【Anaconda实践指南】:深入理解包管理与外部数据源整合
发布时间: 2024-12-10 00:47:31 阅读量: 5 订阅数: 16 

《Anaconda安装指南:适用于初学者的Python环境配置》

# 1. Anaconda简介与安装配置
## Anaconda简介
Anaconda是一个用于科学计算的Python发行版,它包含了conda、Python等180多个科学包及其依赖项。Anaconda具有包管理和环境管理的功能,这使得它非常适合数据科学、机器学习和大规模数据处理等领域。Anaconda支持Linux、Mac和Windows操作系统,能够跨平台运行。
## 安装Anaconda
安装Anaconda的过程非常直接。首先,你需要从[Anaconda官网](https://www.anaconda.com/products/distribution)下载适合你操作系统的安装程序。下载后,运行安装程序并遵循指示完成安装。默认情况下,Anaconda会安装最新版本的Python。对于Windows用户,安装过程中可以设置环境变量和安装路径,而Mac和Linux用户可能需要手动设置环境变量。
## 配置Anaconda
安装完成后,你需要验证安装是否成功。打开终端或命令提示符,输入`conda --version`检查Conda的版本。接下来,可以使用`conda list`命令查看已安装的包。最后,使用`conda update conda`命令更新Anaconda到最新版本。这一节的内容虽然简单,但对于初学者来说至关重要,因为它是开始使用Anaconda的先决条件。
# 2. Anaconda包管理器的基础使用
## 2.1 Conda的基本命令和功能
### 2.1.1 安装、更新和卸载包
在使用Conda进行Python包管理时,基本命令是用户必须掌握的基础。例如,安装一个包可以通过`conda install`命令完成:
```bash
conda install package_name
```
此命令会从Conda配置的默认通道安装指定的包。如果要安装特定版本的包,可以指定版本号,如:
```bash
conda install package_name=1.0.4
```
对于更新包,Conda提供了简单直接的方式:
```bash
conda update package_name
```
这条命令会检查并更新到最新版本。如果想要更新所有可更新的包,则可以省略包名:
```bash
conda update --all
```
而卸载一个包,Conda提供了如下命令:
```bash
conda remove package_name
```
执行以上命令时,Conda会询问用户是否继续,以防止误操作。
### 2.1.2 管理环境和依赖关系
Conda的另一个重要特性是环境管理。创建一个新的环境,可以使用以下命令:
```bash
conda create -n myenv python=3.8
```
这个命令创建了一个名为`myenv`的新环境,并在其中安装了Python 3.8。环境可以针对不同的项目需求进行隔离。
激活一个环境使用`conda activate`:
```bash
conda activate myenv
```
在环境激活的状态下,安装的包都会被限制在该环境中,不会影响到其他环境或全局安装的包。
为了查看当前激活的环境及其包,可以使用`conda list`命令。同时,Conda提供了`conda env list`来查看所有可用环境。
## 2.2 Pip包管理器的使用与注意事项
### 2.2.1 Pip与Conda的比较
Pip是另一个广泛使用的Python包管理器。它与Conda的主要区别在于,Pip主要用于安装和管理Python包,而Conda不仅可以安装Python包,还能管理整个环境的依赖。
Pip安装包的命令为:
```bash
pip install package_name
```
为了与Conda环境协同工作,Conda为Pip提供了特殊的环境管理命令:
```bash
conda activate myenv && pip install package_name
```
这样可以确保Pip安装的包只在当前激活的Conda环境中。
### 2.2.2 解决Pip包依赖冲突
使用Pip时,尤其是在多个环境中工作时,可能会遇到包依赖冲突的问题。为了解决冲突,可以采取以下措施:
- 使用虚拟环境来隔离不同项目依赖。
- 使用`pip freeze`来导出当前环境的依赖,然后在其他环境中使用`pip install -r requirements.txt`重新安装。
- 利用`pip install --ignore-installed`选项强制重新安装某个包的指定版本。
## 2.3 环境的创建和管理
### 2.3.1 理解环境的重要性
在数据科学和开发过程中,环境隔离是非常重要的。它允许用户为每个项目创建独立的运行环境,从而避免不同项目之间的依赖冲突。
环境可以包含不同的Python解释器版本以及不同版本的依赖包。这使得开发者可以为每个项目精确控制运行环境,确保代码的一致性和项目的可复现性。
### 2.3.2 创建和配置新环境
Conda提供了一个非常便利的方式来创建和管理环境。创建一个新的环境,首先需要确定环境的名称以及要使用的Python版本:
```bash
conda create -n env_name python=x.x
```
之后,可以通过`conda activate env_name`激活环境。激活之后,所有使用Pip或Conda安装的包都会只影响该环境,而不会影响到其他环境或全局Python环境。
还可以在创建环境时一次性指定多个依赖包:
```bash
conda create -n env_name numpy scipy matplotlib
```
此命令会创建一个名为`env_name`的环境,并安装`numpy`、`scipy`和`matplotlib`这三个包。
# 3. Anaconda环境的高级管理技巧
## 3.1 环境的克隆和备份
### 3.1.1 环境的导出和导入
环境管理是数据科学工作流中的一个重要环节,尤其是在需要在不同机器或者不同项目之间迁移环境时。Anaconda提供了一种简单的方式来进行环境的导出和导入。这一过程通常涉及到使用`conda env export`和`conda env create`命令。
通过`conda env export`命令,可以将当前环境中的所有包及其版本导出为一个YAML格式的文件。执行命令后,会显示包含环境依赖信息的列表,该列表可以被保存到一个YAML文件中,例如`environment.yml`。
```
conda env export > environment.yml
```
然后,可以使用`conda env create`命令来创建一个与导出环境相同配置的新环境。该命令读取YAML文件,并安装所有列出的包及其指定的版本。
```
conda env create -f environment.yml
```
#### 参数说明
- `-f` 参数指定要读取的YAML文件的路径。
#### 执行逻辑说明
1. 在当前环境运行`conda env export > environment.yml`,导出环境配置到YAML文件。
2. 将YAML文件复制到新的工作环境或另一台机器。
3. 在新的环境或机器上运行`conda env create -f environment.yml`,以导入环境配置。
通过这种方式,可以确保不同环境间的一致性,并且能够在团队协作中有效地同步环境配置。
### 3.1.2 利用YAML文件管理环境
YAML(Yet Another Markup Language)文件是用于配置Anaconda环境的一种强大工具。它可以详细记录环境中的所有依赖关系和版本信息,使得环境配置变得透明和可复现。
一个典型的YAML文件包含以下几个部分:
- 环境的名称
- 环境所在的Anaconda或Miniconda的路径
- 包及其版本号
下面是一个简单的YAML文件示例:
```yaml
name: myenv
channels:
- https://conda.anaconda.org/conda-forge
- https://conda.anaconda.org/defaults
dependencies:
- numpy=1.20.1
- pandas=1.2.4
- python=3.8
```
#### 执行逻辑说明
1. 创建一个名为`environment.yml`的YAML文件,将环境的名称、通道和依赖关系写入文件。
2. 在新环境或需要该环境的机器上,使用`conda env create -f environment.yml`命令导入YAML文件定义的环境。
在实际操作中,YAML文件不仅能够用于环境的创建和导出,还可以利用版本控制系统进行版本控制和协作开发。团队成员可以在共享的代码仓库中同步环境配置,确保开发环境的一致性。
YAML文件的管理和使用,提高了环境配置的可复现性和可移植性,是高级环境管理中不可或缺的一步。
## 3.2 环境变量的设置和调试
### 3.2.1 环境变量的作用域
环境变量在计算机程序中起着至关重要的作用,尤其是在多任务操作系统中。它们定义了程序运行的环境以及程序如何与系统交互的配置信息。在Anaconda环境中,环境变量的作用域可以限定在特定的Conda环境内,这样可以避免全局环境变量的污染,并提供更好的封装性。
Conda环境允许用户为每个独立的环境设置不同的环境变量。当激活某个环境时,与该环境相关的环境变量会被自动加载,而其他环境的变量则会被隐藏。
例如,可以设置`PATH`环境变量,将某个自定义脚本或工具的路径添加到其中。通过在环境的激活状态下添加路径,可以确保只有该环境中的程序能够使用这些路径。
```
conda activate myenv
export PATH=/path/to/my/script:$PATH
```
### 3.2.2 常见问题及排查方法
在管理环境变量时,经常会遇到一些问题,例如路径设置错误、变量未被正确加载等。在排查这些问题时,可以通过以下步骤进行:
1. **确认环境是否被正确激活**:只有激活了相应的Conda环境,环境变量的设置才会生效。
2. **检查环境变量的设置位置**:确保环境变量是在环境激活的状态下设置的。可以使用`echo $PATH`来确认路径是否已经正确添加。
3. **使用`conda env list`命令**:查看当前所有激活和非激活的环境,并确认所需的环境是否已经被激活。
4. **使用`which`命令**:在环境激活后,使用`which <command>`来检查特定命令的路径是否指向了正确的环境。这可以用来检查系统是否能够找到正确的执行文件。
5. **使用`env`命令**:通过`env | grep PATH`可以查看环境变量设置的详细信息,这有助于识别是否有多个环境变量设置冲突。
正确地管理环境变量能够提高开发效率,并且有助于维持开发环境的稳定性和一致性。排查环境变量相关的问题时,需要细致地检查每一步设置,并确认环境的状态。
## 3.3 多环境的协同工作
### 3.3.1 环境间的依赖解析
在处理多个Conda环境时,确保各个环境之间的依赖关系不会冲突是一个挑战。每个Conda环境都可以有自己独立的包和版本,这可能导致在环境之间的切换过程中出现依赖冲突。
为了解决这一问题,Conda提供了一些命令来帮助用户管理和解析依赖。例如,`conda env update`命令可以用来更新环境配置,它会尝试解决依赖冲突并安装相应的包。
```
conda env update --name myenv --file environment.yml
```
使用这种方法可以确保在一个环境中的更新不会影响到其他环境。然而,当依赖关系变得更加复杂时,可能需要手动干预来解决冲突。
### 3.3.2 工作流中的环境管理策略
在开发过程中,通常会有多种环境,比如开发环境、测试环境和生产环境。这些环境通常会有不同的配置和依赖关系。为了确保流程的顺利和产品的稳定性,需要制定一个明确的环境管理策略。
一种常见的策略是使用环境配置文件(如YAML文件)来管理不同环境中的配置。这样做的好处是可以清晰地记录每个环境的配置,同时也便于在不同环境之间迁移和复现。
另一个策略是使用持续集成(CI)和持续部署(CD)的工具来自动化环境的创建和管理。工具如Jenkins、Travis CI和GitHub Actions可以与Conda环境无缝集成,自动化测试、构建和部署过程。
#### 执行逻辑说明
1. **环境配置文件管理**:为每种环境创建一个YAML配置文件,记录必要的依赖和包版本。
2. **自动化工具集成**:使用CI/CD工具,在代码提交时自动创建和测试新的Conda环境。
3. **环境隔离**:确保每个环境都有独立的资源和配置,避免相互影响。
通过这种方式,开发团队可以更高效地管理和维护多个环境,同时减少因环境差异导致的问题。在多环境协同工作时,清晰的策略和自动化工具的使用可以大大提升工作效率和项目质量。
# 4. Anaconda与外部数据源的整合
## 4.1 掌握外部数据源的配置
### 4.1.1 配置Anaconda以使用私有源
对于企业环境或者需要特定包版本的场景,配置Anaconda使用私有源是一个常见需求。私有源可以是公司内部维护的,也可以是特定的第三方源。私有源配置的目的是让Conda能够从私有服务器上拉取或推送包。
首先,需要在用户主目录下的 `.condarc` 文件中添加私有源的地址。如果该文件不存在,则需要新建一个。配置项 `channels` 用于添加源的地址,可以添加多个源,并且Conda会按照列表的顺序查找包。
```yaml
channels:
- https://private-source.example.com/anaconda
- https://conda.anaconda.org/conda-forge
- https://repo.anaconda.com/pkgs/main/
```
在上述配置中,Conda首先会尝试从私有源下载包,如果私有源中没有,则会查找conda-forge和默认的anaconda源。
### 4.1.2 管理多个数据源的优先级
当配置了多个数据源后,包的查找和安装顺序就需要特别注意。Conda默认是先查找配置文件中列出的第一个源,如果找不到需要的包,再依次查找后面的源。
如果需要对特定包从特定源安装,可以使用 `-c` 参数指定通道:
```shell
conda install package-name -c private-source
```
有时可能会遇到多个数据源提供相同包的不同版本的情况,为了避免版本冲突,可以明确指定需要的版本或者从特定的数据源安装。
```shell
conda install package-name=1.0.0 -c private-source
```
此外,Conda还提供了一种方式来解决版本冲突问题,即创建一个名为 `priority` 的文件夹,在该文件夹内存放高优先级的包,Conda在查找包时会优先查找该文件夹内的包。
## 4.2 外部数据源在项目中的应用
### 4.2.1 项目依赖的外部包管理
项目开发中,外部包的依赖管理是一个关键部分。正确的管理方法可以确保项目的可复现性和依赖的准确性。Conda允许通过环境文件(`.yaml`)来管理依赖。
创建一个环境文件 `environment.yml`,列出所有需要的包和对应的版本:
```yaml
name: my-project-env
dependencies:
- python=3.8
- numpy=1.20
- scipy=1.6
```
之后,可以通过以下命令来创建环境:
```shell
conda env create -f environment.yml
```
### 4.2.2 解决包版本冲突的方法
当项目涉及多个依赖包时,可能会出现版本冲突的问题,特别是当某些包依赖于同一个库的不同版本时。Conda提供了两种解决冲突的方法:
1. **使用 `mamba`:** `mamba` 是一个基于 `libsolv` 的Conda替代品,它提高了包解决的速度。对于复杂的依赖环境,mamba能更快找到解决方案。
```shell
mamba env create -f environment.yml
```
2. **使用 `conda env update`:** 如果环境已经创建,而需要更新某些包的版本,可以使用以下命令来更新环境,同时尝试解决潜在的依赖冲突。
```shell
conda env update --name my-project-env --file environment.yml
```
## 4.3 案例分析:外部数据源的集成实战
### 4.3.1 实际项目需求分析
假设有一个数据分析项目需要使用到特定版本的pandas库和一个私有源的自定义包。项目组成员分布在不同的地点,需要能够独立地安装和运行项目环境。
为了满足这个需求,我们需要做如下几步操作:
1. **配置私有源:** 在所有成员的 `.condarc` 文件中添加私有源的地址。
2. **编写环境文件:** 创建 `environment.yml` 文件,明确指定需要的包和版本。
3. **部署环境:** 成员在自己的计算机上根据环境文件创建Conda环境。
### 4.3.2 集成步骤与问题解决
#### 步骤一:配置 `.condarc`
私有源地址为 `https://private-source.example.com/anaconda`。所有参与项目的成员需要将其添加到自己的 `.condarc` 文件中。
```yaml
channels:
- https://private-source.example.com/anaconda
```
#### 步骤二:编写 `environment.yml`
指定项目所需的所有包及版本。
```yaml
name: data-analysis-env
dependencies:
- pandas=1.2.3
- custom-package=0.1.0
```
#### 步骤三:创建环境
在项目根目录下运行以下命令来创建环境:
```shell
conda env create -f environment.yml
```
或者更新已有环境:
```shell
conda env update --name data-analysis-env --file environment.yml
```
#### 问题解决
在操作过程中,可能会遇到包冲突或者依赖问题。我们可以使用 `conda env export` 查看当前环境的完整配置,然后在问题出现时进行调整。如果遇到难以解决的冲突,可以考虑使用mamba作为替代方案:
```shell
mamba env create -f environment.yml
```
通过这样的步骤,团队成员可以确保在不同地点使用一致的环境配置,提高开发和部署的效率,避免了因环境差异导致的问题。
# 5. Anaconda的扩展应用与未来展望
Anaconda不仅仅是一个方便的Python包管理工具,它的强大之处还体现在与各种技术的整合能力上。在数据科学和云计算等领域,Anaconda的整合应用正在不断拓宽其边界,并为未来的发展趋势增添更多可能性。
## 5.1 Anaconda与云计算服务的整合
Anaconda与云计算服务的结合,开辟了数据科学工作流的新模式,极大提升了研究和部署的效率。
### 5.1.1 利用Anaconda部署到云端
在云计算日益普及的今天,许多云服务提供商支持Anaconda,使其成为云端部署的理想选择。例如,AWS、Google Cloud Platform和Azure等都提供了与Anaconda相关的服务或镜像。通过云服务的虚拟机或容器服务,如Docker和Kubernetes,可以实现Anaconda环境的快速部署和扩展。
```bash
# 示例:在AWS的EC2实例上部署Anaconda环境
ssh -i "your_key.pem" ubuntu@ec2-instance-public-dns
sudo su
# 安装Docker
apt-get update && apt-get install docker.io
# 获取包含Anaconda的Docker镜像并运行
docker run -it -v /home/ubuntu/your_project:/project continuumio/anaconda3 /bin/bash
# 现在你可以在容器中使用Anaconda了
```
### 5.1.2 云服务与本地环境的协同
云服务与本地Anaconda环境之间的协同工作,可以实现数据的无缝流动和处理能力的弹性扩展。通过使用Anaconda与云平台集成的工具,如Anaconda’s Enterprise Platform,数据科学家可以轻松地在本地和云端之间迁移项目和数据。
## 5.2 Anaconda在数据科学中的应用趋势
随着数据科学领域的不断演进,Anaconda正逐步成为该领域的核心工具。
### 5.2.1 当前数据科学领域的挑战
数据科学领域正面临着数据量的爆炸性增长、计算资源的需求增加以及跨学科合作的复杂性提升等挑战。Anaconda通过提供集成的工具链和环境管理功能,帮助数据科学家应对这些挑战。
### 5.2.2 Anaconda在未来角色预测
Anaconda的未来发展可能会集中在以下几个方向:增强的协作功能、对新兴技术(如AI、机器学习和大数据)的更紧密集成、以及更强大的跨平台兼容性。此外,Anaconda可能会更多地融入自动化和智能化的数据工作流程中。
## 5.3 社区动态与资源分享
Anaconda社区是推动这一平台持续成长的重要力量。社区成员不仅能够分享经验,还能共同开发和测试新的功能。
### 5.3.1 加入Anaconda社区的好处
加入Anaconda社区,可以访问丰富的学习资源、最新的软件更新和一个由全球数据科学家组成的互助网络。社区还会定期举办线上线下的活动,促进成员间的交流和合作。
### 5.3.2 分享和获取资源的最佳实践
在社区中分享和获取资源的最佳实践包括:参与讨论论坛、贡献或使用开源项目、以及通过博客或会议交流经验。例如,你可以通过Conda Forge发布自己创建的包,也可以从该平台上下载其他成员开发的包来优化你的工作流程。
总结而言,Anaconda的未来展望充满了无限的可能性,而社区和云计算服务的整合将成为推动这一平台发展的关键力量。随着数据科学的不断演化,Anaconda作为一个核心工具的角色将更加凸显,并为这一领域的创新和进步作出贡献。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在为数据科学家提供全面的指南,帮助他们高效地将外部数据源集成到 Anaconda 环境中。通过深入探讨七大技巧、安全集成策略、速成指南、最佳实践、核心技术、扩展秘籍、优化策略、多数据源管理技巧和从零开始的全面指南,本专栏涵盖了 Anaconda 外部数据源集成的各个方面。无论您是经验丰富的数据科学家还是刚起步的初学者,本专栏都将为您提供必要的知识和技巧,让您充分利用 Anaconda 的强大功能,无缝地集成外部数据源,并提升您的数据科学项目效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【电力驱动系统安全风险评估】:IEC 61800-5-1标准下的风险分析技巧

参考资源链接:[最新版IEC 61800-5-1标准:电力驱动系统安全要求](https://wenku.csdn.net/doc/7dpwnubzwr?spm=1055.2635.3001.10343)
# 1. IEC 61800-5-1标准概述
IEC 6
【硬件更新与维护攻略】:TIA博途V16维护经验分享

参考资源链接:[TIA博途V16仿真问题全解:启动故障与解决策略](https://wenku.csdn.net/doc/4x9dw4jntf?spm=1055.2635.3001.10343)
# 1. TIA博途V16基础介绍
## 1.1 TIA博途V16概览
TIA博途(Totally Integrated Automation Portal)是西门子公司
Altium 设计者的挑战:15分钟内解决元器件间距过小问题
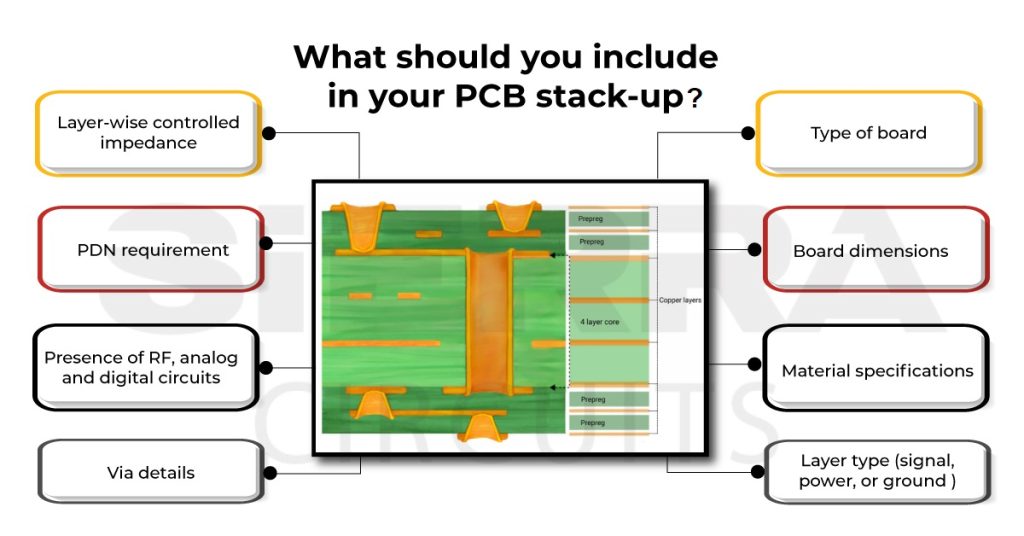
参考资源链接:[altium中单个元器件的安全间距设置](https://wenku.csdn.net/doc/645e35325928463033a48e73?spm=1055.2635.3001.10343)
# 1. Altium Designer中的元器件布局挑战
在当今的电子设计自
MATLAB信号处理全攻略:一步到位掌握入门到高级技巧(限时免费教程)

参考资源链接:[MATLAB信号处理实验详解:含源代码的课后答案](https://wenku.csdn.net/doc/4wh8fchja4?spm=1055.2635.3001.10343)
# 1. MATLA
【BMC管理控制器深度剖析】:戴尔服务器专家指南

参考资源链接:[戴尔 服务器设置bmc](https://wenku.csdn.net/doc/647062d0543f844488e4644b?spm=1055.2635.3001.10343)
# 1. BMC管理控制器概述
BMC(Baseboard Management Controller)管理控制器是数据中心和企业级计算领域的核心组件之一。它负责监控和管理服务器的基础硬
PSCAD C语言接口实战秘籍:从零到精通的7天速成计划

参考资源链接:[PSCAD 4.5中C语言接口实战:简易积分器开发教程](https://wenku.csdn.net/doc/6472bc52d12cbe7ec306319f?spm=1055.2635.3001.10343)
# 1. PSCAD软件概述与C语言接口简介
在现代电力系统仿真领域,PSCAD(Power Systems Computer Aide
RK3588射频设计与布局:提升无线通信性能的关键技巧
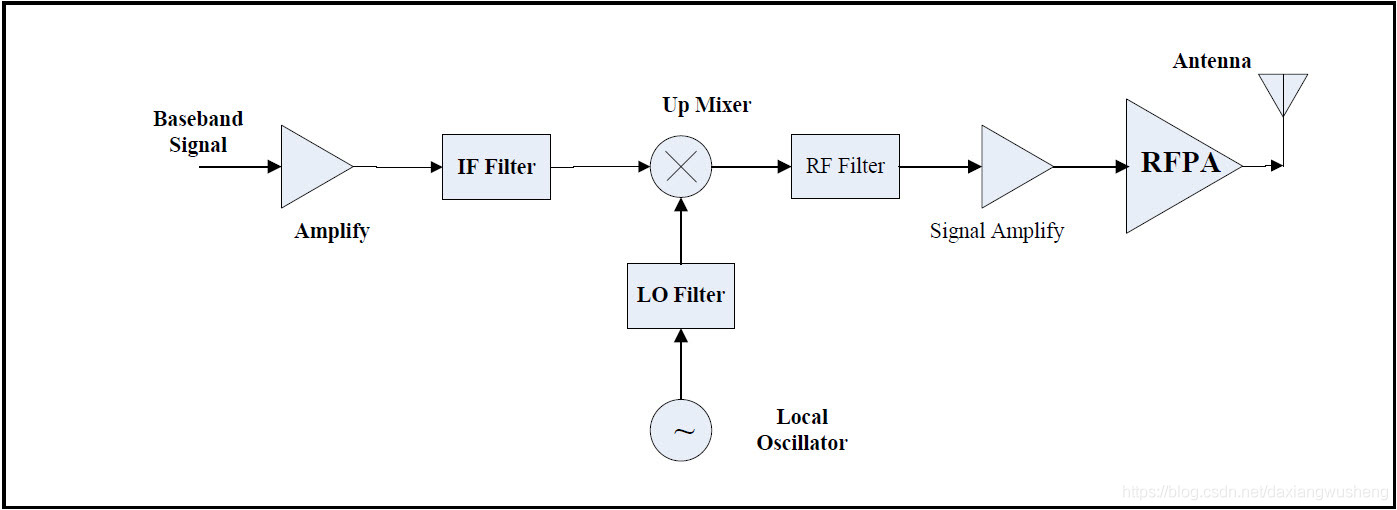
参考资源链接:[RK3588硬件设计全套资料,原理图与PCB文件下载](https://wenku.csdn.net/doc/89nop3h5n
微信视频通话质量提升必杀技:虚拟摄像头高级设置全解

参考资源链接:[使用VTube Studio与OBS Studio在微信进行虚拟视频通话的探索](https://wenku.csdn.net/doc/85s1wr0wvy?spm=1055.2635.3001.10343)
# 1. 虚拟摄像头技术概述
在信息技术高速发展的今天,虚拟摄像头技术以其独特的魅力,成为了一个引人注目的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )