令。例如,创建一个名为`myenv`的新环境,并安装Python版本3.8:
```bash
conda create -n myenv python=3.8
```
激活环境,使用以下命令:
```bash
conda activate myenv
```
在环境中安装包时,Conda会自动处理依赖关系,确保环境的一致性。例如,安装Pandas库:
```bash
conda install pandas
```
如果你想查看环境中安装的所有包,可以使用`conda list`命令。
删除一个环境,则执行:
```bash
conda remove --name myenv --all
```
Conda环境管理器还支持环境复制和导出功能,允许用户在多个环境间共享和迁移。
## 2.2 包的安装与管理
### 2.2.1 安装常用数据分析包
Anaconda提供了超过7500个预构建的科学和数据分析包。这些包是针对Windows, macOS和Linux操作系统预编译的二进制文件,从而简化了安装过程。常用的包包括Pandas, NumPy, Matplotlib等。
对于数据分析项目,Pandas是一个极其重要的数据处理库。安装Pandas可以通过Conda命令:
```bash
conda install pandas
```
NumPy是处理大型多维数组和矩阵的基础包,可以通过以下命令安装:
```bash
conda install numpy
```
Matplotlib用于生成高质量的图形和可视化。安装它同样很简单:
```bash
conda install matplotlib
```
这些命令不仅安装了指定的包,同时还会安装所有必须的依赖项。
### 2.2.2 更新和删除包的策略
随着时间的推移,软件包会不断更新,以修复错误、提高性能或增加新功能。Conda环境管理器提供了方便的命令来更新包或环境。
更新单个包:
```bash
conda update pandas
```
更新所有包:
```bash
conda update --all
```
删除不再需要的包,以减少环境中的冗余:
```bash
conda remove pandas
```
### 2.2.3 版本控制和依赖性管理
在管理多个项目或多个用户时,不同版本的包可能会带来依赖性冲突。Conda通过创建环境和记录每个环境的精确依赖关系,从而解决了这个问题。
Conda环境可以保存为YAML文件(`.yaml`),文件中详细记录了环境的配置。使用以下命令可以导出当前环境:
```bash
conda env export > environment.yaml
```
要创建与上述文件相同的环境,可以使用:
```bash
conda env create -f environment.yaml
```
Conda的这种管理机制允许用户在不同项目之间轻松切换,并确保了环境的一致性。
## 2.3 虚拟环境的实践技巧
### 2.3.1 解决环境冲突的策略
在多个项目同时进行时,可能会因为不同项目间的依赖版本不同而产生冲突。为了解决这些冲突,可以通过创建独立的Conda环境来避免包版本的直接冲突。
- **环境隔离**:使用不同环境来运行不同版本的包,确保每个环境的独立性。
- **环境命名约定**:为环境选择描述性的名称,方便管理。例如,根据项目名称和Python版本来命名环境。
- **环境文件管理**:养成将环境配置导出为YAML文件的习惯,便于跟踪和复现环境配置。
- **环境清理**:定期检查和清理不使用的环境,减少系统的负担。
### 2.3.2 虚拟环境的迁移和分享
虚拟环境的迁移和分享对团队协作和项目部署至关重要。Conda环境通过导出和导入配置文件来实现环境的迁移。
- **环境迁移**:在一台计算机上导出环境文件后,可以将文件传输到另一台机器上,并通过导入环境文件来重建相同的环境。
- **环境分享**:将环境配置文件分享给团队成员或部署到生产环境,以确保环境的一致性。
在团队协作中,环境文件通常通过版本控制系统(如Git)来管理,这允许团队成员共享和同步环境配置的变更。
# 3. 集成外部数据源的策略
在数据驱动的今天,集成外部数据源已经成为了企业与组织不可或缺的一部分。数据集成,简单来说,就是将不同来源、不同格式和不同结构的数据结合起来,存储在一个统一的系统中,以便于分析和处理。本章将探讨数据源的分类和选择、数据集成工具的使用以及数据集成的实践案例。
## 3.1 数据源的分类和选择
在处理数据集成之前,首先需要了解数据源的分类和如何选择合适的数据源,以满足特定业务的需求。
### 3.1.1 内部数据源与外部数据源的区别
内部数据源通常指由企业内部系统产生的数据,如ERP系统、CRM系统、日志文件等。这些数据一般结构化程度较高,易于管理。然而,企业为了更全面地了解市场和消费者,外部数据源的引入变得尤为重要。外部数据源包括社交媒体数据、公开API、行业报告、市场调研等,这类数据来源广泛,更新频率快,但数据质量参差不齐,需要经过仔细的筛选和预处理。
### 3.1.2 评估数据源的可靠性和兼容性
选择合适的数据源时,需考虑以下几个关键因素:
- **可靠性**:数据的准确性、完整性和时效性。
- **兼容性**:数据格式是否符合集成系统的要求。
- **相关性**:数据对于业务问题的相关度和价值。
- **成本效益**:获取和处理数据的成本与潜在收益的对比。
## 3.2 数据集成工具的使用
当数据源被选定后,接下来的任务是使用适当的工具进行数据集成。这包括数据抓取工具、数据清洗和预处理工具。
###

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在为数据科学家提供全面的指南,帮助他们高效地将外部数据源集成到 Anaconda 环境中。通过深入探讨七大技巧、安全集成策略、速成指南、最佳实践、核心技术、扩展秘籍、优化策略、多数据源管理技巧和从零开始的全面指南,本专栏涵盖了 Anaconda 外部数据源集成的各个方面。无论您是经验丰富的数据科学家还是刚起步的初学者,本专栏都将为您提供必要的知识和技巧,让您充分利用 Anaconda 的强大功能,无缝地集成外部数据源,并提升您的数据科学项目效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【航天动力学初探】:STK教程,轨道元素与六根体问题全面解析

参考资源链接:[STK中文教程:从基础到高级操作指南](https://wenku.csdn.net/doc/63qrhf85kg?spm=1055.2635.3001.10343)
# 1. 航天动力学基础与STK介绍
在航天工程中,对航天器运动规律的深入理解是至关重要的。航天动力学作为这门学科的核心,涉及轨道力学、推进技术、姿态动力学等多个领域。本章将带您走
数字信号处理:第4版第10章,实战技巧全揭秘
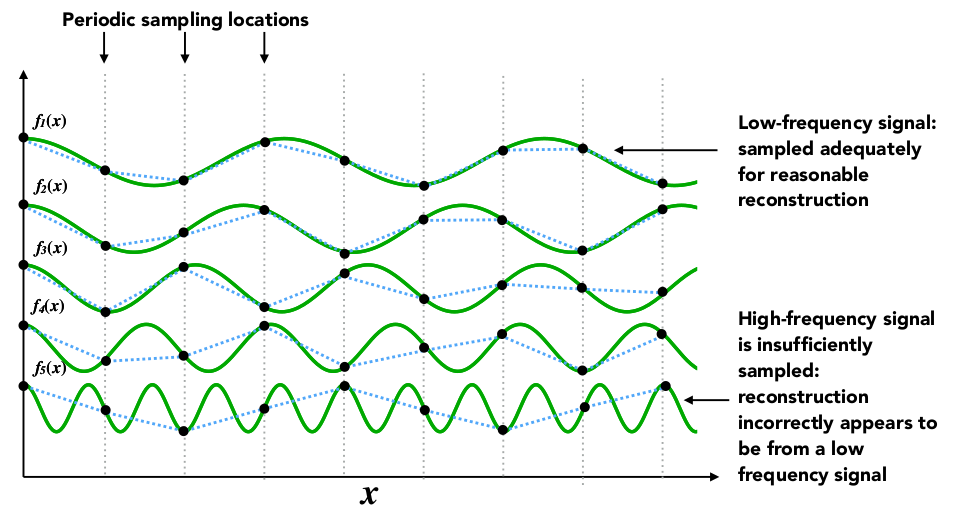
参考资源链接:[数字信号处理 第四版 第10章习题答案](https://wenku.csdn.net/doc/6qhimfokjs?spm=1055.2635.3001.10343)
# 1. 数字信号处理基础
数字信号处理(DSP)是信息科学中的一个重要分支,它涉及使用数字方法对信号进行分析和处理。在这一章节中,我们将简要回顾数字信号处理的基本概念和原理,为后续章节中更深入的技术讨
【J1939Rm模块故障案例库全集】:从问题解决到经验总结
参考资源链接:[AUTOSAR J1939Rm模块详解:请求与响应管理](https://wenku.csdn.net/doc/6401abf8cce7214c316ea282?spm=1055.2635.3001.10343)
# 1. J1939Rm模块概述
在现代的车辆和重型机械中,电子控制单元(ECU)是不可或缺的组成部分,而J1939Rm模块作
【Android事件分发详解】:计算器应用中的高级交互技术
参考资源链接:[Android Studio教程:简易计算器实现与代码详解](https://wenku.csdn.net/doc/2urgwqxj21?spm=1055.2635.3001.10343)
# 1. Android事件分发机制概述
## 1.1 事件分发机制简介
Android应用的交互体验几乎都建立在事件分发机制之上。这一机制负责将如点击、触摸、按键等用户操作(统
Java中的JxBrowser 6.x 高级Web交互实现:专家技巧揭秘

参考资源链接:[JxBrowser 6.x 破解教程:免费获取并修改授权](https://wenku.csdn.net/doc/1ik598iqcb?spm=1055.2635.3001.10343)
# 1. JxBrowser入门基础
在本章中,我们将为你揭开JxBrowser的神秘面纱,概述其入门基础知识,确保即使是初学者也能顺利上手。我们将讨论JxBrowser是什么、它的主要用途以及为什么它在企业级应用中
【M.2故障诊断全攻略】:快速定位问题,保障系统稳定运行

参考资源链接:[M.2规格1.1版:2016年PCIe接口详细设计与PCB布局指南](https://wenku.csdn.net/doc/41m3z
【SFP+选型秘籍】:深入解读SFF-8431,轻松挑选理想光模块
参考资源链接:[SFF-8431标准详解:SFP+光模块低速与高速接口技术规格](https://wenku.csdn.net/doc/3s3xhrwidr?spm=1055.2635.3001.10343)
# 1. SFP+与SFF-8431标准概述
## 1.1 SFP+与SFF-8431简介
SFP+(Small Form-factor Pluggable Plus)是SFP(Small Form-factor Pluggable)接口的增强版,采用了高速串行通信协议,支持10Gbps的数据传输速率。它主要应用于数据中心、高速网络连接以及电信网络。SFF-8431标准则是定义SFP
【线性代数解密】:掌握浙大习题,揭开矩阵运算的神秘面纱(解题秘籍大公开)

参考资源链接:[浙大线性代数习题详细解答:涵盖行列式到特征向量](https://wenku.csdn.net/doc/6401ad0ccce7214c3
LinuxCNC源码深度解析:掌握核心组件与交互机制的7个秘诀
参考资源链接:[LinuxCNC源程序入门指南:结构与功能概览](https://wenku.csdn.net/doc/6412b54abe7fbd1778d429fa?spm=1055.2635.3001.10343)
# 1. LinuxCNC概述与基础架构
LinuxCNC是一个开源的运动控制软件包,广泛应用于数控机床和机器人控制。它的设计目标是提供一个高度可配置、稳定且具有实时性
【编译器设计模式】:模块化编译器构建的最新技术
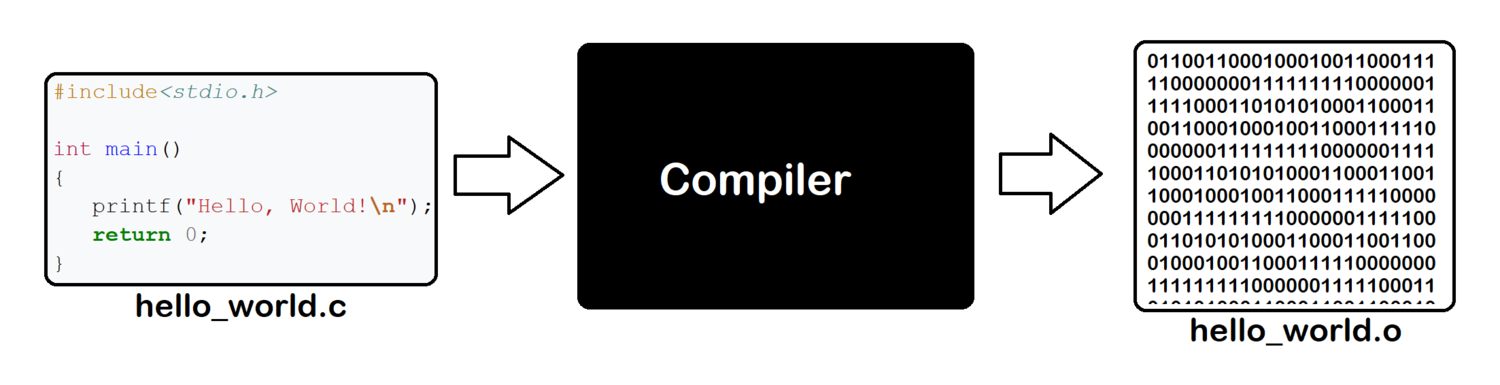
参考资源链接:[《编译原理》清华版课后习题答案详解](https://wenku.csdn.net/doc/4r3oyj2zqg?spm=1055.2635.3001.10343)
# 1. 编译器设计模式概述
在现代计算世界中,编译器承担着将高级编程语言转换为机器语言的关键角色。本章将概述编译器设计模式的基本概念和重要性,为读
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )